この記事は WESEEK Advent Calendar 2020 23日目の記事です。
はじめに
みなさん、よい Prometheus ライフを過ごしていますか?
GROWI.cloud というサービスでインフラ・バックエンドを担当してる skomma と申します。
GROWI.cloud では GKE(Google Kubernetes Engine) を用いてサービスを構築していますが、サービスを運用する際に必須となる監視の仕組みとして、イマドキな Prometheus + Grafana という構成を選択しました。
しかし、実際に運用するために必要な監視のメトリック、アラートルール設定を実施する際に、実用的かつ汎用的なルールは、ググってもあまり見つかりませんでした。
(おそらく皆さん PromQL を一から勉強する or 公開されている Grafana dashboard の PromQL を参考にしながら、ちょっとずつ自分たちのサービスにあったクエリを書いてると思われます...私もそうでした...)
そこで今回は、運用で使えそうな PromQL クエリ集・小ネタ集を記載してみたいと思います。
本記事の想定環境
- Kubernetes
- Prometheus
- Alertmanager
- kube-state-metrics
- node-exporter
- kube-state-metrics/node-exporter については Prometheus helm chart を利用した場合、デフォルトでインストールされます
- https://github.com/prometheus-community/helm-charts/tree/main/charts/prometheus
- blackbox-exporter
Prometheus の設定/PromQL についての紹介記事
本記事で紹介するコンフィグ、PromQL は以下を参照しながら読むと理解しやすいかもしれません。
-
Prometheus 公式の Configuration
- 何はなくとも公式ドキュメント
- 設定項目に困ったら穴が開くほど見ることになるでしょう
-
Prometheusのrelabel config例
- 初学者にはわかりづらい
relabel_configsの挙動について、一つ一つわかりやすく説明されています
- 初学者にはわかりづらい
-
PromQL事始め
- 公式ではなかなかイメージしづらい複数のクエリの join 例が記載されている貴重な記事です
設定編
Ingress で公開しているサービスの監視を blackbox_exporter で行う
Kubernetes 上に登録されている Ingress で定義されている host に対して、blackbox_exporter で監視を行うという設定です。
Prometheus が持っている Service discovery を使い、scrape_configs のいい感じの練習台になる設定ですね。
- job_name: kubernetes-ingress
# scrape 先の HTTP request path を /probe に設定します
metrics_path: /probe
params:
# scrape 時の HTTP request に module=http2xx というパラメータを付加します
module: [http_2xx]
scrape_interval: 1m
kubernetes_sd_configs:
# クラスタ内の Ingress を scrape 先の source にします
# 利用できるラベルは Prometheus のドキュメントに記載されています
# see: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#ingress
- role: ingress
relabel_configs:
# metadata.annotations 内に prometheus.io/probe: "true" という annotaion が設定されているものだけを抽出する
- action: keep
regex: true
source_labels:
