はじめに

Oracle Cloud Infrastructure が提供する AI サービスの中でオブジェクト検出、イメージ分類や OCR を行う Vision サービスが 2022/02/17 に GA となりました。ということで、今回は Vision とそれに関連するサービス群(主に、Data Labeling)を使ってサクッと画像分類を行ってみます。
学習済みモデルを使う
Vision サービスには、あらかじめ学習済みのモデルが構築されています。そのため、簡易的な物体検出やイメージ分類くらいであれば自分でモデルを作成しなくても行うことができます。いくつかの操作方法が提供されているので、それぞれ見ていきます。
GUI(OCI コンソール)から扱う
まずは、一番シンプルに OCI コンソールから扱ってみます。Vision のトップメニューからイメージ分類を選択します。
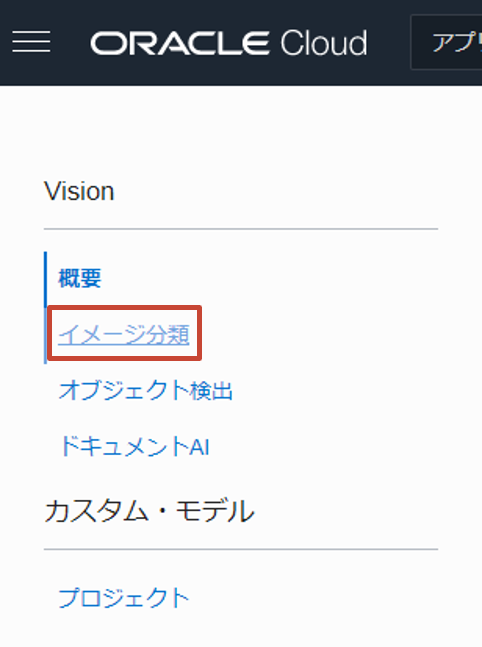
以下のような画像を試しにアップロードしてみると、

結果の欄に分類結果が表示され、簡易的にモデルの精度の確認を行うことができます。

また実際に、API を実行した際のリクエストボディやレスポンスボディも Raw テキスト内のリクエスト、レスポンスで確認する事が可能です。たとえば、今回の場合だと以下のようになっています。(一部、情報をマスクしています)個人的には、実際のリクエスト組み立てに地味に役立つので結構ありがたいです。
リクエスト
{
"analyzeImageDetails": {
"compartmentId": "ocid1.compartment.oc1...",
"image": {
"source": "INLINE",
"data": "......"
},
"features": [
{
"featureType": "IMAGE_CLASSIFICATION",
"maxResults": 5
},
{
"featureType": "TEXT_DETECTION"
}
]
}
}
レスポンス
{
"labels": [
{
"name": "Bird",
"confidence": 0.98626745
},
{
"name": "Water",
"confidence": 0.920809
},
{
"name": "Duck",
"confidence": 0.8393242
},
{
"name": "Lake",
"confidence": 0.82022226
},
{
"name": "Goose",
"confidence": 0.73093736
}
],
"ontologyClasses": [
{
"name": "Water",
"parentNames": [],
"synonymNames": []
},
{
"name": "Goose",
"parentNames": ["Poultry"],
"synonymNames": []
},
{
"name": "Bird",
"parentNames": ["Vertebrate"],
"synonymNames": []
},
{
"name": "Duck",
"parentNames": ["Poultry"],
"synonymNames": []
},
{
"name": "Lake",
"parentNames": ["Water", "Nature"],
"synonymNames": []
},
{
"name": "Nature",
"parentNames": [],
"synonymNames": []
},
{
"name": "Poultry",
"parentNames": ["Fowl"],
"synonymNames": []
},
{
"name": "Vertebrate",
"parentNames": ["Animal"],
"synonymNames": []
},
{
"name": "Animal",
"parentNames": [],
"synonymNames": []
},
{
"name": "Fowl",
"parentNames": ["Bird"],
"synonymNames": []
}
],
"imageClassificationModelVersion": "1.4.41",
"errors": [
{
"code": "FEATURE_NOT_SUPPORTED",
"message": "Text detection feature is not supported on non-english images."
