はじめに
本記事では、AWS EC2上にデータ収集ツールであるAirbyteを構築する方法を説明します。データ可視化基盤の全体デザイン、各サービスの概要については前回の記事をご覧ください。
なお、本記事の正確性や完全性について保証しませんので、本番環境等で利用される方等はご注意ください。
構築手順
基本的な流れは、Airbyteの公式ドキュメントのとおりです。
今回は、AWS EC2上のdockerにAirbyteを構築し、AirbyteのDBに Amazon RDSを利用します。またGitLabのデータを取得してAWS S3に格納してみます。構築時の注意点として、Airbyteの現バージョンはECSに対応していません。
なお、本記事執筆時点の Airbyteのバージョンは 0.40.32 です。ベータのためドラスティックに機能が変更されることもあるため、最新情報は公式サイトをご覧ください。
EC2 構築
本記事では詳細手順は割愛します。AWS EC2でインスタンスを構築し、ssh接続をできるようにします。VPC、サブネット、パブリックIP等の構成は、データ収集先やAirbyteへのアクセス方法にあわせて構築してください。
なお、インスタンスのサイズとしてテスト環境では t2.medium 、本番(プロダクション)環境では t2.large が推薦されています。
私のチームでは、チーム状況やサービスのデータを収集していますが、いまのところ medium でも問題は起きていません。
また、公式ドキュメントでは、ec2のインスタンスタイプとして 't2' が指定されていますが、't3'シリーズでも構築可能です。(t3のほうが多少安価です)

docker インストール
基本的には公式ドキュメントのとおりに docker をインストールします。
sudo yum update -y
sudo yum install -y docker
sudo systemctl start docker
sudo systemctl enable docker
sudo usermod -a -G docker ec2-user
