データベースのインデックスの種類と役割
🎯 この記事の対象者
- データベースのインデックスの基本を学びたい人
- 実際にインデックスの適用条件を検証してみたい人
-
EXPLAIN ANALYZEを活用し、実務でのパフォーマンス改善を考えている人
目次
1. Index(索引)とは?
インデックスは、データ検索を高速化するための仕組みです。
データベースのテーブルに対して作成され、クエリの検索範囲を狭めることで、不要なスキャンを削減します。
📌 インデックスの役割
- 本の目次や辞書の索引のような役割
- データ検索を高速化する
- 特定のカラムを基にデータの並びを最適化
- クエリの検索範囲を狭め、不要なスキャンを削減
- 適切に設計しないと、書き込み(INSERT/UPDATE)が遅くなることもある
2. Indexの種類
インデックスにはいくつかの種類があり、それぞれ異なる用途で使用されます。
ここでは、OLTPでよく使用されるインデックスの一部を紹介します。
| インデックスの種類 | 用途 | 使用頻度 |
|---|---|---|
| B-Tree | 一般的な検索用 | ★★★★★ |
| Composite(複合) | 複数カラム検索用 | ★★★★☆ |
| Partial(部分) | 条件付き検索用 | ★★★☆☆ |
| Unique | 重複防止 | ★★★★☆ |
| Clustered(クラスタ化) | 物理順序の最適化 | ★★★☆☆ |
| Full-Text(全文検索) | テキスト検索用 | ★★☆☆☆ |
各インデックスの詳細については、次のセクションで説明します。
各DB製品のインデックス対応状況
各データベース製品における インデックスの対応可否 を以下の表にまとめます。
| インデックスの種類 | PostgreSQL | MySQL | Oracle | SQL Server |
|---|---|---|---|---|
| B-Tree | ✅ | ✅ | ✅ | ✅ |
| Composite(複合) | ✅ | ✅ | ✅ | ✅ |
| Partial(部分) | ✅ | ❌ | ✅ | ❌ |
| Unique | ✅ | ✅ | ✅ | ✅ |
| Clustered(クラスタ化) | ❌ | ❌ | ✅ | ✅ |
| Full-Text(全文検索) | ✅ | ✅ | ✅ | ✅ |
📌 各インデックスのDBごとの特徴
✅ B-Tree & Unique は 主要なDB全てでサポートされており、一般的な検索に適用可能。
✅ Composite(複合インデックス) も どのDBでも利用可能で、複数カラム検索に有効。
⚠️Partial(部分)インデックス は PostgreSQLとOracleではサポートされるが、MySQLやSQL Serverではサポートされない。
⚠️ Clustered(クラスタ化)インデックス は OracleとSQL Serverのみ対応(PostgreSQL・MySQLでは非対応)。
✅ Full-Text(全文検索) は 全DBでサポートされるが、実装方法はDBごとに異なるため注意。