- __meta_kubernetes_ingress_annotation_prometheus_io_probe
# Ingress 内にある情報を用いて blackbox_exporter へのリクエストに含める target パラメータに入れる文字列を生成します
# __meta_kubernetes_ingress_scheme には http/https が、__address__ には .spec.rules.host が、
# __meta_kubernetes_ingress_annotation_prometheus_io_path には annotations 内にある prometheus.io/path の中に設定された文字列が入ってきます
- source_labels: [__meta_kubernetes_ingress_scheme, __address__, __meta_kubernetes_ingress_annotation_prometheus_io_path]
separator: ;
target_label: __param_target
regex: (.+);(.+);(.*)
replacement: ${1}://${2}${3}
# 上記で設定した __param_target に設定した文字列を、instance ラベルにもコピーします
- source_labels: [__param_target]
target_label: instance
# Ingress 内に設定されている metadata.labels 内にある key/value をそのまま Prometheus の時系列(Time series)にコピーしてきます
# ex.) key: value, という labels が設定されていたら Prometheus の時系列にも key: value というラベルが設定されます
- action: labelmap
regex: __meta_kubernetes_ingress_label_(.+)
# Prometheus の scrape 先である __address__ には blackbox_exporter のホスト名/ポートを設定します
- target_label: __address__
replacement: prometheus-blackbox-exporter:9115
上記を Prometheus に設定した状態で、以下のような Ingress をクラスタ上に登録すると、
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
prometheus.io/probe: "true"
prometheus.io/path: /healthz
name: hogehoge
namespace: hogehoge
spec:
rules:
- host: example.com
http:
paths:
- backend:
serviceName: example
servicePort: 80
http://prometheus-blackbox-exporter:9115/probe?module=http_2xx&target=http://example.com/healthz というパスに Prometheus は scrape しに行くようになります。
Prometheus の Targets 画面でも確認できると思います。
Slack で通知するだけ/全く何も行わない Alertmanager receiver/route を用意する
growi.cloud では、Alertmanager 内の route/receiver を以下のように設定して、運用しています。
- アラート用(
alertreceiver)- 条件に合致する時系列が出た時に FIRING メッセージを出す
- 条件に合致する時系列がなくなったときに RESOLVED メッセージを出す
-
send_resolved: trueを設定しているので、合致する時系列がなくなったときにもメッセージが出ます
-
- 以下の 2 つで指定されているラベルが設定されていないアラートは、全部この receiver にやってきます
