これは何?
なんかすげーモデルが公開されたらしい(語彙力)ということで、お家のノートパソコン(GPU無し)でどこまでやれるか検証しました。
Claude Codeの変わりにならないか期待しています。
環境
- Ubuntu 22.04
- ノートパソコン(GPUなし、メモリ16 GB)
環境構築
python 3.12と3.14はライブラリの依存関係でうまくいかなさそうだったので3.13で試しています。
Hagging Faceの設定
ちょうど別のモデルを試した時に記載したものを参照してください。
python3.13 install
uv python install 3.13
uv python pin 3.13
プロジェクト構築
uv init
With transformers<4.51.0, you will encounter the following error:
こんなことが書いてあったので先にtransformersを入れて動かしたらpytorchがいると言われ、pytorchにtransformersが依存しているようなのでpytorchのcpu版を先にinstallする。
uv add torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
warning: Indexes specified via `--index-url` will not be persisted to the `pyproject.toml` file; use `--default-index` instead.
× No solution found when resolving dependencies for split
│ ((platform_machine != 'aarch64' and sys_platform == 'linux') or
│ (sys_platform != 'darwin' and sys_platform != 'linux')):
╰─▶ Because transformers was not found in the package registry and your
project depends on transformers>=4.54.1, we can conclude that your
project's requirements are unsatisfiable.
help: If you want to add the package regardless of the failed resolution,
provide the `--frozen` flag to skip locking and syncing.
uv remove transformers
uv add torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
uv pip install transformers # これaddにするべきだったけど、めんどくさいので一旦これで
サンプルコード実行
実行するとaccelerateもいると怒られたのでこれもいれておく
uv pip install accelerate
公式そのままのコードをuv initした時にできたmain.py似コピペして動かす。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-30B-A3B-Instruct"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Write a quick sort algorithm."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
uv run main.py
model.safetensors.index.json: 1.70MB [00:00, 149MB/s]
Fetching 16 files: 0%| | 0/16 [00:00<?, ?it/s]
model-00002-of-00016.safetensors: 0%| | 785k/4.00G [00:39<188:07:44, 5.90kB/
model-00001-of-00016.safetensors: 0%| | 710k/4.00G [00:29<26:22:20, 42.1kB/s
model-00008-of-00016.safetensors: 0%| | 0.00/4.00G [00:00<?, ?B/s]
model-00004-of-00016.safetensors: 0%| | 0.00/4.00G [00:00<?, ?B/s]
model-00005-of-00016.safetensors: 0%| | 2.04M/4.00G [00:29<13:37:52, 81.5kB/
model-00006-of-00016.safetensors: 0%| | 0.00/4.00G [00:00<?, ?B/s]
model-00007-of-00016.safetensors: 0%| | 0.00/4.00G [00:00<?, ?B/s]
model-00003-of-00016.safetensors: 0%| | 805k/4.00G [00:49<43:20:18, 25.6kB/s
初期セットアップのモデルダウンロードに時間がかかりそうだったので一旦寝る。
朝起きたら動いていた。
uv run main.py
model.safetensors.index.json: 1.70MB [00:00, 149MB/s]
model-00001-of-00016.safetensors: 100%|██| 4.00G/4.00G [59:33<00:00, 1.12MB/s]
model-00003-of-00016.safetensors: 100%|█| 4.00G/4.00G [1:05:13<00:00, 1.02MB/s
model-00005-of-00016.safetensors: 100%|█| 4.00G/4.00G [1:08:35<00:00, 972kB/s]
model-00002-of-00016.safetensors: 100%|█| 4.00G/4.00G [1:17:20<00:00, 862kB/s]
model-00006-of-00016.safetensors: 100%|█| 4.00G/4.00G [1:19:12<00:00, 842kB/s]
model-00008-of-00016.safetensors: 100%|█| 4.00G/4.00G [1:19:13<00:00, 841kB/s]
model-00007-of-00016.safetensors: 100%|█| 4.00G/4.00G [1:19:23<00:00, 840kB/s]
model-00004-of-00016.safetensors: 100%|█| 4.00G/4.00G [1:19:41<00:00, 837kB/s]
model-00009-of-00016.safetensors: 100%|██| 4.00G/4.00G [38:28<00:00, 1.73MB/s]
model-00016-of-00016.safetensors: 100%|███| 1.09G/1.09G [35:44<00:00, 506kB/s]
model-00011-of-00016.safetensors: 100%|█| 4.00G/4.00G [1:04:27<00:00, 1.03MB/s
model-00012-of-00016.safetensors: 100%|█| 3.99G/3.99G [1:00:21<00:00, 1.10MB/s
model-00010-of-00016.safetensors: 100%|█| 4.00G/4.00G [1:13:00<00:00, 913kB/s]
model-00013-of-00016.safetensors: 100%|██| 4.00G/4.00G [59:27<00:00, 1.12MB/s]
model-00014-of-00016.safetensors: 100%|██| 4.00G/4.00G [59:29<00:00, 1.12MB/s]
model-00015-of-00016.safetensors: 100%|██| 4.00G/4.00G [59:45<00:00, 1.12MB/s]
Fetching 16 files: 100%|███████████████████| 16/16 [2:19:11<00:00, 521.97s/it]
Loading checkpoint shards: 100%|██████████████| 16/16 [00:01<00:00, 8.01it/s]
generation_config.json: 100%|█████████████████| 180/180 [00:00<00:00, 857kB/s]
Some parameters are on the meta device because they were offloaded to the disk and cpu.14-of-00016.safetensors: 100%|██| 4.00G/4.00G [59:29<00:00, 1.92MB/s]
content: Here's a quicksort algorithm implementation in Python:0:42, 1.59MB/s]
model-00015-of-00016.safetensors: 100%|██| 4.00G/4.00G [59:45<00:00, 1.79MB/s]
\```python
def quicksort(arr):
"""
Sorts an array using the quicksort algorithm.
