はじめに
この記事は Prometheus の QUERING PROMETHEUS に書かれた内容を日本語訳したものと、Prometheus 入門の内容と、実際に試した内容に基づいて補足したものです。
より実践的な例は Kubernetes(GKE) で便利な Prometheus 小ネタ集 に紹介されています。
PromQL とは
PromQL(Prometheus Query Language) は Prometheus の時系列データを取得・集約するクエリ言語です。
クエリの結果は Prometheus の式ブラウザで表形式で表示したり、グラフ表示したりできます。
Grafana のようなグラフ描画ツールにてグラフ表示する時にも、Prometheus に対して問い合わせる際に使われるクエリ言語です。
メトリック
Prometheus が参照する時系列データはメトリックと呼びます。
例えばメモリ使用量を表す process_resident_memory_bytes などがメトリックです。
一般的に、あるメトリックに対して複数の時系列データが存在します。
例えば、メトリック process_resident_memory_bytes には Prometheus のメモリ使用量と、そのホストのメモリ使用量の 2 つの時系列データがあるといった具合です。
データタイプ
PromQL が取り扱うデータには次のタイプが存在します。
- Instant vector
- Range vector
- Scalar
- String
Instant vector はメモリ使用量のような、ある時系列データです。
Range vector はある時点から過去の期間における instant vector の値が集まったデータです。
Scalar, String は 1, "string" のような時系列ではない単純な値を指します。
グラフ表示できるのは Instant vector であり、その他のデータタイプは、値を算術したり、一定の期間で値を集約したりするときに使われます。
時系列データのセレクタ
メトリック
最も単純なセレクタ形式は メトリック名 を使うものです。
例えば process_resident_memory_bytes は、メモリ使用量(process_resident_memory_bytes) のメトリックを持つ全 instant vector が選択されます。
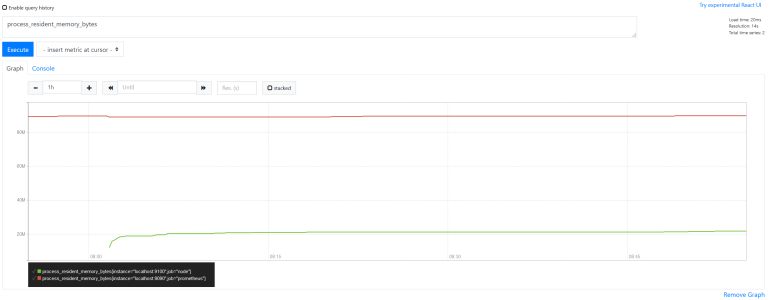
上は Prometheus の式ブラウザで process_resident_memory_bytes をグラフ表示した結果で、{instance="localhost:9100",job="node"} と {instance="localhost:9090",job="prometheus"} のラベルを持つ 2 つの instant vector が選択されていることが分かります。
ラベルマッチャ(基本)
メトリックをラベルでフィルタするものをラベルマッチャと呼びます。
例えば、Prometheus プロセス(job="prometheus")と、そのホスト(job="node")の 2 つのメモリ使用量をスクレイプしている場合、 process_resident_memory_bytes{job="node"} とするとホストだけのメモリ使用量が取得できます。
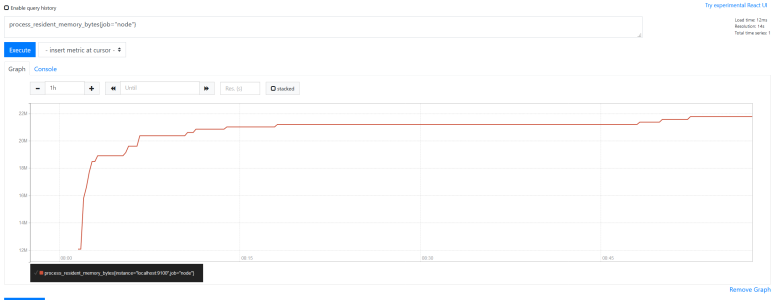
この例における {job="node"} がラベルマッチャです。
ラベルの job が "node" と完全一致するデータのみがフィルタ出来ます。
{job=~"n.*"} のように正規表現を使うこともできます。
| オペレータ | 説明 |
|---|---|
| = | 指定した文字列と完全一致するラベルを選択する |
| != | 指定した文字列と異なるラベルを選択する |
| =~ | 指定した正規表現に合致するラベルを選択する |
| !~ | 指定した正規表現に合致しないラベルを選択する |
ここで、例えば hoge="" を指定した場合、ラベル hoge が存在しない時系列データがすべて選択されます。
ラベルマッチャ(応用)
ラベルマッチャはメトリック名に対しても適用できます。
メトリック名は内部で __name__ ラベルが付与されているため、このラベルに対してマッチャを指定すると複数のメトリックが選択できます。
例えば {__name__=~".*_count"} とすると、末尾に _count がつく複数のメトリックを選択できます。
無効なセレクタ
時系列データのセレクタは、メトリック名 または空にマッチしないラベルセレクタを指定する必要があります。
そのため、メトリック名を指定せず {job=~".*"} や {hoge=""} とした場合は、式ブラウザでエラーが表示されます。
Error executing query: Y:X: parse error: vector selector must contain at least one non-empty matcher
Range vector セレクタ
Range vector はある時点から過去の期間における instant vector の値が集まったデータです。
この期間は [1m] のように示し、これが Range vector セレクタです。
使える単位は次のとおりです。
-
s- seconds -
m- minutes -
h- hours -
d- days -
w- weeks -
y- years
例えば、 process_resident_memory_bytes[1m] を式ブラウザで表示すると次のデータが表示されます。
