day3
Section1-再帰型ニューラルネットワークの概念
Section2-LSTM
Section3-GRU
Section4-双方向RNN
Section5-Seq2Seq
Section6-Word2Vec
Section7-AttentionMechanism
day4
Section1-強化学習
Section2-AlphaGo
Section3-軽量化高速化技術
Section4-応用モデル
Section5-Transformer
Section6-物体検出
Section7-GAN
1 Section1-再帰型ニューラルネットワークの概念
順伝播
RNNとは時系列データを扱うモデル。
時間的順序を追って記録されているデータ(音声データやテキストデータ)
入力層→中間層→出力層
基本的には今までと同じだが、
しかし、 ニューラルネットの出力を別のニューラルネットの入力として利用するような再帰的構造を持っている。
以下の図で、z1で学習した中間層の情報をz2に渡す。z2の情報はz3に、、、と繰り返して行く。

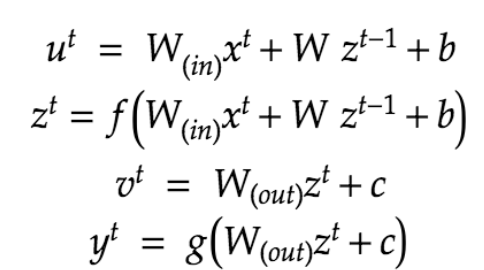
fは入力層~中間層への活性化関数
gは中間層~出力層への活性化関数
u[:,t+1] = np.dot(X, W_in) + np.dot(z[:,t].reshape(1, -1), W)
z[:,t+1] = functions.sigmoid(u[:,t+1])
y[:,t] = functions.sigmoid(np.dot(z[:,t+1].reshape(1, -1), W_out))
(確認テスト)
RNNのネットワークには大きくわけて3つの重みがある。1つは入力から現在の中間層を定義する際にかけられる重み、1つは中間層から出力を定義する際にかけられる重みである。残り1つの重みについて説明せよ。
(回答)
中間層から次の中間層に至るところの重み
RNNの特徴
ひとつ前の時間t-1の状態を保持してそこから次の時間tを再帰的に計算する。
(確認テスト)
RNNのleftとrightの特徴量を算出する際の処理は?
(回答)
np.concatenateで[4, 5]と[1, 2]を合体して
[4, 5, 1, 2]とする。
サイズ2が4になってしまうが、調整して2にする。
逆伝播 (BPTT)
Back Propagation Through Timeの略
名前のとおり時間軸を逆にたどっていくような誤差逆伝播の方法である。
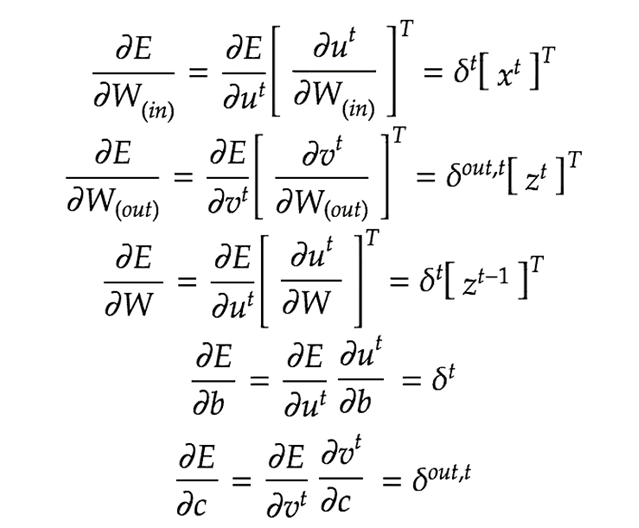
$$
W_{in}^{t+1}=W_{in}^t−ϵ\frac{∂E}{∂W_{in}}=W_{in}^t−ϵ\sum_{z=0}^{T_t}δ^{t−z}[x^{t−z}]^T
$$
$$
W_{out}^{t+1}=W_{out}^t−ϵ\frac{∂E}{∂W_{out}}=W_{out}^t−ϵ\sum_{z=0}^{T_t}δ^{out,t}[x^{t}]^T
$$
$$
W^{t+1}=W^t−ϵ\frac{∂E}{∂W}=W^t−ϵ\sum_{z=0}^{T_t}δ^{t−z}[x^{t−z-1}]^T
$$
(確認テスト)

問題文のs0 s1は図ではz1 z2
(回答)
$$
s_1 = f(s_0 \cdot W + x \cdot W_{(in)} + b)
$$
$$
y_1 = g(s_1 \cdot W_{(out)} + c )
$$
RNNまとめ
時系列データなどのシーケンシャルなデータのパターンを学習するように設計されたニューラルネットワークモデル。
順序を考慮して処理を行い、過去の情報を蓄積していくようにできている。
BPTTにより時系列のバックプロパゲーションを行う。
しかし、時系列の入力が長いと、勾配消失問題が起きる。
2 Section2-LSTM
RNNの問題点
長い時系列の学習が困難。
時系列を遡るとその分勾配が消失してゆく。
前回のDNNでは勾配消失対策としてバッチ正規化などで対処していたが、
RNNの勾配消失の解決策は、構造自体を変えたLSTMによるもの。
復習)
勾配消失が起きやすい活性化関数の代表格はsigmoid
大きな値に対して出力の値が微量(0~1なので)
sigmoidの微分にsigmoidが入っているので、BPを繰り返すと値が小さくなる。
(確認テスト)
シグモイド関数を微分した時、入力値が0の時に最大値をとる。その値として正しいものを選択肢から選べ。
(1)0.15(2)0.25(3)0.35(4)0.45
(回答)
前回講義の山型になっているグラフを思い出す。
真ん中が凸になっていて、最大値が0.25だった。
復習)
学習率の値を、オプティマイザーの推奨値から外したものにすると、勾配爆発は簡単に発生する。
(演習チャレンジ)
RNNや深いモデルでは勾配の消失または爆発が起こる傾向がある。勾配爆発を防ぐために勾配のクリッピングを行うという手法がある。具体的には勾配のノルムがしきい値を超えたら、勾配のノルムをしきい値に正規化するというものである。以下は勾配のクリッピングを行う関数である。(さ)にあてはまるのはどれか。

(1)gradient * rate
(2)gradient / norm
(3)gradient / threshold
(4)np.maximum(gradient, threshold)
(回答)
(1) しきい値に正規化とあるので、しきい値をノルムで割ったものを掛ける。
LSTM全体像

