この記事は ABEJA アドベントカレンダー 2020 の 20 日目の記事です。
ABEJA ではエンジニアをやっており毎日、Clojure Python を書いています。
動機
Wikipedia のLISP のページにも書かれているように、LISP は一般に「括弧が多い」といった印象を持たれています。
LISP の用いる S 式は括弧を大量に使用するため、批判を受けることもある。「LISP は 『lots of irritating superfluous parentheses』(過剰でいらいらさせる大量の括弧)に由来する」というジョークもある。
この「括弧が多い」印象で、LISP 嫌いを多く排出しているようなのですが、そもそも「本当に括弧が多いのか?」が前から気になっていました。
ちょうど、Dataflow, BigQuery を勉強しておきたいと思っていたことも重なり、今回は、Dataflow, BigQuery で実際に「Lisp はカッコが多い!」のか調べてみることにしました。
括弧が少ないとわかれば、LISP 嫌いが減少することを期待しつつ...
とりあえず
実装を開始する前に以下を決めておきます。
- 調査対象となる括弧
- 調査対象となる言語
- 利用するソースコード
- 括弧の多さの判断基準
調査対象となる括弧
無難に、以下の3つを対象とします。
-
(): 丸括弧 -
[]: 角括弧 -
{}: 波括弧
調査対象となる言語
あまたあるプログラミング言語の中で今回は、以下のプログラミング言語を対象にします。
- Lisp 系: Clojure, Common Lisp, Scheme
- Lisp 以外: JavaScript, Python, Java, TypeScript, C#, PHP, C++, C, Shell, Ruby
Lisp 系の言語からは知名度がある Clojure, Common Lisp, Scheme、
Lisp 以外の言語からは GitHub 上で人気の高いプログラミング言語のトップ 10 を選択しました。
参考: https://octoverse.github.com/
利用するソースコード
対象言語から実際の括弧の数をカウントするには、大量のソースコードを用意する必要があります。
今回は、Google から Public Dataset として公開されている Github のソースコードを利用したいと思います。
参考: https://cloud.google.com/blog/products/gcp/github-on-bigquery-analyze-all-the-open-source-code
この Github の Public Dataset にはソースコードを格納したテーブルが2種類あります。
-
bigquery-public-data:github_repos.contents- ソースコードを格納
- 全データで 2.3TB
- field にソースコードのパスがない
-
bigquery-public-data:github_repos.sample_contents-
contentsテーブルのソースコードの10%の内容をランダムにサンプリングした結果のソースコードを格納 - 全データで 24 GB
- field にソースコードのパスがある
-
今回は、パスから言語を判断する必要もあり、簡単に利用できる bigquery-public-data:github_repos.sample_contents を利用します。
もし bigquery-public-data:github_repos.contents を利用したい場合は、パス情報を得るため bigquery-public-data:github_repos.contents
と JOIN する必要があります。 JOIN 後は、本記事と同様のパイプライン処理で括弧をカウントすることができると思います。
括弧の多さの判断基準
利用する Github のソースコード情報は言語毎に、ソースコードの合計ファイル数, 合計文字数が異なります。
そのため、文字数に含む括弧の割合で括弧の多さを判断したいと思います。
- 括弧の多さ(rate):
括弧の数/合計文字数
調査開始
それでは、調査を開始します。
Dataflow を使って、括弧の数をカウントしていくのですが、全体の流れは以下となります。
- BigQuery からソースコードを読み込み
- 各ソースコードの括弧をカウントする
- 言語毎にカウント結果をまとめる
- BigQuery に結果を出力する
さきに Dataflow で走らせた際のパイプラインを貼っておきます。
Step1: BigQuery からソースコードを読み込み
BigQuery から Github のソースコードを読み込む処理は以下のようになります。
GCP_PROJECT_ID = 'xxxxxxxx'
GCS_BUCKET_NAME = 'xxxxxxxx'
JOB_NAME = 'xxxxxxxx'
REGION = "xxxxxxxx"
options = PipelineOptions()
options.view_as(StandardOptions).runner = 'DataflowRunner'
gcp_options = options.view_as(GoogleCloudOptions)
gcp_options.project = GCP_PROJECT_ID
gcp_options.job_name = JOB_NAME
gcp_options.region = REGION
gcp_options.staging_location = f'gs://{GCS_BUCKET_NAME}/staging'
gcp_options.temp_location = f'gs://{GCS_BUCKET_NAME}/temp'
p = beam.Pipeline(options=options)
query = "SELECT content, sample_path FROM `bigquery-public-data.github_repos.sample_contents`"
(p
# Step1
| "ReadFromBigQuery" >> beam.io.ReadFromBigQuery(
