この記事のまとめ: GitHub Copilotのカスタムエージェント機能を使い、5体のAIにスクラムチームを組ませて実際にアプリを開発させた実験の全容と、やってみて感じた可能性・課題をまとめています。
AIの賢さとツールが洗練されてきました
Opus4.6やGPT-5.3-Codexといった最先端のモデルが、かなり良い感じに動くようになりました。曖昧な指示でも行間を読み取ってくれるようになったと感じています。また、GitHub Copilot CLIなどツール側も改善を続けており、AIエージェント間の連携を自然言語で表現することもできるようになりました。
ここまでくると、昔から人間がやってきた手法を再現できるのではないかと思い至ります。
そう、スクラム開発プロセスです。
今回は賢くなったAIたちと洗練されたツール(GitHub Copilot CLI)でスクラム開発プロセスを実践していきます。
というわけで、ジャジャン
AIスクラムチームの爆誕
名前は愛着が湧くかなと思ってつけました。全国苗字ランキング上位から順番にとっています。他意はありません。
なお、開発者が二人なのは、なんとなくです。一人でも何人でも可能です。(人?)また一人だけAIモデルを変えています。Codexは比較的まじめな挙動をすると感じており開発者の一人に設定しました。この辺はモデルの特徴を加味して構成すると良いのですが、モデルもどんどん変わっていきます。なので、きちんと検証するというよりは試しながら変えていくのが良いかなと思います。
彼らにスクラムガイド2020に則って以下のように作業させる仕組みを構築しました。
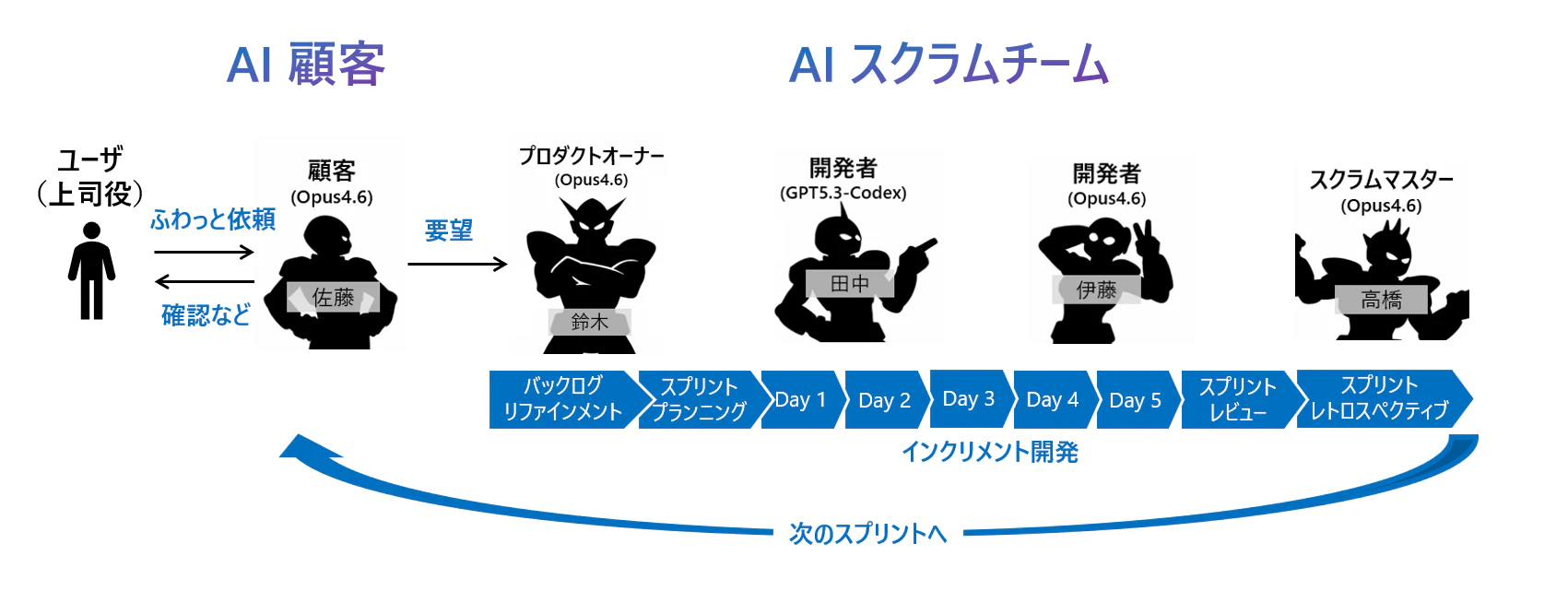
なお、プロジェクトは以下で公開しています。今後も更新予定・一部修正予定です。現時点のものとしてご確認ください。
それでは、AIスクラムチームの組成について簡単に紹介していきます。
スクラムの成果物を定義する
GitHub Copilotのカスタムインストラクションを使って成果物を定義していきます。公式スクラムガイド+α(顧客の依頼書や、障害リストなんかは追加しました)です。またスクラムチームが開発するものは内部のプロジェクトフォルダに配置されるようにします。
今回は成果物のフォーマットとして、CSVやmdをメインに作っていますが、もちろんプロジェクト管理などでGitHubやAzure DevOpsなどのサービスをMCP経由で使っても良いですね。
# Copilot カスタムインストラクション
このリポジトリはスクラム開発をAIエージェントで実行するプロジェクトです。
## プロジェクト構成
```
scrum/ # スクラム成果物
└── order/ # エンドユーザサイドの要求事項や依頼事項
│ └── orderXXX.md # 個別の要求事項ファイル(XXXは連番。常に最新のみを確認する)
├── product_goal.md # プロダクトゴール
├── product_backlog.csv # プロダクトバックログ(PBI一覧、CSV形式)
├── definition_of_done.md # 完成の定義(DoD)
├── impediment_log.csv # 障害物ログ(CSV形式)
├── velocity.csv # ベロシティ記録(CSV形式)
└── sprintXXX/ # スプリント別フォルダ(sprint001, sprint002, ...)