CECが重要
Constant Error Carousel
これを中心にして構築されたネットワークと考えてよい。
以前の情報を記憶することに特化したものがCEC
勾配消失の問題は、勾配が1なら解決できる(?)
CECには覚えるだけで、学習する能力はない。単に覚えるだけ。
そこで、CECの周りに学習機能をもった"取り巻き"を配置する、という発想。
CECが覚えているものをどう使うか、ということを考える。
"取り巻き"として、入力ゲートと出力ゲートがある。
入力ゲート
CECに「どのような記憶のさせ方をするか」を伝える。
前のユニットの入力をどの程度の割合で受け取るかを調整する
出力ゲート
CECに「どのような記憶の取り出し方をするか」を伝える。
前のユニットの出力をどの程度受け取るかを調整する。
それぞれのゲートへの入力値の重みを重み行列W、Uで可変可能とする
忘却ゲート
Forget Gate。
インプットが大きな変化をした場合に、メモリセルで記憶した内容を忘れることを学習する。
(確認テスト)
以下の文章にLSTMに入力し空欄に当てはまる単語を予測したいとする。文中の「とても」という言葉は空欄の予測において無くなっても影響を及ぼさないと考えられるか。このような場合、どのゲートが作用すると考えられるか。
「映画面白かったね。ところで、とてもお腹が空いたから何か____。」
(解答)
忘却ゲート
(演習チャレンジ)

(解答)
正解:3【解説】新しいセルの状態は、計算されたセルへの入力と1ステップ前のセルの状態に入力ゲート、忘却ゲートを掛けて足し合わせたものと表現される。つまり、input_gate* a + forget_gate* cである。
覗き穴結合
CEC自身の値に、重み行列を介して伝播可能にした構造
(判断材料がひとつ増えることになるがそれほど効果は高くないとのこと)

LSTMまとめ
LSTMは記憶を保存するような機構を持つことで、RNNの勾配消失問題を解決している。
古いアウトプットを次の段階でインプットとして使用する、というRNNの構造を保ちつつ、CECという記憶装置を保持し、長期記憶を変化させていくという性質を持つ。
3 Section3-GRU
LSTMの課題
計算量が多く、時間がかかる
パラメータが多すぎて計算負荷が大きかった。
GRU
GRUではパラメータを大幅に減らしつつ、精度が低くならないように工夫がされている。
GRUの全体像

LSTMとの相違点
CEC、入力ゲート、出力ゲートがなくなった
全体的にシンプル
リセットゲートと更新ゲートがある。
リセットゲート
$$
z_t = \sigma(W^{(z)}x_t + U^{(z)}h_{t-1})
$$
更新ゲート
$$
r_t = \sigma(W^{(r)}x_t + U^{(r)}h_{t-1})
$$
状態の更新
$$
\tilde h_t = tanh(Wx_t+r_t \circ Uh_{t-1}), \quad h_t = z_t \circ h_{t-1}) + (1-z_t) \circ \tilde h_t
$$
リセットゲート0の場合
前の状態を無視する
更新ゲート1の場合
前の状態をコピー
(確認テスト)
LSTMとCECの課題は?
(解答)
LSTMには4つの部品があり、パラメータ数が多くなり、計算量が多い
CECは勾配が1で学習能力がない。
(演習チャレンジ)

(解答)
正解:4
【解説】新しい中間状態は、1ステップ前の中間表現と計算された中間表現の線形和で表現される。つまり更新ゲートzを用いて、(1-z) * h + z * h_barと書ける。
(確認テスト)
LSTMとGRUの違いを簡潔に述べよ
(解答)
GRUにはCECがない。
LSTMはパラメータが多い、GRUはパラメータが少ない。
よってGRUの方が計算量が少ない。
GRUまとめ
LSTMの複雑な構造を少しシンプルにして分かりやすくなったモデル。
入力ゲートと忘却ゲートを「更新ゲート」として1つのゲートに統合することで若干シンプルになっている。
LSTMと同様に、離れたステップの特徴の記憶を維持しやすくなります。
(各時間ステップ間を迂回するショートカットパスが効率的に生成されると言えるらしい)
このため、バックプロップが効率化でき、勾配消失の問題を軽減できるとのこと。
4 Section4-双方向RNN
過去の情報だけでなく、未来の情報も加味して精度を上げる。
未来の情報を使えるようなタスクの例
- 文章の推敲
- 機械翻訳
(演習チャレンジ)

(解答)
正解:4【解説】双方向RNNでは、順方向と逆方向に伝播したときの中間層表現をあわせたものが特徴量となるので、np.concatenate([h_f, h_b[::-1]], axis=1)である。
axis=0は
[1, 1, 1] , [2, 2, 2] → [1, 1, 1, 2, 2, 2]
axis=1は
[1, 1, 1]
[2, 2, 2]
↓
[[1, 1, 1],
[2, 2, 2]]
双方向RNNまとめ
順方向の学習と、逆方向の学習を同時に行うというもの。
これにともない、逆方向の隠れ状態も追加される。双方向のコンテキストを集約した出力の予測が可能となる。
5 Section5-Seq2Seq
2つのネットワークを使用する。
Encoder-Decoderモデルの一種
機械翻訳や機械対話に使用される。
前半でインプットを解読(集約)して保持された文脈情報を用いて、後半で別の表現を構築する。
seq2seq全体像

Encoder RNN


単語のベクトル化

ワンホットベクトルはあまりにも無駄が多いので、数百程度のサイズのベクトル表現に変換する。
実際の処理
・vec1をRNNに入力し、hidden stateを出力。
・このhiddenstateと次の入力vec2をまたRNNに入力してきたhidden stateを出力という流れを繰り返す。
・最後のvecを入れたときのhiddenstateをfinalstateとしてとっておく。(これが「文脈」をあらわす)
・このfinalstateがthoughtvectorと呼ばれ、入力した文の意味を表すベクトル。
MLM Masked Language Model は大量の教師なし学習で文脈を考慮した単語を学習できる。
Decoder RNN


- Decoder RNN: Encoder RNN のfinal state (thought vector) から、各token の生成確率を出力していきます
final state をDecoder RNN のinitial state ととして設定し、Embedding を入力。 - Sampling:生成確率にもとづいてtoken をランダムに選びます。
- Embedding:2で選ばれたtoken をEmbedding してDecoder RNN への次の入力とします。
- Detokenize:1 -3 を繰り返し、2で得られたtoken を文字列に直します。
(確認テスト)
下記の選択肢から、seq2seqについて説明しているものを選べ。
(1)時刻に関して順方向と逆方向のRNNを構成し、それら2つの中間層表現を特徴量として利用するものである。
(2)RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
(3)構文木などの木構造に対して、隣接単語から表現ベクトル(フレーズ)を作るという演算を再帰的に行い(重みは共通)、文全体の表現ベクトルを得るニューラルネットワークである。
(4)RNNの一種であり、単純なRNNにおいて問題となる勾配消失問題をCECとゲートの概念を導入することで解決したものである。
正解は、(2)
(1) 双方向RNN
(3) 構文木
(4) LSTM
(演習チャレンジ)

Eというのが対応表。
対応表に単語をドット積をかけると単語のベクトルが取り出せる。
(詳細な説明なし)
Seq2Seqの課題
一問一答しかできない。問に対して文脈がなく、単純に応答するだけ。
HRED
過去の発話を考慮して、文脈のある会話ができる。
HREDの課題
バリエーションが少ない
よくある短い答えしか返さない
「そうだね」、とか、「うん」、とか
VHRED
文脈の考慮+バリエーションを持たせる工夫
(HREDにVAEの潜在変数の概念を持たせた)
オートエンコーダ
教師なし学習のひとつ
入力と同じものを出力
エンコーダからデコーダに行く間にzという潜在変数を作る