(Range vector はグラフ表示できないため、Console タブで確認する必要があります)
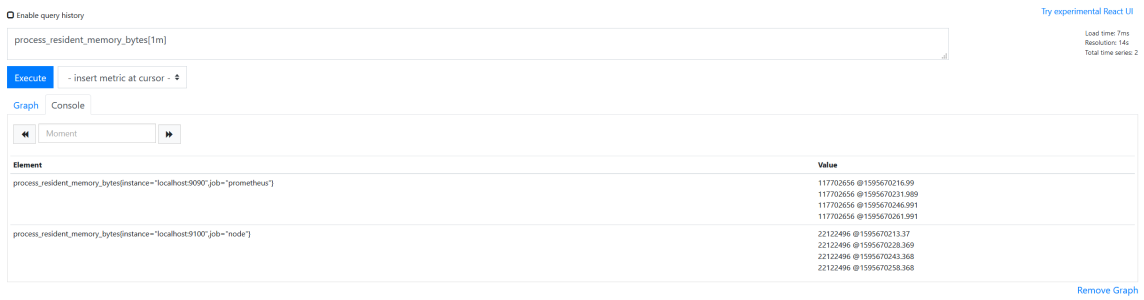
| Element | Value |
|---|---|
| process_resident_memory_bytes{instance="localhost:9090",job="prometheus"} | 117702656 @1595670216.99 117702656 @1595670231.989 117702656 @1595670246.991 117702656 @1595670261.991 |
| process_resident_memory_bytes{instance="localhost:9100",job="node"} | 22122496 @1595670213.37 22122496 @1595670228.369 22122496 @1595670243.368 22122496 @1595670258.368 |
Value に ~@1595670216.99 が付いていることが分かります。
Range vector では Value は Value @ Valueがスクレイプされた時刻 という形式になります。
Value が 4 つあるのは、スクレイプ間隔が 15s に設定されているため、1m の間に 4 回値が取得されていることを指します。
Range vector の使い道は、例えば 1h における平均メモリ使用量を知る場合などです。
※ 詳細は Range vector の集約関数 を参照してください
オフセット修飾子
オフセット修飾子は、Instant vector や Range vector の時刻を指定した分だけ過去にずらす修飾子です。
<instant_query / sub_query> offset <duration>
例えば process_resident_memory_bytes offset 1m とすると 1m 前の process_resident_memory_bytes の値が現在時刻のように表示されます。
グラフを見ると、offset を指定しなかった場合に対して、offset を指定すると右に 1m 分ずれます。
つまり、時系列データの各時刻に offset で指定した値が足されているイメージです。
オフセット修飾子の使い道は、プロセスの再起動が発生したことを知るために、過去と現在のプロセス起動時刻を比較する場合などです。
※ 詳細は Examples を参照してください
サブクエリ
サブクエリは instant vector を返すクエリに付与することで、指定した期間の指定した分解能(レゾリューション)で Range vector へ変換するクエリです。
<instant_query> '[' <range> ':' [<resolution>] ']' [ offset <duration> ]
サブクエリの使い道は、プロセスの再起動が過去1dの間で何回発生したのか知る場合などです。
※ 詳細は Examples を参照してください
コメント
PromQL はコメントをサポートしています。
# This is a comment
オペレータ
算術演算子
-
+(addition) -
-(subtraction) -
*(multiplication) -
/(division) -
%(modulo) -
^(power/exponentiation)
これらの演算子は左辺と右辺のデータタイプにより挙動が変わります。
- 両辺が scalar の場合の挙動(
<scalar> <arithmetic_binary_operator> <scalar>) - 一辺が instant vector、もう一辺が scalar の場合の挙動(
<instant_vector> <arithmetic_binary_operator> <scalar>) - 両辺が instant vector の場合の挙動(
<instant_vector> <arithmetic_binary_operator> <instant_vector>)
両辺が scalar の場合の挙動
2 つの Scalar の値に対して算術が行われます。
例えば 1 + 1 = 2 です。
一辺が instant vector、もう一辺が scalar の場合の挙動
instant vector のすべての時刻における値に対して scalar の値が算術されます。
例えば process_resident_memory_bytes / 1000 とすると、メモリ使用量の単位が bytes ではなく KB となります。
両辺が instant vector の場合の挙動
左辺の各時系列データにおいて、右辺とマッチする要素に対して算術が行われます。
結果となる時系列データからはメトリック名は削除され、算術時のグループ化に使用したラベルが結果に付与されます。
例えば、node_filesystem_avail_bytes * 100 / node_filesystem_size_bytes とすると、ディスク使用率が計算できます。
比較演算子
-
==(equal) -
!=(not-equal) -
>(greater-than) -
<(less-than) -
>=(greater-or-equal) -
<=(less-or-equal)
これらの演算子は左辺と右辺のデータタイプにより挙動が変わります。
- 両辺が scalar の場合の挙動(
<scalar> <arithmetic_binary_operator> <scalar>) - 一辺が instant vector、もう一辺が scalar の場合の挙動(