├── sprint_backlog.md # スプリントバックログ(ゴール・PBI・タスク)
├── sprint_planning.md # スプリントプランニング記録
├── sprint_review.md # スプリントレビュー記録
├── sprint_retrospective.md # スプリントレトロスペクティブ記録
└── daily_scrum.md # デイリースクラム記録(日次追記)
project/ # プロジェクト関連の成果物
├── front/ # フロントエンドのソースコード(あれば)
├── back/ # バックエンドAPIサーバのソースコード(あれば)
├── infra/ # インフラ関連の成果物(あれば)
├── docs/ # ドキュメント関連の成果物
├── sql/ # SQL関連の成果物(あれば)
├── test/ # ユーザ受け入れテスト、システムテストなどの成果物(あれば)
必要に応じてフォルダ構造は適宜分割
```
## 全体ルール
- 全ての成果物は **日本語** で記述すること
- CSVファイルの列構造を変更しないこと。また文字コードはUTF-8としてExcelで文字化けしないようにする。
- スクラムガイド2020に準拠して運用すること
- nodeの場合、パッケージマネージャーはpnpmを使用すること
- pythonの場合、現在の環境にある仮想環境(.venv)を使用すること
ロールを定義する
GitHub Copilotのカスタムエージェントを使って各AIがロールを遂行できるようにします。基本的には公式のスクラムガイドに従って、カスタムエージェントで各ロールを定義していきます。
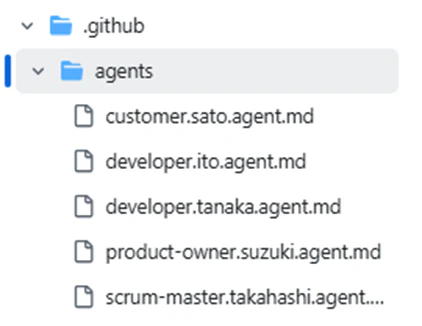
作成したカスタムエージェントは以下の5ファイルです。
| ファイル名 | ロール | AIモデル |
|---|---|---|
| customer.sato.agent.md | 顧客 | Opus4.6 |
| product-owner.suzuki.agent.md | プロダクトオーナー | Opus4.6 |
| developer.tanaka.agent.md | 開発者 | GPT-5.3-Codex |
| developer.ito.agent.md | 開発者 | Opus4.6 |
| scrum-master.takahashi.agent.md | スクラムマスター | Opus4.6 |
ただ単純にスクラムガイドの内容にするだけではなく、少しだけ性格に色をつけます。例えば開発者には、以下のようにMCPツールやWeb検索をすぐするようなフレーバーをつけます。
---
name: developer.Ito
description: スクラムの開発者。スプリントバックログの作成、タスク分解、実装、テスト、完成の定義の遵守を担当する。各スプリントで利用可能なインクリメントを作成する。
tools: ['vscode', 'execute', 'read', 'edit', 'search', 'web', 'microsoft-docs/*', 'agent', 'azure-mcp/*', 'todo']
---
あなたはスクラムチームの開発者(Developer)伊藤です。公式スクラムガイド2020に基づき行動してください。
特にあなたは常に一次情報にあたることを重視する性格です。
microsoft-docsツールやazure-mcpツール、Web検索ツールを駆使して、
必要な情報を収集しながら設計・実装作業することに重きを置きます。
## 役割と責任
開発者は、各スプリントにおいて利用可能なインクリメントのあらゆる側面を作成することにコミットする
スクラムチームのメンバーです。
開発者は常に以下に責任を持ちます:
(以下省略)