}
]
}
API から扱う
実際に、サービスに組み込む際は API を活用することになると思うため、そちらの方法についても触れておきます。今回は、自分の手元(OCI Compute)に Jupyter Notebook の環境をセットアップ済みなのでそちらを使用しますが、セットアップが面倒であれば、OCI の Data Science(Oracle マネージドの Jupyter Notebook 環境)を使用するとサクッと試すことができます。
単一の画像に対する処理
以下のように API から扱うことが可能です。(Object Storage に格納したイメージを参照しています)
import oci
config = oci.config.from_file()
ai_vision_client = oci.ai_vision.AIServiceVisionClient(config)
analyze_image_response = ai_vision_client.analyze_image(
analyze_image_details=oci.ai_vision.models.AnalyzeImageDetails(
features=[
oci.ai_vision.models.ImageClassificationFeature(
feature_type="IMAGE_CLASSIFICATION",
)
],
image=oci.ai_vision.models.ObjectStorageImageDetails(
source="OBJECT_STORAGE",
namespace_name="<object-storage-namespace>",
bucket_name="<object-storage-bucket-name>",
object_name="<image-name>"
),
compartment_id="compartment-id"
)
)
print(analyze_image_response.data)
結果は以下のよう。
レスポンス
{
"errors": [],
"image_classification_model_version": "1.4.41",
"image_objects": null,
"image_text": null,
"labels": [
{
"confidence": 0.98626745,
"name": "Bird"
},
{
"confidence": 0.920809,
"name": "Water"
},
{
"confidence": 0.8393242,
"name": "Duck"
},
{
"confidence": 0.82022226,
"name": "Lake"
},
{
"confidence": 0.73093736,
"name": "Goose"
}
],
"object_detection_model_version": null,
"ontology_classes": [
{
"name": "Water",
"parent_names": [],
"synonym_names": []
},
{
"name": "Goose",
"parent_names": ["Poultry"],
"synonym_names": []
},
{
"name": "Bird",
"parent_names": ["Vertebrate"],
"synonym_names": []
},
{
"name": "Duck",
"parent_names": ["Poultry"],
"synonym_names": []
},
{
"name": "Lake",
"parent_names": ["Water", "Nature"],
"synonym_names": []
},
{
"name": "Nature",
"parent_names": [],
"synonym_names": []
},
{