sudo yum install -y docker-compose-plugin
docker compose version
この際、docker-compose-pluginをインストールできなかった場合、以下のコマンドでインストール可能です。
(docker-composeのバージョンは、適切なものに変更してください)
sudo mkdir -p /usr/local/lib/docker/cli-plugins
sudo curl -SL https://github.com/docker/compose/releases/download/v2.4.1/docker-compose-linux-x86_64 -o /usr/local/lib/docker/cli-plugins/docker-compose
sudo chmod +x /usr/local/lib/docker/cli-plugins/docker-compose
Airbyte インスト-ル
Airbyteをdocker上にインストールし起動します。
基本は公式手順のとおりです。
mkdir airbyte && cd airbyte
wget https://raw.githubusercontent.com/airbytehq/airbyte/master/{.env,flags.yml,docker-compose.yaml}
docker compose up -d # run the Docker container
イメージがダウンロードされて、Airbyteが起動します。現在のところairbyteの認証方式は、basic認証のみとなります。
デフォルトのポートは8000、basic認証のID:PASSは airbyte:password です。
Airbyte 環境設定
Airbyteの環境設定は、.envファイルを編集します。
Basic認証のID:パスワード変更
airbyteインストール先の .env ファイルの以下の箇所を修正します。
# Set to empty values, e.g. "" to disable basic auth
BASIC_AUTH_USERNAME=********