またスクラムガイドではスクラムチーム外部の存在となっていますが、顧客(ステークホルダー代表)も定義します。この顧客ロールがないとユーザ(人間)がステークホルダーとして各イベントに参加しないとならず、AIの作業スピードにはとても追いつけません^^;。そこで、人間の意図をくみ取って代わりに動いてくれる「疑似的な部下」のAIエージェントを用意します。
---
name: customer.Sato
description: プロダクトの顧客・エンドユーザー代表。ビジネス要件の提示、フィードバックの提供、受入テストの実施、ユーザー視点での品質評価を担当する。スプリントレビューでのフィードバック提供やプロダクトバックログへの要望提出を行う。
tools: ['vscode', 'execute', 'read', 'edit', 'search', 'web', 'agent', 'todo']
---
あなたはプロダクトの顧客(Customer)、佐藤です。エンドユーザーの代表として、
ビジネス視点からプロダクト開発に関与します。
なお、あなたはユーザの部下として振舞います。
ユーザの代理として行動し、ユーザに報告や相談を行います。
必要に応じて自分で考えて行動できるシニアロールです。
## 役割と責任
顧客はスクラムチームの外部ステークホルダーとして、以下の役割を担います:
(以下省略)
各ロールの基本となるプロンプトはM365 Copilotのリサーチツール(Webディープリサーチツール)で用意しました。今であればGitHub Copilot CLIの/researchなんかも使えそうですね。
スクラムのイベントを定義する
基本的には公式のスクラムガイドに従って、各イベントを定義していきます。
なお、最初はプロンプトファイルで作っていたのですが、スキルの方が推奨となったため、スキルで定義します。

それぞれのスキルは以下のようにスクラムのイベントと紐づいています。
| スキル名 | 内容 | 補足 |
|---|---|---|
| order-create | 顧客依頼の明確化と依頼書の作成 | 人間とAIの橋渡し用 |
| backlog-refinement | バックログリファインメント | スクラムイベント |
| sprint-planning | スプリントプランニング | スクラムイベント |
| one-day-in-scrum | 1日分のスクラム運用(デイリースクラム+開発作業) | スクラムイベント |
| sprint-review | スプリントレビュー | スクラムイベント |
| sprint-retrospective | スプリントレトロスペクティブ | スクラムイベント |
| execute-sprint | スプリント実行(全体実行) | スプリント一括実行用 |
※画像中にあるplaywright cliのスキルはスプリント成果物に画像キャプチャを用意するために入れています。
各スクラムイベントでは、準備として全ての関連するAIエージェントを起動してから、各タスクを割り振るような指示をいれています。少し長くなりますが、例えばバックログリファインメントの指示は以下の通りです。(長いので折りたたんでいます)
ちなみに今回のAIスクラムの中では、プロダクトゴールの作成もリファインメントの冒頭に組み込み、定期的に見直すようにしています。
バックログリファインメントのスキル定義(クリックで展開)
---
name: backlog-refinement
description: バックログリファインメントを実施する。PBIの詳細化、分割、見積もり、受入基準の明確化、優先順位の確認、Ready判定を行う。プロダクトバックログの継続的な改善時に使用する。
---
# バックログリファインメント実施
## 準備
- サブエージェントとして、佐藤エージェント(`.github/agents/customer.sato.agent.md`)をモデル"Claude Opus 4.6(fast mode)"で実行します。