project=GCP_PROJECT_ID, use_standard_sql=True, query=query)
# Step2
# | "CountBrackets" >> beam.Map(count_language_brackets, lang=lang)
# Step3
# | "FilterNonTarget" >> beam.Filter(lambda element: element[0] in target_languages)
# | "GroupByKey" >> beam.GroupByKey()
# | "CombineValues" >> beam.CombineValues(CountUpFn())
# | "ExtractValues" >> beam.Values()
# | "ChangeFormat" >> beam.Map(to_bq_format)
# Step 4
# | "WriteToBigQuery" >> beam.io.WriteToBigQuery(
# table_spec,
# schema=table_schema,
# write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE,
# create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED
# )
)
p.run()
bigquery-public-data.github_repos.sample_contentsからソースコードが格納された content フィールドと言語を判定するためにパス情報が格納された sample_path フィールドのみ読み込みます。
読み込んだデータ(PCollection)のイメージは以下となります。
{'content': '#include<stdio.h>...', 'sample_path': 'abc/abc.c'}
{'content': 'import random...', 'sample_path': 'def/def.py'}
{'content': '(ns hello)...', 'sample_path': 'ghi/ghi.clj'}
{'content': '#include<stdio.h>...', 'sample_path': 'jkl/jkl.c'}
{'content': '(ns world)...', 'sample_path': 'mno/mno.clj'}
...
Step2: 各ソースコードの括弧をカウントする
Step1 で得られた PCollection データに対して Map に括弧をカウントする処理を渡すことで、以下の PCollection を作成します。
変換後データ
('C', {'language': 'C', 'length': 300, 'brackets': {'(': 2, ')': 2, '[': 2, ']': 2, '{': 10, '}': 10}}),
('Python', {'language': 'Python', 'length': 588, 'brackets': {'(': 3, ')': 3, '[': 2, ']': 2, '{': 8, '}': 8}}),
('Clojure', {'language': 'Clojure', 'length': 895, 'brackets': {'(': 5, ')': 5, '[': 3, ']': 3, '{': 8, '}': 8}}),
('C', {'language': 'C', 'length': 1230, 'brackets': {'(': 4, ')': 4, '[': 5, ']': 5, '{': 5, '}': 5}}),
('Clojure', {'language': 'Clojure', 'length': 300, 'brackets': {'(': 3, ')': 3, '[': 4, ']': 4, '{': 12, '}': 12}})
('non-target', {'language': 'non-target', 'length': 9700, 'brackets': {'(': 9, ')': 9, '[': 30, ']': 30, '{': 8, '}': 8}})
...
あとで、言語毎にカウント結果を集約するため、言語をキーにしたデータ構造にしておきます。
Step3: 言語毎にカウント結果をまとめる
Step2 で得られた PCollection に対し、5 つの Transform を実行することで、言語毎の括弧の数を集計していきます。
(もっと良い書き方がありそう...)
FilterNonTarget
Step2 で得られた結果には、カウント対象となる言語以外も含まれており、non-target キーを付けてカウントしています。
今後の処理では不要なので、このデータを Filter を使って削除します。
変換後データ
('C', {'language': 'C', 'length': 300, 'brackets': {'(': 2, ')': 2, '[': 2, ']': 2, '{': 10, '}': 10}}),
('Python', {'language': 'Python', 'length': 588, 'brackets': {'(': 3, ')': 3, '[': 2, ']': 2, '{': 8, '}': 8}}),
('Clojure', {'language': 'Clojure', 'length': 895, 'brackets': {'(': 5, ')': 5, '[': 3, ']': 3, '{': 8, '}': 8}}),
('C', {'language': 'C', 'length': 1230, 'brackets': {'(': 4, ')': 4, '[': 5, ']': 5, '{': 5, '}': 5}}),
('Clojure', {'language': 'Clojure', 'length': 300, 'brackets': {'(': 3, ')': 3, '[': 4, ']': 4, '{': 12, '}': 12}})
...
