はじめに
この記事では、いつもよりも少し丁寧にCAIプロセスでCSVファイルを読み込む実装、CSVファイルを書き出す実装を確認します。
なお、この記事は次の記事の内容を理解していることを前提としています。
- はじめてCAIを使う際に
- プロセスの作成と実行(匿名認証と基本認証)
- 割り当てステップと、各種変数フィールドの利用
- プロセスオブジェクトによるユーザー定義変数の利用
- CAIでXQueryを利用する時に覚えておきたいこと
- テキストファイルの作成
CSVファイル読み込み・CSVファイル書き出し
CAIプロセスの実装手順を確認する前に、実装方針について簡単に説明します。
-
CSVファイルの読み込み
CAIでは、CDIのように任意のタイミングでCSVファイルを読み取って、少し変換して、CSVファイルに簡単に出力する手段が用意されていません。ではどのように実装するのかと言うと、XQueryの標準関数fn:unparsed-textやfn:tokennizeを利用します。- fn:unparsed-text ... テキストファイル全体を文字列として読み込む
- fn:tokenize ... 指定文字(改行コード・カンマ)で文字列を分割してシーケンス(配列)を取得する
-
CSVファイルへの書き出し
CSVファイルへの書き出しも、やはりCDIのように簡単には設定できません。ヘッダー部はXMLで定義します。CSVのデータ部については動的にXMLを生成するためにXQueryによるコーディングが必要になります。
CAIプロセスの作成
最初に、今回CAIプロセスの動作確認をするために利用するCSVファイルを生成します。次のコマンドではカレントディレクトリに動作確認用のCSVファイルを生成しています。