BASIC_AUTH_PASSWORD=********
BASIC_AUTH_PROXY_TIMEOUT=600
DB変更
Airbyteではデフォルトで、PostgreSQLのイメージ(airbyte/db)を構築し、Airbyteのデータはそこに保存されます。今回はAmazon RDSを利用します。
現在AirbyteはPostgreSQLのみに対応しています。
AirbyteのDBの詳細は公式ドキュメントを参照ください。
DB変更のために.env ファイルの以下の箇所を修正します。
### DATABASE ###
# Airbyte Internal Job Database, see https://docs.airbyte.io/operator-guides/configuring-airbyte-db
DATABASE_USER= ***
DATABASE_PASSWORD= ******
DATABASE_HOST=postgres.*********.ap-northeast-1.rds.amazonaws.com
DATABASE_PORT=5432
DATABASE_DB=airbyte
# translate manually DATABASE_URL=jdbc:postgresql://${DATABASE_HOST}:${DATABASE_PORT}/${DATABASE_DB} (do not include the username or password here)
DATABASE_URL=jdbc:postgresql://${DATABASE_HOST}:${DATABASE_PORT}/${DATABASE_DB}
JOBS_DATABASE_MINIMUM_FLYWAY_MIGRATION_VERSION=0.40.26.001
環境設定が終わったらイメージを再アップします。
docker compose up -d # run the Docker container
なお、設定ミス等でDB等に接続できない場合は、起動できません。その場合、フォアグラウンドで起動することで起動エラーを確認できます。
