結構前にPandasやDaskなどよりも大分高速と話題になっていたPythonのVaexライブラリについて、仕事で利用していきそうな気配がしているので事前にしっかり把握しておくため、色々調べてみました。
どんなライブラリなのか
- Pandasと同じように行列のデータフレームなどを扱うことのできるPythonライブラリです。
- Pandasと比較して膨大なデータの読み込みや計算などを高速に行えます(数十倍~数百倍といったレベルで)。
- 計算上のメモリ効率がとても良く、無駄の少ない実装になっています。
- Daskのように計算が遅延評価されたりと、通常はメモリに乗りきらないデータでも扱うことができます。
- Daskのように並列処理で計算を行ってくれます。
- Pandasと比較的似たインターフェイスで扱うことができます。
この記事で触れること
主に以下のVaexのトピックに関して本記事で触れます。
- インストール関係
- カラムへのアクセス
- スライス制御
- 各種要約統計量の計算
- データの選択(selectとselection)
- 各種データの読み込み処理・データフレーム変換
- データフレームの書き出し処理・各データフォーマットへの変換
- JOIN
- GROUP BY
- 各種文字列操作
- 複数の処理を繋げるためのExpression制御
- カラム操作
- 欠損値制御
- 独自の関数の登録(register_function)とapply
この記事で触れないこと
- Vaexでの機械学習関係のものなどは割愛します。あくまで基本的なPandasに近いところの使い方のみ触れていきます。
- Vaexのプロット関係もスキップします(集計などをVaexで高速にやって、結果のプロットはVaexのインターフェイスではなくmatplotlibやPandasなどでもいいかなと判断しました)。
- JIT(Numba)コンパイラ関係などは割愛します。
- PandasやDaskなどとのパフォーマンス比較などはこの記事では触れません。機会があれば別の記事で書くかもしれません。直近で必要な場合は既に他の方が比較されていたり公式含めTwitterで流れていたりするので、英語圏の情報が多くなりますがそちらをご確認ください。以下にリンクなどのみ貼っておきます。
【参考】
Pandasで行うデータ処理を100倍高速にするOut-of-CoreフレームワークVaex
大規模なテーブルデータを扱うツールの比較検証記事。Vaexが一番、PySparkが次点。Vaexは機能充実面で見劣りする点があるものの、書きやすさ(PySparkはこの点難あり)、データ処理パイプラインの組みやすさ、メモリ/処理効率性に欠かせない遅延評価の実装があり良いとの結果。 https://t.co/sF6dVnlpWm
— piqcy (@icoxfog417) June 1, 2020
Streaming 1 billion rows directly from S3 at more than 1GB/s using @vaex_io and @ApacheArrow (previously limited to 300MB/s). Should be released soon in Vaex v4 🎉 pic.twitter.com/wTcRK5gDdq
— Maarten A. Breddels (@maartenbreddels) October 30, 2020
環境の準備とインストール
どうやらこの記事を書いている時点で公開されているVaexのバージョンでは以下のようなものがあるようです。
- 4.0.0a -> α版と見られるバージョン。
- 3.0.0 -> PyPI上は最新バージョンとされている。
- 2.6.1 -> 2020年6月に公開された、Vaex2系の最終バージョン。
最初3.0.0でいいのかな?と思って色々インストールを試みていたのですが、いまいちインストールがうまくいきません。4.0.0a系もまだ不安定だと思いますので、今回はVaex==2.6.1を利用していくことにします(3系も恐らくそのうちバージョンアップなどでもっとインストールが楽になったり安定してくるでしょう・・・)。
公式ドキュメントだとAnacondaなどでのインストールが推奨されていますが、うちの会社の場合今年のAnaconda有料化による会社規模に抵触してしまうことを加味して、今回はAnacondaを使わずにDockerで環境を用意しました(Jupyterのイメージを利用)。
FROM jupyter/datascience-notebook:python-3.8.6
RUN pip install vaex==2.6.1
RUN pip install jupyter-contrib-nbextensions==0.5.1
RUN jupyter contrib nbextension install --user
RUN jupyter nbextension enable hinterland/hinterland \
&& jupyter nbextension enable toc2/main
このイメージではOSや他の(記事中で利用する)ライブラリは以下のバージョンとなっています。
- Ubuntu 20.04.1 LTS
- numpy==1.19.4
- pandas==1.1.4
また、コードの実行にはJupyter notebookを利用していきます。
とりあえず動かしてみる
正常にVaexのインストールがされたか最低限のものを動かしてみて確認してみます。
Vaexのexample関数でデータフレームの読み込みができる・・・とドキュメントに書かれていますが、今回使うバージョンだと404エラーになったので、Pandasなどを経由してVaexのデータフレームを用意しました。
import vaex
import pandas as pd
pandas_df = pd.DataFrame(
data=[{
'a': 1,
'b': 2,
}, {
'a': 3,
'b': 4,
}])
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
vaex_df

インデックス部分がPandasなどと比べると特殊な表示?(タグがうまく効いていない?)ですがとりあえずは動いたようです。
Vaexの使い方
特定カラムへのアクセス
特定のカラムへのアクセスはPandasのようにdf['<カラム名>']とする方法と、df.<カラム名>とする方法の両方を扱うことができます。
vaex_df['a']
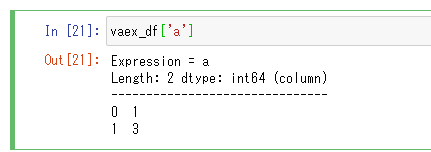
vaex_df.a
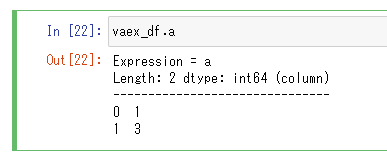
また、Pandasに無かった書き方として、df.col.<カラム名>といった書き方も存在します。
vaex_df.col.a
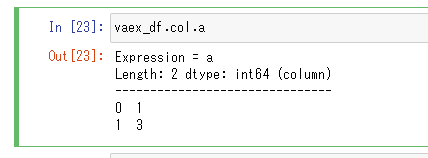
サンプル用のデータフレームの準備
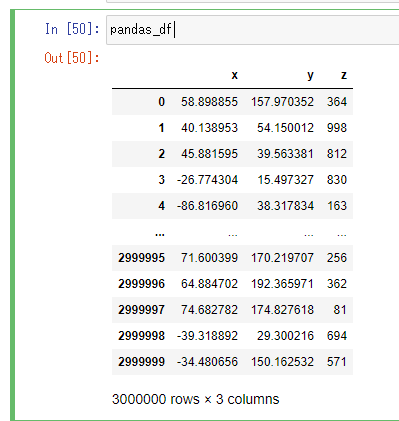
以降の節ではそれなりのサイズのデータフレームで扱いたいため、Vaexのドキュメントに合わせて300万行・x, y, zという3つのカラムを持ったデータフレームを用意します。
import numpy as np
pandas_df = pd.DataFrame(
columns=['x', 'y', 'z'],
index=np.arange(0, 3000000))
pandas_df.x = np.random.uniform(low=-100, high=100, size=len(pandas_df))
pandas_df.y = np.random.uniform(low=0, high=200, size=len(pandas_df))
pandas_df.z = np.random.randint(low=0, high=1000, size=len(pandas_df))
pandas_df
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
特定のカラムの値をメモリに持つ
Vaexは計算が遅延評価されたりするので、多くの処理の過程ではメモリに全てのデータが乗ってきませんが、特定のカラムの値がメモリ上に必要になった場合などにはPandasと同様に該当のカラムのvalues属性でNumPy配列を取得することができます。
numpy_arr = vaex_df.x.values
numpy_arr
array([ 58.89885537, 40.13895255, 45.8815954 , ..., 74.68278245,
-39.31889174, -34.48065571])
スライス制御
任意の条件の箇所のみの抽出処理のスライスはPandasと同じように、比較の演算子を使うことで真偽値の配列を取得することができ、そちらをデータフレームに指定することで行うことができます。
vaex_df.x < 0
Expression = (x < 0)
Length: 3,000,000 dtype: bool (expression)
------------------------------------------
0 False
1 False
2 False
3 True
4 True
...