cat << ___EOF___ > fruite.csv
id, name, color
1, orange, orange
2, kiui, green
3, banana, yellow
4, mango, yellow
5, watermelon, red
6, melon, green
7, lemon, yellow
8, apple, red
9, grape, purple
___EOF___
次の手順では、CSVファイルを読み込んでテキストファイルの作成で定義したアプリケーション接続 recipe-appConn-FileWrite のイベント Delimited Content Writer を使ってCSVファイルを出力するCAIプロセスを作成しています。
読み込んだCSVファイルのid/name列を、File接続で定義したディレクトリに書き出します、もとのCSVファイルで定義しているcolor列は意図的に欠落させています
-
CAIプロセスを次の設定で作成します。
- 名前を recipe-psa-fileWriteCsv2Csv とする
- 匿名アクセス を許可する
- Secure Agent にデプロイする
-
一時フィールドとして tmpFile を定義します。定義された接続タイプ にはアプリケーション接続 recipe-appConn-FileWrite を指定、タイプ として Delimited Content Serialization Task を指定します。
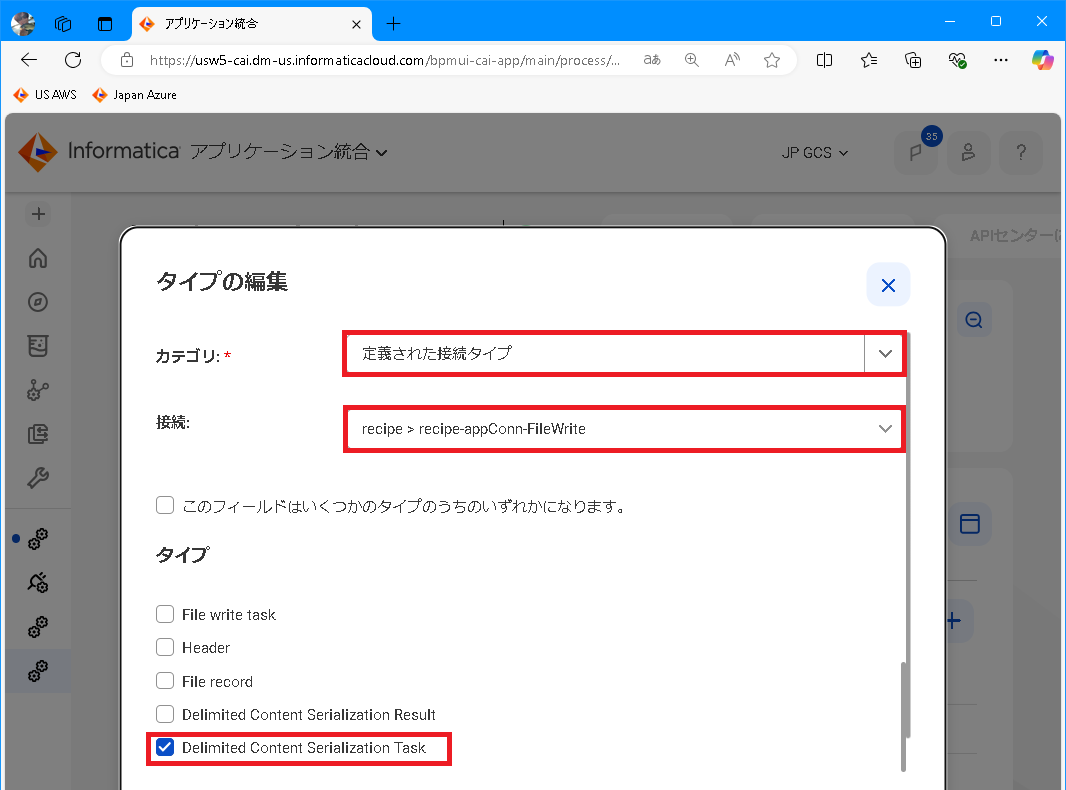
