きっかけ
前の記事 からの続きで、機械学習系の体験をしていきたい。機械学習の一つとして自然言語処理がある。既に色々英知の結晶が提供されている様なので、体験したい。
試してみるサービス等
- GiNZA
- COTOHA API
- AWSの自然言語系サービス
試してみる文章&機能
文章:
前の記事 で書いた**「個人趣味で開発してた自分用家計簿サービスが一段落し、次にやる事を考えてみた。やっぱり、今流行りの機械学習で何かしてみたい。とはいえ、基本知識すらない。」**
機能:
一番基本的な機能、構文解析(形態素解析)
GiNZAを使ってみた。
インストール
# pythonで何かする時は、venv使う派なので。
sudo apt-get install python3-venv
python3 -m venv ginza
source ginza/bin/activate
cd ~/ginza
# GiNZA の中でsudachipyというライブラリが使用されているのでそのインストール
# 本来ならGiNZA本体インストール時にインストールされると思うが、なぜかそこに失敗した為。
# https://github.com/WorksApplications/SudachiPy
pip install SudachiPy
pip install https://object-storage.tyo2.conoha.io/v1/nc_2520839e1f9641b08211a5c85243124a/sudachi/SudachiDict_core-20200127.tar.gz
# GiNZA 本体インストール
# 後から知ったが、pip install ginza で大丈夫だったらしい。
pip install "https://github.com/megagonlabs/ginza/releases/download/latest/ginza-latest.tar.gz"
構文解析(形態素解析)
前述文章をsample.txtに保存して以下実行。
(ginza) ubuntu@ubuntu:~/ginza$ ginza sample.txt
実行結果
mode is C
disabling sentence separator
# text = 個人趣味で開発してた自分用家計簿サービスが一段落し、次にやる事を考えてみた。やっぱり、今流行りの機械学習で何かしてみたい。とはいえ、基本知識すらない。
1 個人 個人 NOUN 名詞-普通名詞-一般 _ 2 compound _ BunsetuBILabel=B|BunsetuPositionType=CONT|SpaceAfter=No|NP_B
2 趣味 趣味 NOUN 名詞-普通名詞-一般 _ 4 nmod _ BunsetuBILabel=I|BunsetuPositionType=SEM_HEAD|SpaceAfter=No|NP_I
3 で で ADP 助詞-格助詞 _ 2 case _ BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|SpaceAfter=No
4 開発 開発 VERB 名詞-普通名詞-サ変可能 _ 11 acl _ BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|SpaceAfter=No
5 し 為る AUX 動詞-非自立可能 _ 4 aux _ BunsetuBILabel=I|BunsetuPositionType=FUNC|SpaceAfter=No
6 て てる AUX 助動詞 _ 4 aux _ BunsetuBILabel=I|BunsetuPositionType=FUNC|SpaceAfter=No
7 た た AUX 助動詞 _ 4 aux _ BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|SpaceAfter=No
8 自分 自分 NOUN 名詞-普通名詞-一般 _ 11 compound _ BunsetuBILabel=B|BunsetuPositionType=CONT|SpaceAfter=No|NP_B
9 用 用 NOUN 接尾辞-名詞的-一般 _ 11 compound _ BunsetuBILabel=I|BunsetuPositionType=CONT|SpaceAfter=No|NP_I
10 家計簿 家計簿 NOUN 名詞-普通名詞-一般 _ 11 compound _ BunsetuBILabel=I|BunsetuPositionType=CONT|SpaceAfter=No|NP_I
11 サービス サービス NOUN 名詞-普通名詞-サ変可能 _ 14 nsubj _ BunsetuBILabel=I|BunsetuPositionType=SEM_HEAD|SpaceAfter=No|NP_I
12 が が ADP 助詞-格助詞 _ 11 case _ BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|SpaceAfter=No
13 一段落 一段落 NUM 名詞-普通名詞-一般 NumType=Card 14 nummod _ BunsetuBILabel=B|BunsetuPositionType=CONT|SpaceAfter=No