2999995 False
2999996 False
2999997 False
2999998 True
2999999 True
sliced_df = vaex_df[vaex_df.x < 0]
sliced_df
AND条件やOR条件のスライスに関してもPandasと同じように()の括弧や&、|の記号を使って対応ができます。
pandas_df = pd.DataFrame(
data=[{
'a': 60,
'b': 300,
}, {
'a': 200,
'b': 50,
}, {
'a': 120,
'b': 110,
}])
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
sliced_df = vaex_df[(vaex_df.a > 100) & (vaex_df.a < 150)]
print(sliced_df)
# a b
0 120 110
sliced_df = vaex_df[(vaex_df.a == 60) | (vaex_df.a == 120)]
print(sliced_df)
# a b
0 60 300
1 120 110
否定条件に関してもPandas同様に~の記号で対応できます。
sliced_df = vaex_df[~(vaex_df.a == 200)]
print(sliced_df)
# a b
0 60 300
1 120 110
行の先頭と末尾を表示する
Vaexでデータフレームの行の先頭と末尾を表示するのはPandasとインターフェイスは同じでheadとtailメソッドとなります。引数も対象行数のnと一緒です。ただしVaexの方はnのデフォルト値が10、Pandasはデフォルト値が5と僅かに実装が異なります。
pandas_df = pd.DataFrame(
data=[{
'a': 1,
}, {
'a': 2,
}, {
'a': 3,
}, {
'a': 4,
}])
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
print(vaex_df.head(n=2))
# a
0 1
1 2
print(vaex_df.tail(n=2))
# a
0 3
1 4
要約統計量の計算
count, mean, maxなどの要約統計量の計算もほぼPandasと同じようにできます。ただし細かいところの挙動はPandasと異なっています。
データフレームのcountメソッドであれば、Vaexの方は1つの値が返る一方で、Pandasの場合は各カラムごとの値の返却値が設定されます。
vaex_df.count()
array(3000000)
※array(...)といった出力になっていますが、配列ではなく単一のスカラー値のようで、以下のように整数にキャストしたりもできます。
int(vaex_df.count())
3000000
pandas_df.count()
x 3000000
y 3000000
z 3000000
dtype: int64
meanなどはVaex側は第一引数にexpressionという引数が必須になっており、データフレームに対するメソッドが引数無しでは呼べません。Pandas側は引数無しで呼んだ場合には各カラムごとの平均値などが算出されます。
expressionの引数には単一のカラムの指定を行います。例えばxカラムのみの平均を出したい場合にはexpression='x'といったように指定します。
vaex_df.mean(expression='x')
array(0.023128)
もしくはexpression=df.xといったようにカラムを指定する形でも同じ結果を得られます。
vaex_df.mean(expression=vaex_df.x)
array(0.023128)
Pandas同様に、データフレームと同じ名称のメソッドはカラムのデータ(シリーズのデータ)にも存在するため、そちらを対象する形の書き方もできます。こちらはexpressionの必須の引数は無いため引数を省略して実行することができます。
vaex_df.x.mean()
array(0.023128)
複数のカラムに対してまとめてmeanやmaxなどを反映したい場合には、expression=['x', 'y']といったようにリストで複数のカラムを指定します。
vaex_df.mean(['x', 'y'])
array([2.31280008e-02, 1.00049438e+02])
Pandasの場合はデータフレームで引数を指定してmeanなどを実行すると、一通りのカラムに対する計算結果が返却されます。
pandas_df.mean()
x 0.023128
y 100.049438
z 499.572456
dtype: float64
他にもmaxなどの諸々の要約統計量のためのメソッドは存在し、同じような感覚で扱えます。
vaex_df.x.max()
array(99.99987536)
Vaexでは以下の要約統計量などのメソッドが用意されています。ほぼPandasなどと同じではありますが、次の節からそれぞれを細かく触れていきます。
- count : 欠損値以外の行数を計算します。
- mean : 平均値を算出します。
- std : 標準偏差を算出します。
- var : 分散を算出します。
- min : 最小値を算出します。
- max : 最大値を算出します。
- minmax : 最小値と最大値を同時に計算します。
- correlation : 相関を算出します。
※中央値やパーセンタイル、最頻値関係もインターフェイスがあったのですが、何だかエラーになっていた(且つ検索してもヒットしない)ので本記事ではスキップします。
また、相互情報量(mutual_information)などもインターフェイスがありましたが、私の用途だと利用機会が今の所無さそうなのでそちらもスキップしています。
欠損値以外の行数を計算する : countメソッド
countメソッドは欠損値などを除いた有効な値の行数をカウントします。
試しにxとyの2つの列で1000行のデータフレームを用意してみます。xカラムの方は200行欠損値を設定しておきます。
na_existing_pandas_df = pd.DataFrame(
columns=['x', 'y'], index=np.arange(0, 1000))
na_existing_pandas_df.x = np.random.randint(
low=0, high=100, size=len(na_existing_pandas_df))
na_existing_pandas_df.y = np.random.randint(
low=0, high=100, size=len(na_existing_pandas_df))
# 200行分欠損値を設定しています。
na_existing_pandas_df.x[:200] = np.nan
na_existing_vaex_df = vaex.from_pandas(
df=na_existing_pandas_df, copy_index=False)
expression引数にアスタリスクの文字やNoneを指定した場合は、各カラムに対していずれかのカラムの値が欠損値でなければ有効な行としてカウントされます(今回のサンプルではyカラム側は欠損値になっていないので結果は1000行となります)。
na_existing_vaex_df.count(expression='*')
array(1000)
na_existing_vaex_df.count(expression=None)
array(1000)
expressionに特定の列のみを指定した場合にはその列のみを参照して有効な行数がカウントされます。
na_existing_vaex_df.count(expression=na_existing_vaex_df.x)
800
na_existing_vaex_df.count(expression='x')
array(800)
平均を求める : meanメソッド
Pandasなどでもお馴染みのmeanメソッドは平均値を出します。データフレームの場合expressionは前述までのものと同様に必須の引数となります。
pandas_df = pd.DataFrame(
data=[{
'a': 100,
}, {
'a': 200,
}, {
'a': 100,
}])
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
vaex_df.mean(expression=vaex_df.a)
array(133.33333333)
標準偏差や分散を求める : var, stdメソッド
varメソッドで分散、stdメソッドでは標準偏差を求められます。これもPandasでお馴染みですね。
ただ、他のメソッドは返却値がarray(...)という形式でしたが、stdメソッドではnp.float64の型で返ってきました。統一されていない?のが少々疑問ですが、将来のバージョンでは変わっているかもしれません。
vaex_df.var(expression='a')
array(2222.22222222)
vaex_df.std(expression='a')
47.140452079103135
最小値と最大値を求める : min, maxメソッド
こちらもお馴染みです。minメソッドで最小値・maxメソッドで最大値が取れます。
pandas_df = pd.DataFrame(
data=[{
'a': 60,
}, {
'a': 200,
}, {
'a': 100,
}, {
'a': 130,
}, {
'a': 30,
}])
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
vaex_df.min(expression=vaex_df.a)
array(30)
vaex_df.max(expression=vaex_df.a)
array(200)
最小値と最大値を同時に計算する : minmaxメソッド
minmaxメソッドはPandasなどには無い?気がしますが、どうやらその名前のままに最小値と最大値の2つの値を格納した配列を返すメソッドのようです。
vaex_df.minmax(expression=vaex_df.a)
array([ 30, 200])
相関を求める : correlationメソッド
2つのカラムなどの相関を求めるにはcorrelationメソッドを使います。Pandasだとcorrメソッドなので少しメソッド名が異なります。
expressionという引数ではなく、xとyの2つの値で指定します。また、expressionで指定していたようなdf.xみたいなカラムを直接指定するやり方だとエラーになりました。今回の記事で使っているバージョンではxとyにそれぞれのカラム名の文字列を指定する必要があるようです。
pandas_df = pd.DataFrame(
data=[{
'a': 60,
'b': 300,
}, {
'a': 200,
'b': 50,
}, {
'a': 100,
'b': 110,
}, {
'a': 130,
'b': 90
}, {
'a': 30,
'b': 360,
}])
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
vaex_df.correlation(x='a', y='b')
array(-0.90936348)
特定条件のデータの選択 : selectメソッドとselection
スライスに似たようなものとなりますが、Vaexにはselectというメソッドがあり、スライス条件のようなものを設定しておくことができます。
スライスと何が違うんだ?という感じですが、データフレーム自体の変数は1つ(スライスで別の変数を用意したりせず)に、複数条件のサブセットのデータフレームで処理を行うといったことができます。
使い方は様々ですが、例えばこれによって変数は1つのまま、且つ元のデータフレームに影響を出すことなく10個の各条件のプロットを行う・・・みたいなことも可能となります。
selectメソッドではboolean_expressionの引数にスライスで指定するような条件の真偽値の条件を指定します。
pandas_df = pd.DataFrame(
data=[{
'a': 60,
}, {
'a': 200,
}, {
'a': 100,
}, {
'a': 130,
}, {
'a': 30,
}])
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
vaex_df.select(boolean_expression=vaex_df.a > 70)
このままでは特に該当のデータフレームは影響がありません。要約統計量などを出してみても特に結果は変わりません。
vaex_df.minmax(expression=vaex_df.a)
array([ 30, 200])
要約統計量のメソッドなどにあるselection引数にTrueを指定することで初めてselectで指定した条件が有効になって結果が返ってきます。下記のサンプルではselectメソッドで指定した70以上という条件が有効になっていることが確認できます。
vaex_df.minmax(expression=vaex_df.a, selection=True)
array([100, 200])
もう一度selectメソッドで条件を指定した場合は、and条件とはならずに条件の上書きとなるようです。
vaex_df.select(boolean_expression=vaex_df.a < 150)
vaex_df.minmax(expression=vaex_df.a, selection=True)
array([ 30, 130])
また、selectメソッドにはname引数で選択条件に名前を付けることができます。別の名前を付けていくことで、複数の選択条件を保持させることができます。
vaex_df.select(boolean_expression=vaex_df.a > 70, name='greater_than_70')
vaex_df.select(boolean_expression=vaex_df.a < 130, name='less_than_130')
要約統計量などのメソッドのselection引数にて、真偽値の代わりにselectメソッドで指定した名前を設定するとその選択範囲の条件が反映された形で結果が返ってきます。
vaex_df.minmax(expression=vaex_df.a, selection='greater_than_70')
array([100, 200])
vaex_df.minmax(expression=vaex_df.a, selection='less_than_130')
array([ 30, 100])
加えて、事前にselectメソッドを設定しておかなくても要約統計量のメソッド実行時のselection引数に直接条件を書くこともできます。例えば「aカラムの値が120以上の行」みたいな条件を指定したい場合にはselection引数に以下のような文字列を指定します。
vaex_df.sum(expression='a', selection='a >= 120')
array(330)
否定条件の~やAND条件の&、OR条件の|などはスライスと同じようにselection(select)でも使うことができます。
vaex_df.sum(expression='a', selection='~(a == 100) & ~(a == 130)')
array(290)
リストなどのベクトルデータでスライスする
VaexでもPandas同様に、カラムがisinのメソッドを持っているのでそちらを使ってNumPy配列やリスト、タプルなどに含まれる行のみ(もしくは~記号を使って含まれない行のみ)にスライスすることができます。
pandas_df = pd.DataFrame(
data=[{
'a': 60,
}, {
'a': 200,
}, {
'a': 100,
}, {
'a': 130,
}, {
'a': 30,
}])
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
a_column = vaex_df.a
sliced_df = vaex_df[vaex_df.a.isin([100, 200])]
print(sliced_df)
# a
0 200
1 100
※注記 : 今回の記事で使っているVaexのバージョンでは、文字列のカラムに対するisinは大分遅いようです。速くした修正自体はマージされており、恐らくVaexの3系や4系のバージョンでは速くなっていると思われます。
参考 :
Vaexのデータ読み込み処理
Daskと同様にファイル経由であったりメモリ上のものからデータフレームを用意するための様々な関数が用意されています。以下のものをそれぞれ見ていきます。
- from_csv : CSVファイルから読み込みます。
- open : HDF5やParquetなどのバイナリファイルを開いてデータフレームを読み込みます。
- openmany : 複数のバイナリファイルなどを連結した形でデータフレームを読み込みます。
- from_ascii : タブ区切りなどのテキストファイルを読み込みます。
- from_arrays : NumPy配列などのiterableオブジェクトからデータフレームを作成します。
- from_dict : 辞書からデータフレームを作成します。
- from_items : 古いPythonバージョンでカラム順を保持した形でiteraboleオブジェクトからデータフレームを作成します。
- from_json : JSONファイルから読み込みます。
- from_pandas : PandasのデータフレームからVaexのデータフレームを作成します。
- from_scalars : 単一のスカラー値から1行のデータフレームを作成します。
from_csv関数
from_csv関数はCSVの読み込みを制御します。Pandasのread_csvに該当します。
まずは挙動確認用に、Pandas経由でCSVを保存しておきます。
pandas_df.to_csv('sample_data.csv', index=False, encoding='utf-8')
第一引数にパスを指定します。
vaex_df = vaex.from_csv('sample_data.csv', copy_index=False)
print(vaex_df)
# a
0 60
1 200
2 100
3 130
4 30
他の関数もそうですが、copy_indexにFalseを指定しない場合はインデックスと同じ値のindexという名前のカラムがデータフレームに追加されます。
vaex_df = vaex.from_csv('sample_data.csv')
print(vaex_df)
# a index
0 60 0
1 200 1
2 100 2
3 130 3
4 30 4
なお、docstringには以下のように書かれています。
Shortcut to read a csv file using pandas and convert to a DataFrame directly.
