はじめに
2024年末ごろから、自宅環境でローカルLLMを触り始めました。
きっかけは、
• クラウドAPIは従量課金で、使えば使うほどコストが見えにくくなる
• セキュリティやデータ持ち出しの観点で不安が残る
• それなら小さなモデルからでも、自前で動かしてみたい
• 将来的に、社内でもローカルLLMの選択肢を広げたい
こうした思いから、小さめのモデルであれば、手元のGPUでも動かせて、Fine-Tuningも自前で試せるのではないかと考えたのがスタートでした。
以下長いので折りたたみ
ただ、実際にローカルLLMを回し始めて気づいたのは、モデルの精度やGPU性能以前の問題でした。• GPUは本当に仕事をしているのか
• 何か異常が起きていないか
• 処理が止まっているのに、GPUサーバの電源が入ったままではないか
ローカル環境では、こうした問いに自動で答えてくれる仕組みは何もありません。
本記事では、この課題に対して New Relicを使ったObservabilityをどう取り入れ、
• 無駄なコスト(電気代)をどのように削減したのか
• 障害対応をどう早められたのか
• LLMを「推論・学習を続けられる状態」にどう近づけたのか
という点を、個人GPU環境での実体験をもとにまとめています。
長めの記事になりますが、「ローカルLLM」、「オブザーバビリティ」に興味のある方に、何かしらのヒントとなれば幸いです。
補足:本記事でいう「GPUサーバ」について
補足内容(補足内容が表示されます)
本記事では「GPUサーバ」という表現を使っていますが、いわゆる GPUを複数枚搭載した業務用サーバ ではありません。
今回の環境は、
• GPU:RTX 4090 × 1枚
• OS:Ubuntu
• 用途:ローカルLLMの推論・Fine-Tuning
という、比較的シンプルな構成です。
あえて「GPUサーバ」と呼んでいるのは、
• 計算資源としてGPUを専有
• 学習・推論ジョブを サーバ的に常時受け付ける運用
• 障害対応・監視・ログ管理を インフラとして扱っている
という理由からです。
物理的にはデスクトップPC・ワークステーションに近いですが、運用の仕方は完全にサーバ なので、本記事ではこの呼び方をしておりますのでご了承下さい。
ローカルLLM、実は一番の敵はGPU性能じゃない?