📌 注意点
- PostgreSQL は Partial Index に対応しているが、MySQL・SQL Server では使用不可。
- Clustered Index は SQL Server ではデフォルトで PRIMARY KEY に適用されるが、PostgreSQL には概念自体が存在しない。
- 全文検索(Full-Text Index)は DB によって機能が異なり、MySQL の
FULLTEXTはLIKEとは異なる動作をする。
1. B-Tree インデックス
B-Tree インデックスは、データベースで最も一般的に使用されるインデックス構造です。
データを 階層的なツリー構造 で管理し、検索処理を効率化します。
B-Tree インデックスの特徴
- 最も一般的なインデックス構造で、多くのデータベースで採用されている。
- データをツリー状に格納し、検索時に二分探索を行うため、高速な検索が可能。
- 範囲検索 (
<,>,BETWEEN) や等価検索 (=) に強い。 - インデックスのサイズが大きくなると、INSERT / UPDATE の負荷が増すことがある。
📌 使用頻度: ★★★★★(非常に高い)
適用シナリオ
✅ 主キー(PRIMARY KEY)や一意性制約(UNIQUE)に必須。
✅ 単一カラムのフィルタリング(WHERE 句)や ORDER BY によるソート最適化。
✅ JOIN 操作のパフォーマンス向上(結合キーに適用)。
📌 B-Tree インデックスは、データの検索パフォーマンスを大幅に向上させるため、ほとんどのテーブルで使用される。
B-Tree インデックスの具体例
id カラムに B-Tree インデックスを作成
CREATE INDEX idx_users_id ON users(id);
- 主キー (PRIMARY KEY) に相当するカラムにインデックスを適用し、検索を高速化。
- SELECT * FROM users WHERE id = 100; のような検索が最適化される。
2. 複合インデックス(Composite インデックス)
複合インデックス(Composite Index)は、複数のカラムを組み合わせたインデックス です。
単一カラムの B-Tree インデックスと異なり、複数カラムを同時に検索・ソートするクエリを効率化 します。
複合インデックスの特徴
- 複数のカラムを組み合わせてインデックスを作成できる。
- 複合条件 (
WHERE column1 = X AND column2 = Y) に最適化される。 ORDER BYで複数カラムが使われる場合にも有効。- カラムの指定順序によって、インデックスの適用可否が変わる。
📌 使用頻度: ★★★★☆(高い)
適用シナリオ
✅ WHERE 句や ORDER BY 句で複数カラムを使用する場合。
✅ 結合 (JOIN) の際に複数のカラムが結合キーとなる場合。
✅ 複数の条件でデータを絞り込む頻度が高い場合。
📌 特に、大規模データに対して WHERE 句で複数カラムを指定する検索では、効果的にクエリを最適化できる。
複合インデックスの具体例
