他人の方のKaggle KernelでMobileNetが出てきたので、色々調べてみました。
TL;DR
- Googleが2017年(V1)と2018年(V2)に発表した論文。モデルのサイズが小さく、計算量が少なく(アプリの処理待ちなどが短い)、メモリも少なく済んで、精度も他の有名なモデルと比較して、結構高い水準を維持しているモデル。名前の通り、モバイル端末でも耐えうる性能を持つ。
- Mobileと名前に付いているものの、用途はスマホアプリ専用というわけではない。計算リソースに制限のあるサーバーや、リソースのコスパを良くしたい場合、その他ColabolatoryやKaggle Kernelなど、起動時間に制限のある環境などでも便利。
- $α$と$\rho$というハイパーパラメーターを調整することで、ネットワークの深さなどを調整しなくても、さくっと精度と負荷のトレードオフを調整できる。アプリの対応する端末に応じて、パフォーマンスを調整したりがとてもシンプル。
- ハイパーパラメーターを調整したもので、VGG16比でKerasの学習速度が約3倍速、モデルサイズが約180分の1。
- Kerasで簡単に使えるよ。
最近のモデル、重くない?
ディープラーニングの技術は日進月歩で、どんどん進化し、精度が上がっていっています。
一方で、精度ばかりを優先していると、どんどんネットワークが深くなり、計算も多くなり、オーバーフィッティングしないようにデータ量を水増しして・・と多くの計算リソースが必要になってきます。
現実問題として、潤沢な予算を確保して計算リソースを用意するといった、お金という力業で解決できれば楽ですが、普通の会社はそうはなかなかいきません。そもそも導入検証とかのフェーズだと、最初はなるべく安く済ましたいところです(予算の通しやすさ的にも)。
また、モバイル端末でも快適に使えれば、サーバーで推論などを頑張らなくても、数千~数万、もしくはそれ以上のユーザーによる端末を計算リソースとして使え、ディープラーニングを使ったアプリが低コストで実現できます。
そういった点を加味して、「如何に軽く」「如何に早く」「そして精度も結構高い」という点を追及しているモデルとなります。
(学習後のモデルのサイズも小さくなることで、モバイルアプリでのダウンロード時間などの面でも好ましくなります)
なんで早いのさ?
Depthwise Separable Convolutionと呼ばれる、畳み込みの計算を分けてやることで、計算量が減って早くなるそうです。
通常、画像に対して畳み込みを行う場合、縦・横・奥行き(カラーチャンネルなど)といった多次元のデータに対して同時に畳み込みを行いますが、それらを分割して計算しつつ、通常の畳み込みの計算と同じような結果を得る手法となります。
Depthwise(奥行き単位)とあることから分かるように、Z方向の次元で分割がされます。
図でみると少しイメージが付きやすい。

一番上が普通の畳み込み。下二つが分割後のDepthwise Separable Conbvolution。
細かい単位に分割されていることが分かります。
分割することで、計算コストが掛け算で必要だったところが足し算分で済み、ぐぐっとコストが低くなるイメージです。
計算内容の流れを見ても、普通の畳み込みよりもやることは多くなっています。(ただし、必要な計算量は少なくて済む)
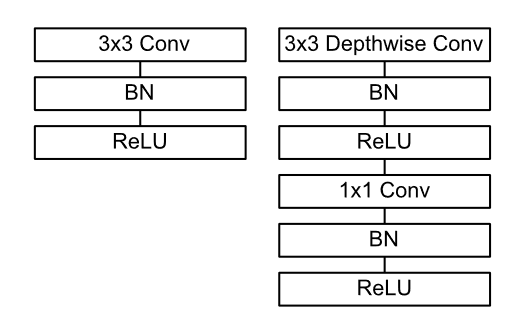
※V1の論文 P4 Figure 3. より
左が通常の畳み込み、右が今回の分割された畳み込みの計算の流れ。
より計算内容など突っ込んだ内容は論文と、加えて動画なども(英語ですが)直観的に図解で分かりやすく説明してくれているものがあったため、必要な場合はご確認ください。
YouTube : Depthwise Separable Convolution - A FASTER CONVOLUTION!
どのくらい計算量が減るの?
条件にもよりますが、V1の方で一般的なカーネルサイズが3 x 3の畳み込みのフィルターで、8~9倍くらい減るそうです。
ただし、V1の方は他の方がまとめてくださっている通り、分割後の1 x 1 x Mの畳み込みの方が計算コスト面でネックになっており、そちらをメインに改善したのがV2の論文となります。そのため、V2ではさらに早く(精度も高く)なっています。
重要なポイントとして、計算量の観点では、conv1x1のほうがボトルネックになっていることが挙げられる。
MobileNet(v1/2)、ShuffleNet等の高速なモデルの構成要素と何故高速なのかの解説
どんなハイパーパラメーターがあるの?