Pandas経由で読み込んで変換しているとのことです。つまりCSVの読み込みではPandasよりも速度は速くなりません。
また、内部でPandasが使われているので、Vaex側のfrom_csvでの**kwargs部分にPandasの引数を指定しても動作しました。例えば以下のようにnrows引数を指定してみると、結果の行数がちゃんと少なくなっていることを確認できます。
vaex_df = vaex.from_csv('sample_data.csv', copy_index=False, nrows=2)
print(vaex_df)
# a
0 60
1 200
Pandasのものが使われているので、以下のように圧縮ファイルなどもVaex自体の関数には引数設定などはありませんがPandas同様に読み込むことが出来ます。
pandas_df.to_csv(
'sample_data.csv.gz', index=False, encoding='utf-8',
compression='gzip')
vaex_df = vaex.from_csv(
'sample_data.csv.gz', copy_index=False, compression='gzip')
print(vaex_df)
# a
0 60
1 200
2 100
3 130
4 30
open関数
open関数はHDF5などのバイナリの読み込みを行うことができます。
まずはVaexの記事でよく見かけるHDF5について触れていきます。HDF5に関しては以下の記事を以前書いているのでそちらをご確認ください。
まずは読み込み処理を扱うためにVaexのインターフェイスでHDF5のファイルを保存しておきます。export_hdf5で実行することができます。
pandas_df = pd.DataFrame(
data=[{
'a': 60,
'b': 300,
}, {
'a': 200,
'b': 50,
}, {
'a': 100,
'b': 110,
}, {
'a': 130,
'b': 90
}, {
'a': 30,
'b': 360,
}])
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
vaex_df.export_hdf5('sample_data.hdf5')
圧縮設定などは無いのかな?と思いましたが、どうやらissueがこの記事を介している時点ではissueはあるもののOpenなままなようです。そのうち将来のバージョンでサポートされるかもしれません。
参考 : Add support for compressed HDF5 files. #101
h5pyで保存されたHDF5の内部構造を見てみると、以下のような階層になっているようです(aやbといった部分が元のデータフレームのカラム名に該当します)。
/table/columns/a/data
/table/columns/b/data
この階層構造はPandasなどとは異なります。試しにPandasでHDF5を保存してみると以下のような構造になっています。
pandas_df.to_hdf('sample_data_pandas.hdf5', key='table', mode='w')
/table/axis0
/table/axis1
/table/block0_items
/table/block0_values
そのためPandasで保存したHDF5をVaexで読み込もうとしてもエラーになります。この辺りは正直統一されていたら嬉しかった・・・感じはあります。
vaex_df_from_pandas_hdf = vaex.open('sample_data_pandas.hdf5', copy_index=False)
KeyError: "Unable to open object (object 'columns' doesn't exist)"
まあVaexの方がメモリに乗りきらないデータに対して高速に処理する・・・的な用途なので、基本Vaex用にHDF5で保存して、Pandasで読むためのh5pyを経由したラッパー関数的なものを用意するか、もしくはVaexで読み込んでPandasに変換すればいいだけの話ではあります(HDF5の階層構造的にはVaexの方が分かりやすくすっきりした感じでもありますし)。
Vaexで保存したHDF5側は普通にVaexでそのまま読み込むことができます。
vaex_df_from_pandas_hdf = vaex.open('sample_data.hdf5', copy_index=False)
print(vaex_df)
# a b
0 60 300
1 200 50
2 100 110
3 130 90
4 30 360
続いてParquetについて触れていきます。ParquetもHDF5と同様にopen関数で扱えます。また、HDF5と異なりPandasで保存したものがそのままVaexでも読み込めます。
pandas_df.to_parquet('sample_data.parquet')
vaex_parquet_df = vaex.open('sample_data.parquet')
print(vaex_parquet_df)
# a b
0 60 300
1 200 50
2 100 110
3 130 90
4 30 360
Pandasだとto_parquetのcompressionのデフォルト値がsnappyとなっていますが、圧縮していた場合でもそのままvaexで読み込めるようです。compression引数など省略してもエラーにならないのは楽でいいですね。
なお、Vaexが計算が遅延評価される都合、HDF5のファイルなどをopen関数で開いている状態で同じファイルをexport_hdf5メソッドなどで更新しようとするとエラーになります。
pandas_df = pd.DataFrame(
data=[{
'a': 60,
'b': 300,
}, {
'a': 200,
'b': 50,
}])
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
vaex_df.export_hdf5('sample_data.hdf5')
vaex_df = vaex.open('sample_data.hdf5', copy_index=False)
vaex_df.export_hdf5('sample_data.hdf5')
OSError: Unable to create file (unable to truncate a file which is already open)
このような書き込みのバッティングを避けるためには該当のPythonプロセスが終了するのを待つ(Jupyterであればカーネルが停止するのを待つ)か、もしくはデータフレームでclose_filesメソッドを呼び出すか、書き込みで失敗したら他のものが終わるまで少し待つ形でリトライ制御を組み込むか・・・といった対応が必要になります。
vaex_df = vaex.open('sample_data.hdf5', copy_index=False)
print('...ここで必要な処理を行います...。')
vaex_df.close_files()
vaex_df.export_hdf5('sample_data.hdf5')
インターフェイスとしてはcloseメソッドも存在しますがclose_filesが正しいようです。closeだと試していたところエラーになりました(初見のとき少し紛らわしいですね)。
参考 : Unable to close open file handles with vaex
該当のissueはopenなままなので将来のバージョンでcloseでも閉じれるようになるかもしれません。
openmany関数
openmany関数は複数のファイルを指定することができ、データフレームがconcat的に連結した状態で一気に読み込むことができる関数です。
vaex_df.export_hdf5('sample_data_1.hdf5')
vaex_df.export_hdf5('sample_data_2.hdf5')
vaex_df_from_many_hdf = vaex.open_many(
filenames=[
'sample_data_1.hdf5',
'sample_data_2.hdf5',
])
print(vaex_df_from_many_hdf)
# a b
0 60 300
1 200 50
2 100 110
3 130 90
4 30 360
5 60 300
6 200 50
7 100 110
8 130 90
9 30 360
from_ascii関数
from_ascii関数はコンマ区切りではないテキストファイル(例えばタブ区切りなど)の読み込みに使えます。
試しにPandasでタブ区切りのデータを保存してみます。to_csvメソッドのsep引数にタブを指定することでタブ区切りでデータを保存することができます。
pandas_df.to_csv('sample_data.tsv', sep='\t', index=False, encoding='utf-8')
以下のようなテキストで保存されています。
a b
60 300
200 50
100 110
130 90
30 360
Vaexで読み込んでみます。こちらはPandas経由のデータでも問題なく動作します。separator引数に必要な区切文字を指定します。
tsv_vaex_df = vaex.from_ascii('sample_data.tsv', seperator='\t')
print(tsv_vaex_df)
# a b
0 60 300
1 200 50
2 100 110
3 130 90
4 30 360
from_arrays関数
from_arrays関数はiterableなデータのベクトルからVaexのデータフレームを生成します。キーワード引数に指定した引数名がカラム名になります。例えばNumPy配列のベクトルからデータフレームを作りたい場合には以下のように書きます。
import numpy as np
arr_a = np.array([1, 2, 3])
arr_b = np.array([4, 5, 6])
vaex_df_from_arr = vaex.from_arrays(a=arr_a, b=arr_b)
print(vaex_df_from_arr)
# a b
0 1 4
1 2 5
2 3 6
Create an in memory DataFrame from numpy arrays.
docstringには上記のようにNumPy配列からデータフレームを作成すると書かれていますが、Pythonのリストやタプルでも動作します。また、カラムごとにデータの型が違っても動作します。
vaex_df_from_arr = vaex.from_arrays(a=(1, 2, 3), b=[4, 5, 6])
print(vaex_df_from_arr)
# a b
0 1 4
1 2 5
2 3 6
from_dict関数
from_dict関数はPythonの辞書からVaexのデータフレームを生成します。キーにはカラム名、値に各カラムの値のリストを指定します。
vaex_df_from_dict = vaex.from_dict({'a': [1, 2, 3], 'b': [4, 5, 6]})
print(vaex_df_from_dict)
# a b
0 1 4
1 2 5
2 3 6
from_items関数
from_arrays関数と似たような挙動となりますが、こちらはキーワード引数の名前でカラム名を指定するのではなく、タプルの最初のインデックスにカラム名、次のインデックスにiterableな値を設定する形のデータを指定するようです。
vaex_df_from_items = vaex.from_items(('a', [1, 2, 3]), ('b', [4, 5, 6]))
print(vaex_df_from_items)
# a b
0 1 4
1 2 5
2 3 6
from_arraysがあれば要らなくないか?と思えましたが、どうやらdocstringを読むと以下のようにPython3.6未満のバージョンでキーワード引数で辞書的に順番が保持されない問題を解決するためにこのインターフェイスが設けてあるようです。Python3.6以降ならfrom_arraysで良いと思われます。
Create an in memory DataFrame from numpy arrays, in contrast to from_arrays this keeps the order of columns intact (for Python < 3.6).