✅ name と age の複合インデックスを作成
CREATE INDEX idx_users_name_age ON users(name, age);
- WHERE name = 'A' AND age = 30; のような検索が高速化される。
- ORDER BY name, age のような並び順の最適化にも適用される。
- ただし、age のみを WHERE 句で指定した場合、インデックスが無効になる可能性がある。
⚠️ 複合インデックスの注意点
-
カラムの順序を誤ると、インデックスが適用されなくなる可能性がある。
→ 検索パターンに合わせて適切な順序で作成することが重要。 -
不要なカラムを含めすぎると、インデックスサイズが増加し、逆にパフォーマンスが低下する可能性がある。
→ 適切なカラム数で作成し、必要以上に複合インデックスを増やさないことが大切。
3. 部分インデックス(Partial インデックス)
部分インデックス(Partial Index)は、特定の条件に一致するデータのみを対象とするインデックス です。
不要なデータをインデックスから除外することで、ストレージ使用量を削減し、検索を最適化 できます。
部分インデックスの特徴
- 特定の条件(
WHERE句)を満たすデータのみを対象にインデックスを作成できる。 - インデックスサイズを小さく保ち、検索性能を向上させる。
- 頻繁に参照されるデータのみをインデックス化することで、パフォーマンスを最適化。
- 適用条件と異なる検索ではインデックスが無効になる点に注意。
📌 使用頻度: ★★★☆☆(中程度)
適用シナリオ
✅ 特定の状態やフラグ(例: is_active = TRUE)が立っているデータのみを頻繁に検索する場合。
✅ 論理削除(deleted_at IS NULL)のように、特定のレコードのみを利用するクエリが多い場合。
✅ データの一部(例: 有効なユーザーのみ、最新データのみ)を頻繁に検索する場合。
📌 大量データの中から一部のデータだけを頻繁に参照する場合に特に有効。
部分インデックスの具体例
✅ is_active = TRUE のユーザーのみを対象に部分インデックスを作成
CREATE INDEX idx_active_users ON users(name) WHERE is_active = TRUE;
- WHERE is_active = TRUE の条件で検索すると、インデックスが適用される。
- is_active = FALSE や is_active を指定しない検索ではインデックスが適用されない。
インデックス適用のポイント(部分インデックス)
| 検索条件 | インデックス適用の可否 |
|---|---|
WHERE is_active = TRUE |
✅ 適用される |
WHERE is_active = FALSE |
❌ 適用されない |
WHERE name = 'A' |
❌ 適用されない |
📌 部分インデックスは、指定された WHERE 条件に完全一致しないと適用されない。
部分インデックスの注意点
-
適用条件と異なる検索では、インデックスが無効になり、フルスキャンが発生する可能性がある。