14 し 為る AUX 動詞-非自立可能 _ 21 advcl _ BunsetuBILabel=I|BunsetuPositionType=SEM_HEAD|SpaceAfter=No
15 、 、 PUNCT 補助記号-読点 _ 14 punct _ BunsetuBILabel=I|BunsetuPositionType=CONT|SpaceAfter=No
16 次 次 NOUN 名詞-普通名詞-一般 _ 18 obl _ BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|SpaceAfter=No|NP_B
17 に に ADP 助詞-格助詞 _ 16 case _ BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|SpaceAfter=No
18 やる 遣る VERB 動詞-非自立可能 _ 19 acl _ BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|SpaceAfter=No
19 事 事 NOUN 名詞-普通名詞-一般 _ 21 obj _ BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|SpaceAfter=No|NP_B
20 を を ADP 助詞-格助詞 _ 19 case _ BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|SpaceAfter=No
21 考え 考える VERB 動詞-一般 _ 35 advcl _ BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|SpaceAfter=No
22 て て SCONJ 助詞-接続助詞 _ 21 mark _ BunsetuBILabel=I|BunsetuPositionType=FUNC|SpaceAfter=No
23 み 見る AUX 動詞-非自立可能 _ 21 aux _ BunsetuBILabel=I|BunsetuPositionType=FUNC|SpaceAfter=No
24 た た AUX 助動詞 _ 21 aux _ BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|SpaceAfter=No
25 。 。 PUNCT 補助記号-句点 _ 21 punct _ BunsetuBILabel=I|BunsetuPositionType=CONT|SpaceAfter=No
26 やっぱり 矢張り ADV 副詞 _ 35 advmod _ BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|SpaceAfter=No
27 、 、 PUNCT 補助記号-読点 _ 26 punct _ BunsetuBILabel=I|BunsetuPositionType=CONT|SpaceAfter=No
28 今 今 ADV 名詞-普通名詞-副詞可能 _ 35 advmod _ BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|SpaceAfter=No
29 流行り 流行 NOUN 名詞-普通名詞-一般 _ 31 nmod _ BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|SpaceAfter=No|NP_B
30 の の ADP 助詞-格助詞 _ 29 case _ BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|SpaceAfter=No
31 機械学習 機械学習 NOUN 名詞-普通名詞-一般 _ 35 nmod _ BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|SpaceAfter=No|NP_B
32 で で ADP 助詞-格助詞 _ 31 case _ BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|SpaceAfter=No
33 何 何 PRON 代名詞 _ 35 iobj _ BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|SpaceAfter=No|NP_B
34 か か ADP 助詞-副助詞 _ 33 case _ BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|SpaceAfter=No
35 し 為る AUX 動詞-非自立可能 _ 47 advcl _ BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|SpaceAfter=No
36 て て SCONJ 助詞-接続助詞 _ 35 mark _ BunsetuBILabel=I|BunsetuPositionType=FUNC|SpaceAfter=No
37 み 見る AUX 動詞-非自立可能 _ 35 aux _ BunsetuBILabel=I|BunsetuPositionType=FUNC|SpaceAfter=No