- ただし、
severity: warningラベルがついているアラートだけはrepeat_invervalを長めに設定して、アラートが多量に出るのを避けています
- ただし、
- 通知用(
notify-onlyreceiver)- 条件に合致する時系列が出た時にメッセージを出す
-
send_resolved: trueを設定していないため、合致する時系列がなくなったときのメッセージは出ません - まさに通知向きですね
-
-
notify: onlyラベルがついているアラートは、この receiver にやってきます - 以下の設定では、
alertreceiver と Slack の通知先チャンネルを分けています
- 条件に合致する時系列が出た時にメッセージを出す
- 何もしない用(
no-notifyreceiver)- 通知に関する
slack_configsを一切設定していない receiver です - 後ほど解説する
非営業日はアラートを出さないで利用します。 -
notify: falseラベルがついているアラートは、この receiver にやってきます
- 通知に関する
receivers:
- name: alert
slack_configs:
- channel: '#example-alert'
send_resolved: true
text: |-
{{ range .Alerts -}}
{{ if eq .Status `firing` }}{{ .Annotations.firing_text }}
{{ else }}{{ .Annotations.resolved_text }}
{{ end -}}
{{ end -}}
title: |-
{{ range .Alerts -}}
{{ if eq .Status `firing` }}[FIRING] {{.Annotations.firing_summary}}
{{ else }}[RESOLVED] {{.Annotations.resolved_summary}}
{{ end -}}
{{ end -}}
username: Alertmanager
- name: notify-only
slack_configs:
- channel: '#example-notify'
color: warning
send_resolved: false
text: |-
{{ range .Alerts -}}
{{ .Annotations.firing_text }}
{{ end -}}
title: |-
{{ range .Alerts -}}
{{ .Annotations.firing_summary }}
{{ end -}}
username: Alertmanager
- name: no-notify
route:
group_by:
- alertname
- instance
group_interval: 2m
group_wait: 1m
receiver: alert
repeat_interval: 30m
routes:
- match:
notify: "false"
receiver: no-notify
- group_by:
- alertname
group_wait: 0s # send notify immediately
match:
notify: only
receiver: notify-only
- match:
severity: warning
repeat_interval: 1d
routes:
- group_by:
- alertname
- instance
- mountpoint
match_re:
alertname: filesystem_free_space_less.*
非営業日はアラートを出さない
Prometheus + Alertmanager だけで実現しようと考え、編み出した技です。
それ以外のプロダクト、PagerDuty などの外部サービスを利用した場合は、アラートを送る時間帯を指定できる機能が搭載されているので、それを利用するべきです。()
ちなみに、以下のルールの合わせ技です。