GroupByKey
次に、言語毎にデータをまとめます。
言語(キー)でまとめるには、GroupByKey を使います。
変換後データ
('C', [{'language': 'C', 'length': 300, 'brackets': {'(': 2, ')': 2, '[': 2, ']': 2, '{': 10, '}': 10}},
{'language': 'C', 'length': 1230, 'brackets': {'(': 4, ')': 4, '[': 5, ']': 5, '{': 5, '}': 5}}])
('Python', [{'language': 'Python', 'length': 588, 'brackets': {'(': 3, ')': 3, '[': 2, ']': 2, '{': 8, '}': 8}}])
('Clojure', [{'language': 'Clojure', 'length': 895, 'brackets': {'(': 5, ')': 5, '[': 3, ']': 3, '{': 8, '}': 8}},
{'language': 'Clojure', 'length': 300, 'brackets': {'(': 3, ')': 3, '[': 4, ']': 4, '{': 12, '}': 12}}]))
...
CombineValues
キーを維持したまま括弧の数を集約したいので、CombineValues を利用します。
変換後データ
('C', {'language': "C", 'files': 200, 'length': 2000, 'rate': 0.037,
'brackets': {'(': 20, ')': 20, '[': 30, ']': 30, '{': 32, '}': 32}})
('Python', {'language': "Python", 'files': 150, 'length': 1500, 'rate': 0.032,
'brackets': {'(': 15, ')': 15, '[': 20, ']': 20, '{': 12, '}': 12}})
('Clojure', {'language': "Clojure", 'files': 100, 'length': 1000, 'rate': 0.071,
'brackets': {'(': 40, ')': 40, '[': 33, ']': 33, '{': 58, '}': 58}})
...
ExtractValues
言語毎に括弧を集約するために利用したキーは不要になったので、Values を使い値のみを取り出します。
変換後データ
{'language': "C", 'files': 200, 'length': 2000, 'rate': 0.037,
'brackets': {'(': 20, ')': 20, '[': 30, ']': 30, '{': 32, '}': 32}}
{'language': "Python", 'files': 150, 'length': 1500, 'rate': 0.032,
'brackets': {'(': 15, ')': 15, '[': 20, ']': 20, '{': 12, '}': 12}}
{'language': "Clojure", 'files': 100, 'length': 1000, 'rate': 0.071,
'brackets': {'(': 40, ')': 40, '[': 33, ']': 33, '{': 58, '}': 58}}
...
ChangeFormat
最後に、BigQuery にデータを格納する際のフィールド名として (,),[,],{,} は利用することができないため、以下のように名前を変更します。
-
(=> left_round -
)=> right_round -
[=> left_square -
]=> right_square -
{=> left_curly -
}=> right_curly
変換には、Step2 同様 Map を使います。
今回は Map に渡す処理として、上記の変換を行うコードを渡します。
変換後データ
{'language': "C", 'files': 200, 'length': 2000, 'rate': 0.037,
'brackets': {'left_round': 20, 'right_round': 20, 'left_square': 30, 'right_square': 30, 'left_curly': 32, 'right_curly': 32}}
{'language': "Python", 'files': 150, 'length': 1500, 'rate': 0.032,
'brackets': {'left_round': 15, 'right_round': 15, 'left_square': 20, 'right_square': 20, 'left_curly': 12, 'right_curly': 12}}
{'language': "Clojure", 'files': 100, 'length': 1000, 'rate': 0.071,
'brackets': {'left_round': 40, 'right_round': 40, 'left_square': 33, 'right_square': 33, 'left_curly': 58, 'right_curly': 58}}
...