Width Multiplierと、Resolution Multiplierという二つのハイパーパラメーターが出てきます。
二つとも、精度を少しずつ下げつつ、さらにパフォーマンスを上げるための調整値です。MobileNet自体が前述の通り、9倍程度早いネットワークになりますが、アプリ側でさらなるパフォーマンスが要求されるケースで設定します。
(たとえば、精度を少し下げて、快適に使える対象のモバイル端末を増やしたり、サーバーで質より量で、大量の推論のリクエストを捌かないといけないとか)
双方とも、1.0が基本の値で、0.0に近づけていくほど精度が下がる代わりにパフォーマンスが高まります。
Width MultiplierはWidthとあるように、ネットワークの厚みのようなパラメーターで、小さくするほどネットワークが薄くなっていきます。
Resolution Multiplierは、扱うデータ(画像)の解像度的なところが調整されます。
論文上では、Width Multiplierは$α$、Resolution Multiplierは$\rho$(ロー)という記号で表されます。Kerasの引数上でも、引数名がalphaになっています。
それぞれ$\alpha$と$\rho$を使って計算コストを表すと、以下のようになりそれぞれが別の要素に絡んでいることが分かります。そのため、両方ともパフォーマンス調整用のパラメーターであるものの、値を変えた際の挙動が異なります。
D_K・D_K・\alpha M・\rho D_F + \alpha M・\alpha N・\rho D_F・\rho D_F
$\alpha$は、減らすと計算量・パラメーター数(モデルサイズに直結)共に減ります。
値が大分小さい値(0.25など)になると、急激に精度が落ちたりするようです。小さくしすぎには注意、といった感じでしょうか。
$\rho$は、値を小さくしてもパラメーター数は減らず、計算量が少なくなるだけです。ただし、精度の低下が安定していて、急激に精度が落ちたりはしないようです。
モバイルアプリ用などで、通信量的にも削減したい場合にはモデルのサイズも小さくなる$\alpha$、サーバーで大量にリクエストをさばく必要があり、ディスクサイズはそこまで気にならないけれども速度と安定した精度を気にしないといけない場合などには$\rho$といった使い分けなのでしょうか?
もしくは、許容できるサイズまで$\alpha$を下げた後、さらに$\rho$も下げてさらなる計算速度を確保する、とかでもいいかもしれませんね。
精度は良いの?
それぞれ、論文が発表されたタイミングでの精度の高いモデルなどとの比較が論文内で色々ありますが、それらと比べても遜色の無いレベル、比較対象によってはそれらを超えるケースもあるようです。
詳細の確認が必要な場合には、各V1V2の論文の後半の方にいろいろな比較結果が乗っているのでご確認ください。
Kerasで動かしてみた
他人のKaggle Kernelですが、膨大な画像(恐らく3500万枚くらい?)・340という多めのクラス数のコンテストで、高い精度を出しているものがありました。
このレベルになるとメモリがかなりきついので、fit_generator関数などをしっかり使いつつ、対応されています。精度に関してはこれらのカーネルをご参照ください。
Greyscale MobileNet [LB=0.892]
※メモリに乗りきらないような規模を扱うめたのfit_generator関数に関しては以前記事を書いています。
Kerasでメモリに乗りきらない量のデータを扱うための、fit_generator関数を試してみる
精度は置いておいて、学習スピードやファイルサイズなどの確認用に、Kerasでコードを書いて進めてみましょう。
Kaggleで公開されている、Flowers Recognitionの4000程度のデータセットと、それにすぐにアクセスができるKaggle Kernelを使っていきます。数が少なく、オーバーフィッティングがっつりしそうな気配がしますが、学習スピードなどを見たいので、そこは置いておきましょう。

サイズ224 x 224 x 3チャンネル、訓練データ約2000バリデーションデータ約2000といった感じに分け、簡単なData Augmentationをして訓練データを1万強程度にしておきます。
この前処理は本題とはあまり関係ないため、割愛します。適当なコードですが、Kaggle Kernelで公開しておいたため、必要な場合は見るなり焼くなりforkして動かすなりでご利用ください。
V1の方でまずは進めてみます。こちらもカーネルは公開しています。
import os
from keras.applications import MobileNetV2
from keras.applications import MobileNet
from keras.applications import VGG16
from keras.optimizers import Adam
import pandas as pd
import numpy as np
from sklearn import preprocessing
from keras.utils import np_utils
まずはimport。from keras.applicationsパッケージに、有名どころのモデルが用意されており、MobileNetも入っていてさくっと使うことができます。
train_meta_df = pd.read_csv('../input/meta.csv')
test_meta_df = pd.read_csv('../input/test_meta.csv')
続いてデータの準備。これは、前処理のカーネルで準備したデータを参照してX_train, y_train, X_test, y_testといったデータを準備するための読み込み処理なので説明を省略します。
NUM_TRAIN = len(train_meta_df)
NUM_TEST = len(test_meta_df)