縮小(次元削減)する処理と復元する処理をいい感じにできるような小さな潜在変数を作りだす
VAE
オートエンコーダをさらに工夫したもの
VAE (Variational Auto Encoder) =変分オートエンコーダー
通常のオートエンコーダーの場合、何かしら潜在変数zにデータを押し込めているものの、その構造がどのような状態かわからない
↓
VAEはこの潜在変数zに確率分布z∼N(0,1)を仮定したもの
データを潜在変数zの確率分布という構造に押し込めることを可能にする
VAEにおけるノイズ
エンコーダーから出力時に、ノイズを加える。(Dropoutのようなもの)
ノイズが入っているものを頑張って処理する。
→ これにより、汎用性を得ることができる
(確認テスト)
VAEに関する下記の説明文中の空欄に当てはまる言葉を答えよ。自己符号化器の潜在変数に____を導入したもの。
(解答)
確率分布
Seq2Seqまとめ
2つのネットワーク(入力のネットワークと出力ネットワーク)を用いて前半戦と後半戦でそれぞれ別々の仕事をする。
前半ではインプットを集約して文脈情報を作り、後半で別の表現を構築するモデル。
Attentionを用いたものに発展していく点で重要。
また、オートエンコーダーやVAEの生成系モデルともかかわりが深いと思われる。
6 Section6-Word2Vec
RNNでは可変長の文字列をNNに与えることはできないので、固定長に変換する。
さっき説明した embedding手法のところの、ベクトルによる単語表現


7 Section7-AttentionMechanism
Seq2Seqの問題点
長い文章への対応が難しい。入力の単語数の数にかかわらず固定次元ベクトルの中に入力が必要。
隠れ層の重みのサイズが決まっている。
100個の数字で表すというモデルを作ったとすると、
2単語だろうが10,000単語だろうが、その100個の数字のモデルで処理しなければならない。
10,000を100で処理するのは無理がある。
解決策
入力の文が長くなるにつれてシーケンスの内部表現の次元も大きくなっていく仕組みが必要。
Attention Mechanism
「入力と出力のどの単語が存在しているか」の関連度を学習する仕組み
(確認テスト)
RNN、Word2Vec、Seq2Seq、Attentionの違いを簡潔に述べよ
(解答)
RNN 時系列データを処理するのに適したネットワーク
Word2Vec 単語の分散表現ベクトルを得る手法
Seq2Seq ある時系列データから別の時系列データを得る手法
Attention 時系列データの中身それぞれに重みをつける手法
(確認テスト)
Seq2SeqとHRED、HREDとVHREDの違いを簡潔に述べよ
(解答)
Seq2Seq ある時系列データから別の時系列データを得る手法。
HREDはseq2seqの機構に文脈を考慮したもの。
VHREDは機械対話などで、短くて当たり障りのない対話になりがちなHREDの特徴を改善したもの。
AttentionMechanismまとめ
詳細は後述のTransformerの章で詳しく学ぶことになるが、ここでは概要のみ学習した。
AttentionやTransformerの実装を後日確認する。
実際にpytorchでの実装や、hugging face のtransformersを利用しているが、かなり性能がよいため、Attention機構を用いたアルゴリズムは、個人的に最も注目しているもののひとつ。
8 Section1-強化学習
強化学習とは
長期的に報酬を最大化できるように環境のなかで行動を選択できるエージェントを作ることを目標とする機械学習の一分野
行動の結果として与えられる利益(報酬)をもとに、行動を決定する原理を改善していく仕組み
教師があるないという見方ではなくて、
成長する目的を設定して、行動によってそれを実現するために学んでいく、という機械学習
実生活で例えると、、、、、何かやり方があるものを学校で教わる、というよりは職場でこれやっといて、と言われて自力で試行錯誤して学習するようなスタイルに近い
強化学習のイメージ

強化学習の応用例
マーケティングに例えると、、、、
環境: 会社の販売促進部
エージェント: プロフィールと購入履歴に基づいて、キャンペーンメールを送る顧客を決めるソフトウェアである。
行動: 顧客ごとに送信、非送信のふたつの行動を選ぶことになる。
報酬: キャンペーンのコストという負の報酬とキャンペーンで生み出されると推測される売上という正の報酬を受ける
キャンペーンを打ってみて結果を見て、顧客ごとに送信するかしないかを決めていくようなイメージ(?)
考え方
最初は誰が買ってくれるかわからない。
だからあてずっぽうで動いてみる必要がある。
あてずっぽうで動く程度と、過去の知識から行動する程度がトレードオフ
探索と利用のトレードオフ
最初から完ぺきな知識がないと動けない人は何もできない
過去の知識に基づいた行動しかできない人は、より良い行動を学習できない
「探索」が足りない状態
↑
↓
未知の行動(あてずっぽう)のみを繰り返す人は、過去の経験が活かせない。
「利用」が足りない状態
強化学習の学習の解説