これで、BigQuery に書き込むことが可能なデータ構造となりました。
Step4: BigQuery に結果を出力する
Step3 の終わりで BigQuery に書き込めるフォーマットの PCollection になっています。
後は データセット名.テーブル名 を表す table_spec とテーブルスキーマを表す table_schema を設定し、apache_beam.io.WriteToBigQueryをパイプライン処理の最後に追加することで、BigQuery への結果の出力を行います。
table_spec = 'xxxx.xxxx'
table_schema = {
'fields': [{'name': 'language', 'type': 'STRING', 'mode': 'NULLABLE'},
{'name': 'files', 'type': 'INTEGER', 'mode': 'NULLABLE' },
{'name': 'length', 'type': 'INTEGER', 'mode': 'NULLABLE' },
{'name': 'rate', 'type': 'FLOAT64', 'mode': 'NULLABLE'},
{'name': 'brackets', 'type': 'STRUCT', 'mode': 'NULLABLE',
'fields': [
{'name': "left_curly", 'type': 'INTEGER'},
{'name': "right_curly", 'type': 'INTEGER'},
{'name': "left_round", 'type': 'INTEGER'},
{'name': "right_round", 'type': 'INTEGER'},
{'name': "left_square", 'type': 'INTEGER'},
{'name': "right_square", 'type': 'INTEGER'}]}]}
(p
# Step1
# Step2
# Step3
# Step4
| "WriteToBigQuery" >> beam.io.WriteToBigQuery(
table_spec,
schema=table_schema,
write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED
)
)
結果報告
それでは、結果報告にいきたいと思います。
括弧の多さの判断基準 で書いたように括弧の多さは rate: 括弧の数/合計文字数 で判断します。
BigQuery にある結果テーブルに対し、rate で降順にソートし出力します。
SELECT * FROM `dataset_name.table_name` ORDER BY rate DESC
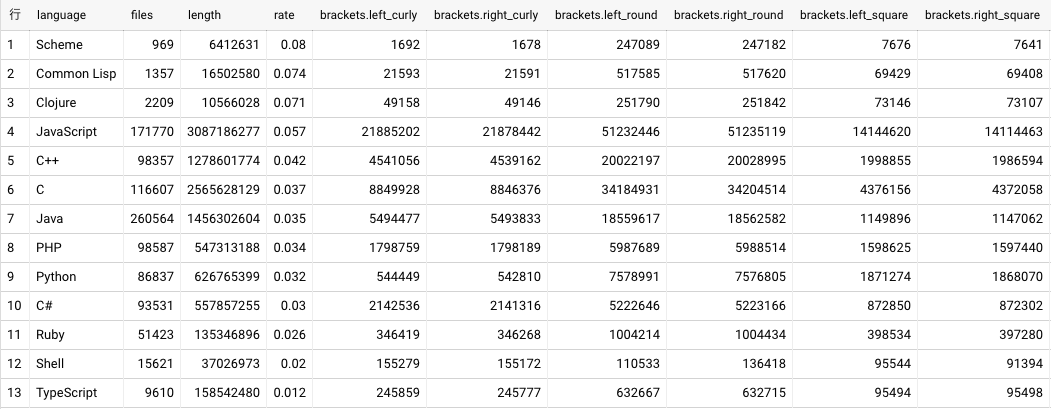
上位3言語を確認すると、
- 1 位: Scheme (Lisp 系)
- 2 位: Common Lisp (Lisp 系)
- 3 位: Clojure (Lisp 系)
となりました...
結果: Lisp はカッコが多い!
まとめ
今回は、以前から気になっていた「Lisp はカッコが多い!」のかを Dataflow, BigQuery のお勉強がてら調査してみました。
残念ながら、皆が思っていた「Lisp はカッコは多い!」を補強する結果となり、
括弧が少ないとわかれば、LISP 嫌いを減少することを期待しつつ...
という裏目的の達成は失敗となりました。
LISP はカッコが多いからはもはや避けられそうにないので、今後は、カッコは友達 方面から攻めていきたいと思います。
それでは、よいお年を。