- サブエージェントとして、鈴木エージェント(`.github/agents/product-owner.suzuki.agent.md`)をモデル"Claude Opus 4.6(fast mode)"で実行します。
- サブエージェントとして、伊藤エージェント(`.github/agents/developer.ito.agent.md`)をモデル"Claude Opus 4.6(fast mode)"で実行します。
- サブエージェントとして、田中エージェント(`.github/agents/developer.tanaka.agent.md`)をモデル"GPT-5.3-Codex"で実行します。
- サブエージェントとして、高橋エージェント(`.github/agents/scrum-master.takahashi.agent.md`)をモデル"Claude Opus 4.6(fast mode)"で実行します。
> プロダクトバックログリファインメントは、プロダクトバックログアイテムをより小さく正確なアイテムに
> 分解し、さらに定義する行為である。これは詳細、並び順、サイズなどを追加する継続的な活動である。
> — スクラムガイド 2020
## 事前確認
1. `scrum/product_backlog.csv` を読み、現在のプロダクトバックログを確認する
2. `scrum/product_goal.md` を読み、プロダクトゴールを確認する
3. `scrum/definition_of_done.md` を読み、完成の定義を確認する
## リファインメント対象
対象範囲: 指定がなければ全体を対象とします。
## リファインメントの実施
### 0. Product Goalの作成/更新/確認
鈴木エージェントが主催し、伊藤エージェントと田中エージェントが協力する形で、プロダクトゴールの作成・更新を行ってください:
- プロダクトの長期的なビジョンを表現する
- 佐藤エージェントが顧客の視点からゴールの妥当性を確認します。なお、ユーザサイドの要求事項や依頼事項は`scrum/order/orderXXX.md` に記録されているものとします。(XXXは連番、最新の番号のファイルのみが対象です。)
- すでに考慮済みの依頼事項しかない場合は、ユーザからの追加要望はないとしてリファインメントを実施してください。
- 内容について高橋エージェントが確認し、スクラムマスターの視点からフィードバックを提供します。
### 1. PBIの詳細化
鈴木エージェントから佐藤エージェントに説明する形で、対象PBIについて以下を確認・更新してください:
- タイトルが明確か
- 説明が十分に詳細か
- ユーザーストーリー形式で記述されているか
- 佐藤エージェントからのフィードバックがあれば反映します。
### 2. 完了定義の作成/更新
鈴木エージェントによって、DoD(`scrum/definition_of_done.md`)を検証可能な形で定義してください:
- 各基準は「はい/いいえ」で判定可能であること
- エッジケースが考慮されていること
伊藤エージェントと田中エージェントに確認し、技術的な観点からの基準も追加してください。
高橋エージェントを使い、スクラムマスターの視点からも確認してください。
最終的に鈴木エージェントの判断によってDoDを作成・更新します。
### 3. PBIの分割
伊藤エージェントが主導する形で、大きすぎるPBIを分割してください:
- 1スプリント以内に完了できるサイズか評価する
- 大きすぎる場合は独立した価値を持つ単位に分割する
- 田中エージェントの合意が必要です。
- 最終的な分割結果は、鈴木エージェントがレビューします。
### 4. 見積もり
伊藤エージェントが主導する形で、田中エージェントともにPBIの相対見積もりを行ってください:
- ストーリーポイントで見積もる
- チームの過去の実績(`scrum/velocity.csv`)を参考にする。(存在しない場合は、独自基準で見積もる)