使っているのはあくまでゲーマ向けのGPU RTX4090。(RTX PRO、DGX Sparkも欲しいですが、はい。買えません。)
データセンター向けGPUのような潤沢なGPUメモリがあるわけでもなく、Blackwell世代というわけではありません。
もちろん、潤沢なGPUメモリがあることに越したことはないですが・・・(SLMのトレンドもあるということで!)
実際、推論・Fine-Tuningを行うと、
• CUDAエラーが出る
• 学習が途中で止まる
• 推論が急に遅くなる
といったことが発生します。
「うまく回らないのは、単純にハードウェアのスペックが問題」と考えていました。
• GPU性能が足りない
• VRAMが少ない
• マシン構成自体が貧弱
そう結論づけていました。
「やっぱり個人環境じゃ厳しい・・・!!」と。
無駄なコストに気づいた瞬間 〜家庭内CFOからの指摘〜
そんな試行錯誤を続けているうちに、技術的な問題とは別の方向から“指摘”が入るようになりました。
家庭内CFOからの一言です。
「最近、電気代ちょっと高くない?」
一瞬ドキッとしつつも、その場ではこう返しました。
「寒くなってきて、エアコン使うようになったからじゃない?」
とその場はなんとかやり過ごし、月々の電気代をあらためて見返してみると、確かに以前よりじわじわ上がっています。これは流石にマズイと思い、そこで初めて「GPUは“計算”していたのか、それとも“電気を消費していただけ”だったのか?」という視点で環境を見直しました。
すると、次の事実が見えてきました。
• Dockerコンテナは落ちている
• Fine-Tuningは止まっている
• GPU使用率は高止まり・サーバの電源はついたまま
処理は止まっているのに、電力だけが消費され続けている。
GPU性能も必要だが、限られた資源の中で最高のパフォーマンスを出すには問題はGPU性能ではなく、「止まっていることに気づけない構造」だった点に気づきました。
そしてもう一つ、同時に気づいたことがあります。
それは、その事実に、これまできちんと対応出来ていなかったという点です。
これは個人環境だけの話ではないと感じています。
少し視点を広げてみると、エンタープライズ環境でも、次のような状況は決して珍しくないのではないでしょうか。
• コストが発生していること自体は把握している