- Prometheus の recording rules
- Prometheus の alerting rules
- Alertmanager の inhibit rules
recording rules
recording rules とは、 Prometheus が scrape した時系列から、PromQL を書くことによって別の時系列を作り出し、TSDB へ保存することができる機能です。
まず、Prometheus ビルトインで現在日時を返す time() は UTC で値が取得できるので、以下のように日本時間を表す時系列を作り出します。
groups:
- name: recording.rules
rules:
- record: jst_time_vector
# adjust UTC to JST(UTC + 9)
expr: vector(time() + 3600 * 9)
alerting rules
次に、営業時間外でアラートが出るようなアラートルールを設定します。
月曜から金曜の 22:00 - 8:00、土曜と日曜の全日に出るアラートです。が、前述の route/receiver 設定で記載されている notify: false をラベルにつけておくことによって、実際にアラートとして通知されることはありません。
Prometheus -> Alertmanager へのアラートリクエストは出ますが、Alertmanager からその先のアラートが出ないようなルールとなります。
- alert: not_business_days
# Mon-Fri 22:00-8:00 / Sat,Sun all day
expr: (day_of_week(jst_time_vector) + 6) % 7 >= 5 or hour(jst_time_vector) < 8 or hour(jst_time_vector) >= 22
labels:
notify: "false"
※このルールをベースに、day_of_month() month() を組み合わせれば、祝日も書けるかも…()
inhibit rules
inhibit rules とは Alertmanager の機能で、あるアラート A が発出している間はアラート B はアラートとして処理しない、inhibit(禁止)できる機能です。
以下のように設定すると、上述の not_business_days というアラートが出たときに、target_match にヒットするアラートを inhibit することができます。以下の設定では、severity: warning ラベルがついているアラートは営業時間(8:00-22:00)以外に通知が出なくなります。
- source_match:
alertname: not_business_days
target_match:
severity: warning
PromQL クエリ編
Node の再起動を検知する
クエリ
changes((
label_join(max by (kubernetes_node)(node_boot_time_seconds), "instance", "", "kubernetes_node")
)[15m:])
* on(instance) group_left(gitVersion) kubernetes_build_info{cloud_google_com_gke_preemptible=""}
> 0
利用する metrics
-
node_boot_time_seconds- node_exporter が出す各 Node の起動時間(UTC)
-
kubernetes_build_info- metrics-server が出す node に関する metric
- 今回のクエリでは、Node で稼働する Kubernetes のバージョン(
gitVersion)ラベルを取得するために利用します - prometheus helm chart でインストールするとデフォルトで追加される
kubernetes-nodesjob により scrape されます
クエリ解説
changes((