Pythonの辞書の値の順番云々は以下のようになっているようです。
Pythonの辞書(dict型オブジェクト)は要素の順番を保持しない。CPythonは3.6から順番を保持しているが、実装依存なのでそのほかの実装では不定。3.7から言語仕様で順番を保持するようになる(らしい)。
Pythonの順序付き辞書OrderedDictの使い方
from_json関数
from_json関数はJSONファイルからデータを読み込みます。Pandasで保存したものがそのままVaexでも使えます。
pandas_df.to_json('sample_data.json')
vaex_df_from_json = vaex.from_json('sample_data.json', copy_index=False)
print(vaex_df_from_json)
# a b
0 60 300
1 200 50
2 100 110
3 130 90
4 30 360
PandasもVaexもお互いにlines引数を持っているので、JSON Linesのフォーマットでも読み込めます。
pandas_df.to_json('sample_data_lines.json', lines=True, orient='records')
vaex_df_from_json = vaex.from_json('sample_data_lines.json', copy_index=False, lines=True)
print(vaex_df_from_json)
# a b
0 60 300
1 200 50
2 100 110
3 130 90
4 30 360
※JSON Linesは以下のような1行単位のJSONのフォーマットです。
{"a":60,"b":300}
{"a":200,"b":50}
{"a":100,"b":110}
{"a":130,"b":90}
{"a":30,"b":360}
from_pandas関数
これまでも大分使ってきましたが、from_pandas関数はメモリ上のPandasのデータフレームからVaexのデータフレームを生成する関数です。
vaex_df_from_pandas = vaex.from_pandas(df=pandas_df, copy_index=False)
print(vaex_df)
# a b
0 60 300
1 200 50
2 100 110
3 130 90
4 30 360
from_scalars関数
from_scalars関数は単一のスカラー値から1行のVaexのデータフレームを生成します。from_arrays関数のようにキーワード引数の引数名がそのままカラム名になります。
vaex_df_from_scalars = vaex.from_scalars(a=1, b=2)
print(vaex_df_from_scalars)
# a b
0 1 2
Vaexのデータ書き出しと変換処理
Vaexでも様々なフォーマットへのデータの書き出しのインターフェイスが存在します。
以降の節では以下のインターフェイスに付いて触れていきます。
- export_hdf5 : HDF5形式のファイルへ保存します。
- export_parquet : Parquet形式のファイルへ保存します。
- export : 拡張子の指定に応じたフォーマットでデータをファイルへ保存します。
- to_arrays : 各カラムのNumPyのベクトルを格納したリストのインメモリのデータへ変換します。
- to_dask_array : Dask配列へと変換します。
- to_dict : キーにカラム名、値にNumPyのベクトルを格納したインメモリのデータへ変換します。
- to_items : カラム名とNumPyのベクトルを格納したインメモリのリストに変換します。
- to_pandas_df : インメモリのPandasのデータフレームへと変換します。
ファイル出力系のプレフィックスがexport_となっており、メモリ上に変数として持つ形の変換のプレフィックスがto_というインターフェイスになっています。
なお、この記事で使っているVaexのバージョンではCSV出力のインターフェイスが無いようです。正式版では無いものの4.0.0のVaexバージョンのドキュメントを見ていたところ、export_csvのインターフェイスがあったので、CSVで出力したい場合にはバージョンを上げるか一度Pandasのデータフレームなどに変換する必要がありそうです。
JSONに関してはこの記事を書いている時点では正式版ではない新しいバージョンでもドキュメント上に見当たらなかったのでまだインターフェイスが無いのかもしれません。
export_hdf5メソッド
ここまででも何度か触れてきましたが、export_hdf5メソッドでHDF5のデータを出力することができます。
注意点としてはこの記事執筆で使っているバージョンの時点では圧縮指定に対応していない点と、階層構造がPandasと異なるためVaex側で書き出したものはダイレクトにPandas側で読み込めないといったところです。
vaex_df.export_hdf5('sample_data.hdf5')
また、書き込みのモードがa(append)などがベースとなる影響なのか、HDFでのクラウド環境(S3など)への書き込みは出来なさそうな気配があります(ドキュメントを見ている感じでは)。
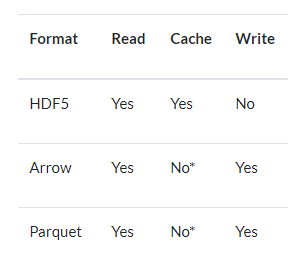
※ドキュメントのI/O Kung-Fu: get your data in and out of Vaexの表から引用。
もしマウントしているS3などで弾かれた場合は一旦別のディスク領域に保存して、そのファイルをS3などにアップする的なことが必要になるかもしれません。
export_parquetメソッド
export_parquetメソッドはParquetのデータをエクスポートできます。
Pandas側で圧縮されたデータでもVaex側でも読み込めますし、Vaex側で保存したデータもPandas側で読み込めます。
vaex_df.export_parquet('sample_data.parquet')
ただしPandas側にはcompression引数があり圧縮が指定できるものの、Vaex側は圧縮関係の引数が無いようです。圧縮はされるのか?未圧縮で保存されるのか?が気になったのでPandas側で各圧縮条件で保存してみて、Vaex経由での保存結果と比較してみました。
200万行2列の整数のサンプルデータを用意して進めます。
import numpy as np
vaex_df = vaex.from_arrays(
a=np.random.randint(0, 1000000, size=2_000_000),
b=np.random.randint(0, 100, size=2_000_000))
vaex_df.export_parquet('disk_size_comparison_vaex.parquet')
pandas_df = vaex_df.to_pandas_df()
pandas_df.to_parquet(
'disk_size_comparison_pandas_snappy.parquet', compression='snappy')
pandas_df.to_parquet(
'disk_size_comparison_pandas_gzip.parquet', compression='gzip')
pandas_df.to_parquet(
'disk_size_comparison_pandas_no_compression.parquet', compression=None)
比較結果としては以下のようになりました。
- Vaex側でexport_parquet: 11618KB
- Pandas側でsnappy(デフォルト)圧縮 : 11619KB
- Pandas側でgzip圧縮 : 8602KB
- Pandas側で未圧縮指定 : 17578KB
Pandas側でsnappy(Pandas側のデフォルト設定)で書き出した時とVaex側で書き出したときがほぼ同じサイズなようです。どうやらVaex側で保存した場合snappy圧縮で扱われるようです。
Pandas側でsnappyがデフォルトになっていることから分かるように、snappyが速度と圧縮率でバランスが良い選択ですし、Vaex側で圧縮方式を指定しなくても(gzipなどでも)自動判別してくれて読み込んでくれるようなので、シンプルで楽ではあります。
exportメソッド
exportメソッドは、指定したファイルパスの拡張子に応じて出力するファイルを決定するメソッドです。
例えば以下のようにhdf5と拡張子がなっていればHDF5で保存されます。
vaex_df.export('sample_data.hdf5')
対応していない拡張子名の場合はファイルは保存されません。例えばh5などの拡張子を指定してもファイルが保存されません。
エラーメッセージも出ないようなので気づきづらいので、うっかりミスをしないように少し注意する必要があります。特に理由がなければexport_hdf5などのフォーマットを明示するインターフェイスの利用の方が無難かもしれません。
to_arraysメソッド
to_arraysメソッドはVaexのデータフレームをNumPy配列のリストにして返します。行列としてのNumPy配列で返却されるのかと思ったらどうやらベクトルのNumPy配列をカラム数分格納したリストが返るようです。
pandas_df = pd.DataFrame(
data=[{
'a': 60,
'b': 300,
}, {
'a': 200,
'b': 50,
}, {
'a': 100,
'b': 110,
}])
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
arr = vaex_df.to_arrays()
print(type(arr))
<class 'list'>
print(arr)
[array([ 60, 200, 100]), array([300, 50, 110])]
to_dask_arrayメソッド
to_dask_arrayメソッドはVaexのデータフレームからDaskの配列に変換してくれます。
da = vaex_df.to_dask_array()
da
print(type(da))
<class 'dask.array.core.Array'>
※Daskに関しては以前記事を書いているのでそちらをご参照ください : PythonのDaskをしっかり調べてみた(大きなデータセットを快適に扱う)
to_dictメソッド
to_dictメソッドはデータフレームをPythonの辞書に変換します。キーにはカラム名が設定され、値には各カラムのNumPy配列が設定されます。
dict_val = vaex_df.to_dict()
print(dict_val)
{'a': array([ 60, 200, 100]), 'b': array([300, 50, 110])}
to_itemsメソッド
to_itemsメソッドはカラム数分のタプルを格納したリストを返却します。タプルの最初のインデックスにはカラム名、2番目のインデックスにはそのカラムの値のNumPy配列を格納します。
item_val = vaex_df.to_items()
print(item_val)
[('a', array([ 60, 200, 100])), ('b', array([300, 50, 110]))]
to_pandas_dfメソッド
to_pandas_dfメソッドはその名の通りVaexのデータフレームからPandasのインメモリなデータフレームに変換します。
pandas_df = vaex_df.to_pandas_df()
print(pandas_df)
print(type(pandas_df))
a b
0 60 300
1 200 50
2 100 110
<class 'pandas.core.frame.DataFrame'>
VaexでのJOIN
VaexのJOIN(2つのデータフレームの統合)にはjoinメソッドを使います。Pandasではjoinとmergeの2つのメソッドがあり、joinはインデックス基準・mergeはカラムの値基準といった感じですが、VaexではPandasのmergeがVaexのjoinに近い挙動になります。
Vaexではデータフレームの連結をしてもメモリのコピーが発生したりはしません。
注意すべき点として、Vaexではデフォルトでは左結合(left join)です。また、現在外部結合(outer join)をサポートしていません。左結合・右結合・内部結合(inner join)のみサポートされています。
基本的な使い方はother引数に右側のデータフレームを指定し、onで連結で参照するカラム名を指定するといったように、Pandasのmerge関数とほぼ同じインターフェイスになっています。
age_df = vaex.from_arrays(id=[1, 3, 5], age=[10, 3, 6])
name_df = vaex.from_arrays(id=[1, 5, 7], name=['タマ', 'ミケ', 'ポチ'])
joined_df = age_df.join(other=name_df, on='id')
print(joined_df)
# id age name
0 1 10 タマ
1 3 3 --
2 5 6 ミケ
Pandas同様にhow引数で結合方法をデフォルトの左結合から変更できます。rightやinnerといった指定も同様です。
joined_df = age_df.join(other=name_df, on='id', how='right')
print(joined_df)
# id name age
0 1 タマ 10