学習するのは2つ
方策と価値
自分が心地良くなるように(報酬が高くなるように)頑張る、良くなるように考えるのが「方策」
どういう状態が一番良い状態なのかを定義するのが「価値」
お金はもらえるけど楽しくない仕事、とか
一時的に売り上げは上がってもあとでコストが高くなるのはだめ、とか、そういった価値を決める。
方策には、
方策関数 TT(s, a)
行動価値関数 Q(s, a)
状態価値関数
教師あり・なしとの違い
結論:目標が違う!
教師あり・なしでは、データに含まれるパターンを見つけたりデータから予測をしたりすることが目標。
強化学習は、優れた方策を見つけることが目標!
いままでホワイトカラー労働者がやっていた経験が必要だった仕事、のようなものができるようになるイメージ
強化学習の歴史
冬の時代があったが、計算速度の進展により大規模な状態をもつ場合の計算が可能となってきている。
関数近似法とQ学習を組み合わせる手法が最近注目を集めている。
関数近似法
- 行動価値関数を、行動する毎に更新することにより学習を進める方法
関数近似法
- 価値関数や方策関数を関数近似する手法のこと
ここまでの確認。
強化学習とは、方策関数と価値関数がよりよい働きをさせるように学習すること。
方策関数
目標設定に基づいて、今、どうするか、を考える。
価値関数
将来の目標設定。
強化学習における「関数」
関数が必要になったらニューラルネットワークでなんとかする。
方策勾配法
方策関数をニューラルネットでいい感じに学習するという発想。
方策勾配法
$$
\theta^{(t+1)} = \theta^t + \epsilon \nabla J(\theta)
$$
ニューラルネットの重みの更新式とほぼ同じ
(NNはマイナスだが、こっちはプラスで書かれている)
方策関数
\pi(s, a | \theta) \\
s 現在の状態
a エージェントがとる行動
重みとして、 θ を取る関数、という意味
ニューラルネット全体が、方策関数πを表している
では、Jというのは何を意味するか
NNのときは、教師データとなるべく同じものを出力するのが目的で、誤差関数をなるべく小さくしていた。
強化学習はなるべく多くの報酬がほしいので、なるべくJを大きくしたい。
なるべく大きくしたいのでプラス記号を使っている。
これで方策関数をニューラルネットにできた。
Jの中身
$$
∇𝐽(𝜃) = E_{𝜋𝜃}[ \ ( \ ∇log \ 𝜋_{𝜃}(𝑎|𝑠) \ 𝑄^{𝜋𝜃}(𝑠,𝑎) \ ) \ ]
$$
↑のこの式変形は難しいと言っている。
元の式
∇𝐽(𝜃) = ∇_{ \theta } \ \sum_{a∈A} \ 𝜋_{\theta}(𝑎|𝑠) \ 𝑄^{𝜋𝜃}(𝑠,𝑎)
式変形は講義では割愛
ここに出てくる ナブラ(逆三角)は微分であると言っている。
強化学習まとめ
今まで個人的にはあまりなじみがなく、詳細を知らなかったが、この章で概要は理解することができたので良かった。
実装を見たらもう少し理解できると思うが、今回の講座ではサンプルのコードがないようなので、時間があれば実装例を探して触ってみたいと思う。
9 Section2-AlphaGo
- Alpha Go Fan 初代モデル GPU176台
- Alpha Go Lee 2代目 TPU48台(Lee Sedol=イ・セドルを倒したモデル)
講義で解説があったモデル(後述) - Alpha Go Master 3代目 TPU4台
- Alpha Go Zero 4代目 TPU4台
これも講義で解説があったモデル(後述) - AlphaZero 5代目 TPU5000台
人間の対局データや定石の知識なしで学習を行うボードゲームAI。
Alpha Go Zero の時点で、自己対局(selfplay)のみでそれまでのモデルを超える性能を実現していたが、
それを調整して囲碁だけでなく、チェス、将棋と3つのドメインに対応した。
2時間で将棋、4時間でチェスの最高峰のAIに勝利し、AlphaGo Zeroも8時間で超えた。
・これまで特殊な手段とされてきた手を多用するなどして、世界の囲碁界に大きな衝撃を与えた。
・事前データおよびドメイン知識なしで囲碁/チェス/将棋において超人的パフォーマンスを達成したことにより
世界に大きなインパクトを与えたが、真に驚くべきはそのアルゴリズムのシンプルさ。 - AlphaStar スタークラフト2で人類の上位0.2%になったやつ
などがある。
講義ではAlpha Go Leeの説明
Policy Net 方策関数のネットワーク

Value Net 価値関数のネットワーク

二次元のデータが入ってきたらコンボリューション(畳み込み)を掛けるのは、現在の深層学習では定石として確立された方法である。
Value Net の場合は最後に確率にするので全結合して一つの値に集約する、というのも定石。
48チャンネルの内訳

Policy Netの強化学習
Policy Poolを利用する。
Plicy Net と Policy Poolから選んだものを対局シミュレーションをさせて方策勾配法を使って学習をおこなう。
※ Policy Pool
Policy Netの強化学習の過程を500 Iterationごとに記録し、保存しておいたもの。
Policy Netがプーリング(貯蔵?)されているような保管庫のようなもの。
対局に幅を持たせて過学習を防いでいる。
Value Netの強化学習
PolicyNetを使用して対局シミュレーションを行い、その結果の勝敗を教師として学習した。教師データ作成の手順は
- まずSL PolicyNet(教師あり学習で作成したPolicyNet)でN手まで打つ。
- N+1手目の手をランダムに選択し、その手で進めた局面をS(N+1)とする。
- S(N+1)からRLPolicyNet(強化学習で作成したPolicyNet)で終局まで打ち、その勝敗報酬をRとする。
S(N+1)とRを教師データ対とし、損失関数を平均二乗誤差とし、回帰問題として学習した。
この学習をminibatch size 32で5000万回行った
N手までとN+1手からのPolicyNetを別々にしてある理由は、過学習を防ぐためであると論文では説明されている
Roll Out Policy
NNではなく、線形の方策関数
探索中に高速に着手確率を出すために使用される。
policy net で予測をするときの計算時間は、一手につき3ミリ秒(3/1000秒)かかる。
何億パターンもの学習するときにこの速度ではとてつもなく時間がかかってしまう。
そこで作られたのが、Roll Out Policy
一手につき 3マイクロ秒 で計算できる。
Policy Net の教師あり学習
KGS Go Server (ネット囲碁対局サイト)の棋譜データから3000万局分の教師データを用意した。
モンテカルロ木探索
価値関数を学習させるときに用いる手法
どうやって価値関数を更新するか、に使う。
現局面から末端局面までPlayOutというランダムシミュレーションを多数行い、その勝敗を集計して着手の優劣を決定する。
(詳細な説明なし)
Alpha Go Lee まとめ
まずは教師あり学習でPolicy Netを学習して、次に強化学習(Policy Net および Value Net)をするという手法を用いることで、効率よく学習できる。
AlphaGo(Lee) とAlphaGoZeroの違い
1. 教師あり学習を一切行わず、強化学習のみで作成
2. 特徴入力からヒューリスティックな要素を排除し、石の配置のみにした
3. PolicyNetとValueNetを1つのネットワークに統合した
4. Residual Net(後述)を導入した
5. モンテカルロ木探索からRollOutシミュレーションをなくした
AlphaGo(Lee)では、「これは役に立ちそう」、みたいな特徴を取り入れていた
(シチョウとか呼吸点とかそういうのをチャネルに含めていた)が、
AlphaGoZero ではそういう人間の恣意的な要素を一切排除した。
Policy Value Net
ニューラルネットは、このように枝分かれすることができる。
分岐して、policy出力value出力をそれぞれ出力する。
真ん中のResidual Blockが重要。

Residual Network
・ネットワークにショートカット構造を追加して、勾配の爆発、消失を抑える効果を狙ったもの
・Residula Networkを使うことにより、100層を超えるネットワークでの安定した学習が可能となった
・基本構造は
Convolution → BatchNorm → ReLU → Convolution → BatchNorm → Add → ReLU
のBlockを1単位にして積み重ねる形となる
・また、Resisual Networkを使うことにより層数の違うNetworkのアンサンブル効果が得られているという説もある
スキップ(ショートカット)があることで、その分別の種類のネットワークがあるような効果がある。
39層あるので、組み合わせを考えると結構な数。
これがアンサンブル学習のような効果を生み出しているらしい。