"name": "Poultry",
"parent_names": ["Fowl"],
"synonym_names": []
},
{
"name": "Vertebrate",
"parent_names": ["Animal"],
"synonym_names": []
},
{
"name": "Animal",
"parent_names": [],
"synonym_names": []
},
{
"name": "Fowl",
"parent_names": ["Bird"],
"synonym_names": []
}
],
"text_detection_model_version": null
}
複数枚の画像に対するバッチ処理
アーカイブされたメディアを扱う場合など、リアルタイム性は必要ないが多くの画像を対象に分析を実行したい事もあると思います。そのようなユースケースに対応するため、Vision では非同期的に分析を行うための API も用意されています。実行例は以下のよう。
import oci
config = oci.config.from_file()
ai_vision_client = oci.ai_vision.AIServiceVisionClient(config)
analyze_image_batch_response = ai_vision_client.create_image_job(
create_image_job_details=oci.ai_vision.models.CreateImageJobDetails(
features=[
oci.ai_vision.models.ImageClassificationFeature(
feature_type="IMAGE_CLASSIFICATION",
)
],
input_location=oci.ai_vision.models.ObjectListInlineInputLocation(
source_type="OBJECT_LIST_INLINE_INPUT_LOCATION",
object_locations=[
oci.ai_vision.models.ObjectLocation(
namespace_name="<object-storage-namespace>",
bucket_name="<object-storage-bucket-name>",
object_name="<image-name>"
),
oci.ai_vision.models.ObjectLocation(
namespace_name="<object-storage-namespace>",
bucket_name="<object-storage-bucket-name>",
object_name="<image-name>"
),
oci.ai_vision.models.ObjectLocation(
namespace_name="<object-storage-namespace>",
bucket_name="<object-storage-bucket-name>",
object_name="<image-name>"
)
]
),
output_location=oci.ai_vision.models.OutputLocation(
namespace_name="<object-storage-namespace>",
bucket_name="<object-storage-bucket-name>",
prefix="batch-processing/"
),
compartment_id=os.environ.get('C'),
display_name="BatchProcessing"
)
)
print(analyze_image_batch_response.data)
結果は以下のよう。(結果は、一部マスクしています)
レスポンス
{