→ インデックスの適用条件と実際のクエリのWHERE条件が一致しているかを確認することが重要。 -
全レコードを対象とする検索 (
WHERE句なし) では、部分インデックスが一切使用されない。
→EXPLAIN ANALYZEを使い、インデックスが適用されているかチェックするのがベスト。
4. Unique インデックス
Unique インデックス(一意インデックス)は、各行の値が一意であることを保証するインデックス です。
データの整合性を保ちつつ、検索パフォーマンスを向上させる目的で使用されます。
Unique インデックスの特徴
- 指定したカラムの値が重複しないように制約をかける。
- データの整合性を確保し、不正な重複データの登録を防ぐ。
- 検索時のパフォーマンスも向上するが、重複チェックのため INSERT/UPDATE は若干遅くなる。
📌 使用頻度: ★★★★☆(高い)
適用シナリオ
✅ ユーザー名やメールアドレスなど、重複を許可しないデータに適用。
✅ 主キー(PRIMARY KEY)の代わりにユニークなデータを識別する場合。
✅ ユニークな識別子(例: 社員番号、会員ID など)を使用する場合。
📌 Unique インデックスは、データの一意性を担保するため、多くのテーブルで使用される。
Unique インデックスの具体例
✅ email カラムに Unique インデックスを作成
CREATE UNIQUE INDEX idx_unique_email ON users(email);
- email の値が重複しないように制約を設定。
- INSERT INTO users (email) VALUES ('test@example.com'); を繰り返すとエラーが発生。
- ユニークなメールアドレスを強制し、一意性を保証する。
Unique インデックスと PRIMARY KEY の違い
| 特性 | Unique インデックス | PRIMARY KEY |
|---|---|---|
| 重複防止 | ✅ | ✅ |
| NULL 許容 | ✅(許可される場合あり) | ❌(必ず NOT NULL) |
| 1つのテーブルに複数設定可能 | ✅ | ❌(1つのみ) |
| 検索最適化 | ✅ | ✅ |
📌 PRIMARY KEY はテーブルに1つしか設定できないが、Unique インデックスは複数のカラムに設定可能。
Unique インデックスの注意点
-
NULL 値は "一意" として扱われるが、データベース製品によって挙動が異なる場合がある。
→ PostgreSQL では、複数のNULL値を許可(NULL != NULL扱い)。
→ MySQL では、NULL値の扱いが異なる可能性があるため、事前に仕様を確認。 -
INSERT 時の一意性チェックが発生するため、大量のデータ登録では若干のパフォーマンス低下がある。
→ インデックスを適切に管理し、不要なユニーク制約を増やさないことが重要。
5. Clustered インデックス(クラスタ化インデックス)