ResidualNetworkの派生形
Bottleneck
1×1KernelのConvolutionを利用。
1層目で次元削減を行って3層目で次元を復元する3層構造。
2層のものと比べて計算量はほぼ同じだが1層増やせるメリットがある。
PreActivation
ResidualBlockの並びを
BatchNorm → ReLU → Convolution → BatchNorm → ReLU → Convolution → Add
とすることにより性能が上昇したとするもの
Network構造の工夫
WideResNet
ConvolutionのFilter数をk倍にしたResNet。
1倍→k倍xブロック→2*k倍yブロック
と段階的に幅を増やしていくのが一般的。
Filter数を増やすことにより、浅い層数でも深い層数のものと同等以上の精度となり、
またGPUをより効率的に使用できるため学習も早い
(特殊なことをしているわけではないけど)
PyramidNet
WideResNetで幅が広がった直後の層に過度の負担がかかり精度を落とす原因となっているとし、
段階的にではなく、各層でFilter数を増やしていくResNet
■ アドバイス
E資格の問題では、〇〇モデルではどのような工夫・改善がなされたか?
みたいな問題がよく出る。
例)AlphaGoZeroではどのような工夫がされたか?→ 選択肢 PreActivateionによってResidualBlockを~のようにして性能が向上した。
論文の中では、それほどのものでなくても、自慢げにそれっぽい名前がついていて自画自賛しているものがけっこう多いが、
既存のものを少しだけ改良したり、組み合わせただけ、のものがほとんど、とのこと。
でもそれらの改良方法や使用しているパーツとかはE資格の問題ではよく問われるとのこと。
ニューラルネットには、非常に重要な発見と、
それらを組み合わせただけでそれっぽい名前が付いているだけのものがあるので、区別するように。
※ 現代の深層学習で非常に重要なアイデア
- 畳み込み
- プーリング
- RNN:(ネットワークの出力を別のネットワークに入れるというアイデアは時系列処理の始まりだった)
- Attention
このそれぞれに活性化関数を適用している。
Residual Network
仰々しい名前だが、スキップ(ショートカット)がついてるだけ。
18~152層を試した。
VGGとの比較でエラーを4%軽減。
AlphaGoZeroの学習
講義では割愛
Alpha Go Zero まとめ
Policy Net と Value Net を統合した。
スキップ(ショートカット)がある39層のネットワークで、アンサンブル学習のような効果があるという説がある。
AlphaGoまとめ
イセドルを倒したから名前はもちろん知っていた。
そのときの衝撃もすさまじかったが、その後もとてつもない進化をしているのはあまりよく知らなかった。本当に驚くべきことだと思う。
また、当時は強化学習についてもよく知らず、いつの時点かにAlphaGoは強化学習が使われていることはなんとなく知っていたが、改めて今回強化学習がここで使われていたことを再認識できてよかった。
10 Section3-軽量化高速化技術
高速化
- モデル並列
- データ並列
- GPU
モデルを動かすときに高性能なPCでなくても動かせるようにしたい。(スマホとか)
- 量子化
- 蒸留
- プルーニング
分散深層学習
複数の計算資源で並列的にニューラルネットを構成することで効率化。
・毎年10倍の勢いでモデルの大きさとデータ量が増えている。
・PCは18か月で2倍の性能
PCの性能が追い付かない。
データ並列化、モデル並列化、GPUによる高速化が不可欠
データ並列化

夜中に充電中に暇しているみんなのスマホを計算資源として有効活用しよう、という研究もある。


同期か非同期を使うかの選択は、どこでどんな使い方をするかによって異なる。
PCを制御できる範囲にあるときは同期型、
世界中の資源を利用、とか、制御できないような資源を使うときは非同期、
といった具合
モデル並列化

モデルを細かいブロックに分割???
よくわからない。そんなことできるの?? どうやってBPとかパラメータ更新するのか。
最初の絵は縦にぶったぎっていて、なんで?と思ったが、
枝分かれした部分を分割するとあとで説明しなおしていたので、これならなんとなくイメージが沸く。
(参照論文) Large Scale Distributed Deep Networks
並列コンピューティングを用いることで大規模なネットワークを高速に学習させる仕組みを提案
GPU
単純な並列処理が得意。もともとはゲームのグラフィック用途。
行列演算のような単純な計算を高速に並列で計算できる。
GPUをDLで使うための環境
現在は CUDA だけ。
TFやPyTorchが対応している。
これらのフレームワークがCUDAに対応しているので、我々がCUDAの勉強をしなくてもよい。
対応したフレームワークを使えばいい感じで動いてくれる。
OpenCLというやつはDLには使われていない。
量子化(Quantization)
64bit浮動小数点を32bit浮動小数点などの下位精度に落とす。
メモリと演算処理の削減を行う。
モデルの規模を小さくする。
重みの情報をメモリに保持するときに、これらの大きさがネックになる。
BERTとかはパラメータの数が億単位になる。
これにより計算も速くなる。
単なる精度を落とすという話だと思うが、「量子化」と呼ばれるのは知らなかった。
省メモリ化

?
省メモリ=量子化?
いずれにしてもbit数を落とすときは極端に小さくすると精度が落ちるので
精度にあまり影響が出ない程度にする必要がある、ということ。
64bitを32bitにしても大して精度に影響はないが、省メモリ+計算高速化が実現できる。
bfloat16 seeeeeeeemmmmmmm
割り当ての仕方をexponentの部分を大きめにしたもの
これが効率がよいとのこと。
表現できる範囲が広い。
蒸留
でかくて精度の高いモデルを、推論用の軽量モデルにすること。
学習済みの精度の高いモデルの知識(頭脳?)を軽量なモデルに継承させる。
蒸留では、教師モデルと生徒モデルの2つを使用する。
教師モデル
予測精度の高い、複雑なモデルやアンサンブルモデル。
生徒モデル
教師モデルをもとに作られる軽量なモデル。