-
出力フィールドとして output を定義します。定義された接続タイプ にはアプリケーション接続 recipe-appConn-FileWrite を指定、タイプ として Delimited Content Serialization Result を指定します。
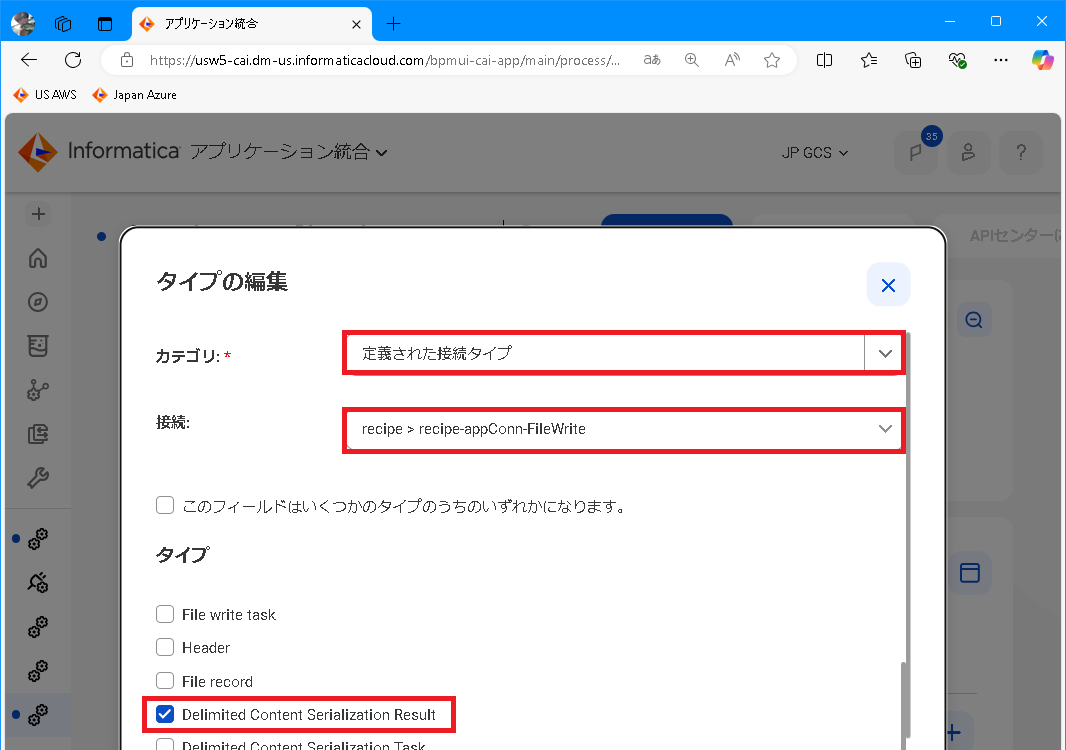
-
CAIプロセスが次の順に実行されるように各種ステップを追加します。
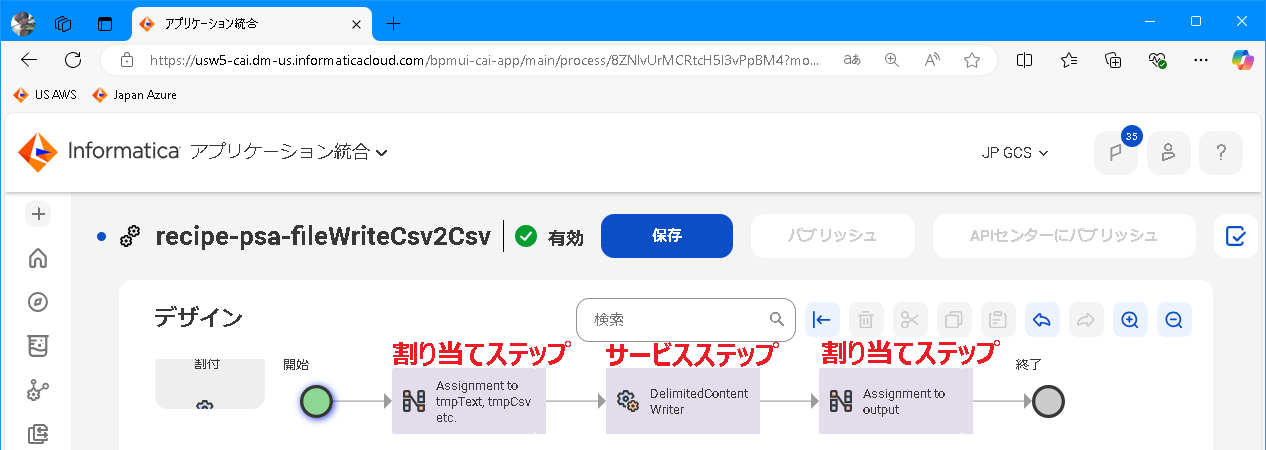
-
割り当てステップを選択して、次のように設定します。
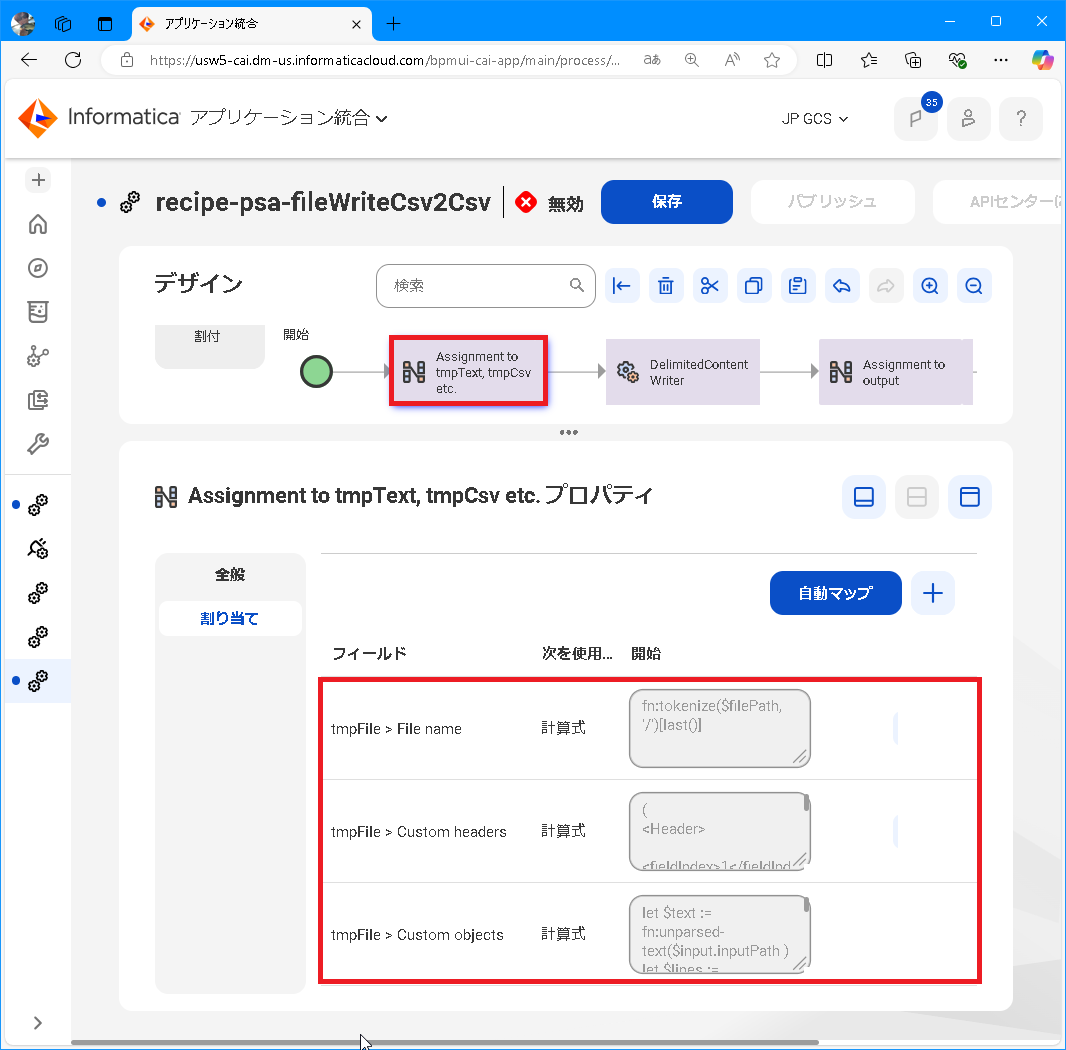
フィールド 割り当て 値 tmpFile > File name 計算式 fn:tokenize(\$inputPath , '/')[last()]
入力フィールドのファイルパスからファイル名を取得しています。tmpFile > Custom headers 計算式 (
<Header>
<fieldIndex>1</fieldIndex>
<name>id</name>
</Header>,
<Header>
<fieldIndex>2</fieldIndex>
<name>name</name>
</Header>
)
ヘッダーをXMLで指定しています。tmpFile > Custom objects 計算式 let \$text := fn:unparsed-text(\$input.inputPath )
let \$lines := tokenize(\$text , '\n')