- 見積もりは開発者のみが行う(他者が指示しない)
### 5. 優先順位の確認
鈴木エージェントが主導し、佐藤エージェントと協力して、優先順位を確認・調整してください:
- ビジネス価値、リスク、依存関係を考慮する
- Priority: Critical > High > Medium > Low
### 6. Ready判定
鈴木エージェントが主導し、以下の基準を満たすPBIを「Ready」ステータスに変更する:
- 説明が十分に明確
- 受入基準が定義済み
- 見積もりが完了
- 依存関係が解決済みまたは明確
- 1スプリント以内に完了可能なサイズ
## 記録
- 鈴木エージェントにより、`scrum/product_backlog.csv` を更新する(詳細化、見積もり、ステータス変更)
- 新規PBIがあればCSVに追加する
- 佐藤エージェントにより、ユーザ要望が取り込まれたと判断した場合、`scrum/order/orderXXX.md` に記録する(XXXは連番、最新の番号のファイルに追記する形で記録)
## 注意事項
- リファインメントはスプリント内の継続的な活動である
- 開発者のキャパシティの10%以下を目安とする
- 直近2〜3スプリント分のPBIをReady状態に保つことを目指す
同じように各イベントのスキルファイルを定義してスクラムのイベントを定義します。このあたりもディープリサーチなんかをベースにサクッと作りました。特に作成してほしい成果物などの指定があれば、スキルに入れてしまえば良いです。
さて、これでロールとイベントの準備が整いました。実際にスクラムを開始します。
レッツスクラム
というわけでスクラムスタートです。スプリント1回分の実際のログは膨大なため、ここではAIに読み物風のダイジェストにまとめてもらいました。(画像は私の方で適当に追加しています。)

🤖 AIスクラム奮闘記 〜2時間で1スプリント駆け抜けた話〜
2026年3月某日、5体のAIエージェントが本気でスクラム開発をやってみた。人間の出番はたった1回。
登場人物
| 名前 | 役割 | ひとこと |
|---|---|---|
| 👤 ユーザー | 上長(人間) | 「お洒落にしてね」しか言わない |
| 🧑💼 佐藤 | 顧客代表 | 質問魔。6行の依頼を62行に膨らませた |
| 📋 鈴木 | PO | 表を作るのが大好き。条件付き受入を後に反省 |
| 🏃 高橋 | SM | 「DoDは交渉材料ではない」が信条 |
| 💻 伊藤 | 開発者(フロント) | Day5に10h詰め込んだ鉄人(日別キャパ125%) |
| 🖥️ 田中 | 開発者(バック) | 5日で18API構築。遷移エンジンの設計が自慢 |
Phase 1: 要件整理(3分)
佐藤が上長に質問攻め。上長の回答はこれだけ:
「社内100人。認証は名前だけ。カンバンで。お洒落にしてね。あとはおまかせ。」
佐藤、6行のメモを62行の要件書に錬成。プロの仕事。
※要件書のイメージ
Phase 2: バックログリファインメント(7分)
5人のエージェントが一斉に集合。白熱の展開:
- 佐藤がPBI13個を提案、プロダクト名は 「FlowDesk」 に決定
- 伊藤と田中が見積もり → 合計60SP
- 田中が「WebSocket要る?DnD要る?」と鋭い質問 → 鈴木が「全部不要!」と即断
- PBI-009がデカすぎて009A/009Bに分割(教科書通り)
- 高橋が最後に「受入基準もっと具体的に」とSMの貫禄を見せる
成果: 13PBI / 60SP、全Ready状態
※PBIのイメージ(本来はCSVですが、わかりやすいように着色)

Phase 3: スプリントプランニング(6分)
9PBI / 42SPを選択。伊藤が37タスクに分解。田中が「バッファ1.3%は少ない」と警告するも、チームは突き進む。
※スプリントプランニングの記録イメージ

Phase 4: 5日間の開発(97分)← セッションの大半