IMG_SIZE = 224
NUM_BATCH = 128
NUM_EPOCH = 40
定数定義。バッチサイズ128、エポック数40としてみました。
X_train = np.memmap(
filename='../input/X_train.npy', dtype=np.float16,
mode='r', shape=(NUM_TRAIN, IMG_SIZE, IMG_SIZE, 3) )
y_train = train_meta_df['class'].values
クラスがラベルになっているので、数値に変換しておきます。
le = preprocessing.LabelEncoder()
le.fit(y_train)
NUM_CLASSES = len(le.classes_)
y_train = le.transform(y_train)
test側のデータも同様に対応します。
X_test = np.memmap(
filename='../input/X_test.npy', dtype=np.float16,
mode='r', shape=(NUM_TEST, IMG_SIZE, IMG_SIZE, 3))
y_test = test_meta_df['class'].values
y_test = le.transform(y_test)
y_test = np_utils.to_categorical(y=y_test, num_classes=NUM_CLASSES)
モデルを生成して学習させます。
model = MobileNet(
input_shape=(IMG_SIZE, IMG_SIZE, 3),
alpha=1.0, depth_multiplier=1, weights=None,
classes=NUM_CLASSES)
Width MultiplierはKeras上ではalphaという引数名になっています。
weightsによる重みの指定は、Noneを指定しないと学習済みの重みがネットからダウンロードされるようなので、ランダムな値で初期化するため、Noneを指定しておきます。
また、まずはハイパーパラメーターは両方とも低くせず、1を指定しておきます。
model.compile(
loss='categorical_crossentropy', optimizer=Adam(), metrics=['accuracy'])
model.fit(
x=X_train, y=y_train, batch_size=NUM_BATCH, epochs=NUM_EPOCH,
verbose=2, validation_data=(X_test, y_test))
Train on 10413 samples, validate on 2000 samples
Epoch 1/40
- 141s - loss: 1.2387 - acc: 0.4775 - val_loss: 4.3266 - val_acc: 0.3470
Epoch 2/40
- 124s - loss: 0.9116 - acc: 0.6478 - val_loss: 6.1653 - val_acc: 0.3075
Epoch 3/40
- 123s - loss: 0.7028 - acc: 0.7341 - val_loss: 4.9408 - val_acc: 0.2830
Epoch 4/40
- 123s - loss: 0.5474 - acc: 0.8028 - val_loss: 2.9661 - val_acc: 0.4460
Epoch 5/40
- 123s - loss: 0.4305 - acc: 0.8428 - val_loss: 3.8309 - val_acc: 0.4230
...@
大体、2エポック目以降、123秒くらいで1エポック学習が進むようです。
モデルを保存して、サイズを確認してみましょう。
model.save(filepath='./model.h5')
ls -lht
-rw-r--r-- 1 root root 38M Nov 27 13:23 model.h5
この条件で、38MBくらいのサイズのようです。モバイル端末でも一応使えそうですが、少しダウンロードするには大きいファイルとも言えます。
サイズを小さくするため、Width Multiplierのハイパーパラメーターを0.5に下げてみましょう。
こちらもKaggle Kernelは公開しておいたため、もし必要であればforkして試してみたりしてください。
model = MobileNetV2(
input_shape=(IMG_SIZE, IMG_SIZE, 3),
alpha=0.5, depth_multiplier=1, weights=None,
classes=NUM_CLASSES)
変えたのは上記のalphaのハイパーパラメーターのところのみです。
Train on 10413 samples, validate on 2000 samples
Epoch 1/40
- 143s - loss: 1.3415 - acc: 0.4105 - val_loss: 7.2139 - val_acc: 0.2565
Epoch 2/40
- 94s - loss: 1.0481 - acc: 0.5683 - val_loss: 3.4594 - val_acc: 0.3585
Epoch 3/40
- 94s - loss: 0.8927 - acc: 0.6415 - val_loss: 3.7705 - val_acc: 0.3890
Epoch 4/40
- 94s - loss: 0.7517 - acc: 0.7066 - val_loss: 2.5202 - val_acc: 0.5210
Epoch 5/40
- 93s - loss: 0.6291 - acc: 0.7595 - val_loss: 5.2448 - val_acc: 0.3810
...