• ただし、「どこで」「何に」コストが使われているかまでは見えていない
• 何となく無駄がありそうだという感覚はある
• しかし日々の業務や別の優先事項に追われ、実態を深掘りできていない
このような状態が続くと、
• 実際の稼働状況が分からないままコストだけが積み上がったり
• 本来は止まっている処理が「動いている前提」で扱われ続けたり
といったことが起こりやすくなります。これは担当者一人ひとりの力量の問題ではなく、状況を正しく把握し、判断や行動につなげるための仕組みが用意されていないことが原因だと考えます。
監視の限界を感じて、オブザーバビリティに切り替えた理由
自宅のサーバ監視は、Zabbix+Grafana+Elasticsearchで行っています。
構成としては定番(定番ですよね??)ですが、オープンソースでは中々課題があります。
• 有料製品・SaaSに比べて痒いところに手が届かない
• アラート条件の設計に時間がかかる
• ダッシュボード作成が手間
• 障害発生時に複数のツールを確認する必要がある
従来の監視では、
• CPUやGPU使用率はこの画面
• アプリの挙動は別の画面
• エラーの詳細はログを探しに行く
といったように、見るべき情報があちこちに分かれている状態になりがちです。
システムが単純なうちは、このやり方でも問題ありません。
しかし、
• 複数のDocker
• GPUのような高価なリソースが絡む
ようになると、「いま何が起きているのか?」、「どこが原因なのか?」を一度に把握するのが、急に難しくなります。
そこで必要になるのが、単なる「監視」ではなくオブザーバビリティという考え方です。
オブザーバビリティでは、システムの内部状態を把握するために次の3つのデータを中核として扱い、さらにNew Relicでは、これらにイベントという要素を加えています。
オブザーバビリティに必要不可欠な3要素+1は以下解説をご覧下さい。
こうした考え方を前提にツールを探す中で、出会ったのがNew Relicでした。
• 一般ユーザーでも無償で利用可能(ログを含め月あたり100GBまで利用可)
• ホスト、Docker、GPUを含むメトリクスを横断的に扱える
• トレースやイベントを同じ文脈で確認できる
「まずは試してみよう」という気持ちで導入しましたが、結果として監視の捉え方そのものが変わったと感じています。