let \$fieldnames:=tokenize(\$lines[1], '\s*,\s*')
return
for \$line at \$i in \$lines
where \$i gt 1
let \$fields := tokenize(\$line, '\s*,\s*')
return
<row>{
for \$fieldname at \$j in \$fieldnames
return
element {fn:replace(\$fieldname,'"','')} {fn:replace(\$fields[\$j],'"','')}
}</row>
XQueryによるコーディングで、大きく次の2つの処理、『CSVファイルの読み込み』と『CSVファイル出力用のデータ生成』を行っています。コードについてはCSVデータ部を生成するXQueryコードの説明に補足を書いてあります。 -
サービスステップを選択して サービスタイプ=接続、接続=recipe-appConn-FileWrite、アクション=DelimitedContentWriter を指定します。
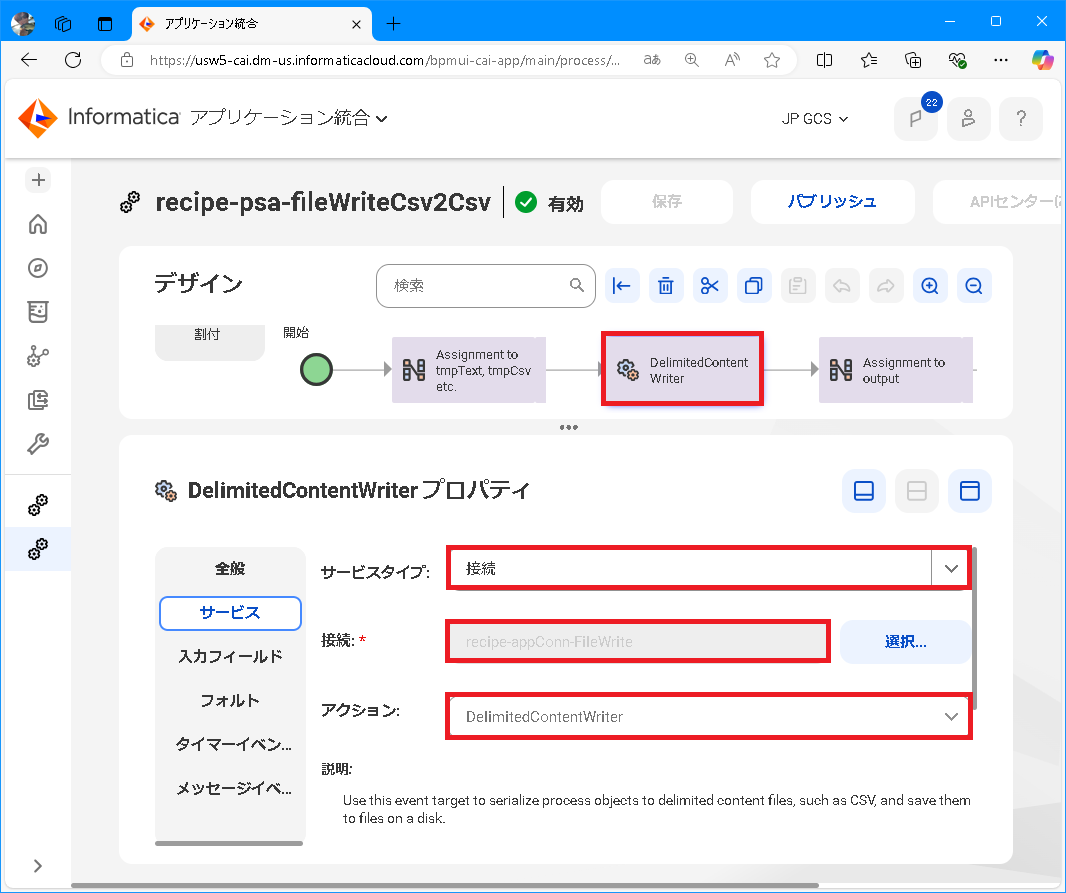
-
サービスステップの 入力フィールド タブを選択して、次のように設定します。
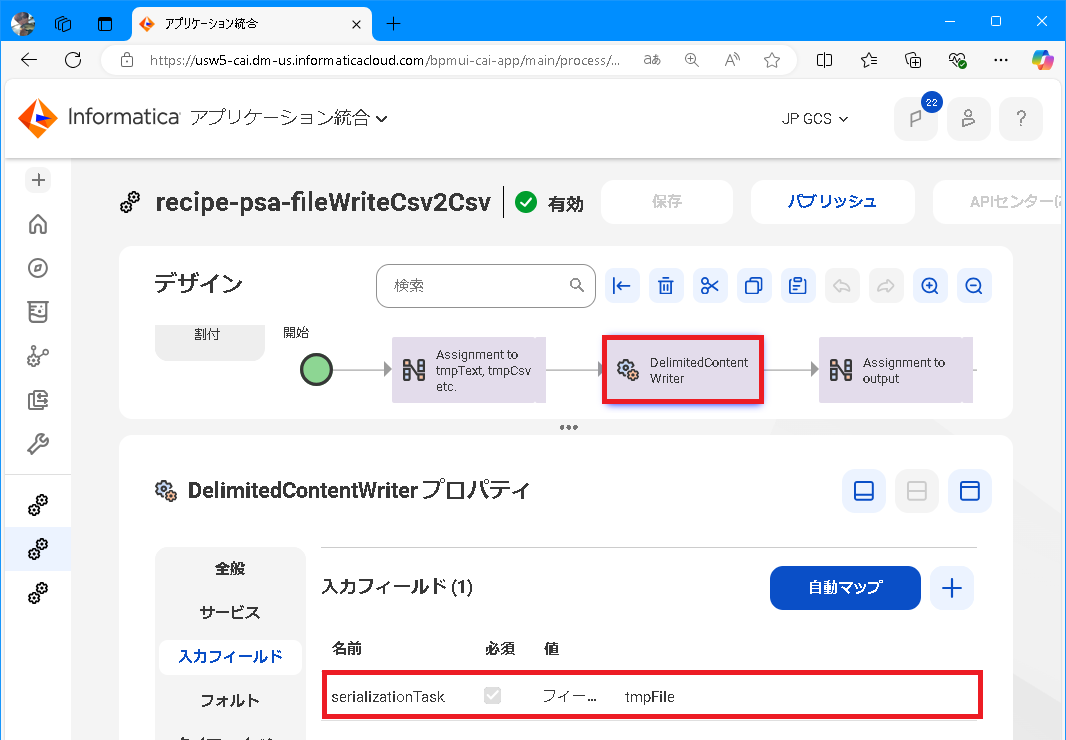
-
割り当てステップを選択して、出力フィールド output に イベント serializationResult( Delimited Content Writer の実行結果)を指定します。
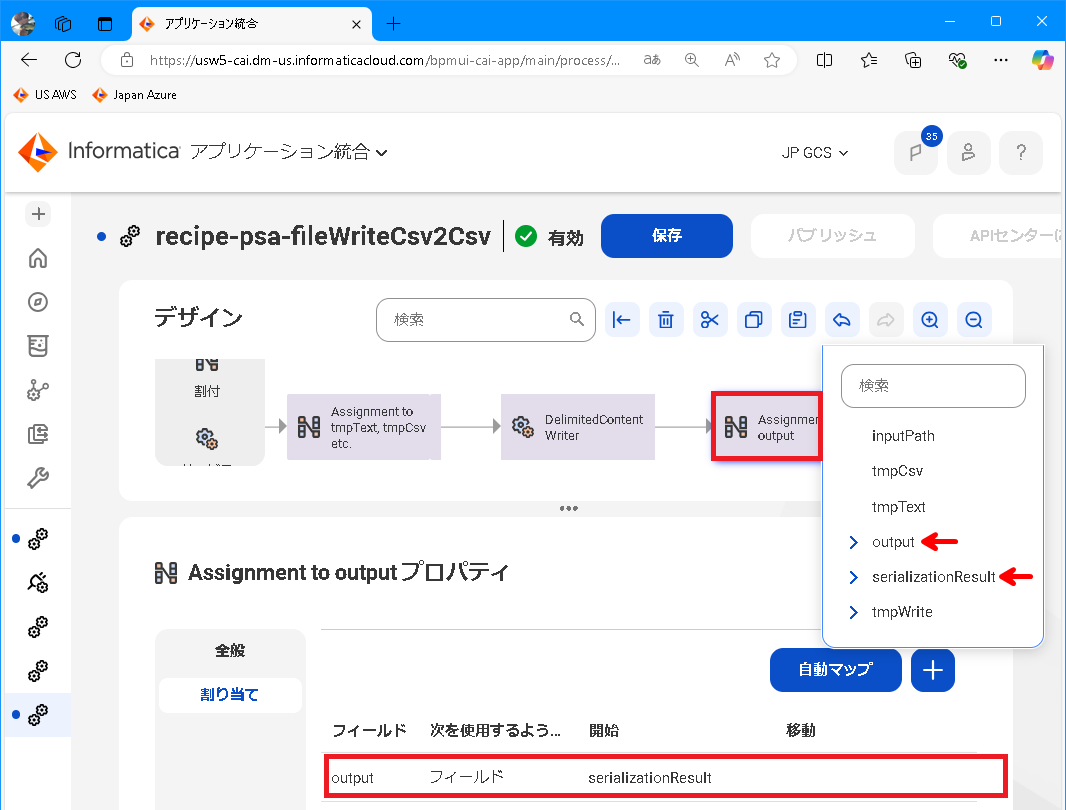
