はじめに
以前、CatBoostの概要を初心者向けに解説しました。こちらの記事
今回は以前の記事から一歩進み、実装の例を紹介します。
この記事の目的
kaggleのtitanicでCatBoostを実装し、実装の際に注意することをまとめます。
機械学習初心者の方がCatBoostを実装するときの参考になればと思います。
kaggleとは?
対象読者
- Catboostを使ってみたい
- 公式ドキュメントを読むのが面倒
- pandas,numpyは知ってる
Poolクラス
CatBoostは、カテゴリカルデータを効果的に処理するために設計されたアルゴリズムでした。
titanicのデータはカテゴリカルデータと数値データの両方を含むデータで、モデルにもそのことを理解してもらわなければいけません。
そこでCatBoostライブラリのPoolクラスを使います。
Poolクラスの引数でカテゴリカルデータを指定すると、CatBoostモデルが指定されたデータをカテゴリカルデータとして扱ってくれます。(後半で実装例を紹介します)
CatBoostClassifierクラス
モデルの構造やハイパーパラメータを決めるのがCatBoostClassifierクラスです。
各引数を指定して使います。(後半で実装例を紹介します)
ただ、ここについて深ぼるときりがない&自動で選択できるので、割愛します。
kaggleで実装
下記の順に実装していきます。
- データの読みこみ
- データの前処理
- Poolクラスの利用
- CatBoostClassifierクラスの利用
- モデルの評価
1. データの読みこみ
データを読みこみます。
後ほどカテゴリカルデータと数値データを分けるので、データの型も確認しておきましょう。
# データの読み込み
train = pd.read_csv('../input/titanic/train.csv')
test = pd.read_csv('../input/titanic/test.csv')
# データの確認
train.info()
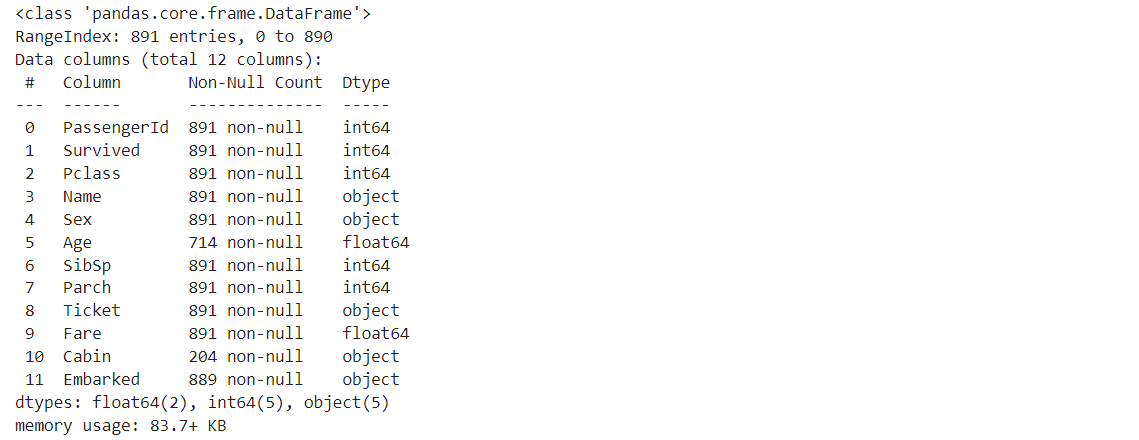
データ内容を見ると、Age, Fare がfloat型なので数値データですね。
intのデータもいくつか見られますがこれらはカテゴリを数値で表したものだとkaggleのデータ概要に書いてありました。
intなのにカテゴリカルデータになる例を見てみましょう。
具体的に、色というデータがあるとします。
- 色:赤、青、緑
ここで、
赤 = 1, 青 = 2, 緑 = 3
というように、数値で表したものがカテゴリカルデータです。データ形式はint型の数値ですが、内容はカテゴリカルデータになります。
データを確認してみると、たしかに数値データではなく、数字をカテゴリとしたカテゴリカルデータになっています。
# データを一部表示
train.head()
2. データの前処理
今回は特にこだわらず、下記の前処理をします。
- いらなそうなデータの削除
- データの欠損を補間
- 数値データを標準化
- 説明変数を目的変数に分ける
カテゴリカルデータの前処理は??となるかもしれませんが、これについてはPoolクラスとCatBoostClassifierクラスで自動で処理してくれるので、ここではなにもしません。
公式ドキュメントを見る感じ数値データに特別な処理は行われないようなので前処理は自分で実装します。
# Cabin列を削除
train = train.drop(columns=['Cabin'])
test = test.drop(columns=['Cabin'])
# Embarked列が空の行を削除
train = train.dropna(subset=['Embarked'])
# Ageの欠損値を平均値で埋める
train['Age'] = train['Age'].fillna(train['Age'].mean())
test['Age'] = test['Age'].fillna(test['Age'].mean())
# testのFareを平均で埋める
test['Fare'] = test['Fare'].fillna(test['Fare'].mean())
# 数値データを標準化
from sklearn.preprocessing import StandardScaler, OneHotEncoder
scaler = StandardScaler()
train[['Age', 'Fare']] = scaler.fit_transform(train[['Age', 'Fare']])