docker compose up
Airbyteによるデータ収集、転送 (GitLab Data -> S3)
Airbyteの構築ができましたので、GitLabのデータを収集し、S3に格納してみます。
Airbyteでは、SourceとDestinationをConnectionで結ぶことでデータ収集、転送が可能です。
今回はConnectionを作成し、その中で順にSource、Destinationを作成します。
Connection作成
左側のConnectionsから「+New connection」を選択します。

Sourceの作成
-
「Set up the source」の「Source type」から「GitLab」を選択します。
なお事前にSourceを作成していた場合は「Select an existing source」から対象のSourceを選択することも可能です。 -
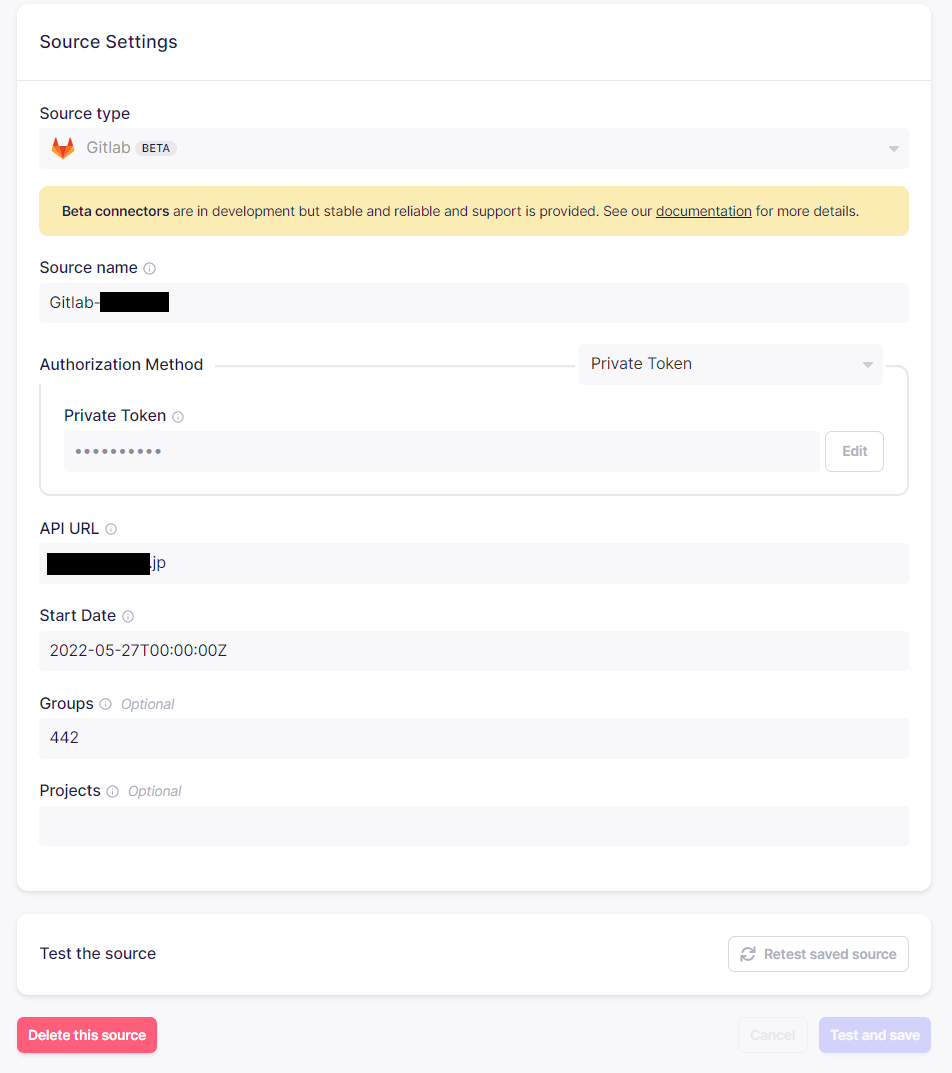
GitLabからデータを収集するためのSourceを作成します。
- Source Name は 識別用の名前のためわかりやすい名前を指定します。
- 認証方法(Authorization Method) として、OAuthとPrivate Tokenがあります。Private Tokenを利用する場合は、GitLab側のユーザ設定からトークンを発行してください。
- API URL は収集対象となるGitLabのAPI URLを指定してください。
- Start Date はいつのデータから収集対象とするかになります。巨大なプロジェクトで古い日時を指定すると収集に時間がかかることがあります。
- Groups / Projects は対象となるグループID もしくはProject ID を指定します。複数指定は半角スペースで区切ります。
過去のバージョンではGroupsにIDを指定すると、データを多重に収集してしまう不良がありましたが現在は修正されています。
設定を指定したら「Test and Save」でSourceを作成します。