38 たい たい AUX 助動詞 _ 35 aux _ BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|SpaceAfter=No
39 。 。 PUNCT 補助記号-句点 _ 35 punct _ BunsetuBILabel=I|BunsetuPositionType=CONT|SpaceAfter=No
40 と と ADP 助詞-格助詞 _ 35 case _ BunsetuBILabel=I|BunsetuPositionType=FUNC|SpaceAfter=No
41 は は ADP 助詞-係助詞 _ 35 case _ BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|SpaceAfter=No
42 いえ 言う VERB 動詞-一般 _ 35 aux _ BunsetuBILabel=I|BunsetuPositionType=CONT|SpaceAfter=No
43 、 、 PUNCT 補助記号-読点 _ 35 punct _ BunsetuBILabel=I|BunsetuPositionType=CONT|SpaceAfter=No
44 基本 基本 NOUN 名詞-普通名詞-一般 _ 45 compound _ BunsetuBILabel=B|BunsetuPositionType=CONT|SpaceAfter=No|NP_B
45 知識 知識 NOUN 名詞-普通名詞-一般 _ 47 iobj _ BunsetuBILabel=I|BunsetuPositionType=SEM_HEAD|SpaceAfter=No|NP_I
46 すら すら ADP 助詞-副助詞 _ 45 case _ BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|SpaceAfter=No
47 ない 無い ADJ 形容詞-非自立可能 _ 0 root _ BunsetuBILabel=B|BunsetuPositionType=ROOT|SpaceAfter=No
48 。 。 PUNCT 補助記号-句点 _ 47 punct _ BunsetuBILabel=I|BunsetuPositionType=CONT|SpaceAfter=No
CoNLL-U Format という標準フォーマットで出力される。
Pythonでもやってみる。
公式ページ のサンプルをちょっと改造。
import spacy
nlp = spacy.load('ja_ginza')
# 解析対象文
test_data = open("sample.txt", "r")
try:
test_lines = test_data.readlines()
for line in test_lines:
doc = nlp(line)
for sent in doc.sents:
for token in sent:
print(token.i, token.orth_, token.lemma_, token.pos_, token.tag_, token.dep_, token.head.i)
print('EOS')
finally:
test_data.close()
実行結果
(ginza) ubuntu@ubuntu:~/ginza$ python3 test02.py
0 個人 個人 NOUN 名詞-普通名詞-一般 compound 1
1 趣味 趣味 NOUN 名詞-普通名詞-一般 nmod 3
2 で で ADP 助詞-格助詞 case 1
3 開発 開発 VERB 名詞-普通名詞-サ変可能 acl 10
4 し 為る AUX 動詞-非自立可能 aux 3
5 て てる AUX 助動詞 aux 3
6 た た AUX 助動詞 aux 3
7 自分 自分 NOUN 名詞-普通名詞-一般 compound 10
8 用 用 NOUN 接尾辞-名詞的-一般 compound 10
9 家計簿 家計簿 NOUN 名詞-普通名詞-一般 compound 10
10 サービス サービス NOUN 名詞-普通名詞-サ変可能 nsubj 13
11 が が ADP 助詞-格助詞 case 10
12 一段落 一段落 NUM 名詞-普通名詞-一般 nummod 13
13 し 為る AUX 動詞-非自立可能 advcl 20
14 、 、 PUNCT 補助記号-読点 punct 13
15 次 次 NOUN 名詞-普通名詞-一般 obl 17
16 に に ADP 助詞-格助詞 case 15
17 やる 遣る VERB 動詞-非自立可能 acl 18
18 事 事 NOUN 名詞-普通名詞-一般 obj 20
19 を を ADP 助詞-格助詞 case 18
20 考え 考える VERB 動詞-一般 ROOT 20
21 て て SCONJ 助詞-接続助詞 mark 20
22 み 見る AUX 動詞-非自立可能 aux 20
23 た た AUX 助動詞 aux 20
24 。 。 PUNCT 補助記号-句点 punct 20
EOS
25 やっぱり 矢張り ADV 副詞 advmod 34
26 、 、 PUNCT 補助記号-読点 punct 25
27 今 今 ADV 名詞-普通名詞-副詞可能 advmod 34
28 流行り 流行 NOUN 名詞-普通名詞-一般 nmod 30
29 の の ADP 助詞-格助詞 case 28