<instant_vector> <arithmetic_binary_operator> <scalar>) - 両辺が instant vector の場合の挙動(
<instant_vector> <arithmetic_binary_operator> <instant_vector>)
いずれの場合も、基本的な挙動はフィルタリングですが、比較演算子の後ろに bool を付けることで値が 0 か 1 になります。
(比較した結果が false の場合は 0、true の場合は 1 です)
<comparison_binary_operator> [bool]
両辺が scalar の場合の挙動
bool を付けることが必須です。
例えば 1 == bool 1 は 1 となり、1 != bool 1 は 0 となります。
一辺が instant vector、もう一辺が scalar の場合の挙動
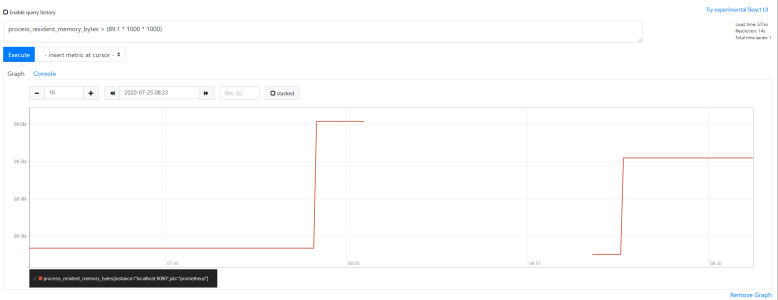
instant vector のすべての時刻における値に対して比較が行われ、真となった値だけ残り、偽となった値は削除されます。
例えば、process_resident_memory_bytes > (89.1 * 1000 * 1000) とした場合、メモリ使用量が 89.1MB より大きかった時点だけフィルタされます。
両辺が instant vector の場合の挙動
Vector マッチング におけるマッチングされた要素に対して比較が行われます。
論理演算子 / 集合演算子
- and (intersection)
- or (union)
- unless (complement)
これらの演算子は instant vector 間でのみ使用できます。
<instant_vector1> and <instant_vector2> の結果は instant_vector1 の要素のうち、instant_vector2 の要素とラベルセットが完全に一致するもののみが残ります。
この時、メトリック名と値は instant_vector1 のものが残ります。
<instant_vector1> or <instant_vector2> の結果は instant_vector1 の全要素に加えて、instant_vector2 の要素のうち、instant_vector1 に一致するラベルセットを持たない要素から構成されます。
<instant_vector1> unless <instant_vector2> の結果は instant_vector1 の要素から、instant_vector2 の要素とラベルセットが一致するものが削除されたものです。
Vector マッチング におけるマッチングされた要素に対して比較が行われます。
Vector マッチング
2つの Vector に対する演算は、右辺の要素とマッチする左辺の要素を探します。
マッチングには、「1対1」と「N対1 / 1対N」の2つの挙動があります。
1対1
1対1では、全ラベルに対してラベルマッチングが行われて一致するものがマッチされます。
ラベルリストを on で限定すること、ignoring で無視することができます。
<vector expr> <bin-op> ignoring(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) <vector expr>
※ 詳細は Examples を参照してください
N対1 / 1対N
N対1 / 1対N では、あるラベルをグループ化し、それ以外の全ラベルに対してラベルマッチングが行われて一致するものがマッチされます。
<vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_right(<label list>) <vector expr>
※ 詳細は Examples を参照してください
集約修飾子
-
sum(calculate sum over dimensions) -
min(select minimum over dimensions) -
max(select maximum over dimensions) -
avg(calculate the average over dimensions) -
group(all values in the resulting vector are 1) -
stddev(calculate population standard deviation over dimensions) -
stdvar(calculate population standard variance over dimensions) -
count(count number of elements in the vector) -
count_values(count number of elements with the same value) -
bottomk(smallest k elements by sample value) -
topk(largest k elements by sample value) -
quantile(calculate φ-quantile (0 ≤ φ ≤ 1) over dimensions)
これらの修飾子は instant vector に対してのみ適用されます。
by, without を指定しない場合、結果からすべてのラベルが失われます。
by は指定したラベルでラベルフィルタされた要素に対して、それぞれ集約を行います。
without は指定したラベル以外のラベルでフィルタされた要素に対して、それぞれ集約を行います。