学習速度が2エポック目以降の比較で、123秒から94秒くらいになりました。単純にがくっと下がるわけではなく、他のボトルネックの個所の影響で、ある程度秒数はかかるといった感じでしょうか?
-rw-r--r-- 1 root root 8.7M Nov 29 13:55 model.h5
サイズは8.7MBとなりました。こちらはぐぐっと下がっていますね!
1GBのスマホゲームも珍しくないご時世なので、この規模のサイズであればダウンロードも問題ないですし、まめにモデルの更新で再ダウンロードが走るのも現実的です。
ついでに比較でVGG16のモデルで学習してみましょう。
Kaggle Kernel : https://www.kaggle.com/simonritchie/vgg16-mobilenetv1
なお、MobileNetと比べてパラメーターが多い分GPUメモリを多く必要とするためか、バッチサイズが128のままだとGPUメモリのエラーとなりました・・。
64に下げて進めましたが、そういったバッチサイズを小さくしないといけない、という点でも速度的に少し不利になるかもしれませんね。
また、時間がかかるのと最初の方だけ学習できれば、速度とサイズ的なところは見えると思いますので、エポック数を減らしておきます。
NUM_BATCH = 64
NUM_EPOCH = 5
...
model = VGG16(
weights=None,
input_shape=(IMG_SIZE, IMG_SIZE, 3),
classes=NUM_CLASSES)
バッチサイズとエポック数とモデルの個所だけ変更。
Train on 10413 samples, validate on 2000 samples
Epoch 1/5
- 368s - loss: 1.6020 - acc: 0.2367 - val_loss: 1.6026 - val_acc: 0.2470
Epoch 2/5
- 307s - loss: 1.5970 - acc: 0.2355 - val_loss: 1.6019 - val_acc: 0.2470
Epoch 3/5
- 306s - loss: 1.5968 - acc: 0.2372 - val_loss: 1.6031 - val_acc: 0.2470
Epoch 4/5
- 306s - loss: 1.5969 - acc: 0.2416 - val_loss: 1.6018 - val_acc: 0.2470
Epoch 5/5
- 306s - loss: 1.5968 - acc: 0.2363 - val_loss: 1.6036 - val_acc: 0.2470
2エポック以降306秒程度。Kerasで動かす際にも数倍程度は速度に差が出るようです。
サイズも見てみます。
ls -lht
-rw-r--r-- 1 root root 1.6G Nov 29 13:07 model.h5
1.6GB・・ある程度想定はしていましたが、サイズの方は圧倒的に変わります。Width Multiplierが0.5のMobile Netと比べると180倍くらいでしょうか。
スマホアプリでダウンロードさせようとするものならユーザーから怒られてしまうレベルです。(結構衝撃的な差ですね・・)
最後に、おまけでV2の方もWidth Multiplier = 0.5で動かしてみます。
Kaggle Kernel : https://www.kaggle.com/simonritchie/mobilenetv2-0-5-1
モデルの生成の個所だけ変更します。
model = MobileNetV2(
input_shape=(IMG_SIZE, IMG_SIZE, 3),
alpha=0.5, depth_multiplier=1, weights=None,
classes=NUM_CLASSES)
Train on 10413 samples, validate on 2000 samples
Epoch 1/40
- 143s - loss: 1.3415 - acc: 0.4105 - val_loss: 7.2139 - val_acc: 0.2565
Epoch 2/40
- 94s - loss: 1.0481 - acc: 0.5683 - val_loss: 3.4594 - val_acc: 0.3585
Epoch 3/40
- 94s - loss: 0.8927 - acc: 0.6415 - val_loss: 3.7705 - val_acc: 0.3890
Epoch 4/40
- 94s - loss: 0.7517 - acc: 0.7066 - val_loss: 2.5202 - val_acc: 0.5210
Epoch 5/40
- 93s - loss: 0.6291 - acc: 0.7595 - val_loss: 5.2448 - val_acc: 0.3810
うん・・?論文見てみた限り、V1の上位互換かと思いましたが、学習速度はV1とそこまで変わらないのでしょうか?(他のボトルネックで引っかかっている?)
-rw-r--r-- 1 root root 8.7M Nov 29 13:55 model.h5
サイズは一緒です。
速度が速くなるのを期待していましたが、変わらないようで、Kerasの使い方が間違っているのか、まだ今年の論文なので、今後のKerasのアップデートで変わるのかなんとも言えませんが、V2に関してはまだ日が浅い影響なのかネットの記事もあまり見つからないので、深追いはまだしないでおこうと思います。
余談 : 時間節約で、各所のコードや検証など、適当なところも結構あるためマサカリは弱めにお願いします。