Hint Training という手法がもっとも精度が良かった。
プルーニング
ネットワークが大きくなると、すべてのパラメータが役に立っているわけではない。
精度に寄与していないパラメータが多くある。
寄与度の少ないニューロンを削除してモデルの圧縮を行う。
重みがしきい値以下の場合、ニューロンを削除してしまい、再学習を行う。
このとき、削除基準となるしきい値を上げすぎると精度に影響がある。(その分大量にニューロンを削除できるが)
軽量化高速化まとめ
実用的なエンジニアリング知識ということでたしかに興味深い内容だった。
量子化とメモリ省力化の説明のところ(両者の関係性)がちょっとよくわからなかった(用語の定義とか使い方の問題?)
11 Section4-応用モデル
いくつかネットワークを紹介。
ネットワークに関する問題はよく出る。問題を作りやすいからだと思う。
DQN、VGG、GoogleNet、ResNet、MobileNet、DenseNet、FasterR-CNN、YOLO、SSD、
WordEmbedding、Transformer、Wavenet、Pix2pix、AlphaGo
VAE、DCGAN、Conditionnal GAN
例)このネットワークではどのような特徴がありますか? (知ってれば得点できるレベル)(ほんと?)
画像に関するネットワークは、2017年頃に完成してしまっていて、もう劇的には発展しなさそうな雰囲気。
小さな計算資源で複雑なモデルを動かすという方向で研究が盛ん。
MobileNet
画像認識向けのネットワーク
畳み込み
28 * 28 * 3 入力特徴マップ H * W * C
3 * 3 * 3 畳み込みカーネル K * K * C
フィルタ数 3
出力チャネル数 H * W * M
H * W * K * K * C * M
一枚の画像でこれだけの計算量が必要
Depthwise Convolution と Pointwise Convolution の組み合わせで軽量化を実現
Depthwise Convolution
フィルタ数は1固定
1つのチャネルに対して1枚のフィルタで計算する。
H * W * K * K * C
Mが消せる
Pointwise Convolution
カーネルを1x1に固定する。
1x1のフィルタなんて、畳み込みと呼べるのか???
そりゃぁ計算量は減るだろうけど、なんでこんなことをするのか意味が分からない。
MobileNetまとめ
Depthwise Separable Convolutionという手法を用いて計算量を削減している。通常の畳込みが空間方向とチャネル方向の計算を同時に行うのに対して、Depthwise Separable ConvolutionではそれらをDepthwise ConvolutionとPointwise Convolutionと呼ばれる演算によって個別に行う。
(確認テスト)
Depthwise Convolitionはチャネル毎に空間方向へ畳み込む。すなわち、チャネル毎にDK×DK×1のサイズのフィルターをそれぞれ用いて計算を行うため、その計算量は(い)となる。
(解答)
H * W * C * K * K
(確認テスト)
次にDepthwise Convolutionの出力をPointwise Convolutionによってチャネル方向に畳み込む。すなわち、出力チャネル毎に1×1×Mサイズのフィルターをそれぞれ用いて計算を行うため、その計算量は(う)となる。
(解答)
H * W * C * M
全部掛け算だったのが、掛け算と掛け算の和という形になる。軽い。
VGGとかだとメモリ300MBとかかかるが、MobileNetだと10数MBしか使わず、本当に軽い。

DenseNet
これも画像認識向けのネットワーク
Dense Convolutional Network(以下、DenseNet)は、畳込みニューラルネットワーク(以下、CNN)アーキテクチャの一種である。ニューラルネットワークでは層が深くなるにつれて、学習が難しくなるという問題があったが、Residual Network(以下、ResNet)などのCNNアーキテクチャでは前方の層から後方の層へアイデンティティ接続を介してパスを作ることで問題を対処した。DenseBlockと呼ばれるモジュールを用いた、DenseNetもそのようなアーキテクチャの一つである。

出力層に前の層の入力を足しあわせる
層間の情報の伝達を最大にするために全ての同特徴量サイズの層を結合する

この画像は、DenseBlockの中の、小さな丸(この図の場合は真ん中の丸)を示している図


以前の出力も付け加えられていく。。。1つのDenseBlockの中で、4回繰り返している。
1回通過すると3chで4回繰り返すとしたら、3ch + 3ch × 4回 = 15ch くらいになる(?)

Transition Layerでダウンサンプリングを実施して、チャネル数が増えすぎないように工夫している。
DenseNet と ResNet との違い
ResNetもスキップコネクション、という前の層を引き継ぐようなのがあった。
ResNetのスキップ(ショートカット)は前の1層分しかジャンプしない。
DenseNetを(ブロック内の)前の層全部が後ろにかかっていく。
DenseNetにはGrowthRateという概念がある。
kはブロック内の繰り返し回数。(ハイパーパラメータなので、任意に設定できる)
3つの正規化
Batch Normalization
・レイヤー間を流れるデータの分布を、ミニバッチ単位で平均が0・分散が1になるように正規化
・Batch Normalizationはニューラルネットワークにおいて学習時間の短縮や初期値への依存低減、過学習の抑制など効果がある
・Batch Sizeが小さい条件下では、学習が収束しないことがあり、代わりにLayer Normalizationなどの正規化手法が使われることが多い
上記の問題により、あまり使いたくない。
バッチの大きさは、環境やデバイスによって、変えざるを得ない。
バッチサイズが小さい条件下では、学習が収束しないなどの副作用があるため、
バッチサイズを小さくしないとモデルが動かない、などということが頻繁に発生しうる現在の状況では、敬遠され、
使い勝手が悪いものとされている。(所属している会社や研究所にもよるだろうけど)

Layer Normalization
N個のsampleのうち一つに注目。H x W x Cの全てのpixelが正規化の単位。
1枚の画像で、3つの色チャネルを対処にして正規化を掛ける。
チャンネルをごちゃまぜにするイメージ
RGBの3チャネルのsampleがN個の場合は、あるsampleを取り出し、全てのチャネルの平均と分散を求め正規化を実施する。
こうやったらうまくいった、というのが本音。
ずいぶんBatch Normとは違うことやっている。
でもこっちのLayer Normはなんでかよくわからんがうまくいくし、上記のBath Normのミニバッチ数依存問題も解消している。

Layer Normは、入力データや重み行列に対して、以下の操作を施しても、出力が変わらない。
- 入力データのスケールに関してロバスト
- 重み行列のスケールやシフトに関してロバスト
Instance Normalization
(不思議な話のひとつらしい)
もはや何個も集める必要ないんじゃないの?
→ 各サンプルの各チャネルごとに正規化をしてみた。
→ うまくいった。
1枚の画像の各チャネル、赤なら赤のチャネルそれだけのなかで正規化をする。
はっきりした要因というのはわからないけど正規化はニューラルネットでうまくいくというのはだいぶ以前から知られている。
音声生成モデル
WaveNet
時系列データに対して畳み込みを適用する。
Dilated Convolution
層が深くなるにつれて畳み込むリンクを離す。
受容野を簡単に増やすことができる。
とびとびに畳み込みを実施していく(?????)(この図では詳しくはわからないけどイメージは分かる)