CAIプロセスの実行
curlコマンドを例とした動作確認結果です。ヘッダーの設定(Custom headers)にて、color列を含めていないため、出力ファイルにもcolor列が含まれない動作を確認できます。
curl -k https://localhost:7443/process-engine/public/rt/recipe-psa-fileWriteCsv2Csv \
-H 'Content-Type: application/json' \
-d '{"inputPath": "/opt/infaUSW5/ff/fruite.csv"}'
//実行結果
{
"output": {
"fileInfo": {
"fullName": "fruite.csv",
"name": "fruite",
"ext": "csv",
"path": "/opt/infaUSW5/ff/tgt/fruite.csv",
"dir": "/opt/infaUSW5/ff/tgt",
"size": 96,
"lastModified": "2024-12-15T07:06:56Z"
},
"processedRecordsCount": 10,
"writtenRecordsCount": 9,
"success": true,
"message": null
}
}
//出力ファイルの確認
$ cat fruite.csv
id,name
1,orange
2,kiui
3,banana
4,mango
5,watermelon
6,melon
7,lemon
8,apple
9,grape
CSVデータ部を生成するXQueryコードの説明
次のXQueryコードについての説明です。
01: let $text := fn:unparsed-text($input.inputPath )
02: let $lines := tokenize($text , '\n')
03: let $fieldnames:=tokenize($lines[1], '\s*,\s*')
04: return
05: for $line at $i in $lines
06: where $i gt 1
07: let $fields := tokenize($line, '\s*,\s*')
08: return
09: <row>{
10: for $fieldname at $j in $fieldnames
11: return
12: element {$fieldname} {$fields[$j]}
13: }</row>
- 1行目: 入力フィールド inputPath で指定されたファイルのテキストデータを取得しています。
- 2行目: 取得したテキストデータを改行コードで区切りシーケンス(配列)として取得しています。
- 3行目: テキストデータの1行目(
$lines[1])、つまりヘッダー行をカンマで区切りシーケンス(配列)としてからフィールド名を取得しています。なお、ヘッダー行のフィールド名前後には空白が入っていることが想定されるため、tokenizeによる分割処理時には、正規表現\s*,\s*を指定しています。 - 5-6行目: テキストデータを改行コードで区切り、シーケンス(配列)の2行目以降(