30 機械学習 機械学習 NOUN 名詞-普通名詞-一般 nmod 34
31 で で ADP 助詞-格助詞 case 30
32 何 何 PRON 代名詞 iobj 34
33 か か ADP 助詞-副助詞 case 32
34 し 為る AUX 動詞-非自立可能 ROOT 34
35 て て SCONJ 助詞-接続助詞 mark 34
36 み 見る AUX 動詞-非自立可能 aux 34
37 たい たい AUX 助動詞 aux 34
38 。 。 PUNCT 補助記号-句点 punct 34
EOS
39 と と ADP 助詞-格助詞 advmod 46
40 は は ADP 助詞-係助詞 dep 44
41 いえ 言う VERB 動詞-一般 dep 44
42 、 、 PUNCT 補助記号-読点 punct 44
43 基本 基本 NOUN 名詞-普通名詞-一般 compound 44
44 知識 知識 NOUN 名詞-普通名詞-一般 iobj 46
45 すら すら ADP 助詞-副助詞 case 44
46 ない 無い ADJ 形容詞-非自立可能 ROOT 46
47 。 。 PUNCT 補助記号-句点 punct 46
EOS
COTOHA使ってみた
自然言語処理を簡単に扱えると噂のCOTOHA APIをPythonで使ってみた をそのままトレースさせてもらいました。
実行結果
{
"result": [
{
"chunk_info": {
"id": 0,
"head": 1,
"dep": "D",
"chunk_head": 1,
"chunk_func": 2,
"links": []
},
"tokens": [
{
"id": 0,
"form": "個人",
"kana": "コジン",
"lemma": "個人",
"pos": "名詞",
"features": [],
"attributes": {}
},
{
"id": 1,
"form": "趣味",
"kana": "シュミ",
"lemma": "趣味",
"pos": "名詞",
"features": [],
"dependency_labels": [
{
"token_id": 0,
"label": "compound"
},
{
"token_id": 2,
"label": "case"
}
],
"attributes": {}
},
{
"id": 2,
"form": "で",
"kana": "デ",
"lemma": "で",
"pos": "格助詞",
"features": [
"連用"
],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 1,
"head": 2,
"dep": "D",
"chunk_head": 0,
"chunk_func": 3,
"links": [
{
"link": 0,
"label": "place"
}
],
"predicate": [
"past",
"past"
]
},
"tokens": [
{
"id": 3,
"form": "開発",
"kana": "カイハツ",
"lemma": "開発",
"pos": "名詞",
"features": [
"動作"
],
"dependency_labels": [
{
"token_id": 1,
"label": "nmod"
},
{
"token_id": 4,
"label": "aux"
},
{
"token_id": 5,
"label": "aux"
},
{
"token_id": 6,
"label": "aux"
}
],
"attributes": {}
},
{
"id": 4,
"form": "し",
"kana": "シ",
"lemma": "し",
"pos": "動詞活用語尾",
"features": [],
"attributes": {}
},
{
"id": 5,
"form": "て",
"kana": "テ",
"lemma": "て",
"pos": "動詞接尾辞",
"features": [
"接続",
"連用"
],
"attributes": {}
},
{
"id": 6,
"form": "た",
"kana": "タ",
"lemma": "た",
"pos": "動詞接尾辞",
"features": [
"連体"
],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 2,
"head": 3,
"dep": "D",
"chunk_head": 3,
"chunk_func": 4,
"links": [
{
"link": 1,
"label": "adjectivals"
}
]
},
"tokens": [
{
"id": 7,
"form": "自分",
"kana": "ジブン",
"lemma": "自分",
"pos": "名詞",
"features": [
"代名詞"
],
"attributes": {}
},
{
"id": 8,
"form": "用",
"kana": "ヨウ",
"lemma": "用",
"pos": "名詞接尾辞",
"features": [
"名詞"
],
"attributes": {}
},
{
"id": 9,
"form": "家計簿",
"kana": "カケイボ",
"lemma": "家計簿",
"pos": "名詞",
