はじめに
MySQL学習用のテストデータを作成する際の、CSVインポート方法をまとめました。
- MySQL Workbenchでのインポート操作
- Pythonスクリプトでの自動化
今回は、Kaggleの以下のデータセットを使用します。
CSV1行目にカラム名が含まれているため、テーブル定義を事前に作成する必要はありません。
方法1: MySQL Workbenchでインポート
1. スキーマ作成
左側のSCHEMASエリアで右クリック → 「Create Schema...」を選択
スキーマ名: gym_member_info
2. CSVインポート
作成したスキーマを右クリック → 「Table Data Import Wizard」を選択
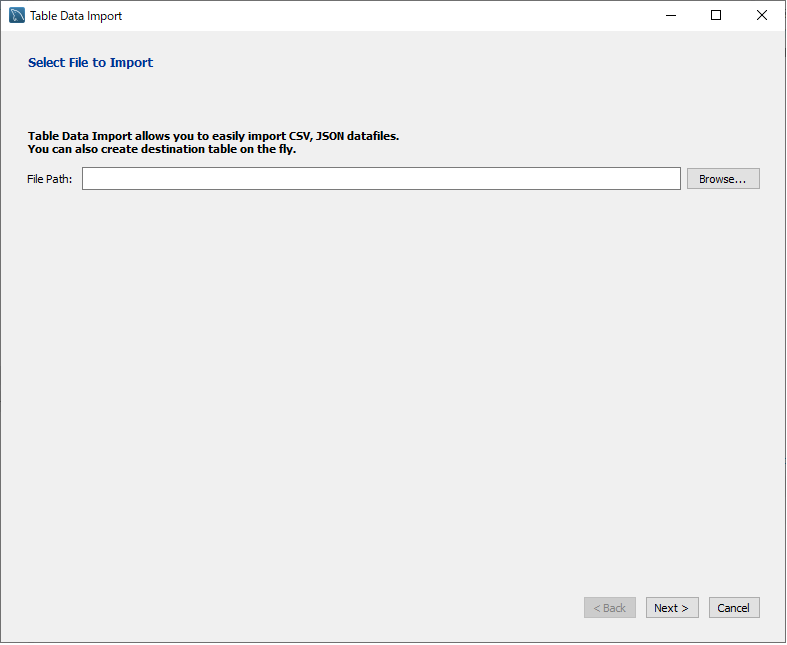
CSVファイルのパスを指定します。
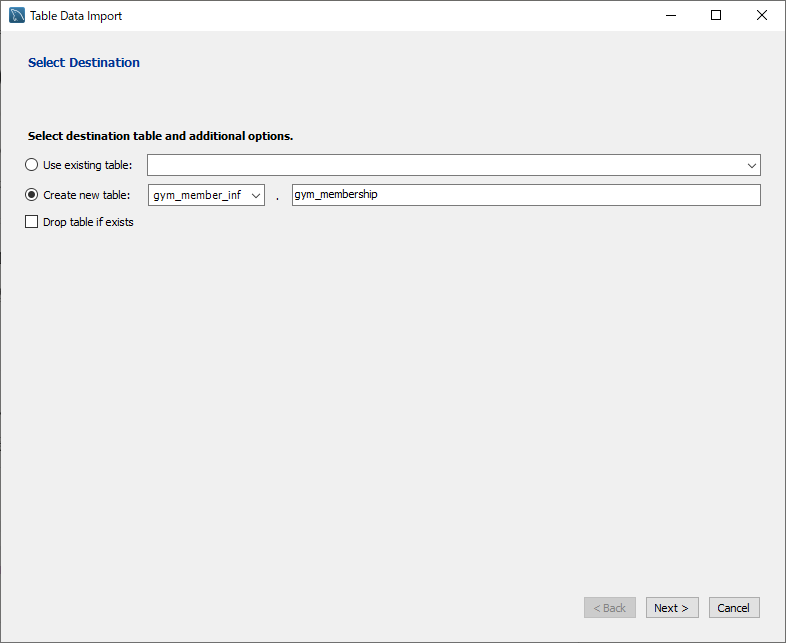
3. テーブル名設定
「Create new table」を選択し、テーブル名を入力
テーブル名: gym_membership
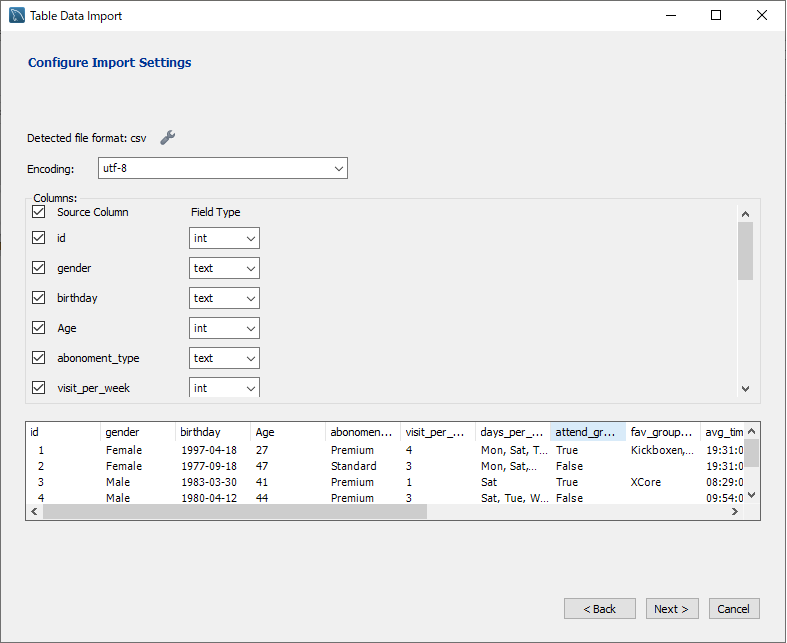
4. カラム定義の確認
データ型が自動判定されます。問題なければ「Next」
5. インポート完了
以下のSQLでデータを確認します。
SELECT * FROM gym_member_info.gym_membership;
方法2: Pythonスクリプトで自動化
複数のCSVファイルを扱う場合や、処理を再現可能にしたい場合はPythonが便利です。
環境準備
必要なライブラリのインストール
pip install pandas sqlalchemy pymysql
インストール確認
pip list
以下のライブラリが表示されればOK
- pandas
- sqlalchemy
- pymysql
各ライブラリの役割
| ライブラリ | 役割 | 主な機能 |
|---|---|---|
| pandas | データ操作 | CSVの読み込み、データ加工、SQLへの書き込み |
| sqlalchemy | DB接続管理 | 統一的なデータベース接続インターフェース |
| pymysql | MySQL通信ドライバ | PythonとMySQLの実際の通信を担当 |
1. pandas の主な機能
CSVファイルの読み込み
df = pd.read_csv(csv_file, encoding='utf-8')
データの確認
len(df) # 行数取得
df.columns.tolist() # カラム名のリスト取得
df.head() # 先頭5行取得
SQLへのデータ書き込み
df.to_sql(name=table_name, con=engine, ...)
