
引用:https://info.tigergraph.com/gsql
はじめに
GraphDBのTigerGraphをざっくり理解するためのエントリーです。
公式ドキュメントと触った感じを基に、TigerGraphの概要や基礎部分、個人的に特徴的と思った部分をまとめました。
TigerGraphとは
TigerGraphとは、高速でスケーラブルなGraphDBです。
Native Parallel Graphと呼ばれる技術によって、リアルタイムに完全な分散型の並列グラフコンピューティングを提供します。
GraphDBとは
そもそも、GraphDB自体聞き慣れないという方も多いと思うので、簡単に説明します。
まず、「Graph」とは、頂点と辺で構成されます。頂点のことをVertexまたはNode、辺のことをEdgeと呼び、頂点と辺で何かしらの関係を表現します。
例えば、「AさんとBさんは友達」という関係をグラフで表現すると、以下となります。
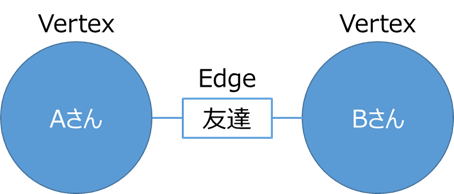
そして、ある頂点に隣接している頂点の探索が高速な仕組みを持つデータベースが**「GraphDB」**です。
※RDBでも他のDBでもGraph構造を表現することは可能です。
GraphDBは、「あるユーザの友達の友達が知りたい」や「スタート地点からゴール地点までの最短経路が知りたい」といったときに活躍してくれます。
参考:https://www.slideshare.net/doryokujin/graphdbgraphdb
TigerGraphのインストール
インストールは、ドキュメントに記載の方法でサクッと完了しました。
私が触ったときは、AWSにインスタンスを作成し、Ubuntu上にインストールしました。
$ wget http://dl.tigergraph.com/tigergraph-developer-latest.tar.gz
$ tar xzf <your_tigergraph_package>.tar.gz
$ cd tigergraph-*/
$ sudo ./install.sh
# y -> N -> N -> N
インストール時に指定しない場合、tigergraphというユーザが作成され、以後そのユーザで操作します。
この場合、次回操作時は、su - tigergraphしてから操作します。
GSQL
GSQLは、TigerGraphのSQLライクなクエリです。
コンソール上からgsqlと入力すると、GSQLで操作できるようになります。
下記のサンプルは、公式ドキュメントから抜粋しています。
Vertexの定義
Vertexは、CREATE VERTEXコマンドで定義します。PRIMARY_IDが必須項目です。
GSQL > CREATE VERTEX person (PRIMARY_ID name STRING, name STRING, age INT, gender STRING, state STRING)
Edgeの定義
Edgeは、CREATE ... EDGEコマンドで定義します。UNDIRECTEDは、双方向のEdgeであることを示します。また、単一方向のEdgeは、DIRECTEDを指定します。
FROMとTOにEdgeが接続するVertexを指定します。個々のEdgeは、VertexのPRIMARY_IDをFROM、TOに与えることで関係を指定します。
GSQL > CREATE UNDIRECTED EDGE friendship (FROM person, TO person, connect_day DATETIME)