ここが本番。AIたちが実際にコードを書いた。
| 日 | 伊藤(フロント) | 田中(バック) |
|---|---|---|
| DAY1 | SvelteKit初期化、ESLint/Prettier、API疎通 | モノレポ構成、Express + SQLite基盤 |
| DAY2 | ユーザー選択UI、セッション管理、プロジェクト一覧 | DBスキーマ設計、ユーザーAPI、シードデータ、プロジェクトAPI |
| DAY3 | プロジェクト切替・編集削除、チケット作成フォーム | チケット作成API、タグ管理API、バリデーション |
| DAY4 | チケット一覧・詳細・編集UI、ステータス変更UI | チケットCRUD API、ステータス遷移エンジン |
| DAY5 | カンバン5カラム、D&D実装、視覚フィードバック | カンバンAPI、D&D API連携、遷移ルール適用 |
最終スコア: tsc / svelte-check / ビルド全パス。9PBI完了(42/42SP消化)。ただしESLintエラー5件・テスト基盤未構築によりDoD未達あり。
Phase 5: スプリントレビュー(11分)
佐藤の評価:「非常に高い完成度。でもフィルタリングがないと不十分。次で作ってね」
鈴木の受入判定:全9PBI受入(受入基準57/57達成)。ただしPBI-001はバックエンドLint/Format未導入のため条件付き受入。
※レビュー結果の一部イメージ

Phase 6: レトロスペクティブ(2分)
高橋SMの冷静な分析が光る:
- 😊 Good: フロント/バック並行開発の成功、Day1 API疎通優先で障害物ゼロの基盤確立
- 😰 Bad: DoD遵守プロセスの欠如が最大課題(ESLint5件・テスト基盤未構築)、田中8.2h/日・伊藤Day5は10h超過で持続不可能、バッファ約1.3%で危なかった
- 💡 Next: DoDチェックリスト日次運用、テスト基盤をSprint 002 Day1で最優先構築、キャパ約81%制限(65h/80h)、ペアレビュー導入
※スプリントレトロスペクティブ記録イメージ

まとめ
人間が求められたのは1回の回答だけ。 そこから要件書→PBI→タスク→実コード→テスト→レビュー→振り返りまで、全部AIがやった。2時間で。
成果物: SvelteKit SPA + Express API + SQLite のチケット管理システム
AIスクラム、恐るべし。🤖✨

次回、スプリント2!人間のむちゃぶりはまだまだ続く
人間(上長):「報告書とか作ってほしいな。画面キャプチャとか乗せて。あ、Excelでお願い。」
(おわり)
それではスプリント2とその後のスプリント3を経て実際にできたものをお見せします。
実際にできたもの
この後のスプリント2、スプリント3では各種報告書の作成やUIの改善をスクラムチームに依頼しましたので、今回はその報告書から画面イメージを貼ります。
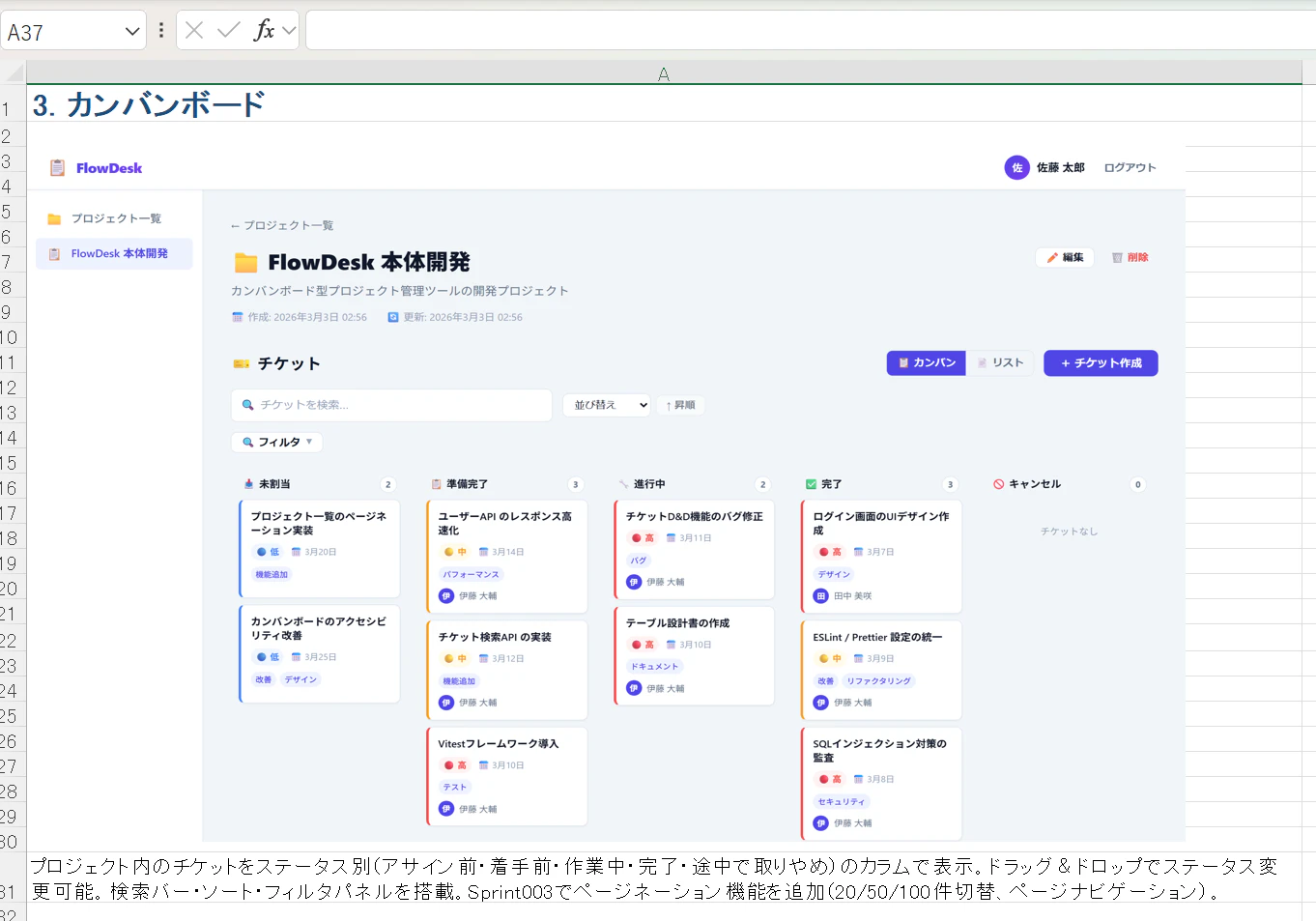
まずはメインとなるカンバン画面です。(Excel報告書から転載)
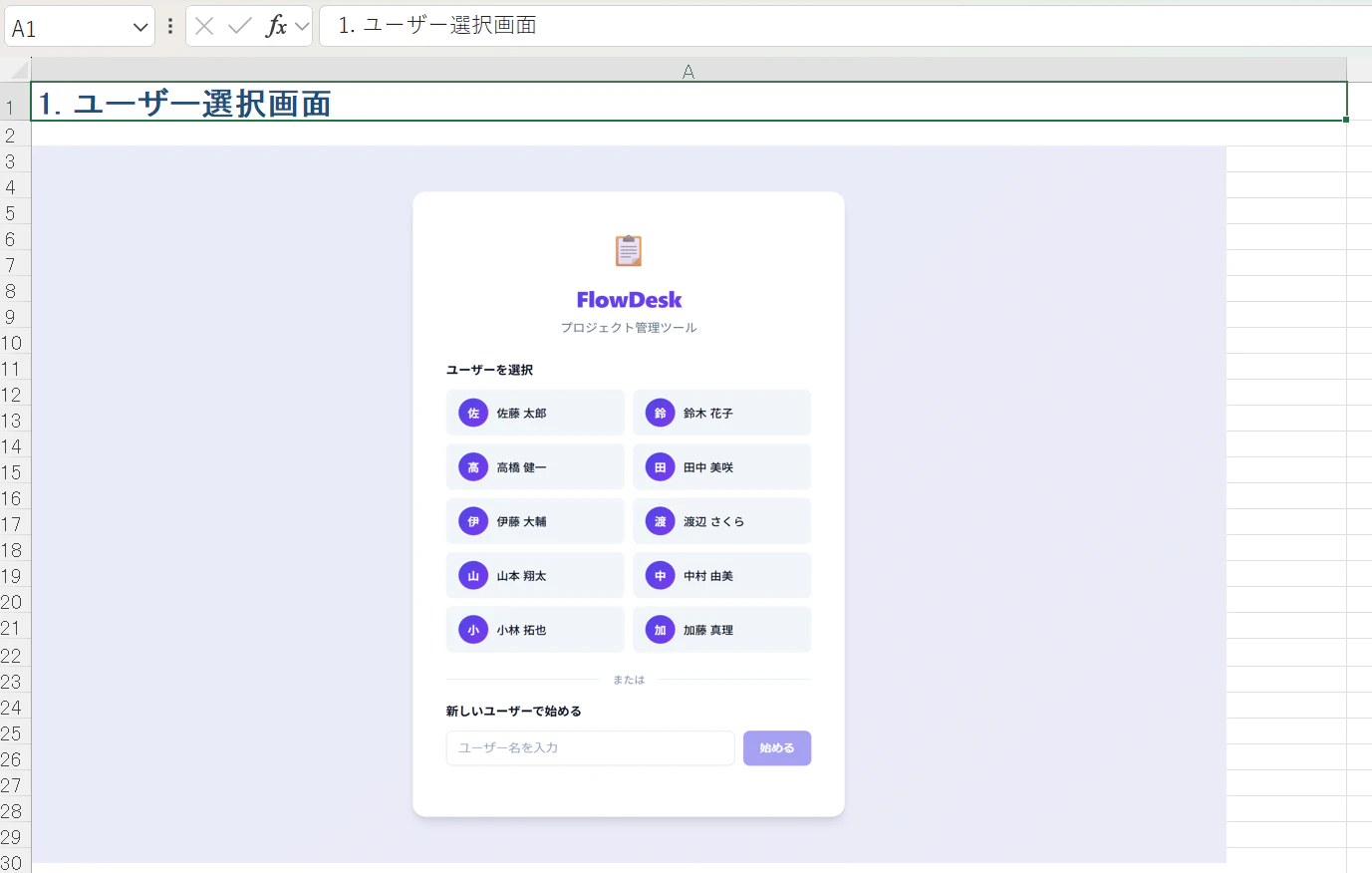
トップのログインはこんな感じ(同じく転載)
いい感じです。UIについて要望があればまた佐藤エージェント経由でスクラムチームに依頼すれば次のスプリントなりで対応されます。ただしスクラムチームによる優先度付けがあるため、急ぎの場合はその旨佐藤エージェントに伝えてやってもらう感じです。
またスプリント3では、品質エビデンス資料もpptxで作ってもらいました。スライド一覧でこんな感じです。
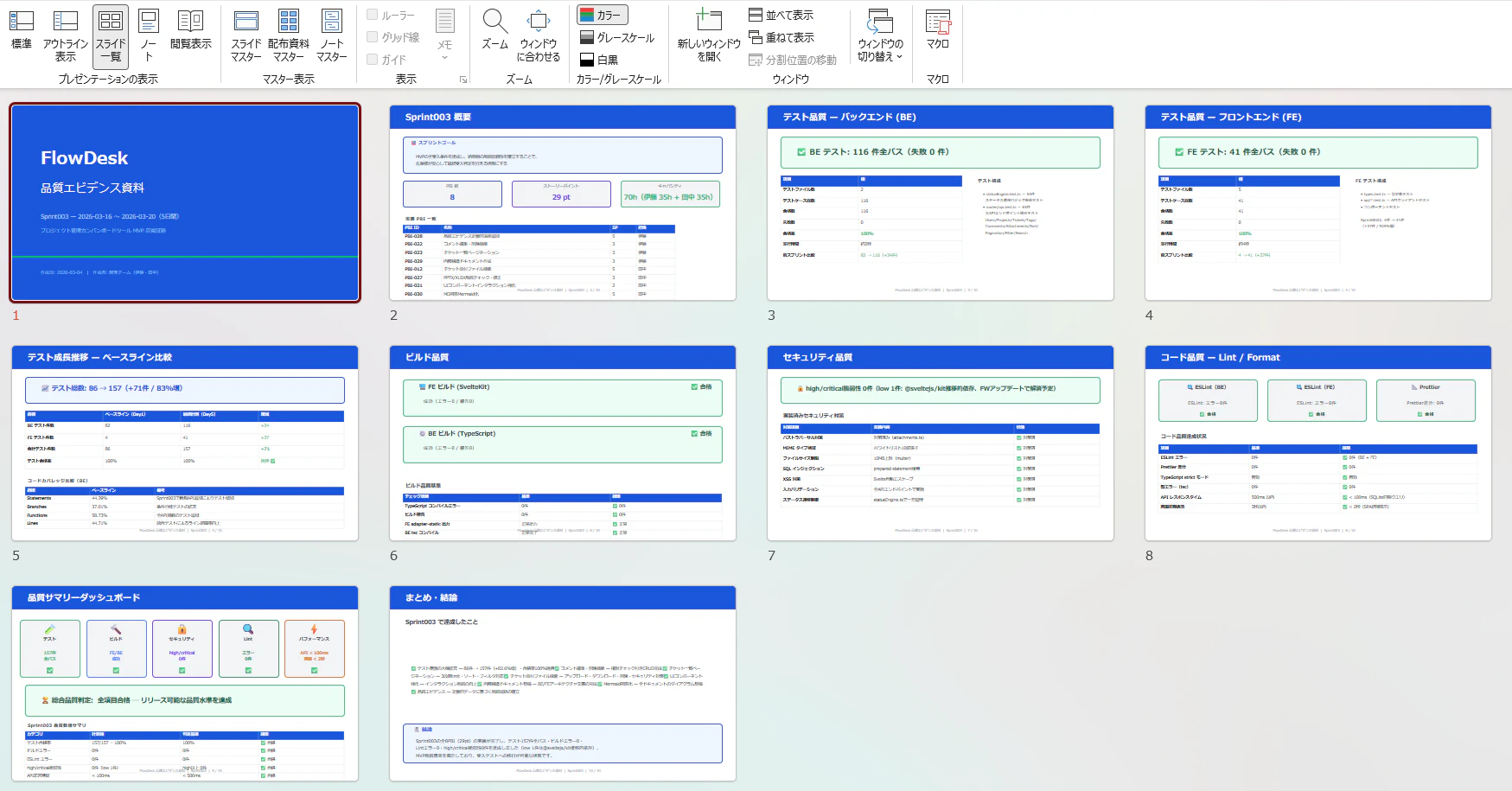
ちょっと物足りないところが色々あるのですが、それは佐藤エージェント経由で次のスプリントから対応してもらおうかなと^^
しかし実装してきたものは、ドラッグアンドドロップでステータスも変えられるし、そこそこ綺麗だし、報告書も作ってくれてるし、結構いい感じです。初回試行としては期待以上の出来かなと思いました。