1 5 ミケ 6
2 7 ポチ --
joined_df = age_df.join(other=name_df, on='id', how='inner')
print(joined_df)
# id age name
0 1 10 タマ
1 5 6 ミケ
VaexでのGROUP BY
VaexでのGROUP BYについて触れていきます。メソッドはgroupbyとなります。
まずは挙動確認用のデータを準備します。
pandas_df = pd.DataFrame(
data=[{
'type': 'weapon',
'cost': 100,
'strength': 20,
}, {
'type': 'armor',
'cost': 120,
'strength': 15,
}, {
'type': 'weapon',
'cost': 50,
'strength': 8,
}, {
'type': 'weapon',
'cost': 220,
'strength': 32,
}, {
'type': 'armor',
'cost': 200,
'strength': 27,
}])
vaex_df = vaex.from_pandas(df=pandas_df, copy_index=False)
print(vaex_df)
# type cost strength
0 weapon 100 20
1 armor 120 15
2 weapon 50 8
3 weapon 220 32
4 armor 200 27
groupbyのインターフェイスはPandasと一緒で、対象のカラム名をby引数に指定します。
grouped_data = vaex_df.groupby(by='type')
ただし、groupbyメソッドで返却されたオブジェクトに対する制御はPandasと異なります。Pandasでは該当のオブジェクトでさらにcountやsum、firstといったメソッドを実行することでGROUP BYした該当の集計結果のデータフレームが得られますが、Vaexの場合aggメソッドに集約されています(※集計 = aggregation)。PandasのGROUP BY結果のaggregateメソッドに近いインターフェイスとなります。
action引数に辞書を指定して、キーに対象とするカラム名、値に集計方法を指定すると結果が得られます。辞書に複数のカラムを設定した場合は結果のデータフレームのカラムも増えます。
result_df = grouped_data.agg(
actions={
'cost': vaex.agg.sum,
'strength': vaex.agg.mean,
})
print(result_df)
出力結果はPandasと異なりbyで指定したカラムがインデックスに設定されたりはせず、Pandassでreset_indexした時のようにbyで指定したカラムは普通に結果のデータフレームのカラムに含まれるようです。
# type cost strength
0 weapon 370 20
1 armor 320 21
vaex.agg.sumなどの部分は'sum'などの文字列で指定しても同じ挙動をしてくれます。
result_df = grouped_data.agg(
actions={
'cost': 'sum',
'strength': 'mean',
})
print(result_df)
# type cost strength
0 weapon 370 20
1 armor 320 21
VaexのGROUP BYの集計関数で使えるものは以下のものがあります。名前はPandasと一緒ですが、lastなどPandas側に存在するものが一部無かったりはするようです。
- vaex.agg.count: 各グループの件数が設定されます。
- vaex.agg.first: 各グループの先頭の値が設定されます。
- vaex.agg.max: 各グループの最大値が設定されます。
- vaex.agg.min: 各グループの最小値が設定されます。
- vaex.agg.sum: 各グループの合計値が設定されます。
- vaex.agg.mean: 各グループの平均値が設定されます。
- vaex.agg.std: 各グループの標準偏差が設定されます。
- vaex.agg.var: 各グループの分散が設定されます。
- vaex.agg.nunique: 各グループでのユニークな値の件数が設定されます。
集計用の関数を実行し、そちらの引数に対象とするカラム名を指定することで結果のデータフレームのカラム名を変更したり、同じカラムに対して複数の集計関数を反映して結果のデータフレームを得たりすることもできます。
result_df = grouped_data.agg(
actions={
'cost_mean': vaex.agg.mean(expression='cost'),
'cost_min': vaex.agg.min(expression='cost'),
'cost_max': vaex.agg.max(expression='cost'),
})
print(result_df)
# type cost_mean cost_min cost_max
0 weapon 123.333 50 220
1 armor 160 120 200
また、これらの集計用の関数にはselection引数が存在するため、グループ内で対象とする行を細かく制御したりも可能です。
vaex_df.select('cost > 90', name='greater_than_90')
vaex_df.select('cost > 120', name='greater_than_120')
vaex_df.select('cost > 160', name='greater_than_160')
grouped_data = vaex_df.groupby(by='type')
result_df = grouped_data.agg(
actions={
'cost_min_overall': vaex.agg.min(expression='cost'),
'cost_min_gt_90': vaex.agg.min(expression='cost', selection='greater_than_90'),
'cost_min_gt_120': vaex.agg.min(expression='cost', selection='greater_than_120'),
'cost_min_gt_160': vaex.agg.min(expression='cost', selection='greater_than_160'),
})
print(result_df)
# type cost_min_overall cost_min_gt_90 cost_min_gt_120 cost_min_gt_160
0 weapon 50 100 220 220
1 armor 120 120 200 200
Vaexでの文字列操作
Vaexは文字列関係の処理が特に高速とよく言われます。そのため文字列関係も色々扱う機会が出てきそうです。
Vaexでは文字列操作がビルトインでお馴染みの関数名のものも含めたくさんのインターフェイスがあります。
この節以降では以下の文字列操作関係の操作方法やインターフェイスについて触れていきます。
- 基本的な文字列操作のインターフェイスの使い方
- contains : 特定の文字列が含まれているかを判定します。
- equals, match : 特定の文字列と一致するかを調べます。
- find, rfind, index, rindex : 指定の文字(列)がどの位置にあるのかを調べます。
- count : 指定の文字(列)が何文字含まれるかをカウントします。
- startswith, endswith : 特定の文字列で開始しているか / 終了しているかを調べます。
- replace : パターンにマッチした文字列部分を他の文字列で置き換えます。
- get : 特定のインデックス位置の文字を取得します。
- isalnum, isalpha, isdigit, isspace : 文字列が指定の種類で構成されているかを調べます。
- len : 各文字の文字数をカウントします。
- slice : 文字列の範囲をインデックス指定でスライスします。
- capitalize, upper, lower, title : 文字列を特定のフォーマットに変換します。
- isupper, islower : 文字列が特定のフォーマットかどうかを判定します。
- ljust, rjust, center, pad, zfill : 文字詰め(埋め)を行います。
- strip, lstrip, rstrip : 文字列の左右の空白文字を取り除きます。
- repeat : 文字列を指定回数繰り返します。
基本的な文字列操作のインターフェイスの使い方
文字列操作は基本的にPandasと同様にdf.<対象のカラム>.str.<使う操作のインターフェイス>といった使い方となります。例えば文字列のnameカラムでcontainsの文字列操作のインターフェイスを使いたい場合にはdf.name.str.contains(...)といった書き方になります。
特定の文字列が含まれているかを判定する : containsメソッド
containsメソッドは対象のカラムの値で引数に指定した文字列のパターンが含まれている行でTrue、含まれていなければFalseを返します。スライスなどで便利です。
vaex_df = vaex.from_arrays(a=['シャム猫', 'マンチカン', 'スフィンクス'])
vaex_df.a.str.contains(pattern='クス')
Expression = str_contains(a, pattern='クス')
Length: 3 dtype: bool (expression)
----------------------------------
0 False
1 False
2 True
デフォルトでは正規表現がパターンに使えます。
vaex_df = vaex.from_arrays(a=['シャム猫', 'マンチカン', 'スフィンクス', 'ペルシャ猫'])
vaex_df.a.str.contains(pattern='猫$')
Expression = str_contains(a, pattern='猫$')
Length: 4 dtype: bool (expression)
----------------------------------
0 True
1 False
2 False
3 True
regex引数にFalseを指定すると正規表現が無向になります。正規表現で使う記号などをそのまま検索したりする際にはFalseにするとシンプルなケースがあるかもしれません。
vaex_df = vaex.from_arrays(a=['シャム猫', 'マンチカン', 'スフィンクス', 'ペルシャ猫'])
vaex_df.a.str.contains(pattern='猫$', regex=False)
Expression = str_contains(a, pattern='猫$', regex=False)
Length: 4 dtype: bool (expression)
----------------------------------
0 False
1 False
2 False
3 False
特定の文字列と一致するかを調べる : equals, matchメソッド
equalsメソッドでは引数に指定した特定の文字列と各行の値が一致するかどうかの真偽値のベクトルを得ることができます。containsメソッドと異なり、部分的に一致しているだけでは駄目で、値が完全に一致している必要があります。
vaex_df.a.str.equals(y='マンチカン')
Expression = str_equals(a, y='マンチカン')
Length: 4 dtype: bool (expression)
----------------------------------
0 False
1 True
2 False
3 False
matchメソッドはequalsメソッドと似たような挙動をしますが、こちらは正規表現のパターンに対応しています。
vaex_df.a.str.match(pattern=r'.+猫')
Expression = str_match(a, pattern='.+猫')
Length: 4 dtype: bool (expression)
----------------------------------
0 True
1 False
2 False
3 True
指定の文字(列)がどの位置にあるのかを調べる : find, rfind, index, rindexメソッド
findメソッドは特定の文字(列)が各行でどの位置にあるのかのインデックスを検索します。ただしユニコードのマルチバイトで計算される?ようで日本語などだと1文字で3とカウントされたりと、少し使いづらいかもしれません。指定した文字(列)が含まれない行は-1になります。
vaex_df.a.str.find('ャ')
Expression = str_find(a, 'ャ')
Length: 4 dtype: int64 (expression)
-----------------------------------
0 3
1 -1
2 -1
3 9
Pythonビルトインのfind関数やPandasだとマルチバイトの文字でも1とカウントされるので、ビルトインなどと挙動が異なるので注意が必要です。
str_val = 'ペルシャ猫'
str_val.find('ャ')
3
pandas_df = pd.DataFrame(data={'a': ['シャム猫', 'マンチカン', 'スフィンクス', 'ペルシャ猫']})