注意として「Test and Save」を連打すると複数のSourceが作られることがあるため一度だけ押しましょう。
Destinationの作成
-
Sourceと同じように「Set up the destination」の「Destinatio type」から「S3」を選択します。
事前に作成していた場合は対象の Destination を選択することも可能です。 -
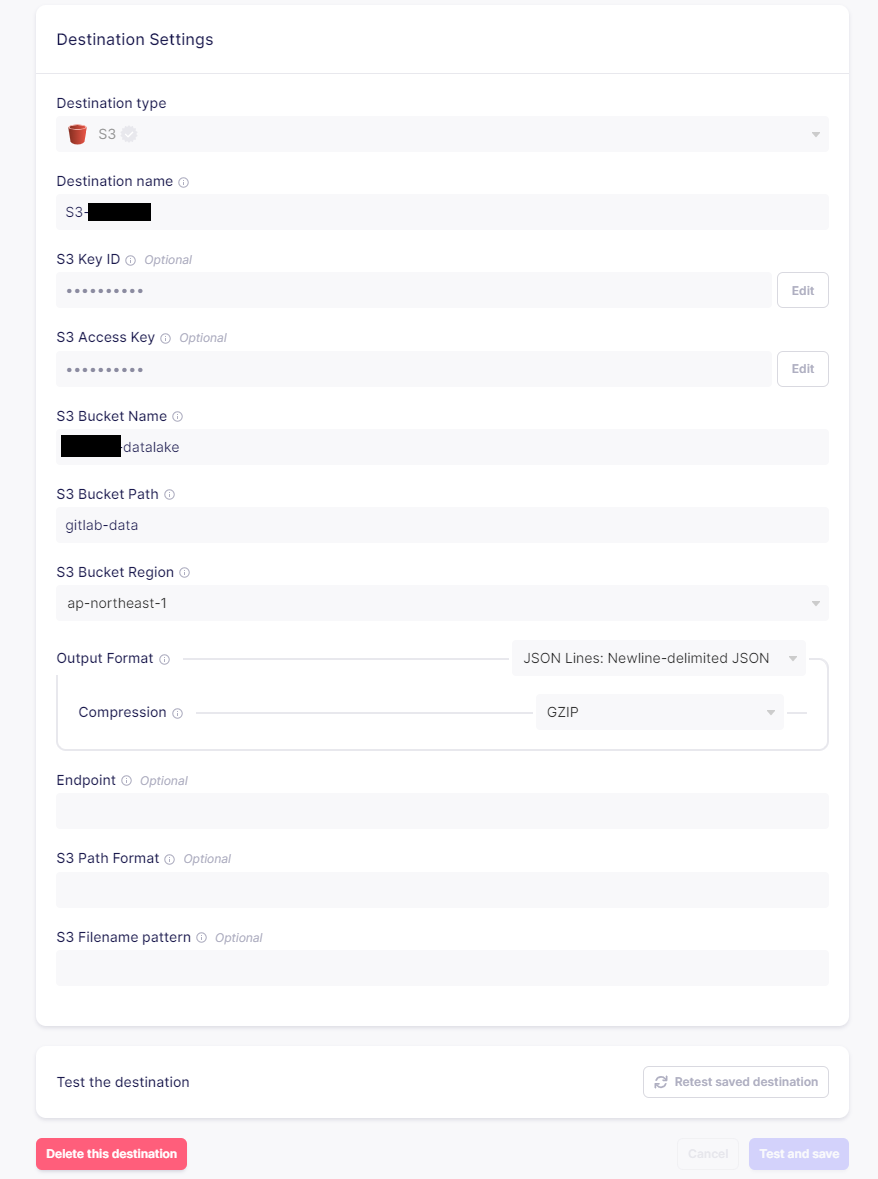
S3 のDestinationの作成
S3側の詳細な作成方法については割愛しますが、格納先となるバケットを作成し、接続用のAccessKeyを発行しておいてください。
- S3 KeyID/S3 Access Keyは、発行したID/Keyを指定します。
- S3 Bucket Name/Bucket Pathは、格納先のバケットネーム/パスを指定します。
- Output Formatについては、データの使い道に合わせた方法を指定しますが、今回はデータ容量、使い勝手の観点からJSONフォーマットのGZIP圧縮を指定しています。
設定を指定したら「Test and Save」でSourceを作成します。
Connection設定
収集元(Source)と転送先(Destination)を作れたら、最後にConnectionの設定をします。
重要な点は以下のとおりです。
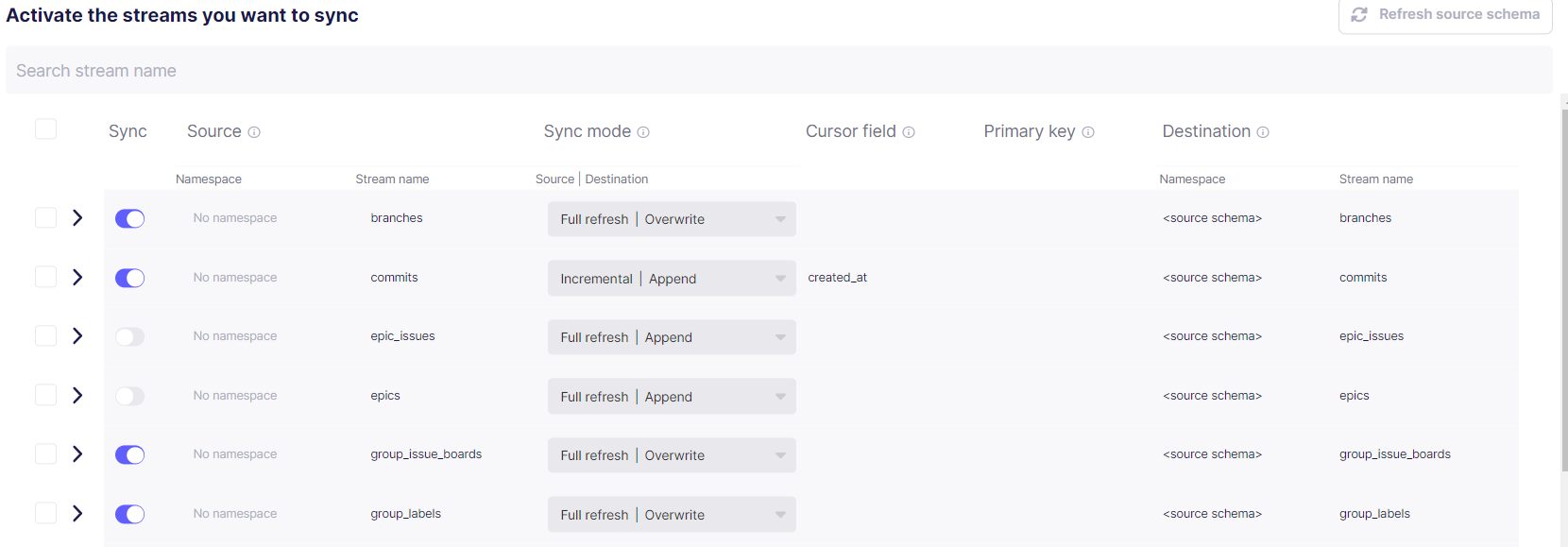
- Transfer の 「Replication frequency」 で収集頻度を指定します。GitLabの特性上、あまり早い頻度を指定すると頻繁に大量のデータを収集することになりますのでご注意ください。私のチームでは1日毎にしています。
- Streams の 「Destination Namespace」は「Mirror source stracture」を指定します。
- 「Activate the streams you want to sync」で収集する対象のデータと収集方法を指定します。具体的にどのような項目が取れるかは公式ドキュメントを御覧ください。