label_join(max by (kubernetes_node)(node_boot_time_seconds), "instance", "", "kubernetes_node")
)[15m:])
node_boot_time_seconds は起動時間を示すものなので、Node が再起動すると必ず値が変わります。
その metric の特性を利用して、Prometheus で指定された range (上記クエリでは [15m:]) の中で変化する値を changes 関数を使って絞り込みます。
max by (kubernetes_node)(node_boot_time_seconds) に関しては、同じ Node 名であっても一度再起動が発生するとラベルの一部が変わり、同じ時系列として扱われなくなるため、Node 名で同じ時系列とみなせるように max 関数で集約しています。
以下は、ある Node に関する時系列ですが、instance だけ変わっていることが確認できると思います。
node_boot_time_seconds{app="prometheus",chart="prometheus-11.16.9",component="node-exporter",heritage="Tiller",instance="10.146.0.26:9100",job="kubernetes-service-endpoints",kubernetes_name="growi-prometheus-node-exporter",kubernetes_namespace="growi-cloud",kubernetes_node="gke-example-prod-example-d06b4993-k3r6",release="growi-prometheus"}
node_boot_time_seconds{app="prometheus",chart="prometheus-11.16.9",component="node-exporter",heritage="Tiller",instance="10.146.0.25:9100",job="kubernetes-service-endpoints",kubernetes_name="growi-prometheus-node-exporter",kubernetes_namespace="growi-cloud",kubernetes_node="gke-example-prod-example-d06b4993-k3r6",release="growi-prometheus"}
max 関数を通すと、上記の時系列は {kubernetes_node="gke-example-prod-example-d06b4993-k3r6"} という一つの時系列に統一されます。
label_join(..., "instance", "", "kubernetes_node") は kubernetes_build_info metric で Node 名を表すラベルが instance であるため、kubernetes_node ラベルの内容を label_join 関数を用いて instance にコピーしています。
* on(instance) group_left(gitVersion) kubernetes_build_info{cloud_google_com_gke_preemptible=""}
> 0
max, label_join, changes を通してできた時系列に対して、Node 名で kubernetes_build_info metric と join するために、* on(instance) としています。
kubernetes_build_info は必ず 1 となる時系列のため * で join し、group_left(gitVersion) で kubernetes_build_info metric 内にある gitVersion ラベルを取り出しています。
また、GKE では preemptible node を利用すると、Node リソースに cloud.google.com/gke-preemptible: true というラベルが付加されるため、{cloud_google_com_gke_preemptible=""} のラベル指定で、preemptible ではない Node に関してのみ抽出しています。