"compartment_id": "ocid1.compartment.oc1...",
"display_name": "BatchProcessing",
"features": [
{
"feature_type": "IMAGE_CLASSIFICATION",
"max_results": null,
"model_id": null
}
],
"id": "ocid1.aivisionimagejob.oc1.ap-tokyo-1.amaaaaaa74akfsaa4q773wytoqxhtruyciykz62rlvw44avkg47n7y4al6mq",
"input_location": {
"object_locations": [
{
"bucket_name": "vision-test",
"namespace_name": "<object-storage-namespace>",
"object_name": "batch-test/image01.jpg"
},
{
"bucket_name": "vision-test",
"namespace_name": "<object-storage-namespace>",
"object_name": "batch-test/image02.jpg"
},
{
"bucket_name": "vision-test",
"namespace_name": "<object-storage-namespace>",
"object_name": "batch-test/image03.jpg"
}
],
"source_type": "OBJECT_LIST_INLINE_INPUT_LOCATION"
},
"is_zip_output_enabled": false,
"lifecycle_details": null,
"lifecycle_state": "ACCEPTED",
"output_location": {
"bucket_name": "vision-test",
"namespace_name": "<object-storage-namespace>",
"prefix": "batch-processing/"
},
"percent_complete": 0.0,
"time_accepted": "2022-02-20T07:58:45.353000+00:00",
"time_finished": null,
"time_started": null
}
実際の処理結果が出力されている Object Storage を確認してみると、以下のように各画像データに対する分析結果が JSON で格納されています。
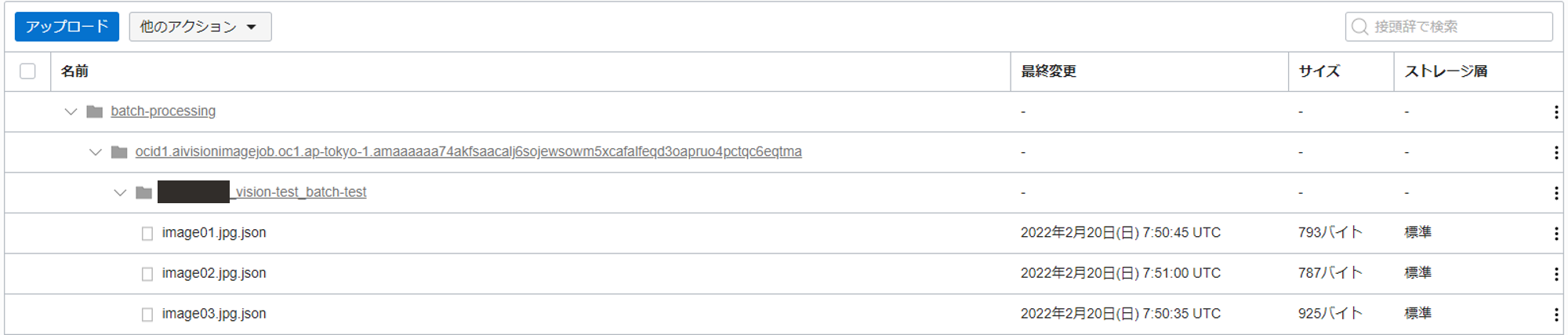
各、JSON は以下のような構造になっています。
{
"imageObjects": null,
"labels": [
{
"name": "Bird",
"confidence": 0.9922408
},
{
"name": "Animal",
"confidence": 0.8110203
},
{
"name": "Wing",
"confidence": 0.5649025
},
{
"name": "Sky",
"confidence": 0.53637326
},
{
"name": "Parrot",
"confidence": 0.5187305
}
],
"ontologyClasses": [
{
"name": "Sky",
"parentNames": ["Nature"],
"synonymNames": []
},
{
"name": "Wing",
"parentNames": [],
"synonymNames": []
},
{
"name": "Bird",
"parentNames": ["Vertebrate"],
"synonymNames": []
},
{
"name": "Animal",
