英語論文を楽して読みたい!!!
英語苦手すぎて輪講が進まないので、楽する方法がないかと考えました。
思いついたのが要約っぽいことをしてその英文を訳せばいいのでは…
動作確認環境
- Windows10
- Powershell(cmdでもOK)
- Google Colaboratory
- Python 3.7.3
Colaboratoryとは
Colaboratory は、完全にクラウドで実行される Jupyter ノートブック環境である。設定不要で、無料で利用可能。
Colaboratory を使用すると、コードの記述と実行、解析の保存や共有、強力なコンピューティングリソースへのアクセスなどをブラウザからすべて無料で行うことが可能。

手順
- 論文から本文のみを抽出する(タイトル、章の名前、図表、参考文献を除去)
- 各章の文章に対してLexRankを適用し、キーとなる文章の抽出
- 各章のキーとなる文章を結合し、言語モデルを用いて要約に近い文章を作成する
※論文のabstractやconclusionより詳細な文章を生成するために、正解文を必要としないやり方を使ってます
LexRankについて
文章の要約は大きく分けて抽出型と生成型に分類されます。
LexRankは抽出型に分類される要約アルゴリズムです。
文書からグラフ構造を作り出して重要な文のランキングを作ることで要約と言える文を出力するというものです。
2004年にGunes Erkan, Dragomir R. Radevによって提案されています。
文のグラフ表現における固有ベクトル中心性の概念に基づいて文の重要度を計算するための新しいアプローチ、LexRankを検討します。このモデルでは、文内コサイン類似性に基づく接続性マトリックスが、文のグラフ表現の隣接性マトリックスとして使用されます。
We consider a new approach, LexRank, for computing sentence importance based on the concept of eigenvector centrality in a graph representation of sentences. In this model, a connectivity matrix based on intra-sentence cosine similarity is used as the adjacency matrix of the graph representation of sentences.
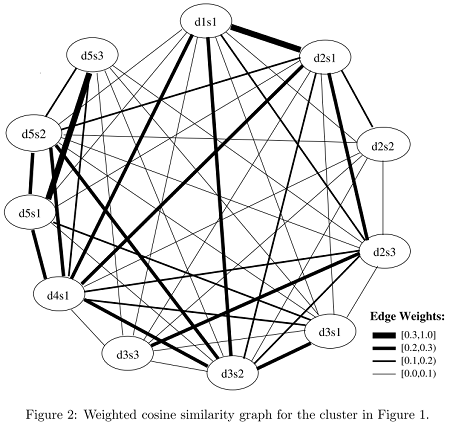
ohkeさんの記事で詳しく説明がされていました。
LexRankのキーポイントは2つで、PageRankから着想を得たTextRank (提案論文PDF) の派生となります。文をノード、文間の類似度をエッジとした無方向グラフを作る。提案論文では、TF-IDFからコサイン類似度で計算 (現代的にはword2vecなども使えるはず)。上のグラフから得られた推移確率行列 (M) と確率ベクトル (P) が安定する状態 (MP=P) まで計算して、最終的な確率ベクトルの値が大きい文を要約文として選択する。
上の理論を視覚化した上図 (提案論文Figure 2から抜粋) で、エッジ数が多く (=たくさんの文と類似している) かつエッジが太い (=類似度が高い) d5s1やd4s1などが要約文の候補となります。
実装
ライブラリのインポートは以下の通りです。LexRankの実装や分かち書き、LSTM言語モデルの構築に必要なライブラリを使用しています。
from __future__ import absolute_import
from __future__ import division, print_function, unicode_literals
from sumy.parsers.html import HtmlParser
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lsa import LsaSummarizer as Summarizer
from sumy.nlp.stemmers import Stemmer
from sumy.utils import get_stop_words
from keras.callbacks import LambdaCallback
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.optimizers import RMSprop
from keras.utils.data_utils import get_file
from googletrans import Translator
import nltk
import numpy as np
import random
import sys
import io
import os
import glob
補足:nltkを使用するときは、punktパッケージごとアップデートすると使用できるようです。
!python -c "import nltk; nltk.download('punkt')"
LexRank部分(sumyを用いた実装)
def sectionLex():
#言語は英語に設定
LANG = "english"
#.txtファイル(各セクションの本文データ)を全て選択
file = glob.glob('*.txt')
ex = []
for i in range(len(file)):
parser = PlaintextParser.from_file(file[i], Tokenizer(LANG))
stemmer = Stemmer(LANG)
summarizer = Summarizer(stemmer)
summarizer.stop_words = get_stop_words(LANG)
for sentence in summarizer(parser.document, [何文出力するか]):