クエリにより抽出される時系列は結果的に以下のような形になります。
{gitVersion="v1.17.XX-gke.XXX",instance="gke-example-prod-example-760d52ef-mv8b",kubernetes_node="gke-example-prod-example-760d52ef-mv8b"}
preemptible node に対して上記のクエリを実行すると、以下のように再起動時に値が 1 になっている様子が見て取れると思います。

Alertmanager による通知設定例
- alert: preemptible_node_restarted
annotations:
firing_summary: Node {{ $labels.instance }} RESTARTED
firing_text: '{{ $labels.instance }} is now restarted. (ver: {{ $labels.gitVersion }})'
expr: |
changes((
label_join(max by (kubernetes_node)(node_boot_time_seconds), "instance", "", "kubernetes_node")
)[15m:])
* on(instance) group_left(gitVersion) kubernetes_build_info{cloud_google_com_gke_preemptible="true"}
> 0
labels:
notify: only
severity: warning
前述の Alertmanager 設定と組み合わせて、このようなアラートルールを登録しておくと、Node が再起動した際に Slack 上の #example-notify にメッセージが通知されると思います。
Preemptible node が最後に再起動した時間/再起動回数を出す(GKE)
クエリ
- 最後に再起動した時間
label_join(max by (node)(kube_node_labels{label_cloud_google_com_gke_preemptible="true"}), "kubernetes_node", "", "node") * on (kubernetes_node) max by (kubernetes_node)(node_boot_time_seconds) - 再起動回数(直近 1 日)
changes(( label_join(max by (node)(kube_node_labels{label_cloud_google_com_gke_preemptible="true"}), "kubernetes_node", "", "node") * on (kubernetes_node) max by (kubernetes_node)(node_boot_time_seconds) )[1d:])-
[1d:]の部分を[$__range:]に直すと、Grafana では Dashboard 上での範囲指定でのクエリ実行ができるようになります
-
利用する metrics
-
node_boot_time_seconds-
Node の再起動を検知すると同様なので省略
-
-
kube_node_labels- Kubernetes Node リソースに付加されているラベルを、Prometheus のラベル情報として取り出せる metric
-
nodeラベルに Node 名が入ります
クエリ解説
最後に再起動した時間のクエリに関しては、以下のような操作を行っています。
- preemptible node かどうかを
kube_node_labels{label_cloud_google_com_gke_preemptible="true"}で絞る -
max by (node)(kube_node_labels{label_cloud_google_com_gke_preemptible="true"})で、再起動前後の同 Node に関する時系列をまとめる -