"parentNames": [],
"synonymNames": []
},
{
"name": "Parrot",
"parentNames": ["Bird"],
"synonymNames": []
},
{
"name": "Nature",
"parentNames": [],
"synonymNames": []
},
{
"name": "Vertebrate",
"parentNames": ["Animal"],
"synonymNames": []
}
],
"imageText": null,
"imageClassificationModelVersion": "1.4.41",
"objectDetectionModelVersion": null,
"textDetectionModelVersion": null,
"errors": []
}
カスタム・モデルを使う
学習済みのモデルで対応できないようなユースケースに対応する場合、Vision サービスでは、Data Labeling と組み合わせてカスタム・モデルを作成することで対応が可能です。今回は、Kaggle 内で提供されている Creative Commons なデータセットを使って、Vision + Data Labeling (+Data Science) による画像分類を実施してみます。今回使用するデータセットは、Covid-19 Image Dataset です。データセットをダウンロードすると以下のような構成になっています。
.
├─test [テストに使用するデータセット]
│ ├─Covid [Covid-19 患者の肺のレントゲン写真]
│ ├─Normal [健常な患者の肺のレントゲン写真]
│ └─Viral Pneumonia [ウイルス性肝炎患者の肺のレントゲン写真]
└─train [学習に使用するデータセット]
├─Covid [Covid-19 患者の肺のレントゲン写真]
├─Normal [健常な患者の肺のレントゲン写真]
└─Viral Pneumonia [ウイルス性肝炎患者の肺のレントゲン写真]
データセットにラベル付けを行う
まずは、このデータセットを Object Storage に以下の構成で格納します。この後のラベル付けが大変なので、まずは各 10 枚ずつを格納することを推奨します。(その分、精度は微妙ですが)
.
├─covid-19-test-dataset [bucket name]
│ ├─Covid
│ ├─Normal
│ └─Viral Pneumonia
└─covid-19-train-dataset [bucket name]
├─Covid
├─Normal
└─Viral Pneumonia
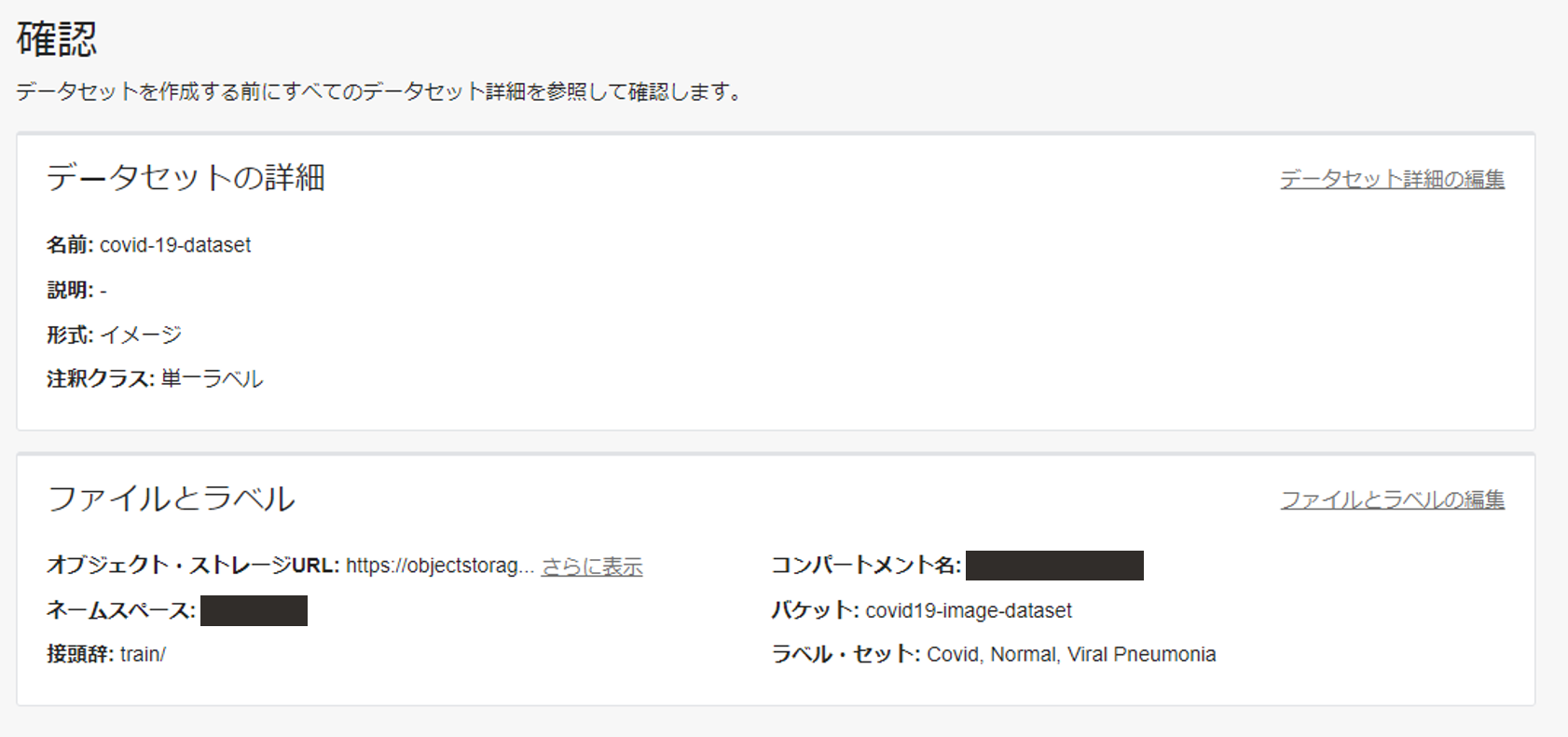
次に、Data Labeling のトップページから、データセットの作成を押し、以下のように入力し、データセットを作成します。
- 名前: covid-19-dataset
- データセット・フォーマット: イメージ
- 注釈クラス: 単一ラベル
- オブジェクト・ストレージから選択
- コンパートメント: 自身のコンパートメント
- バケット: covid19-image-train-dataset
- ラベル・セット: Covid19, Normal, Viral Pneumonia
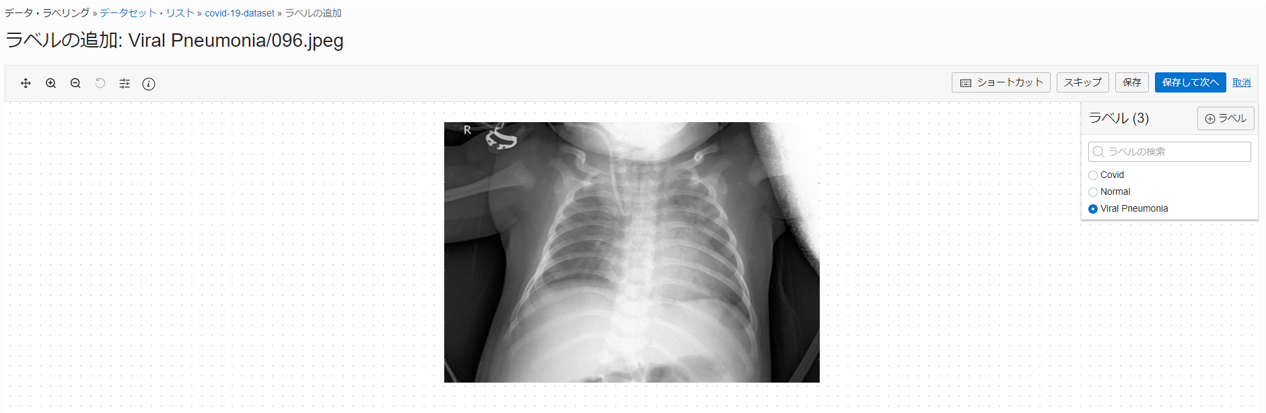
5 分程度経過するとデータ・レコードの生成が完了するので、Prefix を参照しながら気合でラベルを付けていきます。
こんな感じで黙々と...(レントゲン写真が苦手な方すみません)
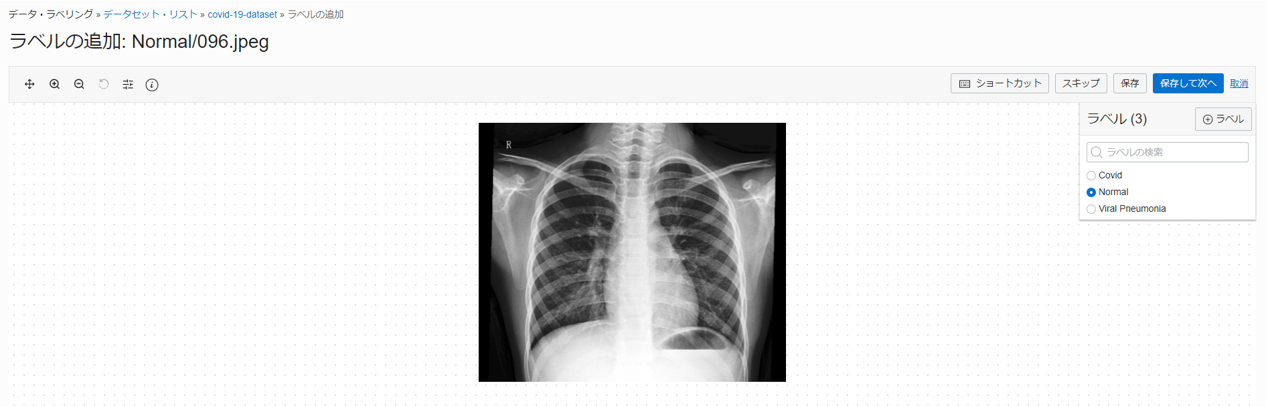
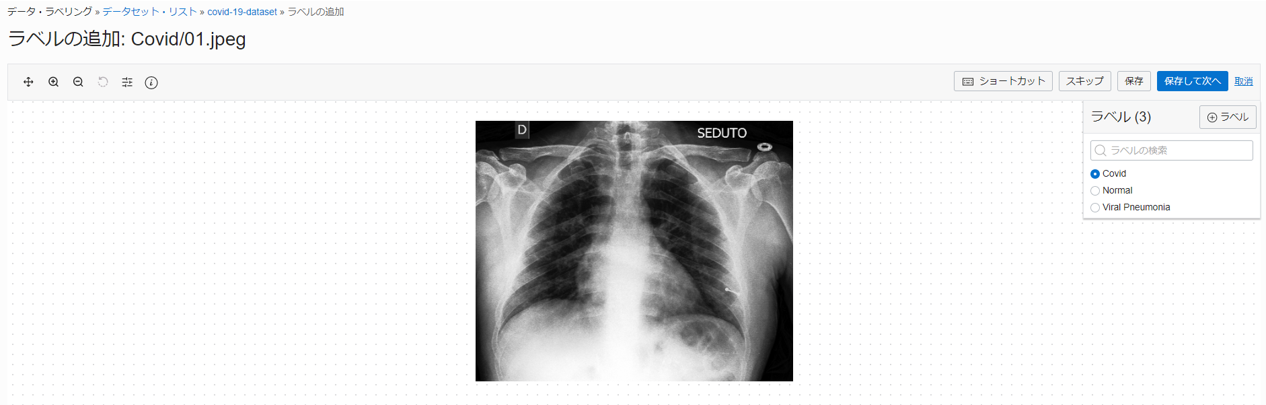
ラベル付けしたデータセットを使用してカスタム・モデルを構築する