Clustered インデックス(クラスタ化インデックス)は、テーブル自体のデータをインデックスの順序で並べ替えるインデックス です。
通常の B-Tree インデックスと異なり、データの物理的な格納順序がインデックスと一致する ため、
範囲検索やソートのパフォーマンスが向上します。
Clustered インデックスの特徴
- テーブルのデータ自体が、インデックスの順序に従って並べられる。
- 特定のカラム順でデータが格納されるため、検索や
ORDER BYの処理が高速化される。 - 主キー(PRIMARY KEY)に適用されることが多い(SQL Server ではデフォルトで適用)。
- データの物理配置が変わるため、頻繁な
INSERT/UPDATEではパフォーマンスが低下する可能性がある。
📌 使用頻度: ★★★☆☆(中程度)
適用シナリオ
✅ データが頻繁にソートされてアクセスされる場合(例: ORDER BY date の履歴データ)。
✅ 範囲検索(BETWEEN など)が頻繁に発生する場合。
✅ 主キー(PRIMARY KEY)の検索が頻繁に行われる場合(SQL Server ではデフォルト適用)。
📌 履歴データやログデータのように、一定の順序でデータを保持する場合に特に有効。
Clustered インデックスの具体例
✅ order_date をクラスタ化インデックスに設定
CREATE CLUSTERED INDEX idx_order_date ON orders(order_date);
- ORDER BY order_date を実行すると、ソートなしで高速に結果を取得できる。
- WHERE order_date BETWEEN '2024-01-01' AND '2024-01-31' のような範囲検索に最適。
- データの挿入時に order_date の順序で格納されるため、ランダムな INSERT は遅くなる可能性がある。
Clustered インデックスと B-Tree インデックスの違い
| 特性 | Clustered インデックス | B-Tree インデックス |
|---|---|---|
| データの格納順序 | 物理的に並べ替えられる | 変更なし(論理的な索引) |
範囲検索 (BETWEEN) |
高速 | 高速だがデータがバラバラ |
ORDER BY の最適化 |
追加のソート不要で高速 | インデックス順なら最適化される |
| INSERT の影響 | 影響大(並び順を維持) | 影響小 |
| DELETE の影響 | 断片化が発生しやすい | 比較的影響は少ない |
| 1テーブルに複数設定可否 | ❌(1つのみ) | ✅(複数作成可能) |
📌 Clustered インデックスは 1 つのテーブルに 1 つしか作成できないが、B-Tree インデックスは複数作成可能。
⚠️ Clustered インデックスの注意点
-
INSERT/UPDATEの際、データの物理順序を維持するため、パフォーマンスが低下する可能性がある。
→ 特にランダムなデータ追加(例:UUIDのようなランダム値の主キー)は向かない。 -
