LDAとは
LDA(Linear Discriminant Analysis)とは機械学習において変数の次元削減に使われるテクニックです。次元削除の代表的なテクニックにPCAもありますが、PCAとの大きな違いは、PCAは教師なし学習であるのに対し、LDA 教師ありの識別モデルです。
LDAのメカニズム
LDAの目的はクラス間分散を最大にしながら、クラス内分散を最小にする境界線を引くことです。
1)クラス間分散
S_b = \sum^g_{i=1} N_i(\overline{x}_i - \overline{x})(\overline{x}_i - \overline{x})^T
- クラス内分散
S_w = \sum^g_{i=1} (N_i-1)S_i = \sum^g_{i=1} \sum^{N_i}_{i=1}(\overline{x}_{i,j} - \overline{x}_i)(x_{i,j} - \overline{x}_i)^T
- 低次元空間への写像
P_{lda} = arg max \dfrac {\left| P^TS_bP\right| }{\left| P^TS_wP\right|}
- 判別式
LDAの判別式は、下のように各クラスに対するガウス分布になります。
P(X|y = k) = \dfrac {1}{(2\pi)^{1/2}|\Sigma_k|^{1/2} exp(-\dfrac{1}{2}(X-\mu_k)^t \sum^{-1}_{k}(X-\mu_k))}
scikit learn で LDA
LDAのパラメター
|パラメター|概要|値|デフォルト|
|---|---|---|---|
|solver|学習の最適化計算のタイプ|"svd", "lsqr", "eigen"|"svd"(大きいデータセットに適する)|
|shrinkage|"lsqr", "eigen"で使われる、学習データの不足補正|None, "auto", floa(0~1)|None|
|n_components|削減する次元数|int|-|
|store_covariance|共分散行列を計算するかどうか|bool|-|
|tol|SDVのしきい値|float|-|
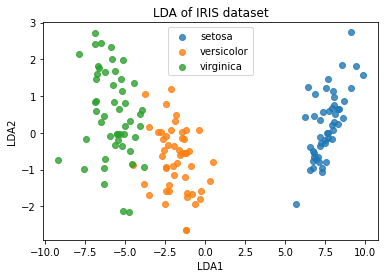
from sklearn import datasets
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from matplotlib import pyplot as plt
iris = datasets.load_iris()
X = iris.data
y = iris.target
target_names = iris.target_names
lda = LinearDiscriminantAnalysis(n_components=2)
X_r = lda.fit(X, y).transform(X)
可視化
colors = ['blue', 'red', 'green']
for color, i, target_name in zip(colors, [0, 1, 2], target_names):
plt.scatter(X_r[y == i, 0], X_r[y == i, 1], alpha=.8,
label=target_name)
plt.xlabel('LDA1')
plt.ylabel('LDA2')
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.title('LDA of IRIS dataset')
plt.show()
LDA の利点と欠点
利点
- 多クラス分類問題では、PCAより性能が良い。
欠点
- 小さいサンプルサイズには向いていない。
- クラスの事後確率が正規分布に従う必要がある。
- 全てのデータに対し、分散共分散行列は同じである必要がある。(→QDA)
LDAの応用
-
QDA(Quadratic Discriminant Analysis):
クラスごとに分散共分散を計算。 - FDA(Flexible Discriminant Analysis):入力データが線形分離できない時。
- RDA(Regularised Discriminant Analysis):正規化して分散共分散を計算することで、多変数の影響を抑える。
参照
Priyankur Sarkar, "hat is LDA: Linear Discriminant Analysis for Machine Learning", 2019
https://www.knowledgehut.com/blog/data-science/linear-discriminant-analysis-for-machine-learning