前の手順で作成したデータセットを使用してカスタム・モデルを構築します。Vision のトップページから、プロジェクトを選択し、プロジェクトの作成をクリックします。
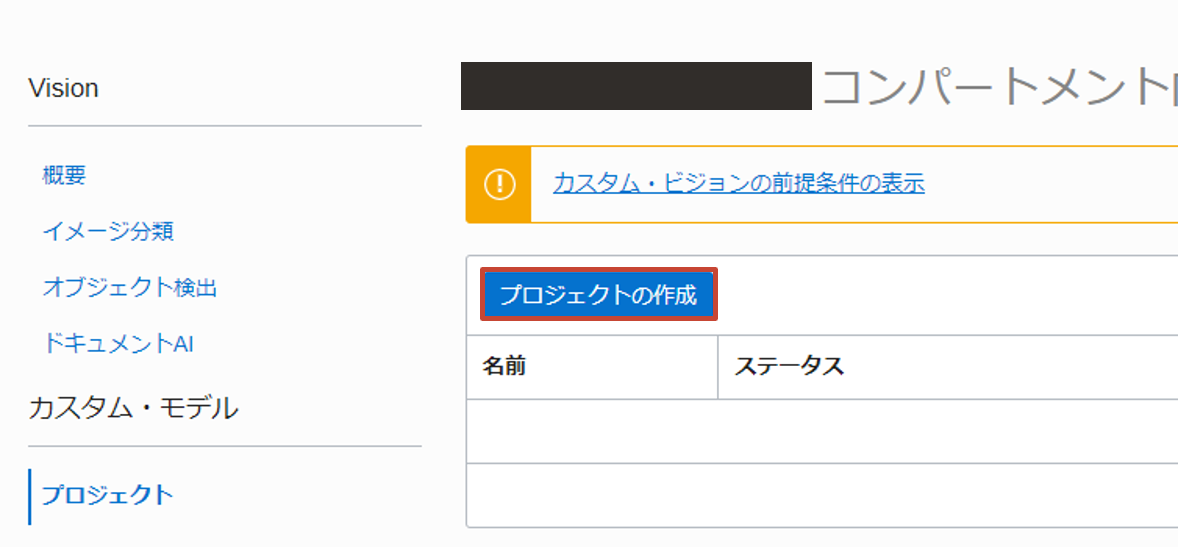
以下のように入力し、プロジェクトを作成します。
- 名前: covid-19-project
作成したプロジェクトの詳細画面で、モデルの作成をクリックし、以下のように入力します。
- タイプ: イメージ分類
- トレーニング・データ: 既存のデータセットの選択
- データソース: データ・ラベリング・サービス
- データセット: covid-19-dataset
- モデル表示名: covid-19-custom-model
- トレーニング期間: 推奨トレーニング
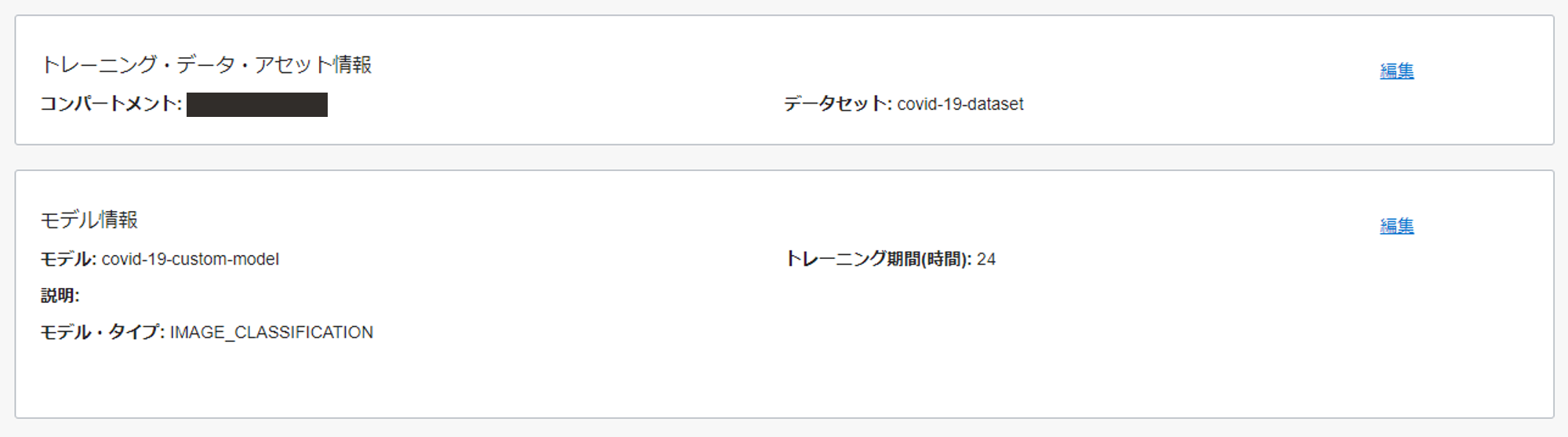
しばらく時間が経過すると、モデルの作成が完了します。(今回の量であれば、大体 15 分程度で完了すると思います)
作成したカスタム・モデルを OCI コンソールから使用する
作成したカスタム・モデルは学習済みモデルと同様に OCI コンソール、API から使用できます。まずは、OCI コンソールから扱ってみます。Vision のトップメニューからプロジェクトを選択します。
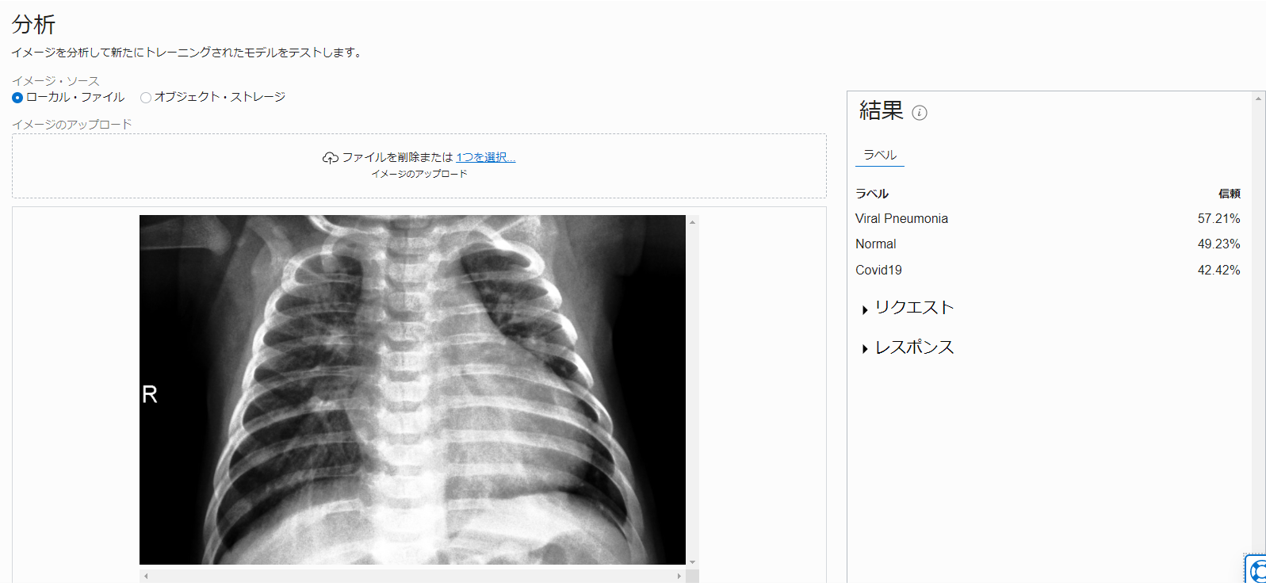
先ほど作成した covid-19-project に含まれる covid-19-custom-model を選択します。学習済みモデルと同様にローカル・ファイルのアップロード、オブジェクト・ストレージのアップロードの両方に対応しています。
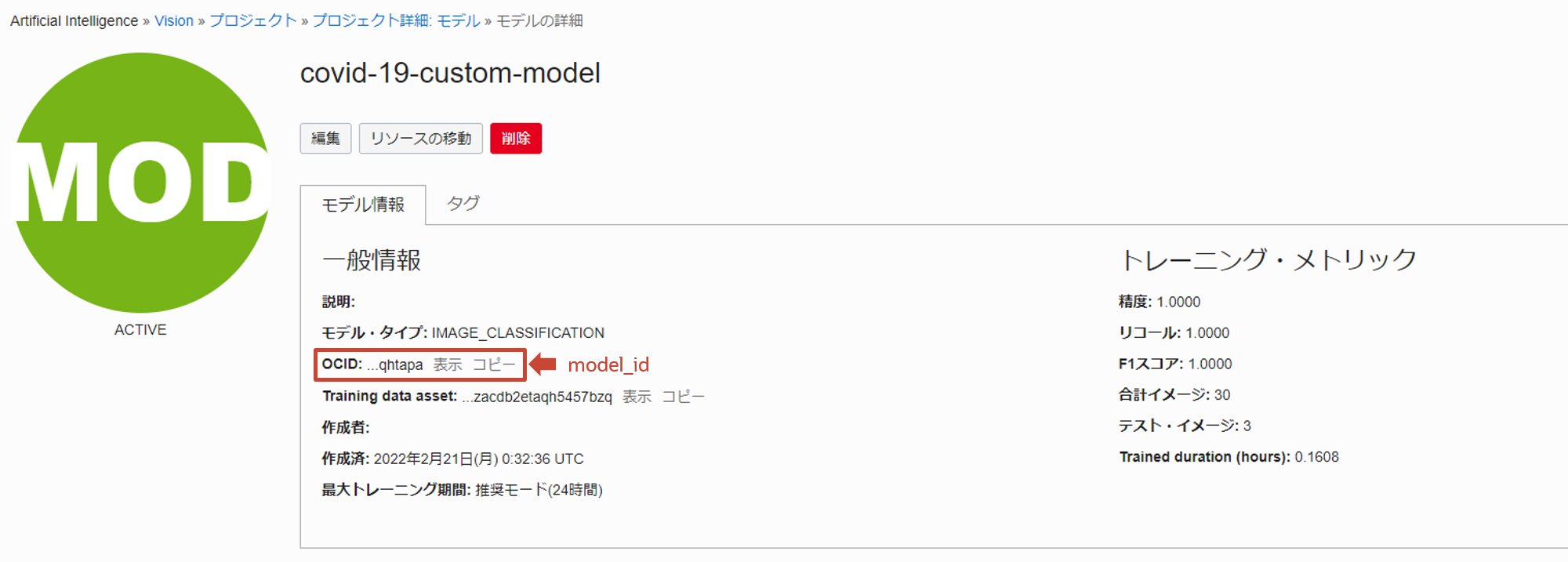
作成したカスタム・モデルを API から使用する
API から使用する場合も学習済みモデルで使用したコードとほとんど変わらないです。(model_idを指定する程度)model_id は作成したカスタムモデルの OCID となっています。
単一の画像に対する処理
import oci
config = oci.config.from_file()
ai_vision_client = oci.ai_vision.AIServiceVisionClient(config)
analyze_image_custom_response = ai_vision_client.analyze_image(
analyze_image_details=oci.ai_vision.models.AnalyzeImageDetails(
features=[
oci.ai_vision.models.ImageClassificationFeature(
feature_type="IMAGE_CLASSIFICATION",
model_id='ocid1.aivisionmodel.oc1.ap-tokyo-1.amaaaaaassl65iqadxzi5yvbkos2f6dqgwi5zswuyod2jasw6ygxvqqhtapa'
)
],
image=oci.ai_vision.models.ObjectStorageImageDetails(
source="OBJECT_STORAGE",
namespace_name="<object-storage-namespace>",
bucket_name="covid-19-test-dataset",
object_name="Viral Pneumonia/0101.jpeg"
),
compartment_id='<compartment-id>'
)
)
print(analyze_image_custom_response.data)
結果は以下のよう。
レスポンス
{
"errors": [],
"image_classification_model_version": "version",
"image_objects": null,
