はじめに
何も知らない状態から画像認識AIを作る連載の第2回です。前回は、AIの入力となる画像データの正体が「NumPyの数字の塊」であることを学びました。今回はそのデータを使ってAIのモデルを組み立て、学習させるまでの流れを解説します。
「TensorFlowとかKerasとか、名前が色々あってややこしい」「AIのコードの全体像が掴めない」という方でも理解できるよう、AI構築の4つのステップを順を追って説明していきます。
前回の記事
本記事のアジェンダ
- TensorFlowとKerasとは
- ディープラーニングの「ブロック(レイヤー)」たちを知ろう
- 【実践】世界一シンプルなAIを組み立てて特訓させてみる
環境
- Google Colabolatory (ランタイム:無料枠T4 GPU)
- Python 3.12.13
1. 下準備
コードを書く前に、Google Colabの設定を行います。AIの学習には、膨大な掛け算や割り算が必要なのでランタイムをGPUに切り替えてください。。
[設定手順]
Colabの上部メニューから「ランタイム」 > 「ランタイムのタイプを変更」 > 「T4 GPU」を選択して保存します。
2. TensorFlowとKerasとは
TensorFlow(テンソルフロー)とは:
Googleが開発したオープンソースの機械学習フレームワーク。ニューラルネットワークの構築・学習・実行を行うための基盤となるライブラリで、細かい処理まで柔軟に制御できます。
Keras(ケラス)とは:
TensorFlowの公式高レベルAPIで、現在はtf.kerasとしてTensorFlowに統合されています。複雑な処理をシンプルなコードで書けるよう設計されており、モデルの構築を直感的に行えるのが特徴です。
今回はシンプルなAIを構築するため、カスタム性の高いTensorFlowではなくKerasを使用します。
3. ディープラーニングの「ブロック(レイヤー)」たちを知ろう
AIの脳みそは、目的(画像・文章・音声など)に合わせて、色々な形をした「ブロック(専門用語でレイヤーと呼びます)」を積み重ねて作ります。今後の画像認識(CNN)でも絶対に登場する、代表的な4つのブロックを紹介します。
Conv2D(畳み込み層):
画像から「特徴」を見つけるブロック。画像にフィルターをかけて、縦の線・横の線・輪郭などの「特徴」を浮き彫りにするセンサーのようなブロック。
MaxPooling2D(プーリング層):
見つけた特徴をギュッと縮小するブロック。画像をあえてざっくり小さくすることで、位置のズレや細かい違いに強いAIになります。
Flatten(平坦化層):
形を整えて「最終判定」につなぐブロック。立体的な画像データを、1列の長い数字の並び(1次元)に変形するブロック。最後の判定ブロックへ繋ぐための前処理です。
Dense(全結合層):
AIの最も基本的な神経細胞(ニューロン)の塊。送られてきた数字を複雑に組み合わせて、「これは95%の確率で『カエル』だ!」と最終的な予測・判定を下します。
4. 【実践】シンプルなAIを組み立てて特訓させてみる
それでは実際に、Kerasを使ってシンプルなAIを作って、学習させてみましょう。今回は「1個の数字(X)を入力したら、それを2倍にして1を足した数字(Y = 2X + 1)」を自力で予測するAIを作ります。AI構築の流れは、次の4つのステップになります。
- Sequential() でAIの形(箱)を作る
まずは Sequential(順番に積み上げる)という入れ物を用意し、一番基本的なブロックである Dense を1つだけ入れます。
import tensorflow as tf
import numpy as np
# 一番シンプルなAIの形を定義
my_first_ai = tf.keras.models.Sequential([
# units=1 (出す数字は1つ), input_shape=[1] (入る数字も1つ)
tf.keras.layers.Dense(units=1, input_shape=[1])
])
- compile() で勉強のルールを決める
形ができたら、次は「このAIに、どういうルールで勉強させるか」を設定(コンパイル)します。ここでは「教師」と「間違いの指標」をセットします。
my_first_ai.compile(
optimizer="sgd", # 家庭教師:脳みそ(重み)を少しずつ修正していく設定
loss="mean_squared_error", # 間違いの指標:AIの解答が、正解とどれくらいズレているかを測る指標
)
- .fit() でデータを流し込んで特訓させる
データ(テンソル)をAIの中に流します。今回は、練習問題(X)と正解(Y)を渡し、「500周(epochs=500)」の特訓を課します。さらに、Matplotlibを使って、AIがどれくらい賢くなったか(間違いの大きさであるLossの減少)をグラフ化してみましょう。
import matplotlib.pyplot as plt
# 練習問題(X)と、その正解(Y)を用意(ルールは Y = 2X + 1)
X = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
Y = np.array([-1.0, 1.0, 3.0, 5.0, 7.0, 9.0], dtype=float)
# 500周の特訓(fit)を開始
history = my_first_ai.fit(X, Y, epochs=500, verbose=1)
# 特訓の記録(Lossの推移)をMatplotlibでグラフ化
plt.plot(history.history["loss"])
plt.title("Loss Reduction") # Lossの減少(AIの成長の記録)
plt.xlabel("Epochs") # エポック(学習の回数)
plt.ylabel("Loss") # 間違いの大きさ
plt.show()
print("500周の猛特訓が完了しました!AIがルールを学習しました。")
- 出力抜粋:
Epoch 1/500
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 43ms/step - loss: 1.0164e-05
Epoch 2/500
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 46ms/step - loss: 9.9545e-06
Epoch 3/500
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 42ms/step - loss: 9.7505e-06
Epoch 4/500
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 44ms/step - loss: 9.5499e-06
Epoch 5/500
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 45ms/step - loss: 9.3543e-06
...