DELETEによってページ内の空き領域が生じ、断片化が発生する可能性がある。
→REBUILDやVACUUMでインデックスの最適化が必要。 -
SQL Server や Oracle では
PRIMARY KEYに対してデフォルトで適用されるが、PostgreSQL や MySQL では手動で設定が必要。
→ 使用するデータベースごとの仕様を確認することが重要。
6. Full-Text インデックス(全文検索インデックス)
Full-Text インデックス(全文検索インデックス)は、テキストデータに対する全文検索を高速化するためのインデックス です。
通常の B-Tree インデックスとは異なり、トークン化(単語ごとの分割)を行い、キーワード検索を最適化 します。
Full-Text インデックスの特徴
- 長文テキストの検索を最適化し、高速な全文検索を可能にする。
- トークン化(単語の分割)を行い、検索時に単語単位で一致を判定。
- 通常のインデックス(B-Tree や Composite)とは異なるデータ構造を持つ。
LIKE '%keyword%'よりも効率的な検索が可能。
📌 使用頻度: ★★☆☆☆(低いが特定シナリオで有効)
適用シナリオ
✅ 商品説明やコメント欄など、長文テキストを検索する場合。
✅ 記事検索、ブログのキーワード検索、FAQ の検索などに最適。
✅ 通常の LIKE '%文字列%' 検索ではパフォーマンスが低下するケース。
📌 短い文字列や ID などの検索には適さず、主にテキスト検索用途で使用する。
Full-Text インデックスの具体例
✅ description カラムに Full-Text インデックスを作成
CREATE FULLTEXT INDEX idx_product_description ON products(description);
- description に対する全文検索を高速化。
- SELECT * FROM products WHERE MATCH(description) AGAINST('keyword'); で検索。
- 単純な LIKE '%keyword%' よりも効率的に検索を実行。
🔍 Full-Text インデックスと通常のインデックスの違い
| 特性 | Full-Text インデックス | B-Tree / Composite インデックス |
|---|---|---|
| データの対象 | テキストデータ(長文) | 数値・短い文字列 |
| 検索対象 | 単語ごとのマッチング | 完全一致または部分一致 |
LIKE '%keyword%' との比較 |
高速 | 遅くなる可能性あり |
| 複合インデックスとの併用 | ❌(基本的に不可能) | ✅(可能) |
📌 Full-Text インデックスは、通常のインデックスとは異なるデータ構造を持つため、複合インデックスと同時に適用できない。
⚠️ Full-Text インデックスの注意点
-
Full-Text インデックスは、通常の B-Tree インデックスとは構造が異なるため、複合インデックスなど他のインデックスと同時に使用できない。