Graphの作成
CREATE GRAPHコマンドで、定義されたVertexとEdgeで構成されるグラフを作成します。
GSQL > CREATE GRAPH social (person, friendship)
ちなみに、グラフに関連する定義を全て消す場合は、GSQLでdrop allです。
データのロード
ロードするデータをCSVで以下のように用意しておきます。
name,gender,age,state
Tom,male,40,ca
Dan,male,34,ny
Jenny,female,25,tx
person1,person2,date
Tom,Dan,2017-06-03
Tom,Jenny,2015-01-01
Dan,Jenny,2016-08-03
まずは、USE GRAPHコマンドで、どのグラフを利用するか宣言します。
GSQL > USE GRAPH social
CREATE LOADING JOBでジョブを定義することで、複数ファイルから複数のオブジェクトへマッピングすることができます。
BEGIN ... ENDは複数行モードの宣言です。
この場合、Vertexのnameは、PRIMARY_IDとnameにマッピングされます。
CREATE LOADING JOBを実行すると構文エラーチェック、ジョブのコンパイルが実行され、ジョブが保存されます。
GSQL > BEGIN
GSQL > CREATE LOADING JOB load_social FOR GRAPH social {
GSQL > DEFINE FILENAME file1="/home/tigergraph/person.csv";
GSQL > DEFINE FILENAME file2="/home/tigergraph/friendship.csv";
GSQL > LOAD file1 TO VERTEX person VALUES ($"name", $"name", $"age", $"gender", $"state") USING header="true", separator=",";
GSQL > LOAD file2 TO EDGE friendship VALUES ($"person1", $"person2", $"date") USING header="true", separator=",";
GSQL > }
GSQL > END
RUN LOADING JOBコマンドで定義したジョブを実行し、グラフにデータをロードします。
GSQL > RUN LOADING JOB load_social
Vertexの取得
WHERE句で条件を指定してVertexを取得できます。
結果は、JSONで返ってきます。
GSQL > SELECT * FROM person WHERE primary_id=="Tom"
Edgeの取得
from_idを指定することで、指定したVertexから伸びるEdgeを取得できます。
こちらも結果は、JSONで返ってきます。
SELECT * FROM person-(friendship)->person WHERE from_id =="Tom"
より複雑なGSQL
GSQLコマンドを.gsqlファイル形式で作成し、インストールさせた上でクエリを発行できます。
これにより、パラメータを指定して発行するクエリ等、より複雑なクエリを実行でき、JSONで結果が返されます。