"features": [],
"attributes": {}
},
{
"id": 10,
"form": "サービス",
"kana": "サービス",
"lemma": "サービス",
"pos": "名詞",
"features": [
"動作"
],
"dependency_labels": [
{
"token_id": 3,
"label": "acl"
},
{
"token_id": 9,
"label": "compound"
},
{
"token_id": 8,
"label": "compound"
},
{
"token_id": 7,
"label": "compound"
},
{
"token_id": 11,
"label": "case"
}
],
"attributes": {}
},
{
"id": 11,
"form": "が",
"kana": "ガ",
"lemma": "が",
"pos": "格助詞",
"features": [
"連用"
],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 3,
"head": 7,
"dep": "P",
"chunk_head": 0,
"chunk_func": 1,
"links": [
{
"link": 2,
"label": "object"
}
],
"predicate": []
},
"tokens": [
{
"id": 12,
"form": "一段落",
"kana": "イチダンラク",
"lemma": "一段落",
"pos": "名詞",
"features": [
"動作"
],
"dependency_labels": [
{
"token_id": 10,
"label": "dobj"
},
{
"token_id": 13,
"label": "aux"
},
{
"token_id": 14,
"label": "punct"
}
],
"attributes": {}
},
{
"id": 13,
"form": "し",
"kana": "シ",
"lemma": "し",
"pos": "動詞接尾辞",
"features": [
"連用"
],
"attributes": {}
},
{
"id": 14,
"form": "、",
"kana": "",
"lemma": "、",
"pos": "読点",
"features": [],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 4,
"head": 5,
"dep": "D",
"chunk_head": 0,
"chunk_func": 0,
"links": []
},
"tokens": [
{
"id": 15,
"form": "次に",
"kana": "ツギニ",
"lemma": "次に",
"pos": "連用詞",
"features": [],
"dependency_labels": [],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 5,
"head": 6,
"dep": "D",
"chunk_head": 0,
"chunk_func": 1,
"links": [
{
"link": 4,
"label": "manner"
}
]
},
"tokens": [
{
"id": 16,
"form": "や",
"kana": "ヤ",
"lemma": "やる",
"pos": "動詞語幹",
"features": [
"R"
],
"dependency_labels": [
{
"token_id": 15,
"label": "advmod"
},
{
"token_id": 17,
"label": "aux"
}
],
"attributes": {}
},
{
"id": 17,
"form": "る",
"kana": "ル",
"lemma": "る",
"pos": "動詞接尾辞",
"features": [
"連体"
],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 6,
"head": 7,
"dep": "D",
"chunk_head": 0,
"chunk_func": 1,
"links": [
{
"link": 5,
"label": "adjectivals"
}
]
},
"tokens": [
{
"id": 18,
"form": "事",
"kana": "コト",
"lemma": "事",
"pos": "名詞",
"features": [],
"dependency_labels": [
{
"token_id": 16,
"label": "amod"
},
{
"token_id": 19,
"label": "case"
}
],
"attributes": {}
},
{
"id": 19,
"form": "を",
"kana": "ヲ",
"lemma": "を",
"pos": "格助詞",
"features": [
"連用"
],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 7,
"head": 16,
"dep": "P",
"chunk_head": 0,