(確認テスト)
深層学習を用いて結合確率を学習する際に、効率的に学習が行えるアーキテクチャを提案したことがWaveNet の大きな貢献の1 つである。提案された新しいConvolution 型アーキテクチャは(あ)と呼ばれ、結合確率を効率的に学習できるようになっている。
(解答)
Dilated causal convolution 正解
Depthwise separable convolution → MobileNetでチャンネルの方は331で畳み込むというやつ(separableという単語はついてなかったが?)
Pointwise convolution → これもMobileNetで出てきたやつ
Deconvolution → 逆畳み込み(?) 小さな画像のピクセル数を増やして畳み込みを行う?といった感じで。
画像の解像度を上げる、例えば古いビデオの画像を4kにするとき、などにこういう手法を使う。
(確認テスト)
(あ)を用いた際の大きな利点は、単純なConvolution layer と比べて(い)ことである。
(解答)
パラメータ数に対する受容野が広い 正解
受容野あたりのパラメータ数が多い : 受容野あたりのパラメータは減るはず。
学習時に並列計算が行える : 関係ないのでは? あるいは並列演算は難しくなると思う。
推論時に並列計算が行える : これも同じく。
応用モデルまとめ
蒸留の手法は、学習済みのモデルを元に(教師モデル)して、非力な環境でも動かせるようなモデル(生徒モデル)を生成する、という非常に興味深い内容だった。教師モデルと生徒モデルのそれぞれの誤差を使って重みを更新していくというロジックの詳細は今後調査してみたい。
12 Section5-Transformer
このセクションの流れ。
Seq2Seqを理解し、それからBERTを学習
AttensionとTransformerを理解する。
Seq2seq : Sequence to Sequence
RNN
- 系列情報の学習における順序情報を加味したモデル(既習)
- 最終的に内部状態ベクトルを出力するということが重要
言語モデル
- 単語の並びに対して、事後確率最大を計算する
- 決定的 : 0か1か ⇔ 確率分布
- Start of sentence
- 言語の自然な並び方を学習する
Encoder-Decoder
- 2つのRNNを連結
- 1つ目がエンコーダ(入力)で2つ目がデコーダ(出力・生成モデル)
- 内部状態ベクトルを出力することエンコード
- デコーダは初期値としてhが与えられるかどうか
- デコーダのアウトプットに正解を与えれば、教師あり学習がend2endで行える
Teacher Forcing
- 正解ラベルを直接デコーダの入力にする
- 訓練とテストで状態が異なるので、テスト結果が悪い可能性がある
Transformer
ニューラル機械翻訳の問題点
文が長くなると表現力が足らなくなる。
(文が長くなるとみるみる精度が落ちていく)
Attention (注意機構)
Attention自体は2015年くらいには発表されていた。(Bahdanau et al. 2015)
情報量が多くなった時に、何に注意を払い、何に注意を払わないべきかを学習的に決定していく、という機構。
内部構造としては単純。
$$
c_i = \sum_{j=1}^{T_x} \alpha_{ij} h_j .
$$
Sumを取ると1になるような重みを設定する。
その重みの分配を各隠れ層の状態の重みを分配していく。

この例だと、$ h_1 $ は重めで $ h_2 $ は普通で $ h_3 $ は軽めで、足すと1になる、というような調整
$$
\alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{k=1}^{T_x} \exp(e_{ik})}
$$
$$
e_{ij} = a(s_{i-1}, \ h_j)
$$
全て足すと1になる重みは、FFNN(Feed Forward Neural Network)でもとめる。
Attentionの3要素
Query、 Key、 Value の3要素でできている。

つまるところ、辞書オブジェクトのようなもの。
query(入力文章)に対してデータベースの中に存在する key の中から query に似た文章を「類似度」を取って検索してくる。
この類似度をとったものに対してソフトマックスをかけると、どれくらい類似しているのかが正規化された形(ベクトル)で出てくる。
正規化されたベクトルを valueという文章の羅列に掛けると、どの文章に注目すべきか、が引き出せる。
keyに対応するqueryを打ち込むと、queryに対応したvalueを引き出せる。これはすなわち辞書オブジェクト。
key-value Attention と呼ばれる(?) (これだと0,1,0,0のようなハードな形(離散的)になってしまって微分できない)
ほんとのAttentionはもっと分散した形(soft attention)だが、イメージとしてはこんな感じ。
文書が長くなっても精度が落ちないということが分かってきた。
Transformer (Vaswani et al. 2017)
** Attention is all you need **
2017年6月
RNNを使わずに、必要なのはAttentionだけ。
当時のSOTAをはるかに少ない計算量で突破した。

大まかな流れ
RNNを使っていないので文字の位置情報を保存できないという弱点があるので、
まず最初に位置情報を付加している。
次に複数のヘッドでDot Product Attentionをする。(講義では self-attentionと言っている)
それをFeedForward(全結合層)にながす。
デコーダ部分では、順序を考慮した学習をするために、未来の単語を見ないようにマスクする機構が入っている。

発明された当初のものと、transformerで使われているものとでは、別物。
source target attention と Self-Attention
Self-Attentionは q,k,v 全てが同じ場所から来る。

※ z1の式は全部v1になっているが、正しくはv1、v2、v3 (講師が訂正)
よく言われているのは、CNNと類似性があるということ。
数式的にはちょっと違うが、どちらも文脈依存の学習をしている。
CNNはウィンドウサイズがあるので決められた範囲内で畳み込み(周辺の情報を考慮した学習)をする。
Self-Attentionは入力された情報すべてから文脈を学習する。
Position-Wised Feed-Forward Network
普通に全結合層を使ってしまうと位置情報を破壊してしまうので、
位置情報を保持したまま順伝播させるようなネットワーク。
線形変換を掛ける層で最終的にアウトプットの次元を揃えなくてはならないので、マトリクスを整えるための全結合層。

Scaled dot product attention
Attentionが実際にどのような計算機構になっているか。
左の図のように、QKVが入力として与えられる。(これらは同じ情報らしい)
QKVが同じ情報とはいっても、それぞれ別の重みで線形変換をかけられた値が流されてくるので処理している値は異なる。
query と key の行列積を取る。
この例だと(3, 1)・(1, 3)なので、(3, 3)の行列が作られる。
これに対して(各行に)ソフトマックスをかけると、図の下段の例ような値になる。
$ d_k $ というのは、内部状態の次元数。これで割ることで、qkが大きくなりすぎないように調整している。
(大きくなりすぎるとバックプロップが効きづらくなるので)
Mask は、扱いたくないAttentionをカットする仕組み。
UNKとかPADとか特別に無視したいものをカット。

Multi-Head Attention
なぜ8個あるのか。
Attention機構を分離させることで、それぞれの独自の注意の掛け方を学習していって、総合的にいい感じにするため。
アンサンブル学習をするような気持ち。

Decoder
Encoderとほぼ同じ。
DecoderはMulti-Headが2つある。
下がSelf-Attention 上がSource Target
上の方は、Encoderの入力を考慮して何を注意すべきか、を学習したいのでSource Targeを使っている。
下のは、一気に情報を入れてしまうと、未来が見えてしまうので、未来はカットする。
(そのため、「Masked」が名前の先頭についている。)

Add & Norm
お作法のようにAdd & Normがついている。
学習上のテクニックのようなもの。
Add (Residual Connection)
入出力の差分を入力すると学習が効率化する。
実装としては2行書くだけ。
Norm (Layer Normalization)
既習。ばらつきを抑える。正規化。

Position Encoding
sin cos を使って位置情報を保持している。


Transformer まとめ
文脈に応じた自己定義ができる、計算量の割に表現力が豊かなモデル。
LSTMに比べると構造がシンプル。
のちにBERT系モデルや、GPT、T5などで使われて、自然言語処理の世界を塗り替えてしまったように思えるモデル。
13 Section6-物体検出
どのようなタスクを解くか