label_join(..., "kubernetes_node", "", "node")でnodeラベルをkubernetes_nodeにコピーします-
node_boot_time_secondsと join するため
-
-
* on (kubernetes_node) max by (kubernetes_node)(node_boot_time_seconds)でkubernetes_nodeをキーにして join します
以下のようなグラフになります。
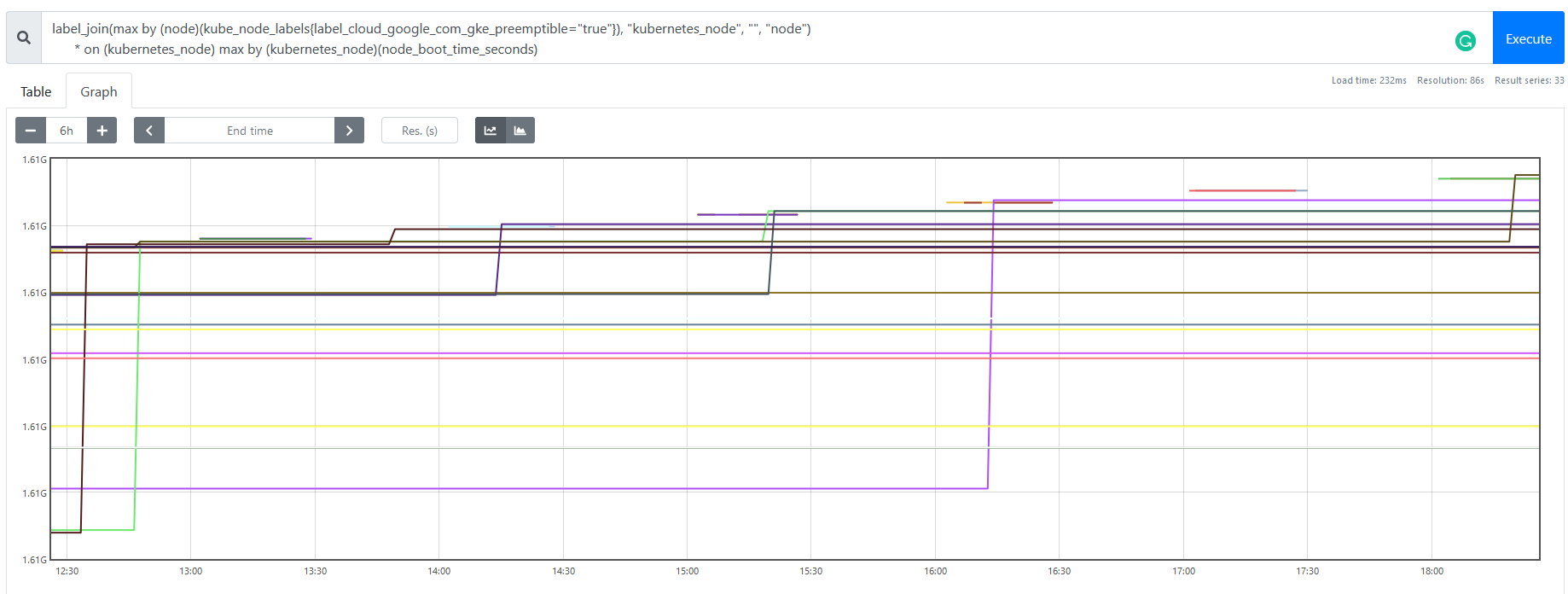
instant vector として直近の結果だけを取ると、最後に再起動した時間を取得できます。
再起動回数のクエリに関しては、上記の結果に対してさらに以下の操作を追加で行っています。
-
changes((...)[1d:])で、上記 4. までの結果の直近 1 日の範囲での変化数を取得します- これが直近 1 日での再起動回数になります
以下のようなグラフになります。
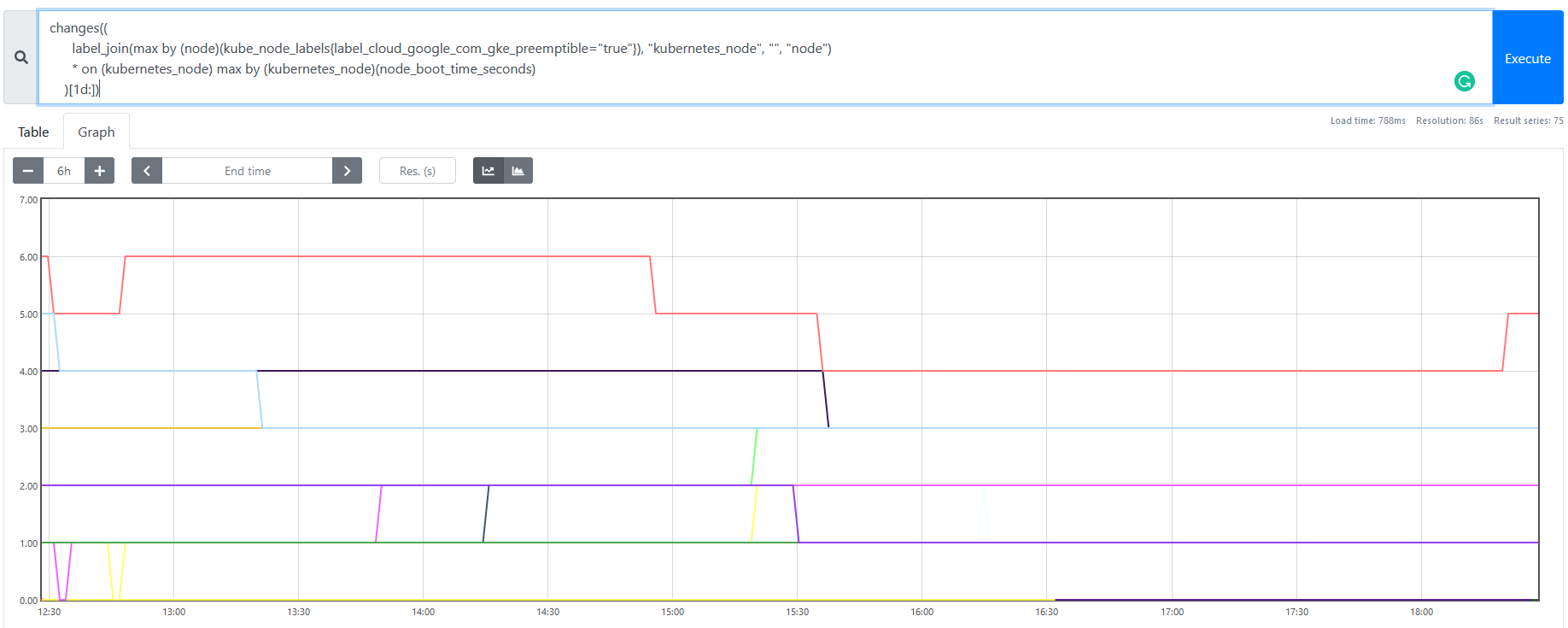
instant vector として直近の結果だけを取ると、直近 1 日での再起動回数を取得できます。
Preemptible node の最長稼働時間、最短稼働時間を出す(GKE)
クエリ
- 最長稼働時間(直近 1 日)
max_over_time(( time() - label_join(max by (node)(kube_node_labels{label_cloud_google_com_gke_preemptible="true"}), "kubernetes_node", "", "node") * on (kubernetes_node) max by (kubernetes_node)(node_boot_time_seconds) )[1d:]) - 最短稼働時間(直近 1 日)
min_over_time(( time() - ( label_join(max by (node)(kube_node_labels{label_cloud_google_com_gke_preemptible="true"}), "kubernetes_node", "", "node") * on (kubernetes_node) min by (kubernetes_node)(node_boot_time_seconds offset 2m) != on (kubernetes_node) min by (kubernetes_node)(node_boot_time_seconds) ) )[1d:])
利用する metrics
kube_node_labels と node_boot_time_seconds だけなので省略します。
クエリ解説
最長稼働時間のクエリに関しては、以下のような操作を行っています。
-
label_join(...) * on (kubernetes_node) ...の部分に関しては、最後に再起動した時間と同一です -
time()で取得した現在日時から引くことで、そのときの稼働時間を得ます -
max_over_time((...)[1d:])を入れることで、直近 1 日での最長稼働時間を得ます
以下のようなグラフになります。
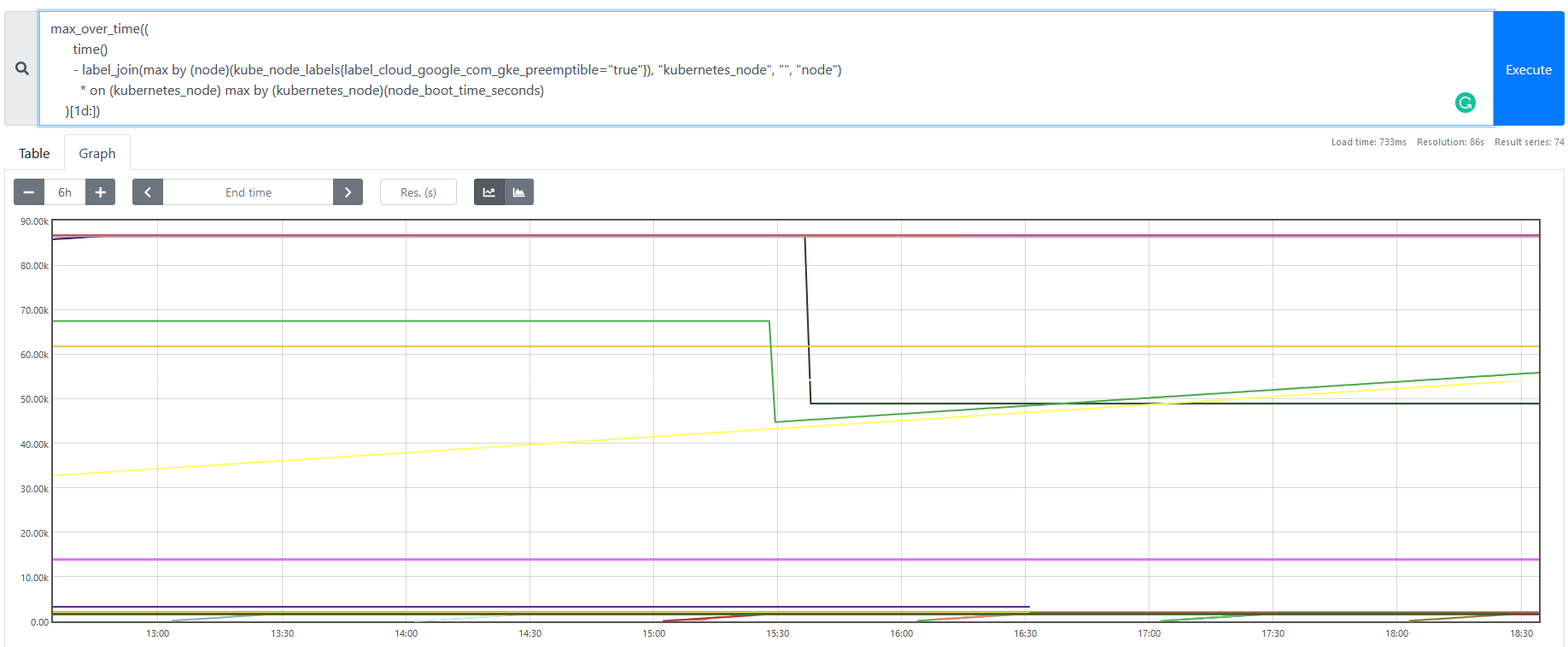
instant vector として直近の結果だけを取ると、その時点での最長稼働時間を取得できます。
上記のグラフで同じ値を指している時間帯は、直近 1 日で preemptible node の最長時間(1 日 = 86400 秒)まで稼働し続けられた Node となり、右肩上がりしている時間帯は、Node が再起動してから稼動し続ければし続けるほど直近 1 日での最大稼働時間が伸びている、という状態を示しています。
最短稼働時間のクエリに関しては、以下のような操作を行っています。
-
label_join(...)の部分に関しては、最後に再起動した時間と同一です -