ex.append(str(sentence) + '\n')
# utf-8エンコードで出力
with open('output.txt', mode='w', encoding='utf-8') as f:
f.writelines(ex)
辞書に使用する変数の宣言
# 正順の辞書リスト
chr_index = {}
# 逆順の辞書リスト
rvs_index = {}
# 文のリスト
sentences = []
# 次の単語
next_word = []
分かち書き
# utf-8エンコードで読み込み、textに格納
with io.open('output.txt', encoding='utf-8') as f:
text = f.read().lower()
# 単語ごとに分解(分かち書き)
text = nltk.word_tokenize(text)
chars = text
辞書の作成
# 正順のリストを作成
count = 0
for c in chars:
if not c in chr_index:
chr_index[c] = count
count += 1
print(count, c)
# 逆順のリストを作成
rvs_index = dict([(value, key) for (key, value) in chr_index.items()])
部分文字列の作成
for i in range(0, len(text) - maxlen, step):
#maxlen個の単語を部分文字列(1文)として格納
sentences.append(text[i: i + maxlen])
#格納した部分文字列の次の単語を格納
next_word.append(text[i + maxlen])
単語のベクトル化
# np.bool型の3次元配列:(部分文字列の数、部分文字列の最大長、単語数)
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
# np.bool型の2次元配列:(部分文字列の数、単語数)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
# 各部分文字列をベクトル化する
for i, sentence in enumerate(sentences):
for t, ch in enumerate(sentence):
x[i, t, chr_index[ch]] = 1
y[i, chr_index[next_word[i]]] = 1
モデルの作成
今回は、Sequentialモデルを使用しています。
softmaxについては、@rtokさんの記事が分かりやすかったです。
# 単純モデルを作る
model = Sequential()
# LSTMを使用。バッチサイズは128
model.add(LSTM(128, input_shape=(maxlen, len(chars))))
# 単語ごとにsoftmaxで確率を出せるようにする
model.add(Dense(len(chars), activation='softmax'))
勾配法にはRMSpropを使用しました。
RMSpropは、@tokkumanさんの記事が分かりやすかったです。
optimizer = RMSprop(learning_rate=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
各単語の出現率を計算し、出力する単語を選ぶ
# preds :モデルからの出力。float32型。
# temperature :多様度。低いほど出現率の高いものが選ばれやすくなる。
# モデルから出力は多項分布の形のため、総和は1.0になる
def selectWD(preds, temperature=1.0):
#float64型へ変換
preds = np.asarray(preds).astype('float64')
#確率の低い単語が選ばれやすくなるように、自然対数を多様度で割る
preds = np.log(preds) / temperature
#確率の自然対数を逆変換する(自然指数関数にする)
exp_preds = np.exp(preds)
#総和が1になるように、全値を総和で割る
preds = exp_preds / np.sum(exp_preds)
#多項分布に従って、ランダムに選ぶ
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)
各epochごとの処理
def on_epoch_end(epoch, _):
print()
print('----- Generating text after Epoch: %d' % epoch)
#最初の4単語を入力文字列の最初にする
start_index = 0
#diversity:多様性。selectWDのtemperatureと同じ。高いほど確率が低い文字も選ばれる。
for diversity in [0.2, 0.5, 0.8, 1.0]:
print('----- diversity:', diversity)
#出力用
generated = ''
sentence = text[start_index: start_index + maxlen]
generated += " ".join(sentence)
print(" ".join(sentence))
print('----- Generating with seed: "' + " ".join(sentence)+ '"')
sys.stdout.write(generated)
#OUTSEN個の文を出力、あるいは1000単語出力で終了
flag = OUTSEN
for i in range(1000):
#現在の文中のどの位置に何の単語があるか
x_pred = np.zeros((1, maxlen, len(chars)))
for t, ch in enumerate(sentence):
x_pred[0, t, chr_index[ch]] = 1.