<aggr-op> [without|by (<label list>)] ([parameter,] <vector expression>)
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
関数
instant vector, range vector, scalar に対して処理を行う関数が定義されています。
関数一覧はこちらを参照してください。
算術系関数
| 関数名 | 書式 | 説明 |
|---|---|---|
| abs() | abs(v instant-vector) | 全ての値を絶対値に変える |
| ceil() | ceil(v instant-vector) | 全ての値を、より大きく最も近い整数に変える |
| floor() | floor(v instant-vector) | 全ての値を、より小さく最も近い整数に変える |
| round() | round(v instant-vector, to_nearest=1 scalar) | 全ての値を最も近い数値に変える。近さが等しい場合は大きい方になる。to_nearestを指定すると、その値の倍数で丸められる。 |
| clamp_max() | clamp_max(v instant-vector, max scalar) | max より大きい値を削除する |
| clamp_min() | clamp_min(v instant-vector, min scalar) | min より小さい値を削除する |
| ln() | ln(v instant-vector) | 全ての値の自然対数を計算する |
| log2() | log2(v instant-vector) | 全ての値の 2 進対数を計算する |
| log10() | log10(v instant-vector) | 全ての値の 10 進対数を計算する |
| exp() | exp(v instant-vector) | 全ての値の指数関数を計算する |
| sqrt() | sqrt(v instant-vector) | 全ての値の平方根を計算する |
解析関数
| 関数名 | 書式 | 説明 |
|---|---|---|
| delta() | delta(v range-vector) | 指定された範囲の最初と最後の値の差をもつ instant vector を返す |
| idelta() | idelta(v range-vector) | 指定された範囲の最後の2つの値の差をもつ instant vector を返す |
| increase() | increase(v range-vector) | 指定した範囲の増加量をもつ instant vector を返す |
| rate() | rate(v range-vector) | 指定した範囲の1秒当たりの増加率をもつ instant vector を返す |
| irate() | irate(v range-vector) | 指定した範囲の末尾2つの値に基づき、1秒当たりの増加率をもつ instant vector を返す |
| deriv() | deriv(v range-vector) | 線形回帰を用いて秒単位での微分を返す |
| predict_linear() | predict_linear(v range-vector, t scalar) | 線形回帰を用いて t 秒後の予測値を返す |
| histogram_quantile() | histogram_quantile(φ float, b instant-vector) | ヒストグラムのバケットbからφ-四分位(0 ≤ φ ≤ 1)を計算する |
| holt_winters() | holt_winters(v range-vector, sf scalar, tf scalar) | Holt-Winters 法による平滑化値を生成する |
Range vector の集約関数
-
avg_over_time(range-vector): the average value of all points in the specified interval. -
min_over_time(range-vector): the minimum value of all points in the specified interval. -
max_over_time(range-vector): the maximum value of all points in the specified interval. -
sum_over_time(range-vector): the sum of all values in the specified interval. -
count_over_time(range-vector): the count of all values in the specified interval. -
quantile_over_time(scalar, range-vector): the φ-quantile (0 ≤ φ ≤ 1) of the values in the specified interval. -
stddev_over_time(range-vector): the population standard deviation of the values in the specified interval. -
stdvar_over_time(range-vector): the population standard variance of the values in the specified interval.