"chunk_func": 3,
"links": [
{
"link": 3,
"label": "manner"
},
{
"link": 6,
"label": "object"
}
],
"predicate": [
"past",
"past"
]
},
"tokens": [
{
"id": 20,
"form": "考え",
"kana": "カンガエ",
"lemma": "考える",
"pos": "動詞語幹",
"features": [
"A"
],
"dependency_labels": [
{
"token_id": 12,
"label": "advcl"
},
{
"token_id": 18,
"label": "dobj"
},
{
"token_id": 21,
"label": "aux"
},
{
"token_id": 22,
"label": "aux"
},
{
"token_id": 23,
"label": "aux"
},
{
"token_id": 24,
"label": "punct"
}
],
"attributes": {}
},
{
"id": 21,
"form": "て",
"kana": "テ",
"lemma": "て",
"pos": "動詞接尾辞",
"features": [
"接続",
"連用"
],
"attributes": {}
},
{
"id": 22,
"form": "み",
"kana": "ミ",
"lemma": "みる",
"pos": "動詞語幹",
"features": [
"A",
"Lて連用"
],
"attributes": {}
},
{
"id": 23,
"form": "た",
"kana": "タ",
"lemma": "た",
"pos": "動詞接尾辞",
"features": [
"終止"
],
"attributes": {}
},
{
"id": 24,
"form": "。",
"kana": "",
"lemma": "。",
"pos": "句点",
"features": [],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 8,
"head": 16,
"dep": "D",
"chunk_head": 0,
"chunk_func": 0,
"links": []
},
"tokens": [
{
"id": 25,
"form": "やっぱり",
"kana": "ヤッパリ",
"lemma": "やっぱり",
"pos": "連用詞",
"features": [],
"dependency_labels": [
{
"token_id": 26,
"label": "punct"
}
],
"attributes": {}
},
{
"id": 26,
"form": "、",
"kana": "",
"lemma": "、",
"pos": "読点",
"features": [],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 9,
"head": 10,
"dep": "D",
"chunk_head": 0,
"chunk_func": 0,
"links": []
},
"tokens": [
{
"id": 27,
"form": "今",
"kana": "イマ",
"lemma": "今",
"pos": "名詞",
"features": [
"日時",
"連用"
],
"dependency_labels": [],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 10,
"head": 11,
"dep": "D",
"chunk_head": 0,
"chunk_func": 1,
"links": [
{
"link": 9,
"label": "time"
}
]
},
"tokens": [
{
"id": 28,
"form": "流行り",
"kana": "ハヤリ",
"lemma": "はやり",
"pos": "名詞",
"features": [],
"dependency_labels": [
{
"token_id": 27,
"label": "nmod"
},
{
"token_id": 29,
"label": "case"
}
],
"attributes": {}
},
{
"id": 29,
"form": "の",
"kana": "ノ",
"lemma": "の",
"pos": "格助詞",
"features": [
"連体"
],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 11,
"head": 13,
"dep": "D",
"chunk_head": 1,
"chunk_func": 2,
"links": [
{
"link": 10,
"label": "adjectivals"
}
]
},
"tokens": [
{
"id": 30,
"form": "機械",
"kana": "キカイ",
"lemma": "機械",
"pos": "名詞",
"features": [],
"attributes": {}
},
{
"id": 31,
"form": "学習",
"kana": "ガクシュウ",