直近では、AI時代のオブザーバビリティをテーマにした公式動画も公開されており、まだSFの世界かもしれませんが、大きな示唆を受けました。
サーバ監視のZabbix+Grafana+Elasticsearchはメトリクス・ログ保存期間の観点から現在も運用しており、New Relicとの使い分けも含めて、別記事で紹介したいと思います。
Dockerログの一括管理 ― ログは「結果」だが、原因への入口になる
LLM関連のアプリケーションは、すべてDockerで構築しています。
推論・Fine-Tuning・前処理などをコンテナ単位で分けているため、ログも分散しがちでした。
そこで、解析に必要なログをElasticsearchからNew Relicに移行しました。
その結果、
• コンテナ横断でのログ検索
• エラー前後の流れを時系列で一気に確認
• ログを追う作業が激減
といった変化があり、「何が起きていたか」を後から追う時間が、明らかに減ったと感じています。
New Relicのobservability記事でも触れられている通り、ログは OS・ミドルウェア・アプリケーションなどから出力される「結果」であり、それ自体が直接の原因を語るものではありません。ただし、GPUメトリクスやコンテナの状態と 同じ時間軸でログを重ねて見ることで、
• どのタイミングで異常が起き
• その直前にどの処理が走り
• 結果としてどのログが出たのか
というプロセス全体 が見えるようになります。
結果として、ログを見る時間を削減、根本原因にたどり着くスピードを上げられるという変化が起きました。ログを「読む対象」ではなく、原因へ辿るための入口として扱えるようになったことは、DockerログをNew Relicで一括管理して得られた一番の価値だと考えています。
AIを止めずに回し続けるためのGPU Monitoring
導入は以下のドキュメントに沿って導入し5分足らずで完了(簡単すぎて感動)
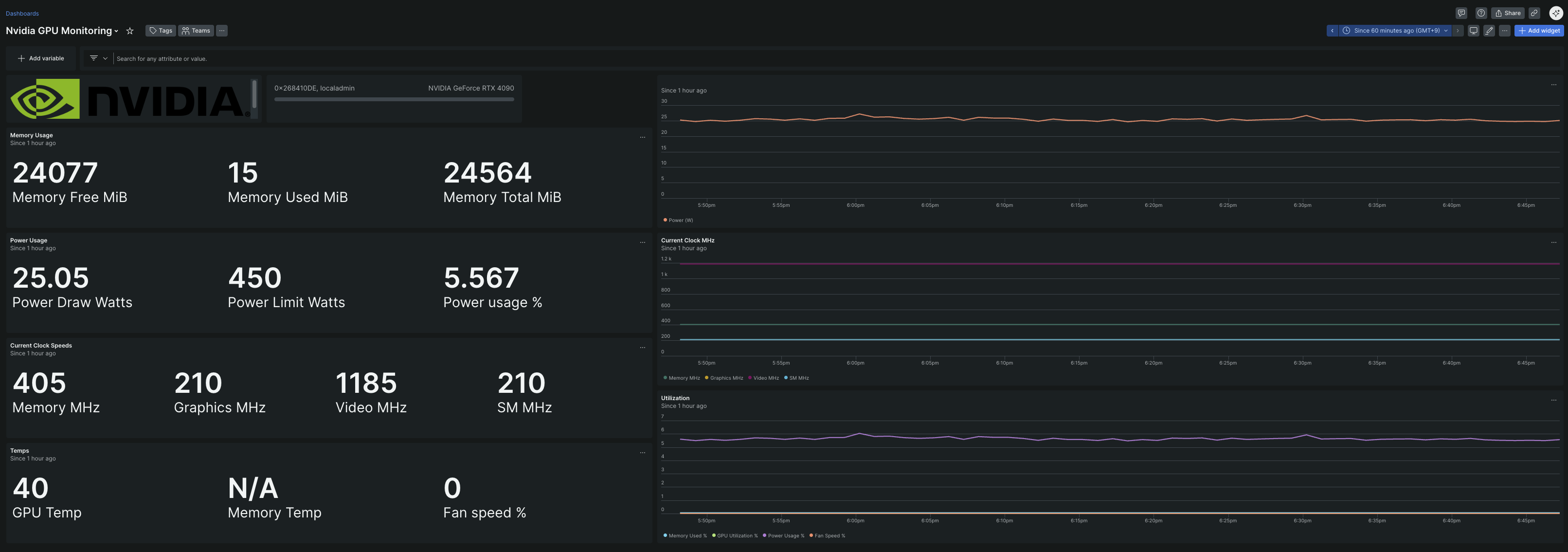
GPU関連では特に、
• 消費電力の監視
• 使用率の異常な張り付き
• メモリ使用量の変化
• エラー発生前後の挙動
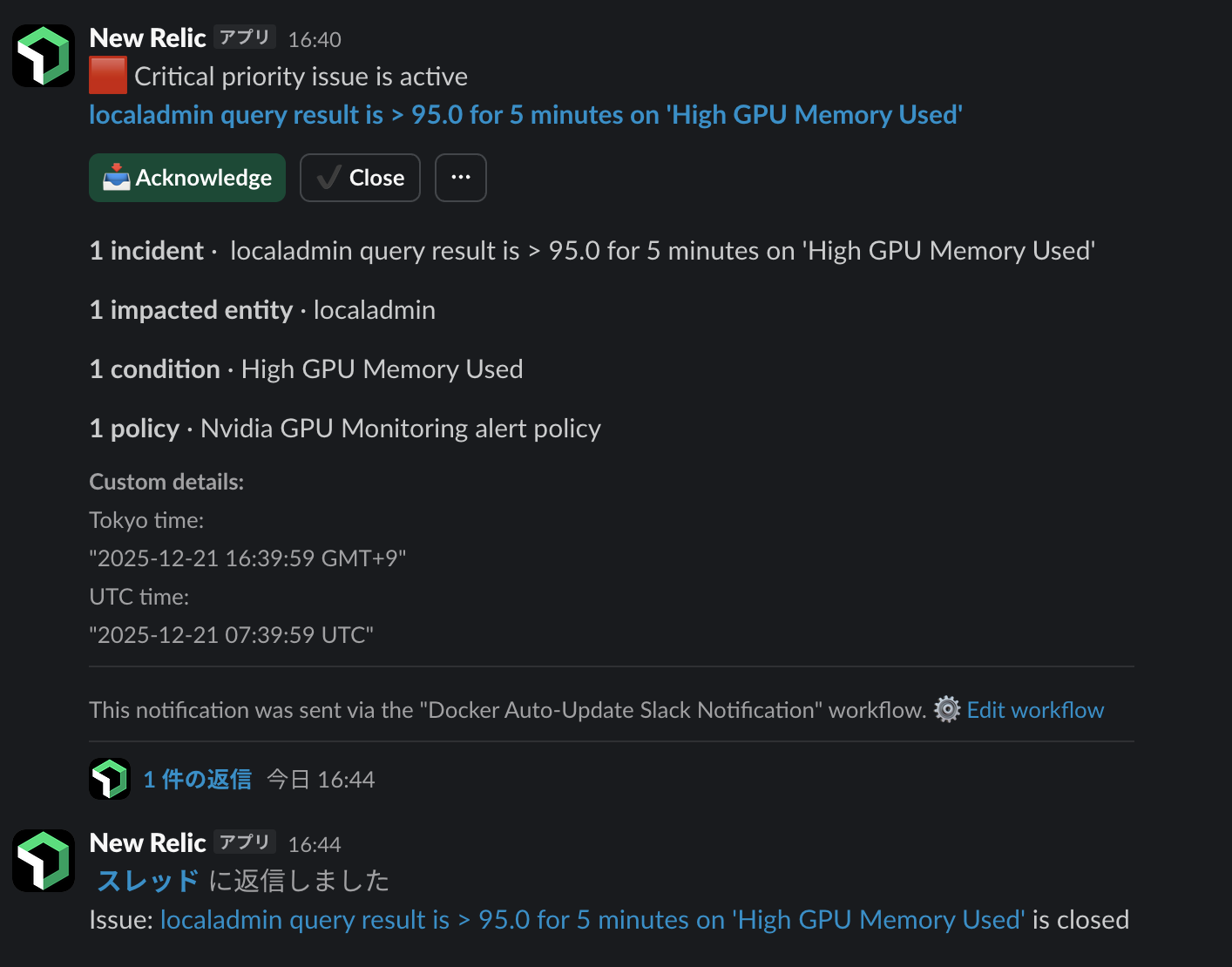