pandas_df.a.str.find('ャ')
0 1
1 -1
2 -1
3 3
Name: a, dtype: int64
rfindメソッドは検索を文字列の末端(右側)から実行します。ただし返却されるインデックスは左からのカウントになります(位置は同じ文字列が複数あった場合、右の方の位置が優先されます)。
vaex_df.a.str.rfind('ン')
Expression = str_rfind(a, 'ン')
Length: 4 dtype: int64 (expression)
-----------------------------------
0 -1
1 12
2 9
3 -1
indexやrindexもfindと似た挙動をし、指定した文字(列)がどの位置に存在するかを検索します(rindexはrfindと同様に右の位置にある文字(列)が優先されます)。
違いとして、開始位置や終了位置といったような値をstartとend引数で指定することができます。ただし、この引数の値はマルチバイト換算ではなく文字数での指定が必要なようで、この点もずれが紛らわしく日本語だと少し使いづらいかもしれません(将来のバージョンでは直っていそうな気もしますが・・・)。
vaex_df.a.str.index(sub='ャ')
Expression = str_index(a, sub='ャ')
Length: 4 dtype: int64 (expression)
-----------------------------------
0 3
1 -1
2 -1
3 9
vaex_df.a.str.index(sub='ャ', start=2)
Expression = str_index(a, sub='ャ', start=2)
Length: 4 dtype: int64 (expression)
-----------------------------------
0 -1
1 -1
2 -1
3 3
指定の文字(列)が何文字含まれるかをカウントする : countメソッド
countメソッドでは指定した文字(列)が何文字各行の文字列に含まれているかを計算することができます。
vaex_df.a.str.count('ン')
Expression = str_count(a, 'ン')
Length: 4 dtype: int64 (expression)
-----------------------------------
0 0
1 2
2 1
3 0
特定の文字列で開始しているか / 終了しているかを調べる : startswith, endswithメソッド
文字列が特定の文字列でスタートしているかどうかの真偽値を取得する場合にはstartswithを使います。
vaex_df = vaex.from_arrays(
a=['シャム猫', 'マンチカン', 'スフィンクス', 'ペルシャ猫', '猫鍋'])
vaex_df.a.str.startswith('猫')
Expression = str_startswith(a, '猫')
Length: 5 dtype: bool (expression)
----------------------------------
0 False
1 False
2 False
3 False
4 True
逆に特定の文字列で終わっているかどうかを調べる場合にはendswithを使います。
vaex_df.a.str.endswith('猫')
Expression = str_endswith(a, '猫')
Length: 5 dtype: bool (expression)
----------------------------------
0 True
1 False
2 False
3 True
4 False
パターンにマッチした文字列部分を他の文字列で置き換える : replaceメソッド
パターンにマッチした文字列部分を他の文字列で置き換えたい場合にはreplaceメソッドを使います。pat引数に設定したいパターン、repl引数に置き換えで指定したい文字列を指定します。
vaex_df.a.str.replace(pat='猫', repl='犬')
Expression = str_replace(str_replace(a, pat='猫', repl='犬'), pat='猫', r...
Length: 5 dtype: str (expression)
---------------------------------
0 シャム犬
1 マンチカン
2 スフィンクス
3 ペルシャ犬
4 犬鍋
特定のインデックス位置の文字を取得する : getメソッド
getメソッドでは特定のインデックス位置の文字を1文字取得します。こちらはマルチバイトなどの影響なく、文字数のインデックスで扱うことができます。指定されたインデックスよりも短い文字列の場合はその行は空文字になります。
vaex_df = vaex.from_arrays(
a=['シャム猫', 'マンチカン', 'スフィンクス', 'ペルシャ猫', '猫鍋'])
vaex_df.a.str.get(i=4)
Expression = str_get(a, i=4)
Length: 5 dtype: str (expression)
---------------------------------
0
1 ン
2 ク
3 猫
4
文字列が指定の種類で構成されているかを調べる : isalnum, isalpha, isdigit, isspaceメソッド
isalnumメソッドは文字列に記号などが含まれておらず英数字になっているかどうかの判定を行います。
ただ、ビルトインのisalnumメソッドもそうなのですが、ひらがなや漢字なども判定がTrueになってしまうという紛らわしい性質をそのままVaexでも持っています。半角の英数字と記号のみを扱う場合には使えますが、日本語なども含むデータを扱う場合には注意が必要です(場合によっては正規表現などが別途必要になってきます)。
なお、数字といっても-や.といったマイナスやfloatのための記号もFalseになります。
vaex_df = vaex.from_arrays(a=['a100', '3.14', '-500', '猫'])
vaex_df.a.str.isalnum()
Expression = str_isalnum(a)
Length: 4 dtype: bool (expression)
----------------------------------
0 True
1 False
2 False
3 True
isalphaメソッドはアルファベットのみかどうかで判定します。が、こちらも日本語などはTrueになってしまいます。a100といったようなアルファベットと数字が混在しているケースはFalseになります。
vaex_df = vaex.from_arrays(a=['a100', 'apple', '3.14', '-500', '猫'])
vaex_df.a.str.isalpha()
Expression = str_isalpha(a)
Length: 5 dtype: bool (expression)
----------------------------------
0 False
1 True
2 False
3 False
4 True
isdigitメソッドは数値かどうかを判定します。こちらは日本語などもFalseになります。.や-などの記号はFalseになるので、3.14や-500といった数値の文字列を扱う際には注意が必要です。
vaex_df = vaex.from_arrays(a=['a100', 'apple', '3.14', '-500', '猫', '600', '0'])
vaex_df.a.str.isdigit()
Expression = str_isdigit(a)
Length: 7 dtype: bool (expression)
----------------------------------
0 False
1 False
2 False
3 False
4 False
5 True
6 True
isspaceメソッドは対象の文字が空白文字のみで構成されているかを判定します。メソッドの名前的にスペースのみかと思えますがタブ(\t)や改行(\n)なども対象です。また、全角スペースは対象外になるようなので日本語などを扱う場合は注意が必要です。一部にスペースなどが含まれていても、他の文字が含まれている場合はFalseになります。
vaex_df = vaex.from_arrays(a=[' ', ' ', '\t', '\n', ' 猫 ', '猫\n犬'])
vaex_df.a.str.isspace()
Expression = str_isspace(a)
Length: 6 dtype: bool (expression)
----------------------------------
0 True
1 False
2 True
3 True
4 False
5 False
各文字の文字数をカウントする : lenメソッド
lenメソッドでは各行の文字列の文字数をカウントします。
vaex_df = vaex.from_arrays(
a=['シャム猫', 'マンチカン', 'スフィンクス', 'ペルシャ猫'])
vaex_df.a.str.len()
Expression = str_len(a)
Length: 4 dtype: int64 (expression)
-----------------------------------
0 4
1 5
2 6
3 5
文字列の範囲をインデックス指定でスライスする : sliceメソッド
sliceメソッドはインデックス範囲による文字列のスライスを行います。startとstopの引数で指定します。日本語でも文字のインデックスは1文字ずつカウントされます。
他のPythonビルトインやPandas同様に、start~stop -1の範囲の文字となります。stopで指定したインデックスは含まれません。stop - 1の範囲となります(4を指定したら3のインデックスまでが対象)。
vaex_df = vaex.from_arrays(
a=['シャム猫', 'マンチカン', 'スフィンクス', 'ペルシャ猫'])
vaex_df.a.str.slice(start=2, stop=4)
Expression = str_slice(a, start=2, stop=4)
Length: 4 dtype: str (expression)
---------------------------------
0 ム猫
1 チカ
2 ィン
3 シャ
文字列を特定のフォーマットに変換する : capitalize, upper, lower, titleメソッド
この節の各メソッドは基本的にアルファベットが対象のインターフェイスとなります。
capitalizeメソッドは各行の文字列の先頭の1文字だけ大文字に変換します。複数単語含まれている場合でも先頭の単語の1文字のみ大文字になります。
vaex_df = vaex.from_arrays(a=['apple', 'orange', 'water melon'])
vaex_df.a.str.capitalize()
Expression = str_capitalize(a)
Length: 3 dtype: str (expression)
---------------------------------
0 Apple
1 Orange
2 Water melon
upperメソッドでは小文字のアルファベットが全て大文字になります。
小文字のアルファベット以外の記号などはそのまま残ります。
vaex_df = vaex.from_arrays(a=['apple', 'orange_price', 'Water melon'])
vaex_df.a.str.upper()
Expression = str_upper(a)
Length: 3 dtype: str (expression)
---------------------------------
0 APPLE
1 ORANGE_PRICE
2 WATER MELON
逆にlowerメソッドでは大文字部分が小文字に変換されます。
vaex_df = vaex.from_arrays(a=['Apple', 'ORANGE_PRICE', 'Water Melon'])
vaex_df.a.str.lower()
Expression = str_lower(a)
Length: 3 dtype: str (expression)
---------------------------------
0 apple
1 orange_price
2 water melon
titleメソッドはタイトルケースと呼ばれる、英文の見出しなどで良く使われる各単語の先頭を大文字にする変換を行います。ただし、タイトルケースはandなどの単語は大文字にしないケースが多くありますがVaexのtitleメソッドはその辺りは関係なく単語単位で先頭の1文字が大文字になる形になります(Pythonビルトインなどと同じ挙動)。
vaex_df = vaex.from_arrays(a=['apple', 'apple and orange', 'water melon'])
vaex_df.a.str.title()
Expression = str_title(a)
Length: 3 dtype: str (expression)
---------------------------------
0 Apple
1 Apple And Orange
2 Water Melon
文字列が特定のフォーマットかどうかを判定する : isupper, islowerメソッド