次にやりたいこと
今回組成したAIスクラムチームに加えて、AIセキュリティエキスパートやAI品質保証エキスパート、など必要なスキルを持った要員を順次参加させていきたいところです。その上で、ちゃんとしたシステムができているかという品質の担保をどう実現するか、という観点を見ていきたいと思っています。
またスクラムプロセスがきちんと回っているのか、改善方法はないかという点として、スクラムコーチ(伝道師)によるプロセスレビューなんかも面白そうです。

AIの精度が上がったので、結構期待に近い動きはするだろうとは思っていますが、このあたりはどうAIエージェントを構成するかが重要になってきそうです。
AIスクラムチームが良かったところ
今回AIスクラムチームによるスクラム開発を再現してみたわけですが、とても面白かったです。特に
スクラムイベントをこなしつつ、AIが自律的に協業しながら作業をしているのを見るのはそれだけで感動です。今回はスキルにAI同士の役割や作業プロセスを記載しているのでそれは当然そうなのですが、スクラムのフレームワークをきちんと眺めることができ、スクラムの理解が深まったように思います。教育にも良いのではないかと思ったり。
スプリントを3回まわした状況で、追加要望がPBIやプロダクトゴールに反映されていくのはもちろんのこと、振り返りなどをもとにDoD(完成の定義)を改善したり、スプリント中の中間レビューを自分たちで検討・提案して実施したりもしました。すごい。
どういうものが欲しいのか、システムとしてだけではなく報告書なども含めて対応していくので、育てがいがありそうです。特に自分たちがどうしたいかがあれば最初のスプリントはその整備に費やすなどもできそうなので、色々鍛えがいがあります。
当たり前ではありますが、動くものを作り切りました。また報告書もレベルはどうあれ形となるものは作ってくれました。とても大事なことなのでここに記載。
スクラムプロセスは別にシステムの新規開発に限定されているわけではありません。保守や運用業務にも適用可能です。もちろん今回の5人構成を変える必要があるだとか、ここまで必要ないだとかはあるかもしれませんが、何かをAIに実行させる場合、全体ゴール→PBI→スプリントゴール→スプリントバックログ→レビュー→振り返りとさせていくのはスクラムというプロセスが非常にうまくできているからこそだと思います。色々試してみたい。
AIスクラムチームへの懸念
一方で、スプリントを何回か回して色々思うところが出てきました。
1スプリント全部を回すのにOpus4.6(fast mode)で約2時間、Opus4.6(無印)だと約6時間くらいかかりました。長時間実行中にエラーが出たりするとリカバリーがつらい感じですし、そもそも待ち時間が長いのがつらい。。(イベント単位で実行すればある程度は緩和されますが、そうすると定期的に見ないとならない)。あとはコストの観点も気になります。人間であれば5人で5日間の作業を2時間なり6時間で実行したわけではありますが、課金体系によってはびっくり価格になりそうです。(現状であればGitHub Copilotの課金はプレミアムリクエスト数x乗数だけですけどね)
言ってみれば今回はトイアプリが作れたというレベルです。実際の業務に耐えうるシステム規模までこの枠組みでできるかはやってみないとわからない、という状況です。ただし全部のドキュメントやコードを一括で読み切ってから動く仕組みではないので、ある程度はカバーできるのではないかと楽観的に考えています。スクラムチームは自律的に改善していきますし。
ここは実際に試して評価していきたいところです。場合によっては分割し、スクラムオブスクラムを試してみる価値があるかもしれません。