この1行でCREATE TABLEとINSERT文を自動実行してくれます。
2. sqlalchemy の主な機能
データベース接続エンジンの作成
from sqlalchemy import create_engine
engine = create_engine(connection_string)
pandasのto_sql()はSQLAlchemyのengineを必要とします。
df.to_sql(con=engine, ...) # ← engineが必要
3. pymysql の役割
接続文字列でドライバを指定
connection_string = f'mysql+pymysql://{username}:{password}@...'
# ↑ pymysqlを使用することを指定
MySQLとの実際の通信プロトコルを提供します。
Pythonスクリプトの実装
ディレクトリ構成
C:\mysql_import\
├── import_csv.py # これから作成するスクリプト
└── gym_membership.csv # インポートするCSVファイル
スクリプト全体
import pandas as pd
from sqlalchemy import create_engine
# ===== 環境に合わせて変更 =====
# CSVファイルのパス
csv_file = 'gym_membership.csv'
# テーブル名
table_name = 'gym_membership'
# MySQL接続情報
username = 'root'
password = 'your_password' # 実際のパスワードに変更
host = 'localhost'
port = 3306
database = 'gym_member_info' # 使用するデータベース名
# ============================
try:
# 1. CSVファイルを読み込む
print(f"CSVファイルを読み込んでいます: {csv_file}")
df = pd.read_csv(csv_file, encoding='utf-8')
# 2. データの確認
print(f"\n✓ 読み込み完了: {len(df)}行, {len(df.columns)}列")
print("\nカラム一覧:")
print(df.columns.tolist())
print("\nデータの先頭5行:")
print(df.head())
# 3. MySQL接続エンジンの作成
print(f"\nMySQLに接続しています...")
connection_string = f'mysql+pymysql://{username}:{password}@{host}:{port}/{database}'
engine = create_engine(connection_string)
# 4. テーブル作成とデータインポート
print(f"\nテーブル '{table_name}' を作成し、データをインポートしています...")
df.to_sql(
name=table_name,
con=engine,
if_exists='replace', # 既存テーブルがあれば置き換え
index=False, # DataFrameのインデックスを含めない
chunksize=1000 # 1000行ずつ分割してインサート
)
print(f"\n✓ 完了しました!")
print(f" テーブル名: {table_name}")
print(f" インポート行数: {len(df)}行")
except FileNotFoundError:
print(f"\n✗ エラー: ファイル '{csv_file}' が見つかりません")
print("CSVファイルがスクリプトと同じフォルダにあるか確認してください")
except Exception as e:
print(f"\n✗ エラーが発生しました: {str(e)}")
print("\n接続情報を確認してください:")
print(f" ユーザー名: {username}")
print(f" ホスト: {host}")
print(f" データベース: {database}")
スクリプトの実行
cd C:\mysql_import
python import_csv.py
実行結果の例
CSVファイルを読み込んでいます: gym_membership.csv
✓ 読み込み完了: 1000行, 8列
カラム一覧:
['member_id', 'name', 'age', 'gender', 'join_date', 'membership_type', 'monthly_fee', 'status']
データの先頭5行:
member_id name age gender join_date membership_type monthly_fee status
0 1 John Smith 28 M 2024-01-15 Premium 5000 Active
...
MySQLに接続しています...
テーブル 'gym_membership' を作成し、データをインポートしています...
✓ 完了しました!
テーブル名: gym_membership
インポート行数: 1000行
まとめ
| 方法 | メリット | デメリット |
|---|---|---|
| Workbench | GUIで直感的、初心者向け | 手動操作、複数ファイルは大変 |
| Python | 自動化可能、再現性が高い、複数ファイル対応 | 初期設定が必要 |
おすすめの使い分け:
- 1〜2個のCSV: Workbenchが簡単
- 複数のCSV: Pythonで自動化
- 定期的にインポート: Pythonスクリプト化