where $i gt 1)、つまりCSVファイルのデータ部を対象に処理します。 - 9,13行目: 行データを示すrow要素の開始・終了を記述しています。
- 10行目: 各フィールドを対象に処理します。この際、フィールド名に対応した位置(インデックス)を$jとして使えるように
for ... at ... inという形式のfor文を使用しています。 - 12行目: この処理は
element {フィールド名} {フィールド値}の形式になっています。例えばelement {"example"} {"This is content"}は<example>This is content</example>を返します。
なお、このXQueryでは次のようなXMLデータを生成しています。
<row>
<id>1</id>
<name>orange</name>
<color>orange </color>
</row>
<row>
<id>2</id>
<name>kiui</name>
<color>green </color>
</row>
...略
修飾子付きのCSVファイル形式に対応するには?
CSVファイルはシンプルにカンマで区切られている形式のほかに、列情報をダブルクォートで囲んでいる修飾子付きのCSVファイル形式もあります。今回の実装例では、前者のシンプルな形式のCSVを使っていましたが、後者の修飾子付きのCSVを扱う場合には、実装に工夫が必要です。
参考までの情報となりますが(CAIプロセスでは動作確認をしていませんが)、Javaでは正規表現,(?=(([^\"]*\"){2})*[^\"]*$)により文字列を分割して修飾子付きのCSVファイルの各列を取得できる動作を確認しています。