はじめに
最近、Pythonの言語処理ツール「GiNZA」を使い始めました。これまではMeCabを使っていましたが、なにやら最先端の機械学習技術を取り入れたライブラリがPythonにあるというのを(恥ずかしながら)最近知ったので、現在GiNZAに移行中です。今回は初めてのGiNZAということもあり、いろいろなサイトを参考にしながら備忘録として処理の流れをまとめてみました。筆者は自然言語解析の初学者で至らぬ箇所も多々ありますので、より深く学習したい方は公式ドキュメントなどを参考にしてください。この記事は、筆者と同じ初学者が「GiNZAってこんなことが出来るんだ!自分も使ってみよう!」と思ってくれればいいなと思いながら書いています。
GiNZAについて
既に多くの方が記事にされていますが、GiNZAはリクルートのAI研究機関であるMegagon Labsと国立国語研究所との共同研究成果の学習モデルを用いた自然言語処理ライブラリです。
「GiNZA」の概要
「GiNZA」は、ワンステップでの導入、高速・高精度な解析処理、単語依存構造解析レベルの国際化対応などの特長を備えた日本語自然言語処理オープンソースライブラリです。「GiNZA」は、最先端の機械学習技術を取り入れた自然言語処理ライブラリ「spaCy」(※5)をフレームワークとして利用しており、また、オープンソース形態素解析器「SudachiPy」(※6)を内部に組み込み、トークン化処理に利用しています。「GiNZA日本語UDモデル」にはMegagon Labsと国立国語研究所の共同研究成果が組み込まれています。
https://www.recruit.co.jp/newsroom/2019/0402_18331.htmlより引用
GiNZAの内部では言語処理ライブラリ「spaCy」を利用しているようですね。こちらに記載されているように、GiNZAはspaCyを日本語対応にしたライブラリであるとざっくり解釈しています。また、形態素解析には「SudachiPy」を利用しています。この記事を読む多くの方が日本語の解析を望んでいるはずなので、Pythonユーザーにとって魅力的なライブラリですね!
開発環境
- Ubuntu 16.04
- Python 3.6.7
- GiNZA 2.2.0
(2020/01/04現在、GiNZAの最新バージョンは2.2.1です。)
GiNZAはpipコマンド一行でインストール出来ます。
$ pip install "https://github.com/megagonlabs/ginza/releases/download/latest/ginza-latest.tar.gz"
※2020/01/21追記
GiNZA開発者様からご連絡をいただきました。(誠にありがとうございます)
最新バージョンのGiNZAでは、以下のコマンド
$ pip install ginza
でインストール出来るようになっています!(2020/01/21現在、GiNZAの最新バージョンは3.1.1です。)
詳細に関しては公式サイトよりご確認ください。
形態素解析
まずは基本の形態素解析を行います。
import spacy
nlp = spacy.load('ja_ginza')
doc = nlp('今年の干支は庚子です。東京オリンピックたのしみだなあ。')
for sent in doc.sents:
for token in sent:
print(token.i, token.orth_, token.lemma_, token.pos_,
token.tag_, token.dep_, token.head.i)
出力結果
0 今年 今年 NOUN 名詞-普通名詞-副詞可能 nmod 2
1 の の ADP 助詞-格助詞 case 0
2 干支 干支 NOUN 名詞-普通名詞-一般 nsubj 4
3 は は ADP 助詞-係助詞 case 2
4 庚子 庚子 NOUN 名詞-普通名詞-一般 ROOT 4
5 です です AUX 助動詞 aux 4
6 。 。 PUNCT 補助記号-句点 punct 4
7 東京 東京 PROPN 名詞-固有名詞-地名-一般 compound 9
8 オリンピック オリンピック NOUN 名詞-普通名詞-一般 compound 9
9 たのしみ 楽しみ NOUN 名詞-普通名詞-一般 ROOT 9
10 だ だ AUX 助動詞 cop 9
11 なあ な PART 助詞-終助詞 aux 9
12 。 。 PUNCT 補助記号-句点 punct 9
上手く形態素に分割できています。左から「入力語」「見出し語(基本形)」「品詞」「品詞詳細」です(tokenの詳細はspaCyのAPIを参照してください)。GiNZAでは依存構造解析にも対応しており、依存関係にある単語番号とその単語との関係も推定されています(token.dep_の詳細はこちらを参照してください)。
GiNZAでは依存関係をグラフで可視化することも可能です。可視化にはdisplacyを使います。
from spacy import displacy
displacy.serve(doc, style='dep', options={'compact':True})
実行後、Serving on http://0.0.0.0:5000 ...と表示されるので、アクセスすると図が表示されます。

MeCabしか使ってこなかったので、一行で構造を図示してくれるのは素晴らしいの一言です。可視化手法の詳細はspaCyのVisualizersを参照してください 。
テキストのベクトル化
単語ベクトルの推定法はいくつか提案されていますが、GiNZAには既に学習済みの単語ベクトルが用意されており、Tokenのvector属性で参照することが出来ます。
doc = nlp('あきらめたらそこで試合終了だ')
token = doc[4]
print(token)
print(token.vector)
print(token.vector.shape)
実行結果
試合
[-1.7299166 1.3438352 0.51212436 0.8338855 0.42193085 -1.4436126
4.331309 -0.59857213 2.091658 3.1512427 -2.0446565 -0.41324708
...