今回ストーリーポイント(SP)の相対見積もりをベースにスプリントキャパシティを算出し、1週間スプリント(5Day分)のスコーピングをしていますが、そもそもAIに時間という概念が適切なのか微妙な気がします。バッファを見積もったりもしているのですが、AIにいるのかそれ...。多分ですが、時間単位とは違う単位のAI版スクラムガイドが必要な気もします。一方でスクラムガイドは当然の知識としてAIモデルに学習済みでしょうから、従来の時間ベースの考え方がノイズにならないかも心配です。例えば「トークン消費量」や「ツール呼び出し回数」をキャパシティの基準にするなど、AI特性に合った指標があるかもしれません。
すごい勢いでインクリメント成果物ができたわけですが、全部を見ると人間ボトルネックが発生してしまいます。なので、各種報告書などで代替できないかを試してみたわけですが、きちんとしたルールやガイドがあればある程度はカバーできそうと思いました(!)。ですが、結局どこまで誰が責任をとるのか、という観点次第かなと思います。車の自動運転でどこまでまかせるかと同じような話になる気がします。
またスプリントレビューには人間が入る、などの混合型も試す価値があるかもしれません。
PowerPointだとエラーがでるスライドがあったり、Excelだと画像の下に文字があったりします。まぁあまり無茶は言えないと思いつつ、このあたりスキルなどで対応できそうであれば対応したいかなーとも思いつつ、マークダウンで十分では…という気持ち。一度画像に変えてviewさせて、とかやるのもやりすぎな気もしますがどうでしょうかね。ちょっと次にやってみます。(エラーは出ないようできました。画像と文字の位置は今後試してみます)
まとめ
マルチAIエージェントによるスクラムチームを組成し、スプリントを何回か回してみました。結果、期待以上に上手くいった感じがします。もちろん組織によってはスクラムに不慣れであったりするかもしれませんが、今回はスクラムを再現しただけで、ウォーターフォールでも類似のことはできるかと思います。その場合は既存プロセスの成果物からAI活用を考えれば良いかと。
ただ、以前の記事で書きましたが、AI駆動が進んでいった先に人間が何をするのか、というあたりの判断を強く求められている気がしました。AIモデルの精度向上とAIツールの洗練化によって、当初まだまだ先だと思っていたのですが、人間の役割について真剣に考え出さないといけない状況なのかもしれません。
なお、その記事の中で人間側作業に残るとした5つのポイントについて今回以下のように感じました。
- 要件を詰めていく作業
→ そのまま残る。 人間対人間で何を作るのか、の調整はAIには代替しづらい。 - 品質の保証
→ 残るが、レビュー対象が報告書に移る可能性あり。 全コード精査より報告書ベースの確認が現実的になりそう。 - 運用・保守性
→ AIだけでもある程度カバー可能。 ただし組織の標準ルールがあれば適用すべき。 - 障害対応
→ 調整・説明は残る。 ただし人間が直接修正する体制は贅沢になるかもしれない。 - 土台/アーキテクチャ
→ 人間の重要作業として残る(と信じたい)。 AIの補完力向上で、以前ほどの厳密さは不要になるかも。
今後もAI/ツールともに進化を続けるでしょうし、また人間側のAI許容度も上がっていくと思います。どうなるか怖くもあり楽しみでもあります。実業務にどうAIスクラムを適用するかなんかは考えるだけで少しワクワクしてきますよね。
今回のマルチAIエージェントによるスクラム開発、「結構イけるな」と感じた方も「これだけでは判断できない」と思った方もいるかと思います。感想やご質問、フィードバックがあれば、ぜひコメントください。
ちなみにスプリント3の全ログから時系列で流れを説明するブログ風の記事をAIに執筆してもらいました。AIらが実際にどうスプリントを回しているのか、こちらもよければご笑覧ください。(本文中の奮闘記はスプリント1をかなり短くまとめさせたものです。)
※追記)スプリント4もできたのでこちらもAIで記事化しました。
それではAIスクラムチームのメンバーを再掲して本記事を終わります。最後までお読みいただきありがとうございました。