#次の単語を予測する
preds = model.predict(x_pred, verbose=0)[0]
next_index = selectWD(preds, diversity)
next_char = rvs_index[next_index]
#最初の単語を削り、後ろに予測された単語を追加
sentence = sentence[1:]
sentence.append(next_char)
#出力整理
if next_char == '.':
flag -= 1
generated += next_char + "\n"
sys.stdout.write(next_char+"\n")
elif next_char == ',':
generated += next_char
sys.stdout.write(next_char)
else:
generated += " " + next_char
sys.stdout.write(" "+next_char)
sys.stdout.flush()
if flag <= 0:
break
sys.stdout.flush()
print()
# 各エポック時に上記処理を呼ぶように設定
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
フィッティング処理
# バッチサイズ128、エポック数100、前記述の関数を呼び出す
model.fit(x, y, batch_size=128, epochs=100, callbacks=[print_callback])
結果
BottaらのIntegration of Cloud computing and Internet of Things: A survey(2016)をデータにした際の結果です。
----- Generating text after Epoch: 99
----- diversity: 0.2
in general , iot
----- Generating with seed: "in general , iot"
in general , iot can benefit from the virtually unlimited capabilities and resources of cloud to compensate its technological constraints ( e.g., storage, processing, communication ).
being iot characterized by a very high heterogeneity of devices, technologies, and protocols, it lacks different important properties such as scalability, interoperability, flexibility, reliability, efficiency, availability, and security.
as a consequence, analyses of unprecedented complexity are possible, and data-driven decision making and prediction algorithms can be employed at low cost, providing means for increasing revenues and reduced risks.
the availability of high speed networks enables effective monitoring and control of remote things, their coordination, their communications, and real-time access to the produced data.
this represents another important cloudiot driver : iot processing needs can be properly satisfied for performing real-time data analysis ( on-the-fly ), for implementing scalable, real-time, collaborative, sensor-centric applications, for managing complex events, and for supporting task offloading for energy saving.
5文の出力をしていますが、google翻訳で日本語訳をするとこんな感じ。
一般に、iotはクラウドの実質的に無制限の機能とリソースの恩恵を受けて、技術的な制約(ストレージ、処理、通信など)を補うことができます。
デバイス、テクノロジー、およびプロトコルの非常に高い不均一性が特徴であり、スケーラビリティ、相互運用性、柔軟性、信頼性、効率、可用性、セキュリティなどのさまざまな重要なプロパティがありません。
その結果、前例のない複雑さの分析が可能になり、データ駆動型の意思決定および予測アルゴリズムを低コストで採用できるため、収益の増加とリスクの削減を実現できます。
高速ネットワークの可用性により、リモートのもの、その調整、通信、および生成されたデータへのリアルタイムアクセスの効果的な監視と制御が可能になります。
これは別の重要なcloudiotドライバーを表します:リアルタイムデータ分析(オンザフライ)の実行、スケーラブルでリアルタイムのコラボレーション中心のセンサー中心のアプリケーションの実装、複雑なイベントの管理、および省エネのためにタスクのオフロードをサポートします。
それっぽくまとまっているように感じます!
このソースコード全体はgithubで公開しています。
日本語的におかしいところも少し出ているので、改善していきます…