test[['Age', 'Fare']] = scaler.fit_transform(test[['Age', 'Fare']])
# 説明変数と目的変数に分ける & いらなそうなデータの消去
X = train.drop(columns=['PassengerId', 'Name', 'Ticket', 'Survived'])
Y = train['Survived']
X_test = test.drop(columns=['PassengerId', 'Name', 'Ticket'])
前処理はこれで完了です。
3. Poolクラスの利用
Poolクラスにはカテゴリカルデータの列インデックスを指定します。
そのために、
- カテゴリカルデータの列インデックスを取得
- それをPoolクラスに渡す
という手順で実装します。
float以外の型がカテゴリカルデータであることを最初に確認したので、それを利用してカテゴリカルデータの列インデックスを取得します。
# カテゴリカルデータの列インデックスを取得
cat_features = np.where(X.dtypes != float)[0]
print(cat_features)

これでカテゴリカルデータがどの列インデックスにあるかを示すリストができました。
これをPoolクラスに渡します。
Poolクラスはトレーニングデータのdf、ラベルのdf、カテゴリカルデータの列インデックスを指定します。
# Poolクラスの利用
from catboost import Pool
train_pool = Pool(data=X_train, label=y_train, cat_features=cat_features)
val_pool = Pool(data=X_val, label=y_val, cat_features=cat_features)
4. CatBoostClassifierクラスの利用
とりあえず実装します。
# CatBoostClassifierクラスでモデル構築
from catboost import CatBoostClassifier
model = CatBoostClassifier(
iterations=500,
depth=10,
loss_function='Logloss',
eval_metric='Accuracy',
l2_leaf_reg=20.0,
verbose=100,
early_stopping_rounds=100,
subsample=0.8,
boosting_type='Ordered',
one_hot_max_size=2
)
このように引数を指定することで、ハイパーパラメータを決定します。
詳しく指定したい方は調べながら決めてみてください。
5. モデルの評価
モデルを学習させて精度を確認します。
# モデルの学習
model.fit(train_pool, eval_set=val_pool, use_best_model=True)
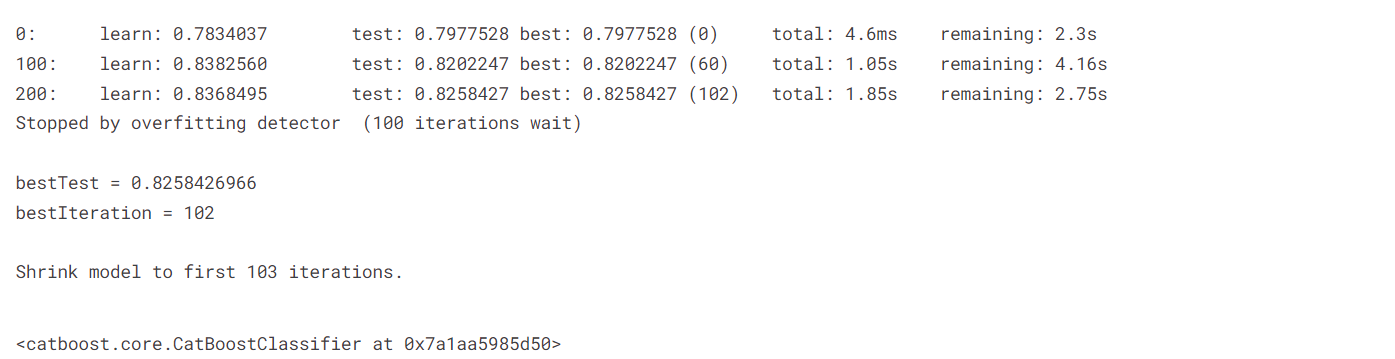
学習はこれで完了です。検証データで0.825のaccuracyを出せています。
引数にはPoolで作成したトレーニングデータと検証データを指定します。
最後にkaggleで提出するデータを作成します。
# テストデータの予測
predictions = model.predict(X_test)
# データフレーム作成
submission = pd.DataFrame({
'PassengerId': test['PassengerId'],
'Survived': predictions
})
# csvで出力
submission.to_csv('submission.csv', index=False)
以上でkaggleのtitanicコンペにCatBoostを使って提出することができました。
(ちなみに、1581位/16934 の精度でした)
まとめ
CatBoostを使ってみたい人は、ぜひこの記事を参考にしてみてください。
Reference
[1] https://qiita.com/ski_hoshi/items/5483012160bf2d0ab539
[2] https://www.kaggle.com/
[3] https://catboost.ai/en/docs/concepts/python-reference_pool
[4] https://catboost.ai/en/docs/concepts/python-reference_catboostclassifier
[5] https://www.kaggle.com/competitions/titanic/data