代表的データセット
| データセット名 | クラス | Train+Val | 1画像あたりのボックス数の平均 | 備考 | |
|---|---|---|---|---|---|
| VOC12 | 20 | 11,540 | 2.4 | Instance Annotation | PASCAL VOC Object Detection Challenge |
| ILSVRC17 | 200 | 476,668 | 1.1 | - | 2017年に終了(後継はOpen Images Challenge) Imagenetのサブセット |
| MS COCO18 | 80 | 123,287 | 7.3 | Instance Annotation | Microsoftのデータ |
| OICOD18 | 500 | 1,743,042 | 7.0 | Instance Annotation | 他に比べて枚数が多い |
| ni | |||||
| 画像サイズは一様ではない。 |
1画像あたりのボックス数の平均
少ないとアイコン的な日常の画像とはかけ離れたもの
多いと日常のコンテキストに近いものになる。物体の重なりも多くなる。
他にも
cifer10とかfood101とか
楽天データとか
有名なコンペは商業的に宣伝効果があるので重要視される。
(2015年にある企業がテストデータに不正アクセスして問題になったこともある)
※ クラス数が多くて嬉しいのか
ImageNetの悪い例
同じようなものなのに別物として分類されていることによりクラス数が増えている場合もある。
おかしなものもある。ex)葉っぱの上にテントウムシの画像に、左隅に蟻が小さく映っていて「蟻」とラベリングされている、とか。
もうImageNetを使うのは時代遅れではないか、という主張がされてきている。
(品質が悪くなる原因になっている)
評価指標
混同行列(復習)

IoU

Union部分が分母に来るのは、理由がある。
以下のような定義をしてしまうと、正確な評価ができないため。

同じものに対して複数検出してしまうときの扱いはアルゴリズムによっていろいろある。
被ったものは除外するアルゴリズムもあれば、そのまま結果として出てきてしまうものもある。
mAP

MS COCO で導入されたのは、IoUの閾値も0.05刻みでAP&mAPを計算して算術平均を計算した。

※ 応用上の要請から, 検出精度に加え検出速度も問題となる。
FPS: Frames per Second
物体検出
2012年のAlexNetの登場を皮切りに時代はSIFTからDCNNへ移った。
AlexNetの論文はちゃんと読んだ方がよいとのこと。

アルゴリズムの特性などを考慮して選択すること。雰囲気で決めない。

2段階検出器は時間がかかる。
リアルタイム検出だと1段階検出のスピードを求められることが多い。
SSD (Single Shot Detector)
1段階検出器
DefaultBoxを用意し、それを変形して検出領域を出力する。
VGG16のネットワーク復習
(これも論文は読んでみてくださいと)
黒と青のボックスを数えると16個あるのでVGG16

SSDのネットワークアーキテクチャ

多数のデフォルトボックスを用意する。
IoUを計算し、閾値で複数の予測があったら、最もconfidenceが高いものだけを残す。
IoUが小さい(重なりが小さい)場合は、別のものを指している可能性が高いので除外しない。
背景のようなクラスがある場合に、背景の数がそれ以外の物体と比べて多くなりすぎて不均衡となる。
⇒ 最大の比率を決めてそれ以上にならないように制約を掛ける
ex) posittive:negative=1:3 とか
その後のSSDの進化
DSSD: ResNetがベース(SSDはVGG16だったのに対して)
SS (Semantic Segmentation)
アップサンプリングの壁
コンボリューション+プーリングを経ることで解像度が下がっていくので、SSを行うためにはアップサンプリングが必要になる。
プーリングなんてしなければよいのでは? という疑問が出てくると思うが、反論できるか?
→ ある程度の受容野を確保するためにはどうしても必要。
→ コンボリューションを増やす方向で受容野の確保を解決しようとすると演算量・メモリの問題にぶつかる。
Deconvolution / Transposed Convolution

FCNとUNetの例
FCN

UNet

DeconvNet & SegNet
Unpooling
どこが最大の情報を持っていたのかという位置情報を保持しておいて、その位置情報をもとにUnpoolingを行う。
Dilated Convolution
プーリングなしでやっぱりなんとかする手法

物体検出まとめ
物体検出における評価指標は、IoU、mAP、mAP COCOなどがある。
物体検出フレームワークは大別すると2種類。
(1段階検出器と2段階検出器)
SSDはVGG16をベースにしたもので、全結合層は削除してある。
物体検出アルゴリズムにおいては、低くなった解像度をどうやってアップサンプリングするかが問題となる。
DeConvolutionやUnpoolingで対処する。
14 GAN
GAN
生成器と識別器を競わせて学習する生成&識別モデル
Generator と Discriminator
Generator
乱数からデータを生成
Discriminator
入力データが真データ(学習データ)であるかを識別。
相反する目的で2人がそれぞれ学習を行う
↓
2プレイヤーのミニマックスゲームで説明ができる。
- 1人が自分の勝利する確率を最大化する作戦を取る
- もう一人は相手が勝利する確率を最小化する作戦を取る
- GANでは価値関数𝑉に対し, 𝐷が最大化, 𝐺が最小化を行う
価値関数𝑉

バイナリクロスエントロピーに似ている

判定のときの要になるのは、おそらくここだと思われる。

DCGAN
GANを利用した画像生成モデル。いくつかの構造制約を組み込むことにより成果物の品質を向上させている。
Generator
- Pooling層の代わりに転置畳み込み層を使用
- 最終層はtanh、その他はReLU関数で活性化
Discriminator
- Pooling層の代わりに畳み込み層を使用
- Leaky ReLU関数で活性化
共通
- 中間層に全結合層を使わない
- バッチノーマライゼーションを適用
GANまとめ
このモデルを最初に知ったときは衝撃的だったのを覚えている。
2プレイヤーのミニマックスゲームというたとえが分かりやすかった。
偽札を作る人とそれを見つけるための捜査官というたとえ話も確かどこかで聞いたような気がする。
発展形のDCGANやほかにもCycleGAN、StyleGANなど実際に試しに使ってみたことがあるものも多い。
これらの発展形も面白いアイデアでできている。
CycleGANは大量のペア画像を用意しなくても、2つの違う画像データセット(それぞれ固有のドメインとして収集されたデータ群)からその関係を学習して画像変換アルゴリズムを獲得できるモデルである。
これは、普通の馬の画像をシマウマに変換することができるモデルとして有名である。
このアイデアを知った時もとても驚いたのを覚えている。
15 day3とday4の演習
ノートブックによる演習
1. シンプルなRNN
2. RNN、LSTM、GRUの実装演習
3. Transformer(Seq2Seq)
4. Transformer(Attentionのみ)(RNNなし)
Githubのノートブックが表示されない場合のサイト
https://nbviewer.jupyter.org/github/rkti498/e_shikaku/blob/main/day34_01_simpleRNN.ipynb
https://nbviewer.jupyter.org/github/rkti498/e_shikaku/blob/main/day34_02_predict_word.ipynb
https://nbviewer.jupyter.org/github/rkti498/e_shikaku/blob/main/day34_03_lecture_chap1_exercise_public.ipynb
https://nbviewer.jupyter.org/github/rkti498/e_shikaku/blob/main/day34_04_lecture_chap2_exercise_public.ipynb