をまとめて把握できるようにしました。さらに、異常が出た場合は Slackに即通知。
ここで初めて、「GPUが計算しているのか、ただ電力を消費しているだけなのか」を、感覚ではなく事実で判断できるようになりました。
#実際のダッシュボード
#Slack通知の様子
障害が起きる前に手を打てるようになった
New Relicを使い始めてから、監視に対する捉え方そのものが大きく変わりました。
以前は、「アラートが飛んだら対応する」 という、いわば事後対応型の運用でした。問題が起きてから気づき、そこから原因を探して対応する、という流れです。
一方で現在は、GPU使用率の張り付きや消費電力の増加傾向、コンテナの挙動が不安定になるといった予兆を見て、問題が顕在化する前に手を打てるようになりました。
そのため対応も慌ただしくなりません。
VPNでGPUサーバに接続し、状況を確認した上でコンテナやGPUプロセスをリセット、必要であれば学習を再開するといった判断を迅速に行えます。
結果として、
• Fine-Tuningが完全に止まってしまう時間を最小化でき
• 無駄なGPU稼働を早い段階で止められ
• 電力消費も必要最小限に抑えられる
ようになりました。
この経験を通して、運用は「問題が起きてから動くもの」ではなく、「起きる前に手を打てるもの」へと変えられるのだと実感しています。
#異常感度閾値の設定例(画像ではCPUに関してThreshold directionをUpper onlyで設定)
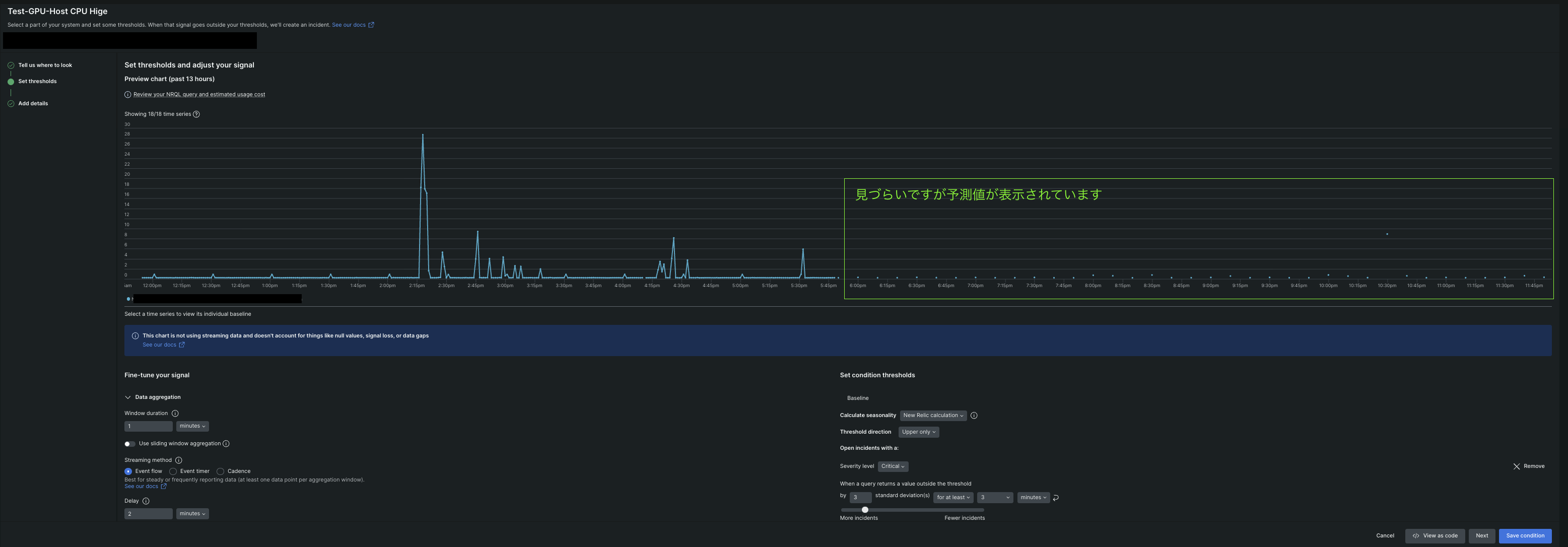
異常感度閾値に関する解説は長くなってしまう為、以下公式ドキュメントをご確認下さい。
まとめ
ローカルLLMxGPU運用で本当に重要だったのは、GPU性能でも、台数でもありません。
「今、何が起きているのかを正しく把握できること」つまりオブザーバビリティでした。
GPUが計算しているのか、止まっているのか。無駄な電力を使っていないか。問題が起きそうな兆候は出ていないか。
これらを 感覚ではなく、事実で判断できる状態 を作れたことで、
• 無駄なコストを止め
• 障害対応を早め
• AIを推論・学習し続けられる運用に近づけた
と感じています。
オブザーバビリティを考えている方にとって、本記事が少しでも参考になれば幸いです。