→ 例えば、prefecture_codeやgenderの複合インデックスとdescriptionの Full-Text インデックスは共存できない。 -
全文検索の結果は完全一致ではなく、関連度(スコア)でランク付けされることが多い。
→ 結果の精度を考慮し、LIKEなどの通常の検索と使い分ける必要がある。 -
データの変更(INSERT/UPDATE)時にインデックスが再構築されるため、大量データの更新が頻繁に発生する場合はパフォーマンスに影響を与える可能性がある。
→ 全文検索が不要なカラムには適用しないように設計することが重要。
3. Indexの構造イメージ(複合インデックス)
本項目では、複合インデックスの構造イメージについて記載します。
- 使用するデータ
📌 このデータは、name(アルファベット順)とage(昇順)の複合インデックスを適用する想定で整理されています
| id | name | age | other_info |
|---|---|---|---|
| 1 | A | 20 | User1 |
| 2 | A | 30 | User2 |
| 3 | F | 25 | User3 |
| 4 | F | 45 | User4 |
| 5 | N | 22 | User5 |
| 6 | N | 50 | User6 |
| 7 | T | 35 | User7 |
| 8 | T | 45 | User8 |
- インデックス
CREATE INDEX idx_users_name_age
ON users(name, age);

・このツリー構造では、name(アルファベット順)と age(昇順)の複合インデックスを適用した場合の B-Tree のイメージを示しています。
-
Root ノード:
M, 30(M以前は左、M以降は右) -
Branch ノード:
A~L(左)、N~Z(右) -
リーフノード:
nameごとにageで昇順にソート
・このツリー構造のポイント
nameのアルファベット順に並び、同じnameの場合はage昇順に並ぶ。- B-Tree の仕組みにより、検索時の探索コストが最小限に抑えられる。
WHERE name = 'A' AND age = 20などのクエリでインデックスが活用される。
4. 検証
🔍 検証目的
複合インデックスと部分インデックスの適用状況を確認し、実行計画を検証する。
- 複合インデックスでは、特定の条件を WHERE 句に指定した場合の影響を確認。
- 部分インデックスでは、定義された条件と異なる場合にインデックスが適用されるかを確認。
- PostgreSQL で
EXPLAIN ANALYZEを用いて、どのインデックスが使用されているか検証。 - データ件数は400万件。
- 統計情報とインデックスは最新の状態とする。
🛠️ 検証内容
✅ 複合インデックスの検証
対象インデックス
CREATE INDEX idx_people_02 ON people
(duplication_many, duplication_forty_type, duplication_twenty_type);
-
全カラム指定