また、インストールしたクエリをRESTエンドポイントとしても実行可能です。
gadmin
TigerGraphを管理するためのツールとして、gadminが提供されています。
下記はコマンドの一例です。gadmin -hでコマンドの一覧が確認できます。
$ gadmin restart all
$ gadmin log
$ gadmin --configure timeout_seconds
$ gadmin config-apply
GraphStudio UI
GUIでグラフをブラウザから操作できるツールも用意されています。
個人的には、コマンドベースで動かしましたが、GUIの方がいいという人にも優しいTigerGraphです。
GraphStudioのドキュメントを見ていると、想像より色々機能が充実しているようで、ざっくり以下などができます。画像は、GSQLの操作画面です。
- ユーザ管理
- グラフスキーマの定義
- データのロード、グラフへのマッピング
- グラフへの読み書き
- GSQLの作成、インストール、実行
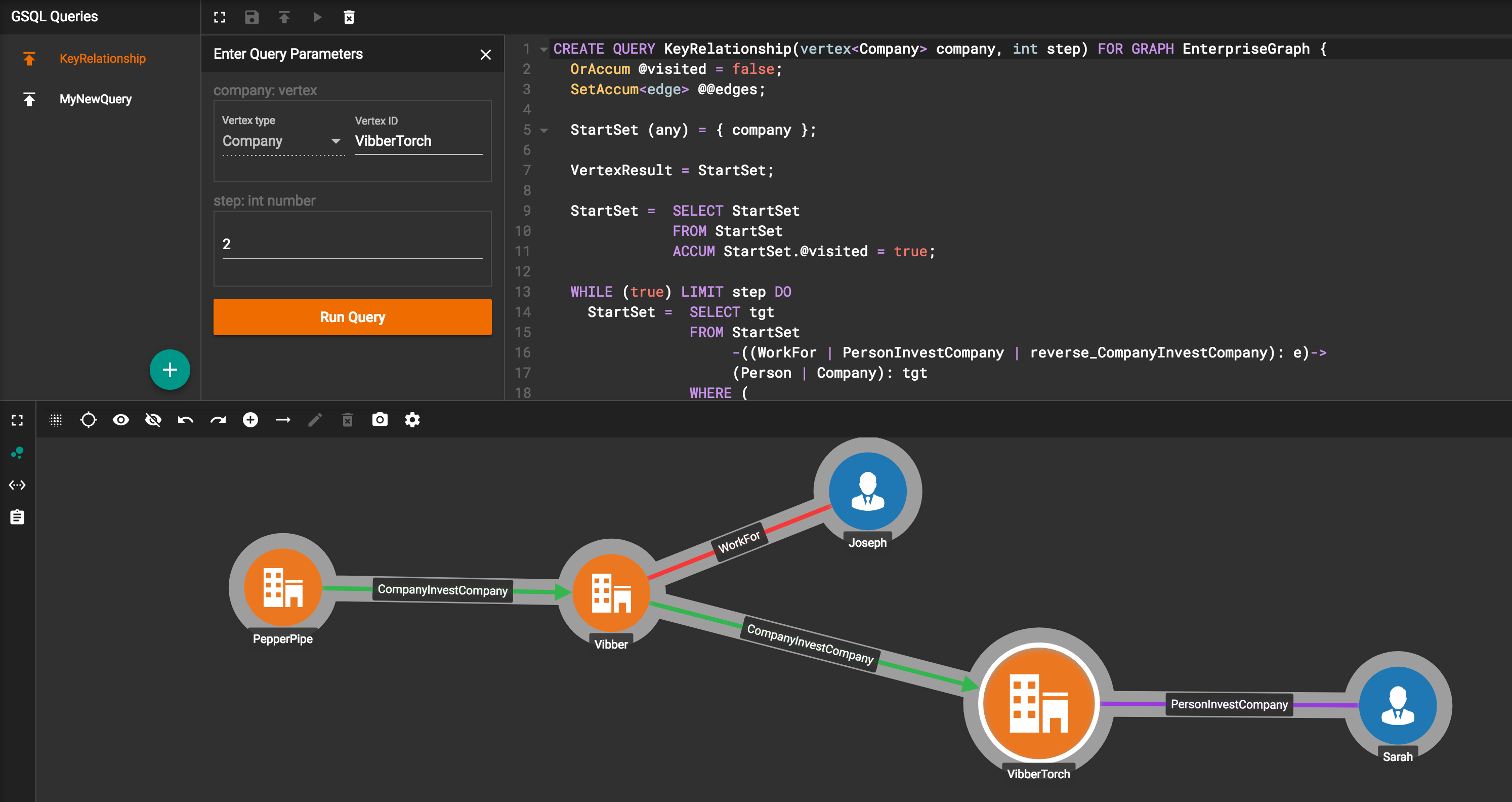
引用:https://doc.tigergraph.com/2.1/TigerGraph-GraphStudio-UI-Guide.html
その他ドキュメントの要点
トランザクション
- TigerGraphは、オートミットの順次処理です。ロールバックはできず、自動ロックです。
- ACID特性の詳細はこちらのExample Scenariosを読めば理解が早いです。
インデックス
- VertexのPKにハッシュインデックスが自動で作成されます。
※セカンダリインデックスをVertexとEdgeで構築可能とドキュメント内に記載がありますが、具体的にどうするかは調査中です。
MultiGraph
- TigerGraphのMultiGraphサービスを利用することで、1つのインスタンス内で複数のグラフを管理できます。下図のように、ユーザの権限に応じて、参照や更新可能な範囲を設定や複数グラフで共有する箇所を設定することが可能です。
- TigerGraphのエンタープライズエディションで利用できます。
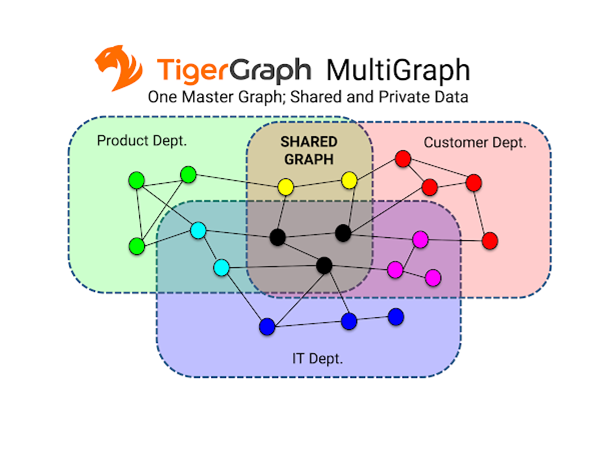
引用:https://www.tigergraph.com/2018/02/27/introducing-tigergraph-2-0/
High Availability Cluster
- TigerGraphのクラスタ構成では、グラフを分割して複数インスタンスに分散できます。Kafkaでメッセージングし、インスタンス間の同期が実現されています。
- こちらもTigerGraphのエンタープライズエディションで利用可能です。
おわりに
SQLライクにクエリが記述でき、グラフの作成もすんなり完了したので、お試しだけならとっつきやすいです。
ただ、現時点で関数等の便利機能は、ほとんど提供されていません。
なので、複雑なクエリが必要な場合は、自分でGSQLを書いていく必要があるため、玄人向けといった印象です。
また、今回触ったのは、エンタープライズエディションではなかったので、グラフの分散をどう構築するかや、実用的かは気になるポイントです。
参考:https://doc.tigergraph.com/report/WP_NativeParallelGraphs_Sep17_web.pdf
簡単に速度の検証もしてみました。こちらもどうぞ。
【入門】TigerGraphを触ってみた ~検証編~