Epoch 495/500
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 48ms/step - loss: 3.7502e-10
Epoch 496/500
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 49ms/step - loss: 3.6767e-10
Epoch 497/500
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 70ms/step - loss: 3.6165e-10
Epoch 498/500
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 52ms/step - loss: 3.5434e-10
Epoch 499/500
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 50ms/step - loss: 3.4846e-10
Epoch 500/500
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 52ms/step - loss: 3.4141e-10
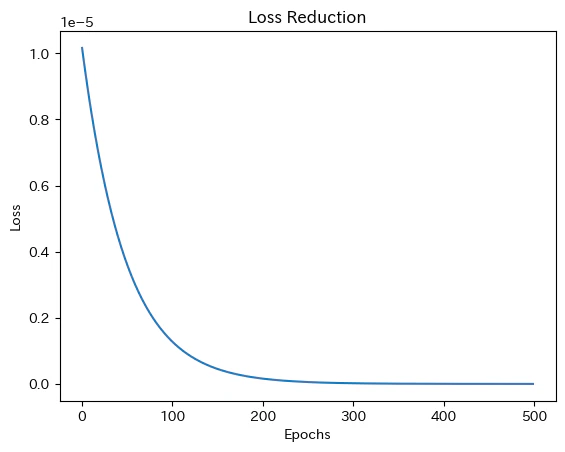
実行すると、最初は大きかった loss の数字が、回数を重ねるごとにどんどん小さくなっていく様子がリアルタイムで見られます。グラフでも、綺麗にLossが右肩下がりにゼロへ向かっていくのが分かります!
- .predict() で未知の問題を予測させる
学習が終わったAIに、教えていない新しい問題を出してみましょう。「x が 10.0 のとき、 y は何になる?」と質問(predict)します(正解は 10 × 2 + 1 = 21 になるはずです)。
# predict =「予測する」という命令
result = my_first_ai.predict(np.array([[10.0]]))
print("AIの予測結果:", result)
出力結果: AIの予測結果: [[21.000055]]
AIは数式(Y = 2X + 1)を人間から教えられたわけではなく、500回の特訓の中でデータだけを見て、自力でこの法則を学習し、ほぼ「21」という正解を導き出しました!
「AIの予測結果:」の出力
※出力が「21」ぴったりではなく「21.000021」となっているのは、AIが学習を通じて重みを調整する際に、完全に一致する値を出すのが難しいためです。これは「学習誤差」と呼ばれ、実際のAIではごくわずかなズレが生じることが一般的です。
TensorFlow入門のまとめ
今回の流れをまとめると以下の4ステップになります。
-
Sequential()でレイヤーを積み上げてモデルの構造を定義する -
compile()で学習のルール(最適化関数・損失関数)を設定する -
.fit()でデータを使ってモデルを学習させる -
.predict()で未知のデータに対して予測を行う
画像認識AI(CNN)になっても、基本のステップはすべて今回と同じです。
次回(第3回)は、いよいよ今回学んだConv2D・MaxPooling2D・Flatten・Denseを組み合わせて、カラー画像を分類する画像認識AI(CNN)を実装します。
参考文献