ソート関数
| 関数名 | 書式 | 説明 |
|---|---|---|
| sort() | sort(v instant-vector) | 要素を値で昇順ソートする |
| sort_desc() | sort_desc(v instant-vector) | 要素を値で降順ソートする |
判定系関数
| 関数名 | 書式 | 説明 |
|---|---|---|
| absent() | absent(v instant-vector) | もし1つでも要素があれば空を返し、何も要素がなければ値が1の要素を返す。これは指定された条件の時系列データがないことを検知する場合に使う。 |
| absent_over_time() | absent_over_time(v range-vector) | もし1つでも要素があれば空を返し、何も要素がなければ値が1の要素を返す。これは指定された条件の時系列データがないことを検知する場合に使う。 |
| changes() | changes(v range-vector) | 値の変化が起こった回数を返す |
| resets() | resets(v range-vector) | 指定された範囲内でのカウンタリセット回数をinstant vectorとして返す |
補助系関数
| 関数名 | 書式 | 説明 |
|---|---|---|
| days_in_month() | days_in_month(v=vector(time()) instant-vector) | 値をUTC時刻とみなし、その月が何日あるか(28-31 の値)を返す |
| minute() | minute(v=vector(time()) instant-vector) | 値をUTC時刻とみなし、その時点が何分であるか(0-59 の値)を返す |
| hour() | hour(v=vector(time()) instant-vector) | 値をUTC時刻とみなし、その時点が何時であるか(0-23 の値)を返す |
| month() | month(v=vector(time()) instant-vector) | 値をUTC時刻とみなし、その時点が何月であるか(1-12 の値)を返す |
| day_of_week() | day_of_week(v=vector(time()) instant-vector) | 値を UTC 時刻とみなし、その週の曜日(0-6 の値)を返す |
| day_of_month() | day_of_month(v=vector(time()) instant-vector) | 値を UTC 時刻とみなし、その日の日付(1-31 の値)を返す |
| year() | year(v=vector(time()) instant-vector) | 値を UTC 時刻とみなし、その時点が何年であるかを返す |
| time() | time() | UNIX time を返す |
| timestamp() | timestamp(v instant-vector) | timestamp を返す |
| label_join() | label_join(v instant-vector, dst_label string, separator string, src_label_1 string, src_label_2 string, ...) | src_label_X の各値を separator で結合した新しいラベル dst_label を追加する |
| label_replace() | label_replace(v instant-vector, dst_label string, replacement string, src_label string, regex string) | src_label の値に対して正規表現 regex によるマッチングを行い、replacement で評価した値をもつ dst_label を追加する |
| scalar() | scalar(v instant-vector) | 1つの要素を与えた場合、その値の Scalar を返す。複数の要素が与えられた場合は NaN を返す。 |
| vector() | vector(s scalar) | Scalar の値をもつ instant vector を返す |
Examples
より実践的な例は Kubernetes(GKE) で便利な Prometheus 小ネタ集 に紹介されています。
メモリ使用量
process_resident_memory_bytes
ノードの再起動発生有無
changes(node_boot_time_seconds[1m])
ディスク空き容量の割合
node_filesystem_avail_bytes * 100 / node_filesystem_size_bytes
温度
node_hwmon_temp_celsius * ignoring(label) group_left(label) node_hwmon_sensor_label
CPU の I/O wait 割合
sum without(cpu)(rate(node_cpu_seconds_total{mode="iowait"}[5m])) # 1
/ ignoring(mode) # 2
sum without(mode, cpu)(rate(node_cpu_seconds_total[5m])) # 3
1 の結果には次のようにラベル mode が含まれる。
{instance="localhost:9100",job="node",mode="iowait"} : 1.9954526794454766
3 の結果には次のようにラベル mode が含まれない。
{instance="localhost:9100",job="node"} : 1.998273690267743
そのため / を使って計算するためには ignoring を使って mode ラベルを除外する必要がある。
結果には mode ラベルは含まれない。
Load Avarage (1 分平均) が 1h の内で 1 を超えた回数
count_over_time((node_load1 > 1)[1h:])
備考
どうやってメトリックを調べるの?
Exporter の仕様を調べましょう。
既に構築された Prometheus がある場合、どの Exporter を使っているかは Targets を調べます。