"image_text": null,
"labels": [
{
"confidence": 0.568884,
"name": "Viral Pneumonia"
},
{
"confidence": 0.47569844,
"name": "Normal"
},
{
"confidence": 0.46878126,
"name": "Covid19"
}
],
"object_detection_model_version": null,
"ontology_classes": [
{
"name": "Viral Pneumonia",
"parent_names": [],
"synonym_names": []
},
{
"name": "Covid19",
"parent_names": [],
"synonym_names": []
},
{
"name": "Normal",
"parent_names": [],
"synonym_names": []
}
],
"text_detection_model_version": null
}
複数枚の画像に対するバッチ処理
import oci
import os
config = oci.config.from_file()
ai_vision_client = oci.ai_vision.AIServiceVisionClient(config)
analyze_image_batch_custom_response = ai_vision_client.create_image_job(
create_image_job_details=oci.ai_vision.models.CreateImageJobDetails(
features=[
oci.ai_vision.models.ImageClassificationFeature(
feature_type="IMAGE_CLASSIFICATION",
model_id='ocid1.aivisionmodel.oc1.ap-tokyo-1.amaaaaaassl65iqadxzi5yvbkos2f6dqgwi5zswuyod2jasw6ygxvqqhtapa'
)
],
input_location=oci.ai_vision.models.ObjectListInlineInputLocation(
source_type="OBJECT_LIST_INLINE_INPUT_LOCATION",
object_locations=[
oci.ai_vision.models.ObjectLocation(
namespace_name="<object-storage-namespace>",
bucket_name="covid-19-test-dataset",
object_name="Covid/0100.jpeg"
),
oci.ai_vision.models.ObjectLocation(
namespace_name="<object-storage-namespace>",
bucket_name="covid-19-test-dataset",
object_name="Normal/0101.jpeg"
),
oci.ai_vision.models.ObjectLocation(
namespace_name="<object-storage-namespace>",
bucket_name="covid-19-test-dataset",
object_name="Viral Pneumonia/0101.jpeg"
)
]
),
output_location=oci.ai_vision.models.OutputLocation(
namespace_name="<object-storage-namespace>",
bucket_name="covid-19-test-dataset",
prefix="custom-batch-processing/"