1.1213776 1.1430703 -1.231743 -2.3723211 ]
(100,)
単語ベクトルの次元数は100次元です。
また、similarity()メソッドを使用することで単語ベクトル間のコサイン類似度をはかることが出来ます。
word1 = nlp('おむすび')
word2 = nlp('おにぎり')
word3 = nlp('カレー')
print(word1.similarity(word2))
# 0.8016603151410209
print(word1.similarity(word3))
# 0.5304326270109458
コサイン類似度は0-1の範囲を取り、1に近いほど単語同士が似ているという意味になります。実際に、おむすびはカレーよりおにぎりに近いです。また、単語ではなく文書の場合でも同じ手順でベクトル化とコサイン類似度の計算が出来ます。文書のベクトルは、その文を構成する単語ベクトルの平均を返しているようです。
最後に、単語や文書をベクトルで表現できたのでこれらをベクトル空間に図示してみます。ベクトルの次元は100次元なので今回は主成分分析を用いて2次元まで落としてからプロットします。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# text2vector
vec1 = nlp('あけましておめでとうございます').vector
vec2 = nlp('昨日キャベツを買った').vector
vec3 = nlp('映画を観に行こう').vector
vec4 = nlp('カレーが食べたい').vector
vec5 = nlp('買い物しようと町まで出かけた').vector
vec6 = nlp('昨日食べたチョコレート').vector
# pca
vectors = np.vstack((vec1, vec2, vec3, vec4, vec5, vec6))
pca = PCA(n_components=2).fit(vectors)
trans = pca.fit_transform(vectors)
pc_ratio = pca.explained_variance_ratio_
# plot
plt.figure()
plt.scatter(trans[:,0], trans[:,1])
i = 0
for txt in ['text1','text2','text3','text4','text5','text6']:
plt.text(trans[i,0]-0.2, trans[i,1]+0.1, txt)
i += 1
plt.hlines(0, min(trans[:,0]), max(trans[:,0]), linestyle='dashed', linewidth=1)
plt.vlines(0, min(trans[:,1]), max(trans[:,1]), linestyle='dashed', linewidth=1)
plt.xlabel('PC1 ('+str(round(pc_ratio[0]*100,2))+'%)')
plt.ylabel('PC2 ('+str(round(pc_ratio[1]*100,2))+'%)')
plt.tight_layout()
plt.show()
実行結果
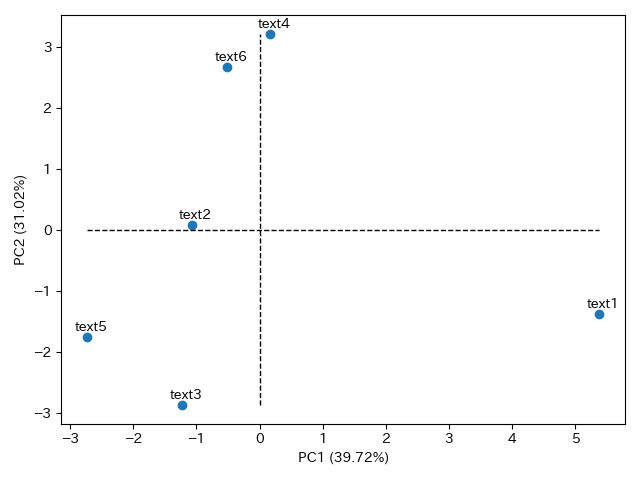
情報量は落ちていますが、大量のデータを扱うにはこちらの方が認識しやすいかと思います。この図を見るとtext3と5が、text4と6がそれぞれ近いようですね。肌感覚でもそんな気がします。
最後に
自然言語処理初学者でしたが、GiNZAを利用することで形態素解析からベクトル化まで簡単に解析することが出来ました。これから言語処理を始めたい方にぜひオススメです。もし間違っている箇所やおかしな表現などありましたらご指摘をいただけますと幸いです。