"lemma": "学習",
"pos": "名詞",
"features": [
"動作"
],
"dependency_labels": [
{
"token_id": 28,
"label": "nmod"
},
{
"token_id": 30,
"label": "compound"
},
{
"token_id": 32,
"label": "cop"
}
],
"attributes": {}
},
{
"id": 32,
"form": "で",
"kana": "デ",
"lemma": "で",
"pos": "判定詞",
"features": [
"連用"
],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 12,
"head": 13,
"dep": "D",
"chunk_head": 0,
"chunk_func": 0,
"links": []
},
"tokens": [
{
"id": 33,
"form": "何か",
"kana": "ナニカ",
"lemma": "何か",
"pos": "連用詞",
"features": [],
"dependency_labels": [],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 13,
"head": 16,
"dep": "D",
"chunk_head": 0,
"chunk_func": 6,
"links": [
{
"link": 11,
"label": "condition"
},
{
"link": 12,
"label": "manner"
}
],
"predicate": [
"past"
]
},
"tokens": [
{
"id": 34,
"form": "し",
"kana": "シ",
"lemma": "する",
"pos": "動詞語幹",
"features": [
"SURU"
],
"dependency_labels": [
{
"token_id": 31,
"label": "nmod"
},
{
"token_id": 33,
"label": "advmod"
},
{
"token_id": 35,
"label": "aux"
},
{
"token_id": 36,
"label": "aux"
},
{
"token_id": 37,
"label": "aux"
},
{
"token_id": 38,
"label": "punct"
},
{
"token_id": 39,
"label": "mark"
},
{
"token_id": 40,
"label": "case"
}
],
"attributes": {}
},
{
"id": 35,
"form": "て",
"kana": "テ",
"lemma": "て",
"pos": "動詞接尾辞",
"features": [
"接続",
"連用"
],
"attributes": {}
},
{
"id": 36,
"form": "み",
"kana": "ミ",
"lemma": "みる",
"pos": "動詞語幹",
"features": [
"A",
"Lて連用"
],
"attributes": {}
},
{
"id": 37,
"form": "たい",
"kana": "タイ",
"lemma": "たい",
"pos": "動詞接尾辞",
"features": [
"終止"
],
"attributes": {}
},
{
"id": 38,
"form": "。",
"kana": "",
"lemma": "。",
"pos": "句点",
"features": [],
"attributes": {}
},
{
"id": 39,
"form": "と",
"kana": "ト",
"lemma": "と",
"pos": "引用助詞",
"features": [
"連用"
],
"attributes": {}
},
{
"id": 40,
"form": "は",
"kana": "ハ",
"lemma": "は",
"pos": "連用助詞",
"features": [],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 14,
"head": 16,
"dep": "D",
"chunk_head": 0,
"chunk_func": 0,
"links": []
},
"tokens": [
{
"id": 41,
"form": "いえ",
"kana": "イエ",
"lemma": "いえる",
"pos": "動詞語幹",
"features": [
"A"
],
"dependency_labels": [
{
"token_id": 42,
"label": "punct"
}
],
"attributes": {}
},
{
"id": 42,
"form": "、",
"kana": "",
"lemma": "、",
"pos": "読点",
"features": [],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 15,
"head": 16,
"dep": "D",
"chunk_head": 1,
"chunk_func": 2,