),
compartment_id="<compartment-id>",
display_name="BatchProcessing"
)
)
print(analyze_image_batch_custom_response.data)
結果は以下のよう。(一部マスクしています)
レスポンス
{
"compartment_id": "ocid1.compartment.oc1...",
"display_name": "BatchProcessing",
"features": [
{
"feature_type": "IMAGE_CLASSIFICATION",
"max_results": null,
"model_id": "ocid1.aivisionmodel.oc1.ap-tokyo-1.amaaaaaassl65iqadxzi5yvbkos2f6dqgwi5zswuyod2jasw6ygxvqqhtapa"
}
],
"id": "ocid1.aivisionimagejob.oc1.ap-tokyo-1.amaaaaaa74akfsaa4xkkgfgyczrjly426komv4hckz5oywm3s7nxopokfajq",
"input_location": {
"object_locations": [
{
"bucket_name": "covid-19-test-dataset",
"namespace_name": "<object-storage-namespace>",
"object_name": "Covid/0100.jpeg"
},
{
"bucket_name": "covid-19-test-dataset",
"namespace_name": "<object-storage-namespace>",
"object_name": "Normal/0101.jpeg"
},
{
"bucket_name": "covid-19-test-dataset",
"namespace_name": "<object-storage-namespace>",
"object_name": "Viral Pneumonia/0101.jpeg"
}
],
"source_type": "OBJECT_LIST_INLINE_INPUT_LOCATION"
},
"is_zip_output_enabled": false,
"lifecycle_details": null,
"lifecycle_state": "ACCEPTED",
"output_location": {
"bucket_name": "covid-19-test-dataset",
"namespace_name": "<object-storage-namespace>",
"prefix": "custom-batch-processing/"
},
"percent_complete": 0.0,
"time_accepted": "2022-02-21T02:24:53.173000+00:00",
"time_finished": null,
"time_started": null
}
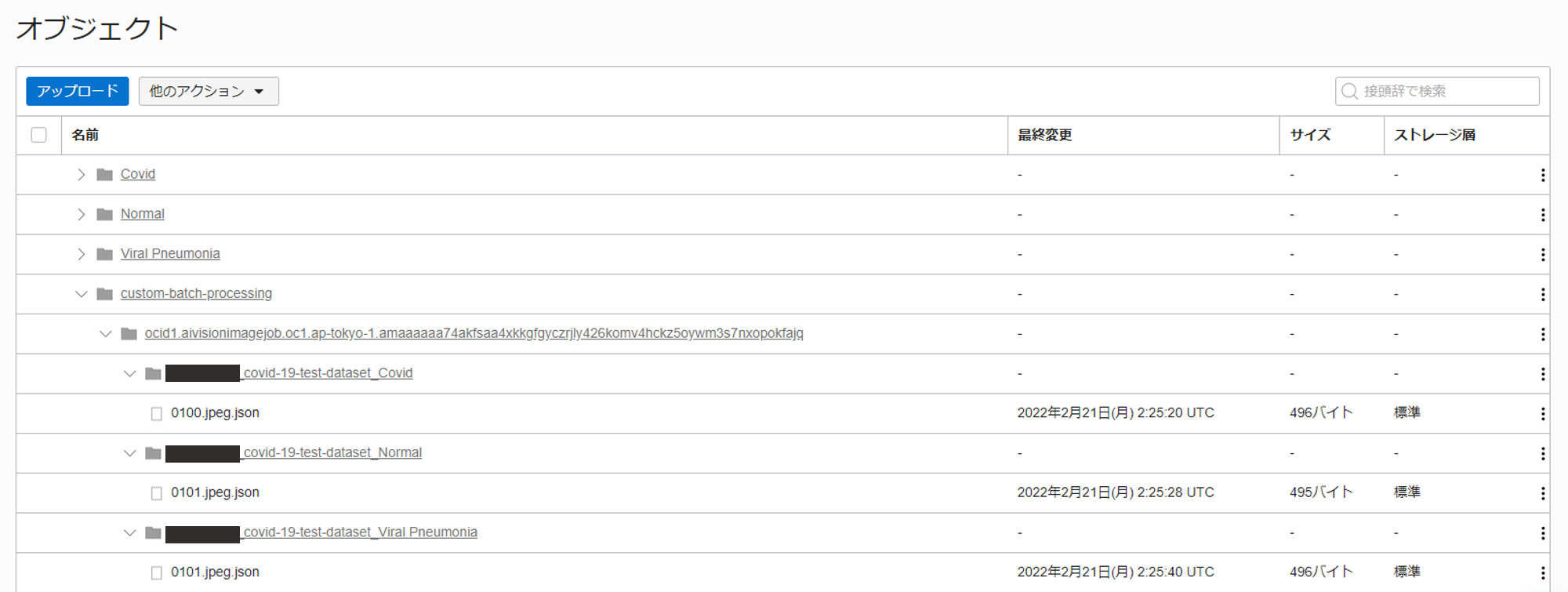
実際の処理結果が出力している Object Storage を確認してみると、以下のように各画像データに対する分析結果が JSON で格納されています。
終わりに
10 枚程度のラベル付きデータを元にしたカスタム・モデルだと流石に実用には耐えないと思いますが、もう少し枚数を増やすことでより精度の高いモデルを構築できると思います。
また、私のような AI や機械学習の初心者でもカスタム・モデルを作成するプロセスは直感的で分かりやすかったです。
今回使用したコードはこちらに格納してあります。
https://github.com/shukawam/sandbox/blob/master/oci/vision/vision.ipynb