前節で触れたフォーマット変換に近い処理になりますが、こちらは変換ではなく各行の文字列が該当のフォーマットになっているかどうかの真偽値を返却します。
isupperメソッドは含まれているアルファベットが全て大文字になっているかどうかで判定します。記号などが含まれていても問題ありません。
vaex_df = vaex.from_arrays(a=['Apple', 'ORANGE', 'ORANGE_PRICE', 'Water Melon'])
vaex_df.a.str.isupper()
Expression = str_isupper(a)
Length: 4 dtype: bool (expression)
----------------------------------
0 False
1 True
2 True
3 False
islowerでは逆にアルファベットが全て小文字かどうかで判定がされます。
vaex_df = vaex.from_arrays(a=['Apple', 'ORANGE', 'orange_price', 'water melon'])
vaex_df.a.str.islower()
Expression = str_islower(a)
Length: 4 dtype: bool (expression)
----------------------------------
0 False
1 False
2 True
3 True
※istitleなどの別の判定のインターフェイスはこの記事で使っているバージョンでは無い?ようです。4.0.0aなどのαバージョンの新しいバージョンのドキュメントでは存在していたので、将来使えるようになると思われます。
文字詰め(埋め)を行う : ljust, rjust, center, pad, zfillメソッド
ljustメソッドは指定した文字数になるまで左寄せで右側に特定の文字を追加するメソッドです。
width引数に文字数、fillchar引数に埋めるのに利用する文字を指定します。
vaex_df = vaex.from_arrays(a=['7', '15', '137', '2374'])
vaex_df.a.str.ljust(width=4, fillchar='A')
Expression = str_ljust(a, width=4, fillchar='A')
Length: 4 dtype: str (expression)
---------------------------------
0 7AAA
1 15AA
2 137A
3 2374
rjustメソッドでは逆に右寄せで左側に特定の文字を追加します。
vaex_df = vaex.from_arrays(a=['7', '15', '137', '2374'])
vaex_df.a.str.rjust(width=4, fillchar='A')
Expression = str_rjust(a, width=4, fillchar='A')
Length: 4 dtype: str (expression)
---------------------------------
0 AAA7
1 AA15
2 A137
3 2374
centerメソッドでは元の文字を中央に配置した状態で左右に文字を埋めます。左右どちらかに埋める文字が多くなる場合には右側が多くなります。
vaex_df = vaex.from_arrays(a=['7', '15', '137', '2374'])
vaex_df.a.str.center(width=4, fillchar='A')
Expression = str_center(a, width=4, fillchar='A')
Length: 4 dtype: str (expression)
---------------------------------
0 A7AA
1 A15A
2 137A
3 2374
padメソッドも前述までの文字埋めのメソッドと同じような挙動をじますが、引数で左側を埋めるのか右側を埋めるのかといった指定ができます。基本的にはljustかrjustを使えば済むので無くても大丈夫だけどあるとたまに便利程度の関数でしょうか。side引数でleftやrightと指定して文字を埋める方向を設定します。
vaex_df = vaex.from_arrays(a=['7', '15', '137', '2374'])
vaex_df.a.str.pad(width=5, side='left', fillchar='A')
Expression = str_pad(a, width=5, side='left', fillchar='A')
Length: 4 dtype: str (expression)
---------------------------------
0 AAAA7
1 AAA15
2 AA137
3 A2374
zfillメソッドは0埋めを行います。rjustメソッドでfillcharに0を指定する形でも実現できますが、こちらの方が記述がシンプルになります。
vaex_df = vaex.from_arrays(a=['7', '15', '137', '2374'])
vaex_df.a.str.zfill(width=4)
Expression = str_zfill(a, width=4)
Length: 4 dtype: str (expression)
---------------------------------
0 0007
1 0015
2 0137
3 2374
文字列の左右の空白文字を取り除く : strip, lstrip, rstripメソッド
※そのままのVaexの出力だと違いが分かりづらかったので、この節では各インターフェイスを利用した際に返却されるExpressionクラスのインスタンスと処理の評価を行って結果のNumPy配列を取得するevaluateメソッドを利用していきます。
stripメソッドは各行の文字列の左右から、スペースやタブ、改行などの空白文字を取り除きます。
vaex_df = vaex.from_arrays(a=[' 猫', '\t犬', '\n兎\n'])
expression = vaex_df.a.str.strip()
expression.evaluate()
array(['猫', '犬', '兎'], dtype=object)
to_strip引数に取り除きたい文字を指定(文字列ではなく1文字ずつの判定)した場合には空白文字以外も指定することができます。
expression = vaex_df.a.str.strip(to_strip='猫 \n')
expression.evaluate()
array(['', '\t犬', '兎'], dtype=object)
lstripとrstripは左側だけ、もしくは右側だけ空白文字などを取り除きます。
expression = vaex_df.a.str.lstrip()
expression.evaluate()
array(['猫', '犬', '兎\n'], dtype=object)
expression = vaex_df.a.str.rstrip()
expression.evaluate()
array([' 猫', '\t犬', '\n兎'], dtype=object)
to_stripの引数はstripメソッドと同様です。
文字列を指定回数繰り返す : repeatメソッド
各行の文字列を指定した回数繰り返した文字列を取得するにはrepeatメソッドを使います。
vaex_df = vaex.from_arrays(a=['猫', '犬', 'ライオン'])
vaex_df.a.str.repeat(repeats=3)
Expression = str_repeat(a, repeats=3)
Length: 3 dtype: str (expression)
---------------------------------
0 猫猫猫
1 犬犬犬
2 ライオンライオンライオン
複数のインターフェイスの処理が必要な場合のExpressionの制御
ここまでで色々なインターフェイスの制御を見てきました。Vaexではスライスなどは普通にPandasなどと同様に処理を繋げていけばスライス結果が複数反映されていきます。しかし各メソッドなどの処理はPandasやDask感覚で繋げていっても動作してくれません。
例えば以下のようにカラムの値をPandasやDaskの感覚で更新しようとしても更新されません(置換後の犬という文字ではなく元の猫という文字がデータフレームの値に設定されたままで、エラーなども発生しません)。
vaex_df = vaex.from_arrays(
a=['シャム猫', 'マンチカン', 'スフィンクス', 'ペルシャ猫', '猫鍋'])
vaex_df.a = vaex_df.a.str.replace(pat='猫', repl='犬')
print(vaex_df)
# a
0 シャム猫
1 マンチカン
2 スフィンクス
3 ペルシャ猫
4 猫鍋
同様にカラムに対する数値計算なども反映されません。
vaex_df = vaex.from_arrays(a=[100, 200, 300])
vaex_df.a += 10
print(vaex_df)
# a
0 100
1 200
2 300
では必要な処理が複数ある場合どのように繋いでいくべきかという話ですが、対応方法の一つとしてExpressionとevaluateメソッドなどを使うと複数の処理を繋げることができます。
各インターフェイスや数値計算などは、VaexのExpressionクラスのインスタンスが返却されます。
vaex_df = vaex.from_arrays(
a=['シャム猫', 'マンチカン', 'スフィンクス', 'ペルシャ猫', '猫鍋'])
expression = vaex_df.a.str.replace(pat='猫', repl='犬')
print(type(expression))
<class 'vaex.expression.Expression'>
このExpressionインスタンスはVaexの特定カラムと同じインターフェイスを持ちます。つまりこのExpressionのインスタンスでさらに特定のインターフェイスを呼び出して、別のExpressionインスタンスを得るといった繋げ方ができます。
expression = expression.str.replace(pat='犬', repl='兎')
最後にExpressionのインスタンス自体のevaluateメソッドか、もしくはデータフレームのevaluateメソッドの第一引数がexpressionとなっているので対象のExpressionインスタンスを指定してあげれば複数の処理を反映した結果を得ることができます。
expression.evaluate()
array(['シャム兎', 'マンチカン', 'スフィンクス', 'ペルシャ兎', '兎鍋'], dtype=object)
vaex_df.evaluate(expression=expression)
array(['シャム兎', 'マンチカン', 'スフィンクス', 'ペルシャ兎', '兎鍋'], dtype=object)
数値計算も同様にExpressionを使っていくことで対応ができます。
vaex_df = vaex.from_arrays(a=[100, 200, 300])
expression = vaex_df.a + 10
expression = expression + 50
expression.evaluate()
array([160, 260, 360])
Vaexでのカラム操作
以降の節では以下のカラム操作について触れていきます。
- カラムの追加
- カラムの削除
- カラムのリネーム
カラムの追加
カラムの追加はdf['<カラム名>']といった形で右辺に値を指定すれば対応ができます。
vaex_df = vaex.from_arrays(a=[1, 2], b=[3, 4])
vaex_df['c'] = np.array([5, 6])
print(vaex_df)
# a b c
0 1 3 5
1 2 4 6
NumPy配列は指定できますが、Pandasのようにスカラー値やリストは指定できません。
vaex_df = vaex.from_arrays(a=[1, 2], b=[3, 4])
vaex_df['c'] = 5
ValueError: 5 is not of string or Expression type, but <class 'int'>
vaex_df['c'] = [5, 6]
ValueError: [5, 6] is not of string or Expression type, but <class 'list'>
データフレームのカラム同士の演算結果を新たなカラムとして設定することもできます。
vaex_df = vaex.from_arrays(a=[1, 2], b=[3, 4])
vaex_df['c'] = vaex_df.a + vaex_df.b
print(vaex_df)
# a b c
0 1 3 4
1 2 4 6
なお、これらのカラム同士の演算などで生成したカラムはVaexで仮想カラム(virtual column)と呼ばれ、他の処理などと同様に計算で必要になるまで大半はメモリに持たない形となっているようです。
We call this a virtual column since it does not take up any memory, and is computed on the fly when needed. A virtual column is treated just as a normal column.