Args:
arr: List of comparable elements
Returns:
None (sorts in-place)
"""
if len(arr) <= 1:
return
def partition(low, high):
"""Partition function using last element as pivot"""
pivot = arr[high]
i = low - 1 # Index of smaller element
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i] # Swap elements
arr[i + 1], arr[high] = arr[high], arr[i + 1] # Place pivot in correct position
return i + 1
def quicksort_helper(low, high):
"""Recursive helper function"""
if low < high:
# Partition the array and get pivot index
pi = partition(low, high)
# Recursively sort elements before and after partition
quicksort_helper(low, pi - 1)
quicksort_helper(pi + 1, high)
quicksort_helper(0, len(arr) - 1)
# Example usage:
if __name__ == "__main__":
# Test the algorithm
test_array = [64, 34, 25, 12, 22, 11, 90]
print("Original array:", test_array)
quicksort(test_array)
print("Sorted array:", test_array)
# Test with other cases
test_cases = [
[5, 2, 8, 1, 9],
[1],
[],
[3, 3, 3, 3],
[5, 4, 3, 2, 1]
]
for i, case in enumerate(test_cases):
original = case.copy()
quicksort(case)
print(f"Test {i+1}: {original} → {case}")
\```
**How it works:**
1. **Divide**: Choose a "pivot" element and partition the array so that elements smaller than the pivot are on the left, and larger elements are on the right
2. **Conquer**: Recursively apply quicksort to the sub-arrays on both sides of the pivot
3. **Combine**: The array is sorted when all sub-arrays have been processed
**Key features:**
- **Time Complexity**: O(n log n) average case, O(n²) worst case
- **Space Complexity**: O(log n) due to recursion stack
- **In-place sorting**: Modifies the original array
- **Not stable**: Relative order of equal elements may change
**Alternative version with random pivot selection** (better average performance):
\```python
import random
def quicksort_randomized(arr):
"""Quicksort with random pivot selection for better average performance"""
def partition(low, high):
# Randomly select pivot and swap with last element
random_index = random.randint(low, high)
arr[random_index], arr[high] = arr[high], arr[random_index]
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quicksort_helper(low, high):
if low < high:
pi = partition(low, high)
quicksort_helper(low, pi - 1)
quicksort_helper(pi + 1, high)
if len(arr) > 1:
quicksort_helper(0, len(arr) - 1)
\```
The algorithm efficiently sorts arrays by repeatedly dividing them into smaller subproblems, making it one of the most popular sorting algorithms in practice.
こいつ、、動くぞ!!
ちなみにモデルは全部で60 GBくらいだった。
du -h ~/.cache/huggingface/hub/models--Qwen--Qwen3-Coder-30B-A3B-Instruct
68K /home/sigma/.cache/huggingface/hub/models--Qwen--Qwen3-Coder-30B-A3B-Instruct/snapshots/c80c45f9bf08d0618421554990aea2102abcff70
72K /home/sigma/.cache/huggingface/hub/models--Qwen--Qwen3-Coder-30B-A3B-Instruct/snapshots
57G /home/sigma/.cache/huggingface/hub/models--Qwen--Qwen3-Coder-30B-A3B-Instruct/blobs
8.0K /home/sigma/.cache/huggingface/hub/models--Qwen--Qwen3-Coder-30B-A3B-Instruct/refs
4.0K /home/sigma/.cache/huggingface/hub/models--Qwen--Qwen3-Coder-30B-A3B-Instruct/.no_exist/c80c45f9bf08d0618421554990aea2102abcff70
8.0K /home/sigma/.cache/huggingface/hub/models--Qwen--Qwen3-Coder-30B-A3B-Instruct/.no_exist
57G /home/sigma/.cache/huggingface/hub/models--Qwen--Qwen3-Coder-30B-A3B-Instruct
Claude Codeの代替になるか
Qwen-Codeは自分のやりたいこととは違いそう?