"links": []
},
"tokens": [
{
"id": 43,
"form": "基本",
"kana": "キホン",
"lemma": "基本",
"pos": "名詞",
"features": [],
"attributes": {}
},
{
"id": 44,
"form": "知識",
"kana": "チシキ",
"lemma": "知識",
"pos": "名詞",
"features": [],
"dependency_labels": [
{
"token_id": 43,
"label": "compound"
},
{
"token_id": 45,
"label": "case"
}
],
"attributes": {}
},
{
"id": 45,
"form": "すら",
"kana": "スラ",
"lemma": "すら",
"pos": "連用助詞",
"features": [],
"attributes": {}
}
]
},
{
"chunk_info": {
"id": 16,
"head": -1,
"dep": "O",
"chunk_head": 0,
"chunk_func": 1,
"links": [
{
"link": 7,
"label": "manner"
},
{
"link": 8,
"label": "manner"
},
{
"link": 13,
"label": "object"
},
{
"link": 14,
"label": "manner"
},
{
"link": 15,
"label": "object"
}
],
"predicate": []
},
"tokens": [
{
"id": 46,
"form": "な",
"kana": "ナ",
"lemma": "ない",
"pos": "形容詞語幹",
"features": [
"アウオ段"
],
"dependency_labels": [
{
"token_id": 20,
"label": "advcl"
},
{
"token_id": 25,
"label": "advmod"
},
{
"token_id": 34,
"label": "dobj"
},
{
"token_id": 41,
"label": "advmod"
},
{
"token_id": 44,
"label": "dobj"
},
{
"token_id": 47,
"label": "aux"
},
{
"token_id": 48,
"label": "punct"
}
],
"attributes": {
"DepLabel": "NEG"
}
},
{
"id": 47,
"form": "い",
"kana": "イ",
"lemma": "い",
"pos": "形容詞接尾辞",
"features": [
"終止"
],
"attributes": {}
},
{
"id": 48,
"form": "。",
"kana": "",
"lemma": "。",
"pos": "句点",
"features": [],
"attributes": {}
}
]
}
],
"status": 0,
"message": ""
}
標準フォーマットではなさそうですね。chunk_info という要素もあり、固まり情報も提供してくれるようです。
AWS Comprehend 使ってみた
コンソールからもサンプル実行できるらしい。
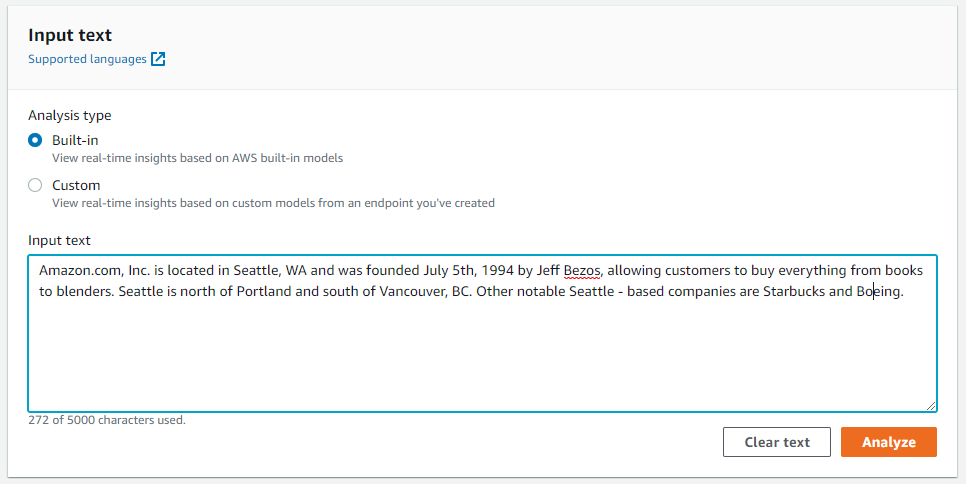
の入力に対して
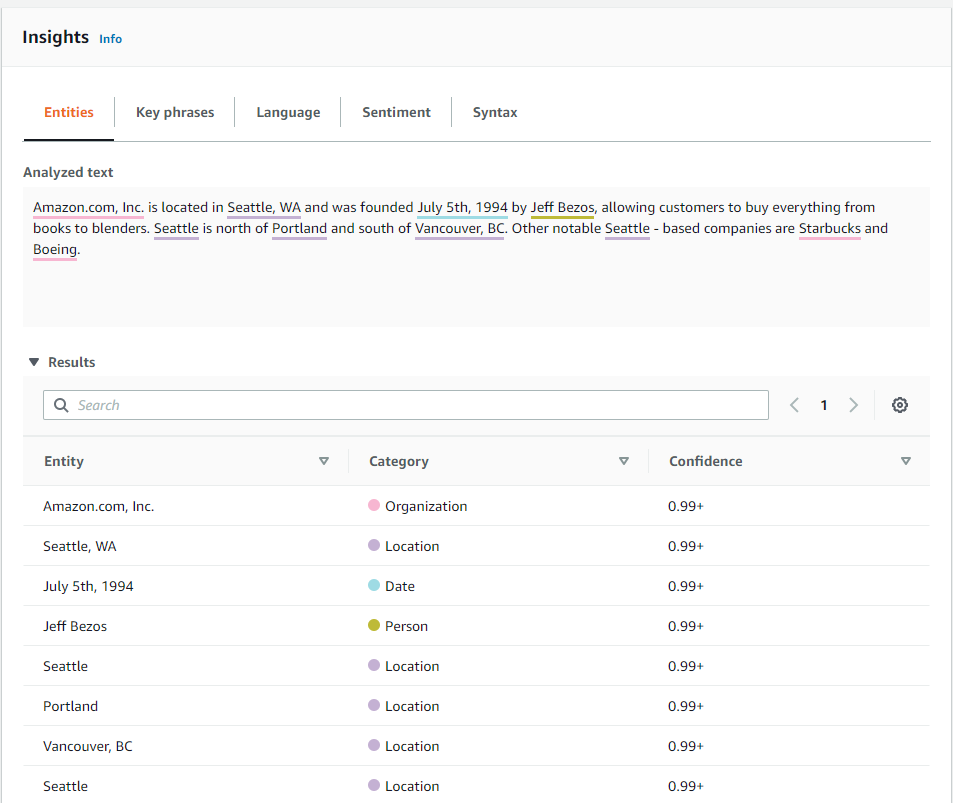
の様な結果を返してくれるはずだが、
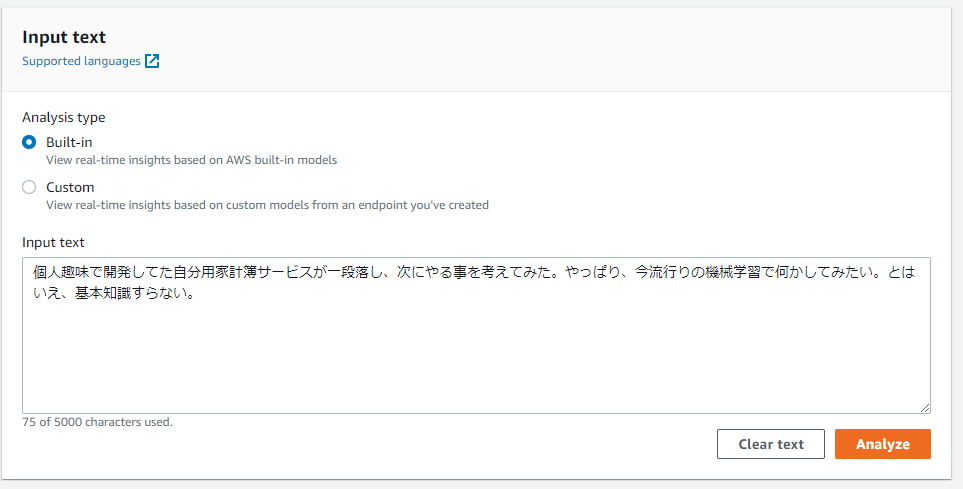
の入力に対して、
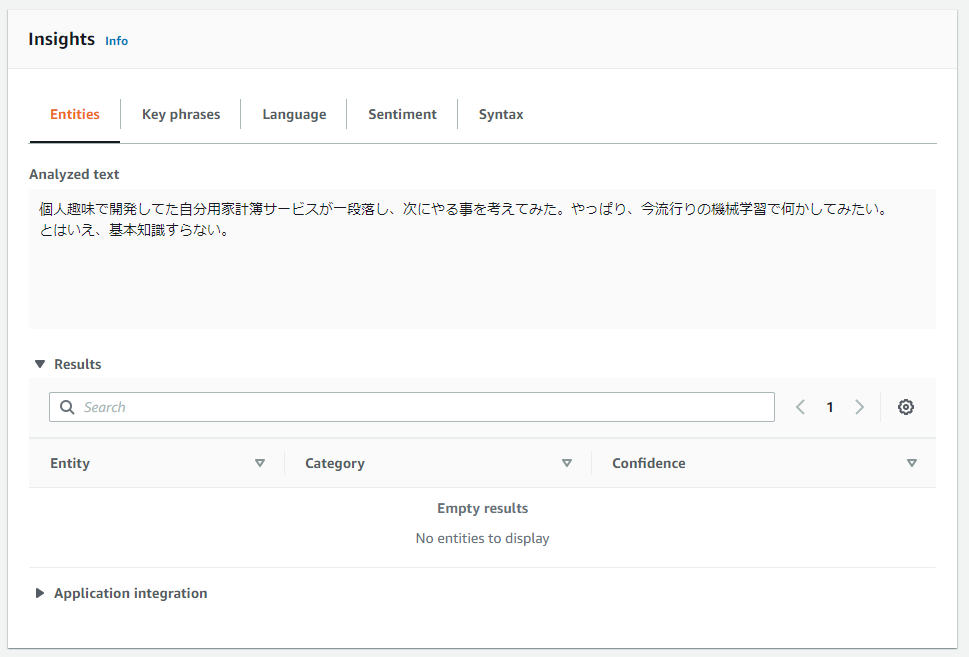
こんな感じ。一応日本語サポートされてるらしいのだけど。
Languages Supported in Amazon Comprehend
APIだとうまく行くのかな?この調子だとあまり期待できない。
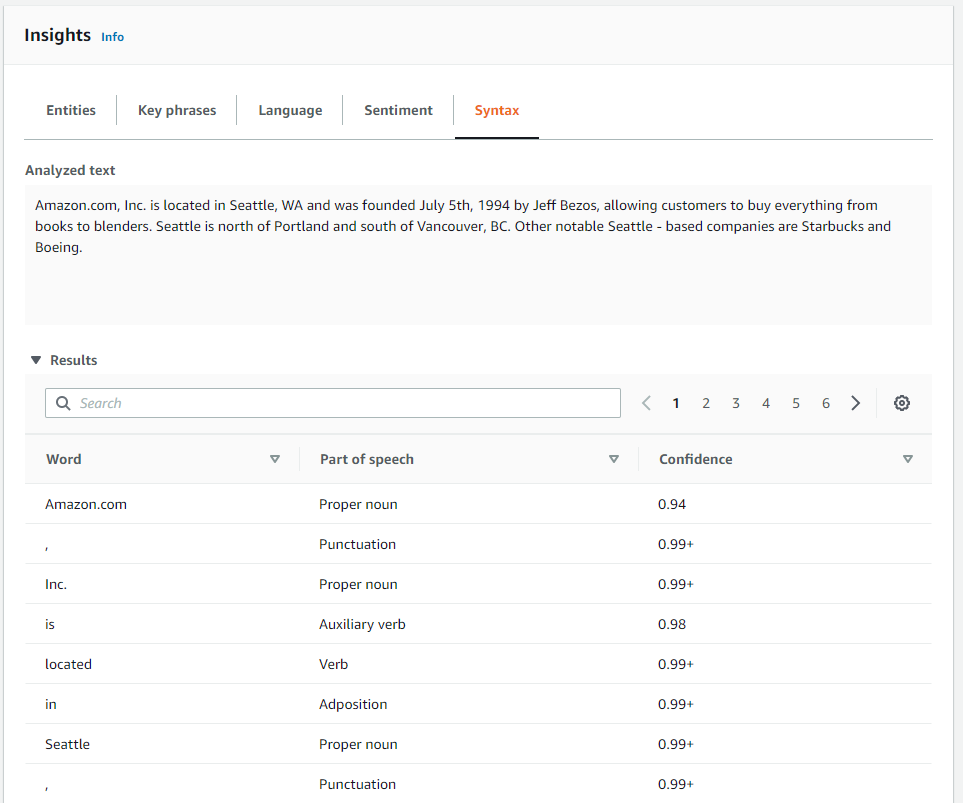
構文解析はSyntaxの方だったのかも。ただ、こっちは日本語未対応。マジか。
重要ワード
上記対応で色々調べていっているうちに知った重要ワード
コーパス
言語学において、自然言語処理の研究に用いるため、自然言語の文章を構造化し大規模に集積したもの。(wikiより引用)
CoNLL-U Format
言語学で決められている(?)構文解析結果のフォーマット
言語処理100本ノック
言語処理100本ノック 2015
東北大学の乾・鈴木研究室で使用されている、言語処理の基本を体に叩き込むための課題集(だと思う)。Qiitaでも取り組んでいる人が多い様子。自分もやってみたい。
ベクトル化
単語の特徴を数値化したもの。これにより更なる処理が出来るようになる。今後もっといろいろな事をやる時には必要になるはず。
感想
多分画像処理系と共に機械学習の大きなターゲットである自然言語処理。画像処理系は必要サンプル数も処理時間も相当なものになりそう。個人が趣味でやるには自然言語の方がよさそう。自分の当面の目標であるクソアプリのネタも色々転がっていそう。
100本ノックに走るか、もうちょっと各種サービスを体験するか悩んでいる今日この頃。