* on (kubernetes_node) min by (kubernetes_node)(node_boot_time_seconds offset 2m) != on (kubernetes_node) min by (kubernetes_node)(node_boot_time_seconds)の部分に関しては、再起動する直前の起動時間のみを取得し、kubernetes_nodeラベルで join します -
time()で取得した現在日時から引くことで、そのときの稼働時間を得ます -
min_over_time((...)[1d:])を入れることで、直近 1 日での最短稼働時間を得ます-
- で再起動する直前の起動時間だけを取得することによって、
min_over_timeで最小稼働時間を取得できるようになります
- で再起動する直前の起動時間だけを取得することによって、
- 最長稼働時間と同様にすべての稼働時間を範囲にしてしまうと、max も min も結果が変わらなくなります
-
以下のようなグラフになります。
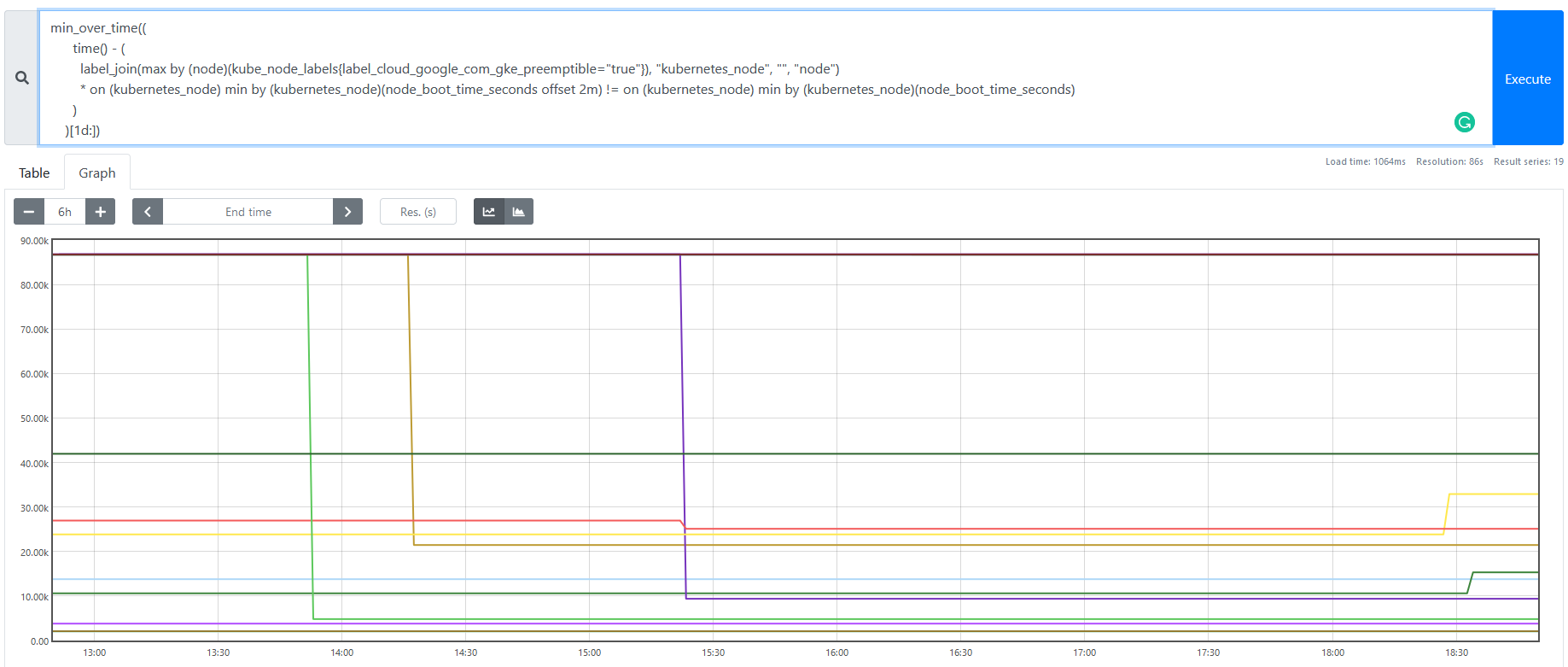
instant vector として直近の結果だけを取ると、その時点での最短稼働時間を取得できます。
上記のグラフで値が変化している時間帯は、直近 1 日で preemptible node の最短稼働時間が変化した Node となります。最長稼働時間のグラフと異なり、再起動する直前の起動時間のみを取得しているため、右肩上がりの時系列は出てきません。
小ネタの中の小ネタクエリ
小ネタなのでクエリのみで。
PV の容量/inode 使用率を出す
max(kubelet_volume_stats_available_bytes / kubelet_volume_stats_capacity_bytes) by (namespace, persistentvolumeclaim)
max(kubelet_volume_stats_inodes_free / kubelet_volume_stats_inodes) by (namespace,persistentvolumeclaim)
ストレージ使用率アラートは、サービスを運用していく上で必須のアラートですね。
Service の Endpoint 数を出す
max by (endpoint)(kube_endpoint_address_available)
Service で指定した selector に紐づく ready Pod の数をチェックできるので、障害が発生したときにどのサービスが unhealthy になったのか確認するために役立ちます。
Node の追加・削除を出す
kubernetes_build_info unless on (instance) kubernetes_build_info offset 5m
kubernetes_build_info offset 5m unless on (instance) kubernetes_build_info
unless join を利用して、5 分前まで存在しなかった時系列を検出することで Node 追加を検知し、5 分前までは存在していたが今は存在していない時系列を検出することで Node 削除を検知できます。
GKE で自動スケーリングを有効にしているときに、どのタイミングで Node が追加・削除されたのかを確認するために役立ちます。
まとめ
いかがでしたでしょうか。
今まで Web ではあまり引っかからなかった実用的(?)かつ汎用的な小ネタ集だったのではないでしょうか。
以上のように Prometheus は数式で書ければ、アラート・通知も自由自在に操れます。
(もちろん全部 Prometheus にやらせるのは不適だろうとか、多少の無理やり感は承知しています)
今まで Prometheus を触ったことがない人のためにも、Prometheus でサービスを監視中だよという人のためにも、お役に立ててもらえると幸いです。
※この記事は WESEEK Tips wiki に 2020/12/23 に投稿された記事の転載です。
Tips wiki では、IT企業の技術的な情報やプロジェクトの情報を公開可能な範囲で公開しています。