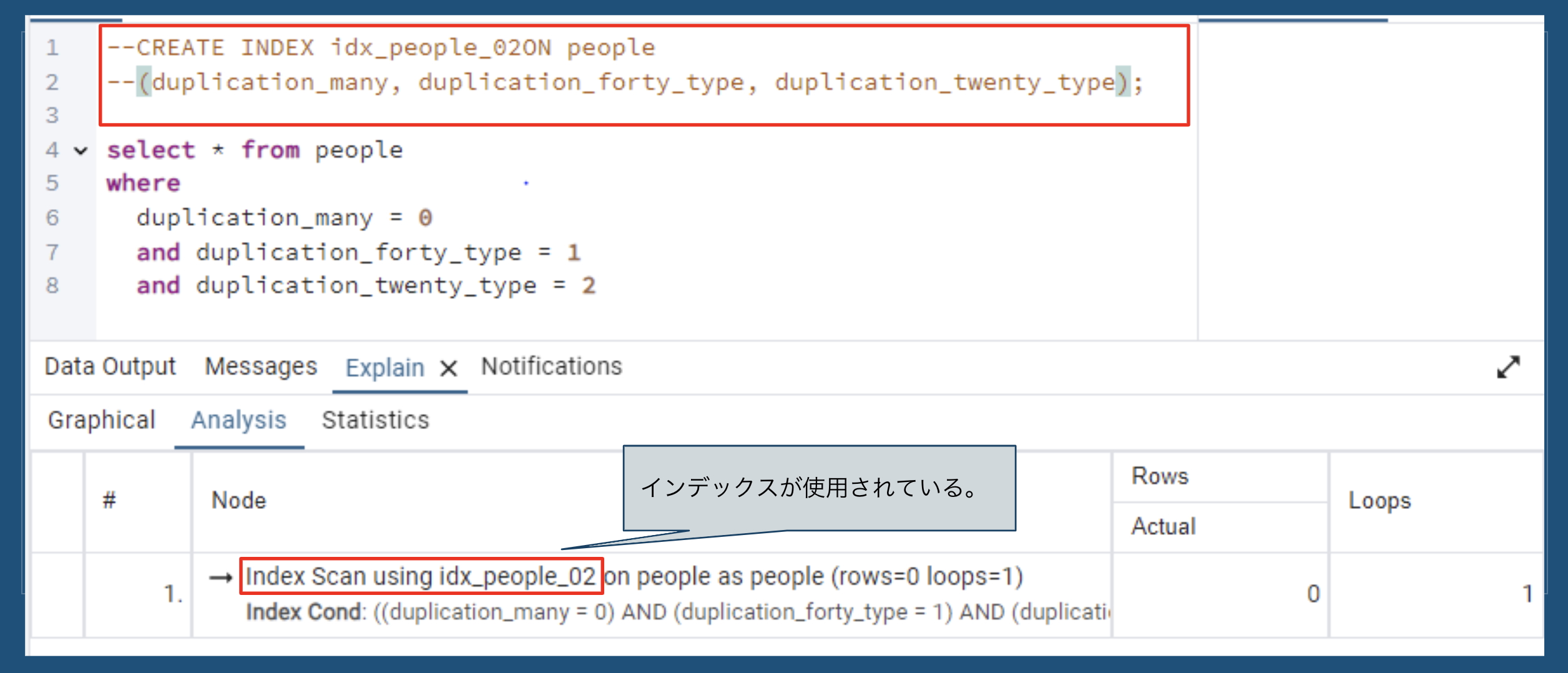
-
先頭カラム指定
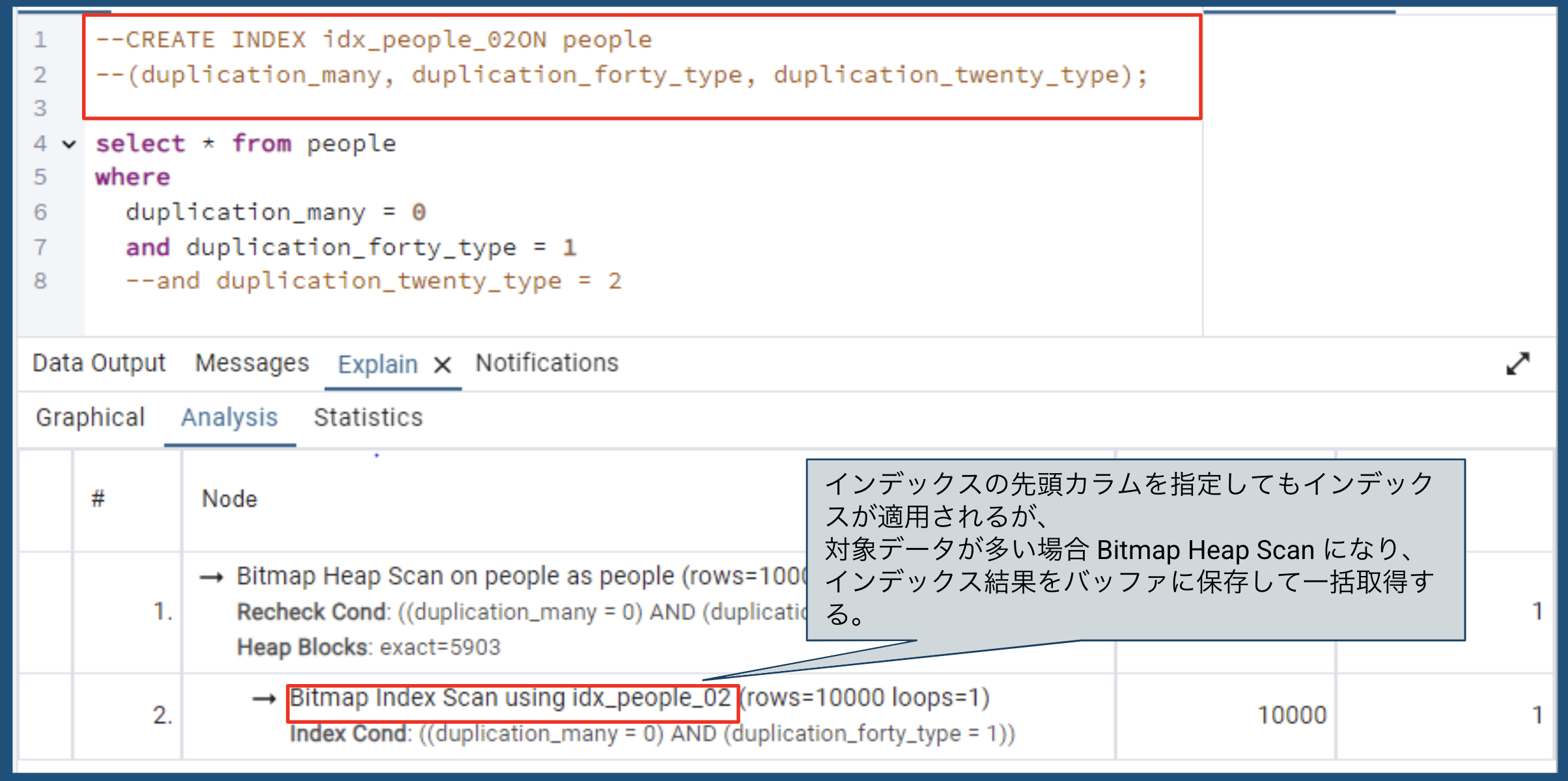
-
最後のカラム指定
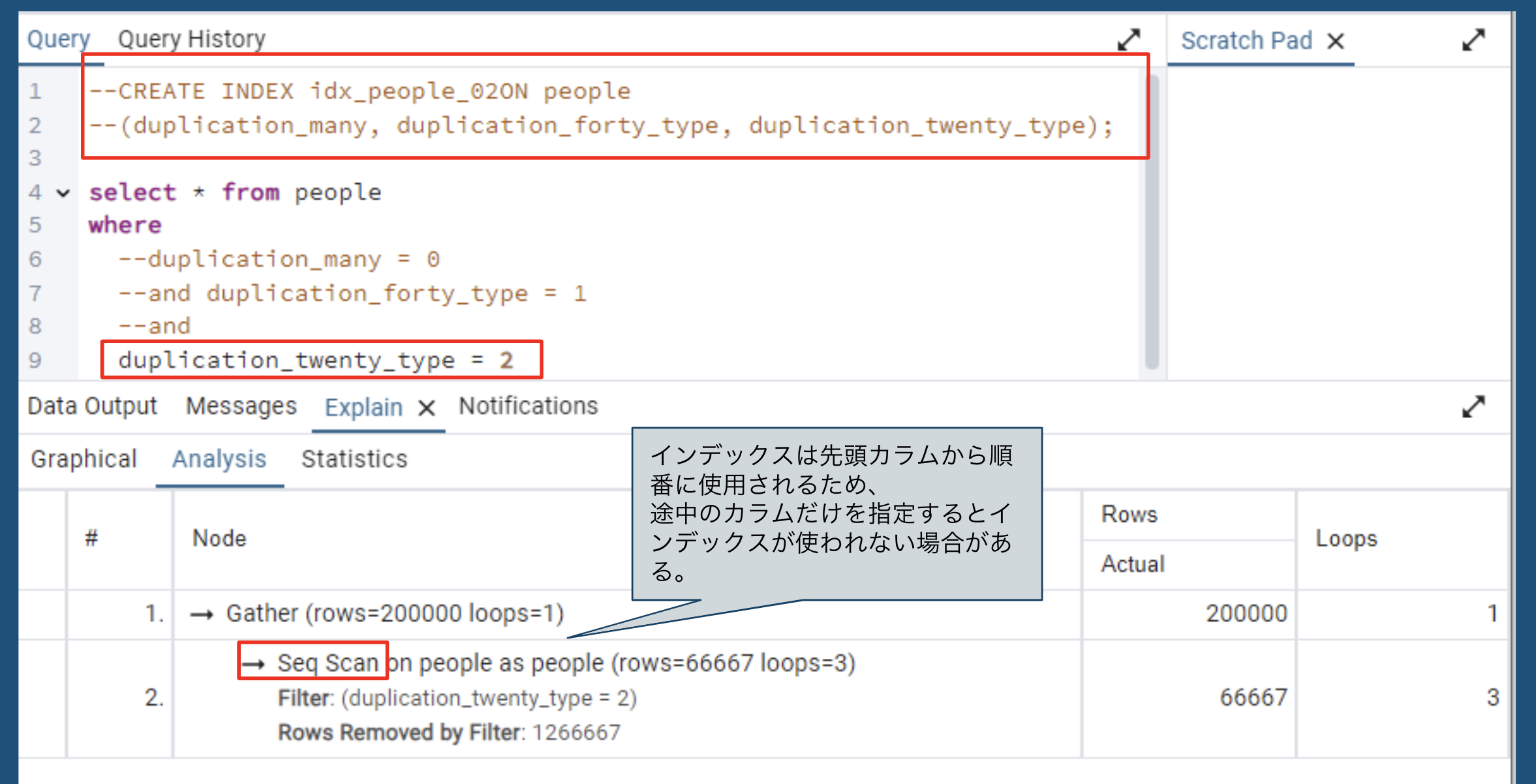
✅ 部分インデックスの検証
対象インデックス
CREATE INDEX idx_people_02 ON people
(duplication_many, duplication_forty_type)
WHERE GENDER = 'M';
-
条件そのまま
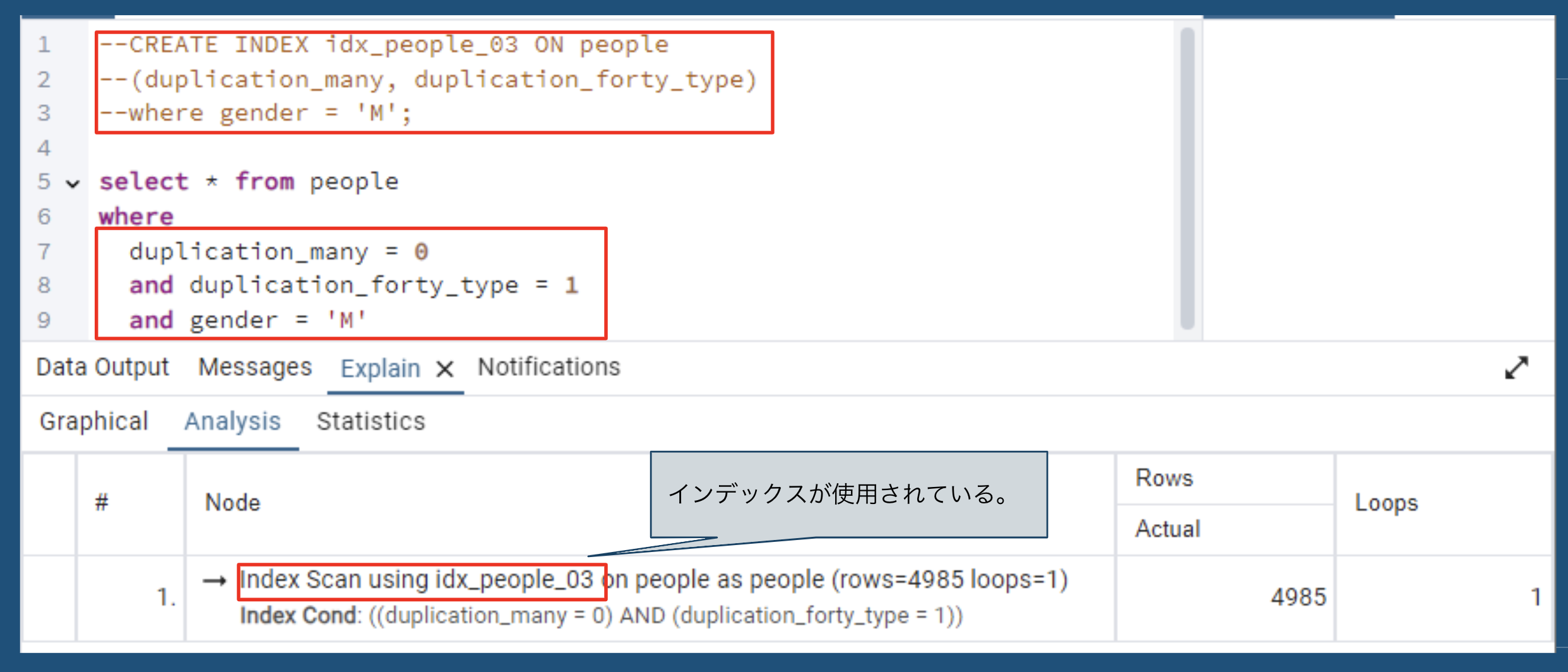
-
条件一部変更
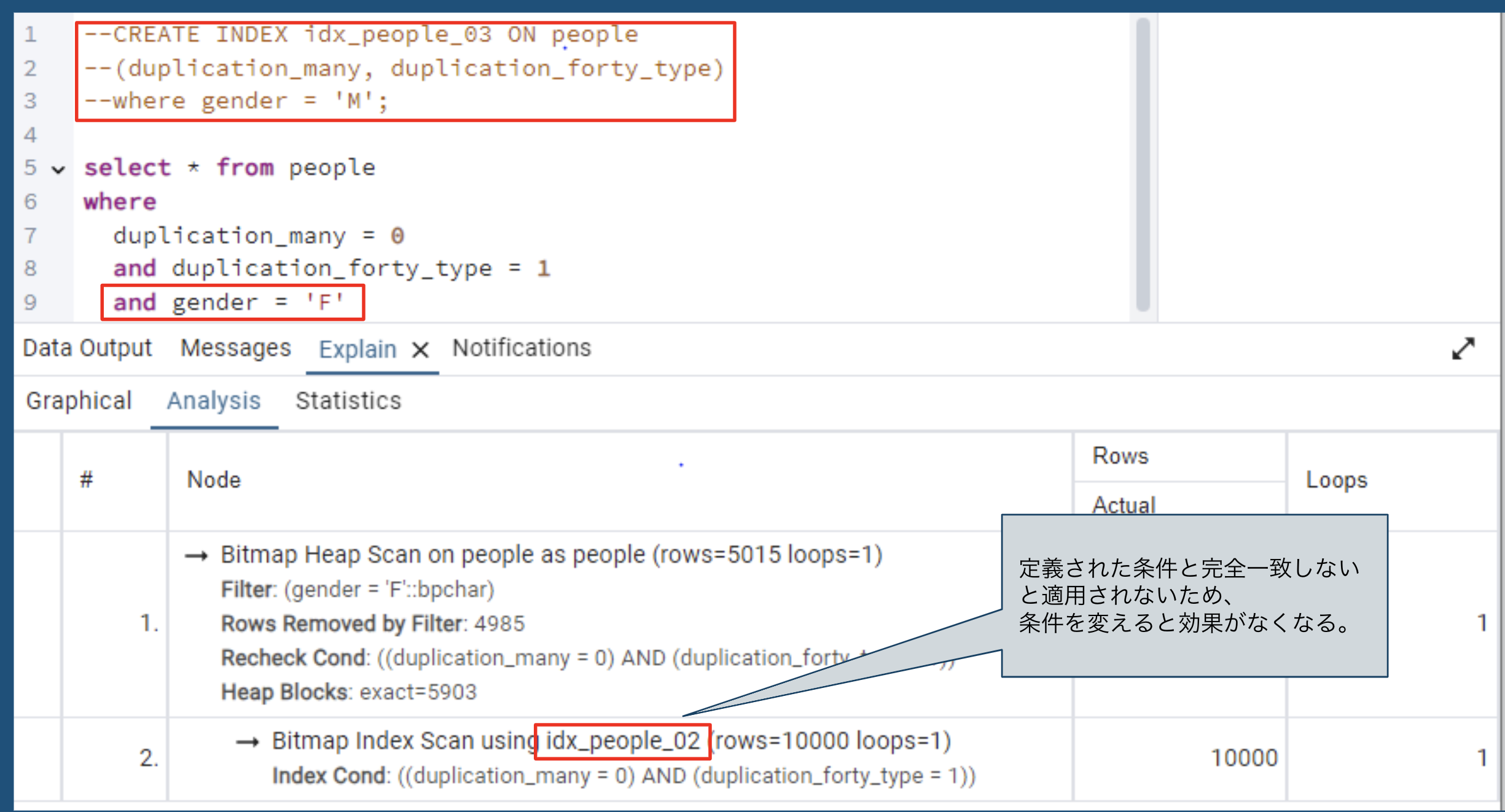
-
条件無し
-

🔍 検証結果一覧
| インデックスの種類 | 条件 | 結果 |
|---|---|---|
| 複合インデックス | 全カラム指定 | Index Scan |
| 先頭カラム指定 | Bitmap Heap Scan | |
| 最後のカラム指定 | インデックス未使用 | |
| 部分インデックス | 条件そのまま | Index Scan |
| 条件一部変更 | インデックス未使用 | |
| 条件なし | インデックス未使用 |
📌 複合インデックスでは、全カラムや先頭カラムを指定するとインデックスが適用されるが、最後のカラムのみ指定すると適用されない場合がある。
📌 部分インデックスは、定義された条件をそのまま指定した場合のみ適用されるが、一部変更や条件なしの場合は適用されない。
5. まとめ
📌 インデックスの活用ポイント
✅ 適切なインデックス設計により、検索パフォーマンスを向上できる。
✅ ただし、条件次第ではインデックスが適用されない場合があるため、都度 EXPLAIN ANALYZE などで実行計画の確認が必要。
🔍 検証結果のポイント
✅ 複合インデックス
- 全カラム(カバリングインデックス)や先頭カラムを指定すると、インデックスが適用される確率が上がる。
- 途中のカラムや最後のカラムのみを使用すると、インデックスが適用されない場合がある。
- 取得結果が多い場合、Bitmap Heap Scan が選択されることがある。
📌 検索クエリの WHERE 句に合わせて、インデックスのカラム順序を適切に設計することが重要。
✅ 部分インデックス
- 定義された
WHERE条件をそのまま指定した場合にインデックスが適用される。 - 異なる条件(例:
WHERE is_active = FALSE)やWHERE句なしではインデックスが適用されない。
📌 部分インデックスを活用する際は、実際のクエリと定義条件が合致することを確認する。
⚠️ 注意点
- 複合インデックスの適用には、検索時の
WHERE句で先頭カラムを指定することが必要。 - 部分インデックスは、
WHERE句が定義と異なる場合には使用されないため、適用範囲を意識する。 EXPLAIN ANALYZEを活用し、実際のインデックス適用状況を定期的に確認することが重要。