scikit-learnで欠損値を補完する場合は、ImputerクラスかSimpleImputerクラスを使います。scikit-learnのバージョンが0.22より前はImputerクラス、0.22以降はSimpleImputerクラスを使います。
次のDataFrameがある場合を考えます。
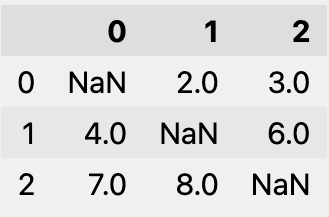
SimpleImputerクラスを使うと、NaNが列ごとの平均値で補完され、NumPyのndarrayで返ります。
from sklearn.impute import SimpleImputer
imp = SimpleImputer(strategy='mean')
imp.fit(df)
imp.transform(df)
▶︎ array([[5.5, 2. , 3. ],
[4. , 5. , 6. ],
[7. , 8. , 4.5]])
その他の選択肢も前処理で使うクラスですが、目的が異なります。前処理で使う主なクラスは以下となります。
■ 欠損値補完 → Imputer
■ カテゴリ変数エンコーディング → LabelEncoder
■ One-hotエンコーディング → OneHotEncoder
■ 分散正規化 → StandardScaler
■ 最小最大正規化 → MinMaxScaler
■ 次元削減(主成分分析) → PCA