- epic, epic_issues は GitLab CEにはありません。
- jobs/pipelines_extendedは容量が大きいので分析の必要がなければ収集対象外にしたほうが良いです。
- commits/issues/merge_requests/pipelines はSync modeを「Incremental|Append」にすることで更新日時(update_at)による差分収集が可能です。特にpipelines/commitsは肥大化しがちなので差分収集にすることをおすすめします。
- 上記以外は原則として更新データなどを取得するためにすべて上書き「Full refresh|Overwrite」となります。「Full refresh|Append」を指定することで、過去のデータを残しながら収集日毎のデータを追記することもできます。日毎の情報が必要な場合はこちらを指定すると良いですが、データ量が増えていきますので注意ください。
「Set up connection」でConnectionを作成します。
Connection実行、データ収集、転送
Connectionを作成したら、SyncNowでデータ収集を実行できます。(Syncした時間が定期実行の基準になりますので注意ください)
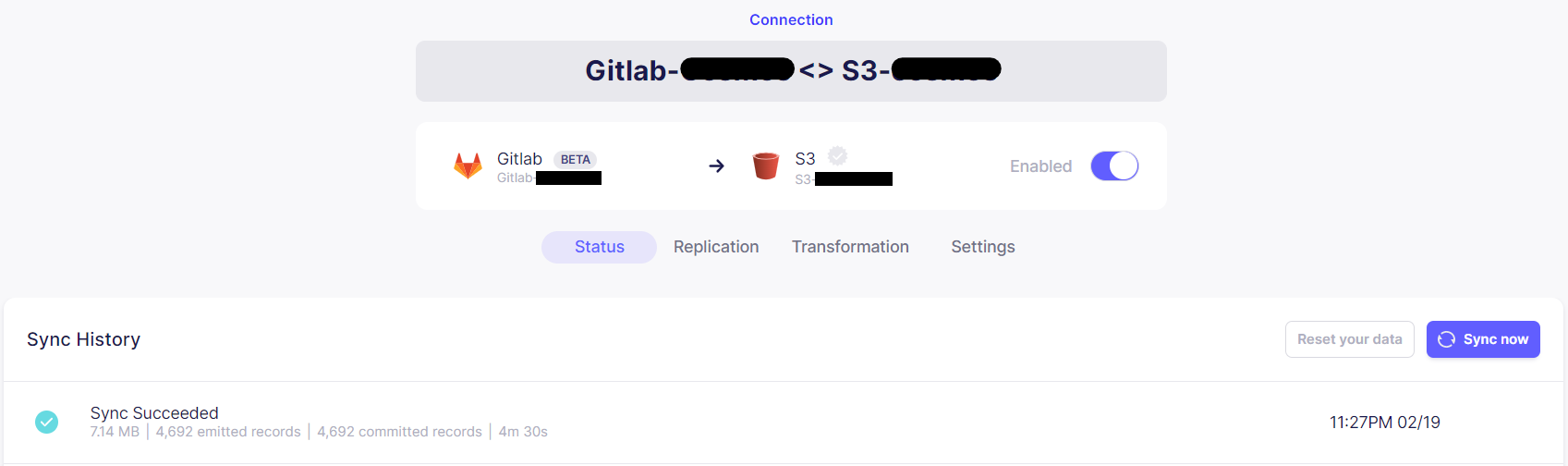
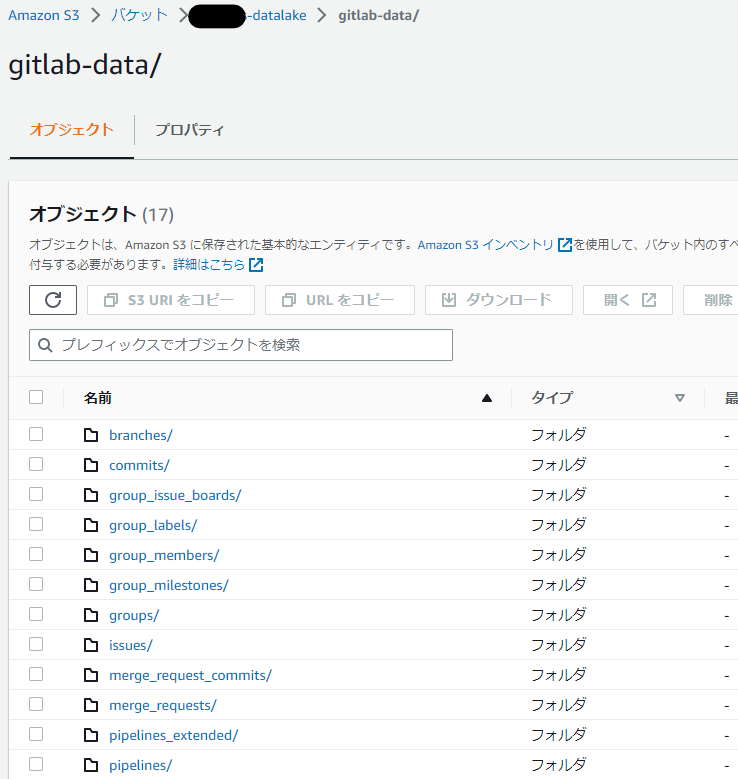
同期完了後にS3を見てみると、GitLabのデータが保存されています。
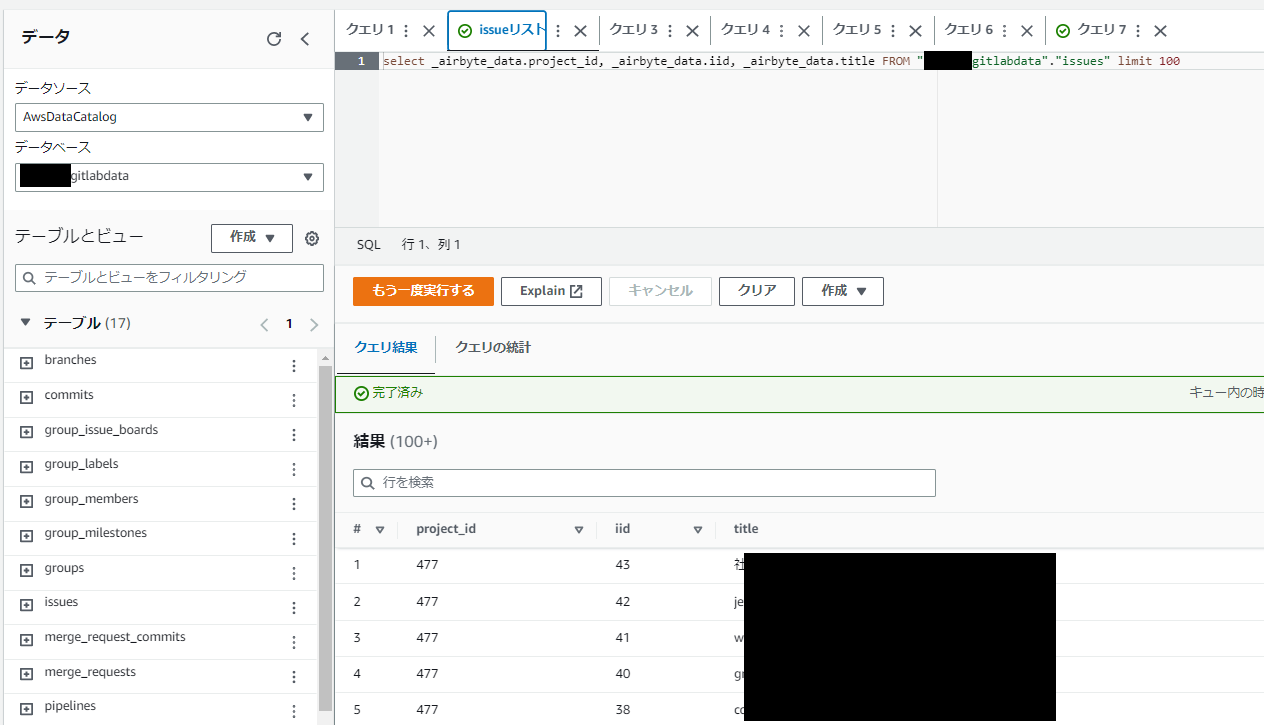
詳しくは次回の記事で説明しますが、Athenaでissueデータを見てみると以下のようにちゃんと格納されています。
次回は、S3に格納されたデータをAWS Glueでカタログ化しAthenaで簡単に分析してみます。
商標
- AWSおよびAWSの各種サービスは、Amazon.com, Inc.またはその関連会社の商標です。
- 記載の会社名、製品名、サービス名等はそれぞれの会社の商標または登録商標です。