.envに設定を書いて起動するらしい。
OpenAIのAPIキーを入れて起動テストするも動かず。
OPENAI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxx"
OPENAI_BASE_URL="https://openrouter.ai/api/v1"
OPENAI_MODEL="qwen/qwen3-coder:free"
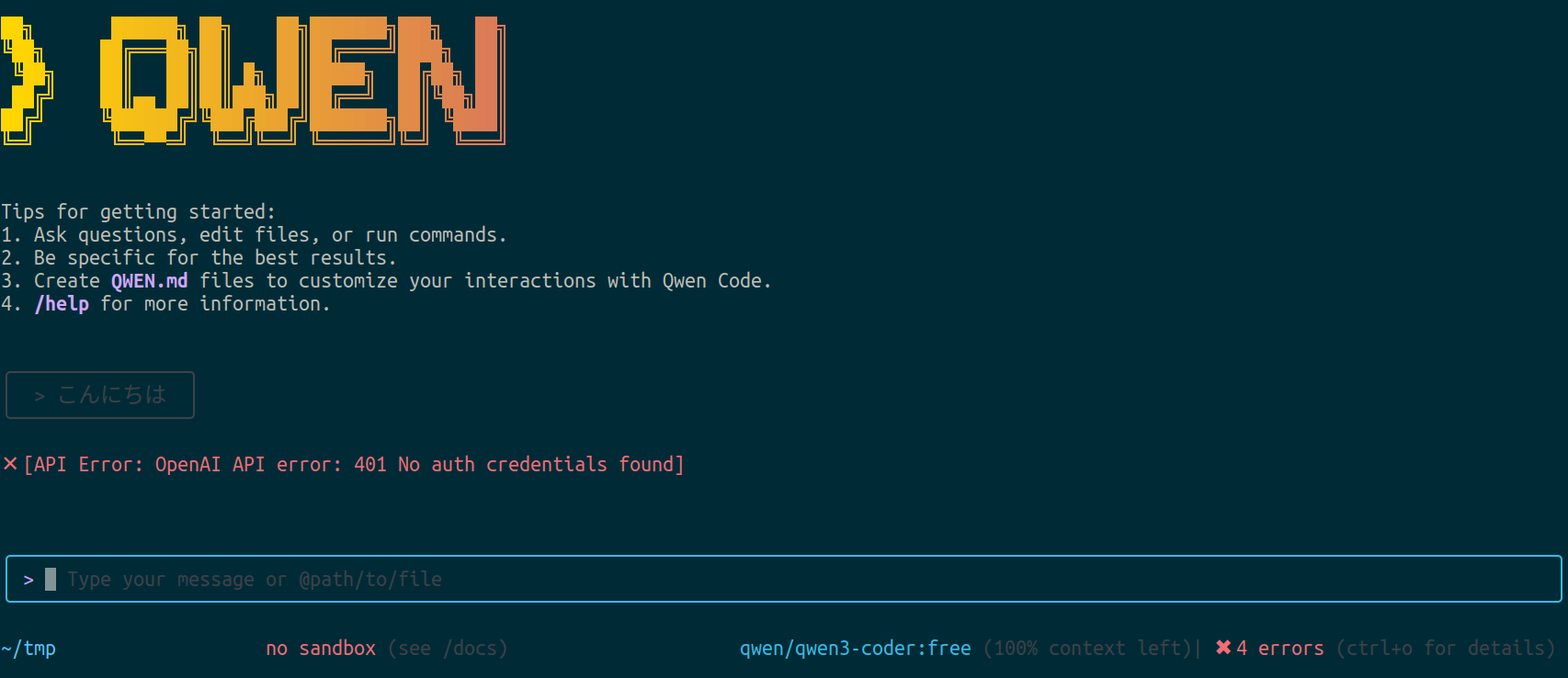
調べてみると、どうやらOpenRouterというやつを契約してそのAPIキーをOPENAI_API_KEYにいれないとだめらしい。
モデルもローカルで動いていなさそうなので用途が違いそうということで一旦放置する
olc(Ollama‑Code)+ Ollama
やはり、モデルにはローカルで動いてほしい。
だが、Agentic Codingを使用と思うと、Hagging Faceで落としてきたモデルを使うのは難しそうだ。
何らかの方法でモデルを別アプリケーションからアクセス可能な状態にし、エージェントツールがこれに対応している必要がある。
Ollamaを使うとローカルでモデルをホストできるらしい。
OllamaでホストしたモデルをOllama-Codeから使えないか試してみる。
TODO