Vaex introduction in 11 minutes
カラムの削除
VaexだとPandasの感覚でdelキーワードなどを使ってもカラムが削除されないので注意が必要です(エラーにもならず、カラムが残ったままとなります)。
vaex_df = vaex.from_arrays(a=[1, 2], b=[3, 4], c=[5, 6])
del vaex_df.c
print(vaex_df)
# a b c
0 1 3 5
1 2 4 6
カラムを切り落としたい場合には明示的にdropメソッドを使う必要があります。
vaex_df = vaex.from_arrays(a=[1, 2], b=[3, 4], c=[5, 6])
vaex_df = vaex_df.drop(columns=['c'], inplace=True)
print(vaex_df)
# a b
0 1 3
1 2 4
columns引数のリストに複数の値を指定することで複数のカラムを同時に切り落としできます。
vaex_df = vaex.from_arrays(a=[1, 2], b=[3, 4], c=[5, 6])
vaex_df = vaex_df.drop(columns=['a', 'c'], inplace=True)
print(vaex_df)
# b
0 3
1 4
カラムのリネーム
カラムのリネームをするにはrename_columnメソッドを使います。
vaex_df = vaex.from_arrays(name=['ミケ', 'タマ'])
vaex_df.rename_column(name='name', new_name='after_name')
print(vaex_df)
# after_name
0 ミケ
1 タマ
ちなみにですが、Pandasと違って日本語のカラムを指定してみたらうまく動きませんでした(該当のカラムが表示されない結果に)。
vaex_df = vaex.from_arrays(name=['ミケ', 'タマ'])
vaex_df.rename_column(name='name', new_name='名前')
print(vaex_df)
#
0
1
欠損値制御
以降の節ではVaexでの欠損値制御についての以下のインターフェイスについて触れていきます。
- isna, isnan : 各行が欠損値かどうかの判定をします。
- fillna, fillnan : 各行の欠損値を任意の値で補正します。
- dropna, dropnan : 欠損値の行を切り落とします。
インターフェイス名を見て分かる通り、Pandasだとisnaとisnullといったインターフェイスがありましたが、Vaexでは少し変わっています。
各行が欠損値かどうかの判定する : isna, isnanメソッド
isnaメソッドは各行が欠損値かどうかの真偽値を返却値します。Noneでもnp.nanでもそれぞれ欠損値として扱われます。
vaex_df = vaex.from_arrays(a=[None, np.nan, 100])
vaex_df.a.isna()
Expression = isna(a)
Length: 3 dtype: bool (expression)
----------------------------------
0 True
1 True
2 False
似ているインターフェイス名ですが、isnanメソッドの方はNoneは対象外となりnp.nanの場合にのみTrueとなります。
vaex_df.a.isnan()
Expression = isnan(a)
Length: 3 dtype: bool (expression)
----------------------------------
0 False
1 True
2 False
各行の欠損値を任意の値で補正する : fillna, fillnanメソッド
fillnaとfillnanメソッドはそれぞれ欠損値補正のメソッドです。isnaとisnanの違いと同様に、こちらもNoneが補正対象になるかならないかの違いで別のメソッドになっています。isnanの方ではNoneは補正されません。
vaex_df.a.fillna(value=-1)
Expression = fillna(a, value=-1)
Length: 3 dtype: object (expression)
------------------------------------
0 -1
1 -1
2 100
vaex_df.a.fillnan(value=-1)
Expression = fillnan(a, value=-1)
Length: 3 dtype: object (expression)
------------------------------------
0 None
1 -1
2 100
欠損値の行を切り落とす : dropna, dropnanメソッド
続いて欠損値の切り落とし関係です。dropnaとdropnanの2つのメソッドがあり、こちらも違いは切り落としでNoneを対象とするかどうかとなります。
vaex_df.a.dropna()
Expression = a
Length: 1 dtype: object (column)
--------------------------------
0 100
vaex_df.a.dropnan()
Expression = a
Length: 2 dtype: object (column)
--------------------------------
0 None
1 100
独自の計算を行う : register_function関数とapplyメソッド
ここまでで様々なVaexの操作のインターフェイスを見てきましたが、これらのインターフェイスだけでは対応できないケースがもちろん出てきます。Pandasでいうところのapplyみたいな関数を反映するような処理が欲しくなってきます。
その場合にはregister_function関数をデコレーターに設定することでその関数をVaexのデータフレームのインターフェイスに追加することができ、他と同じExpressionのインスタンスを得ることができます。
@vaex.register_function()
def add_one(arr):
return arr + 1
vaex_df = vaex.from_arrays(a=[100, 200, 300])
vaex_df.a.add_one()
Expression = add_one(a)
Length: 3 dtype: int64 (expression)
-----------------------------------
0 101
1 201
2 301
デコレーターを設定する関数の引数はNumPyの配列(ndarray)です。
複数のカラムの値を渡したり、固定値を渡したりすることもできます。df.<カラム名>.<追加した関数>という呼び出し方の場合、対象の関数の第一引数へは該当のカラムが設定されます。それ以降の引数については任意のカラムや値が指定できます。Pandasのapply的な挙動ですね(渡されるのは個別のスカラー値ではなく配列まるごとといった感じではありますが・・・)。
@vaex.register_function()
def sum_a_and_b_andx(a_arr, b_arr, x):
return a_arr + b_arr + x
vaex_df = vaex.from_arrays(a=[100, 200, 300], b=[50, 60, 70])
vaex_df.a.sum_a_and_b_andx(b_arr=vaex_df.b, x=500)
Expression = sum_a_and_b_andx(a, b_arr=b, x=500)
Length: 3 dtype: int64 (expression)
-----------------------------------
0 650
1 760
2 870
カラム名を指定しない形で、df.func.<追加した関数>という書き方もできます。この場合関数の第一引数も指定する必要があります。
vaex_df.func.sum_a_and_b_andx(a_arr=vaex_df.a, b_arr=vaex_df.b, x=500)
Expression = sum_a_and_b_andx(a_arr=a, b_arr=b, x=500)
Length: 3 dtype: int64 (expression)
-----------------------------------
0 650
1 760
2 870
また、スカラー値ごとに処理を行うapplyメソッドも一応あります。ただしDaskなどと同様に、VaexはOut-of-Coreで並列で処理されたりする都合、並列処理での値の転送などが必要になってかなり遅くなりうる・・・とのことです(Pandasの感覚で頻繁に使うべきではないインターフェイス)。
ドキュメントにも「最後の手段」(last resort)と書かれています。
In case a calculation cannot be expressed as a Vaex expression, one can use the apply method as a last resort.
Vaex introduction in 11 minutes
def get_animal_name(scalar_val):
if scalar_val == 1:
return '猫'
if scalar_val == 2:
return '犬'
return '兎'
vaex_df = vaex.from_arrays(a=[1, 2, 3])
vaex_df.a.apply(f=get_animal_name)
Expression = lambda_function(a)
Length: 3 dtype: str (expression)
---------------------------------
0 猫
1 犬
2 兎
Vaexを触ってみての所感
Pandasなどの方がやはり古くからあってコミュニティの人数も多いので、細かい点まで洗練されていたりバグが少なかったり、サポートされているインターフェイスが多かったりというのは確かに感じました(Vaexはちらほらエラーで引っかかったり、うまく動かない条件があったり、些細な表示での問題などが見受けられたり等)。
しかし大半はPandasの感覚で使えますし、基本的な機能は大体カバーされていますので、膨大なデータセットでの処理が必要な場合には十分利用を検討して良さそうな印象です。
どれも素晴らしいライブラリなので、ライトなものであればPandas、メモリに乗りきらないデータで速度も必要な場合にはVaex、時間は少しかかってもOKでメモリに乗りきらないデータで多くのインターフェイス(Vaexで足りないものなど)を利用したければDask・・・といった具合に色々使い分けができそうです。お仕事でも役立てていきたい。
参考文献・サイトまとめ
- Vaex documentation(公式ドキュメント)
- Vaex introduction in 11 minutes
- API documentation for vaex library
- I/O Kung-Fu: get your data in and out of Vaex
- Pythonの順序付き辞書OrderedDictの使い方
- Add support for compressed HDF5 files. #101
- 【Python】文字列が英数字かどうかを判定する(正規表現)
- 【Python】isalnum 英数字のみか?入力値チェック
- Pandasで行うデータ処理を100倍高速にするOut-of-CoreフレームワークVaex