はじめに
2025/04/10 Google Cloud Next 2025 で A2A というプロトコルが発表されました。
このプロトコルは、AI エージェント同士のコミュニケーションプロトコルとして考案されたものです。現在は、AI 関連のプロトコルといえば、MCP が有名ですがマルチエージェントな利用が提案される昨今において、A2A のようなプロトコルの必要性が増すのではと思います。
この記事では、以前に私が投稿した「マルチモーダルずんだもんとペアプロを試みた」で作成したシステムに対し、A2A を導入した紹介と、躓いたポイントなどを紹介します。
前回の記事: https://qiita.com/shuji-k/items/16f88ad1a0b0b7503fbc
A2A の概要
仕様が生まれて日が浅いため、気づいたら仕様が生えるので、ここではざっくり話をします。
細かい仕様は公式サイトをご参照ください。
公式サイト: https://a2a-protocol.org/latest/
A2A の立ち位置
A2A は、あくまでもエージェント同士の通信を主眼に置いています。このため、他アプリケーションとの通信は MCP に任せる、という住み分けをしています。
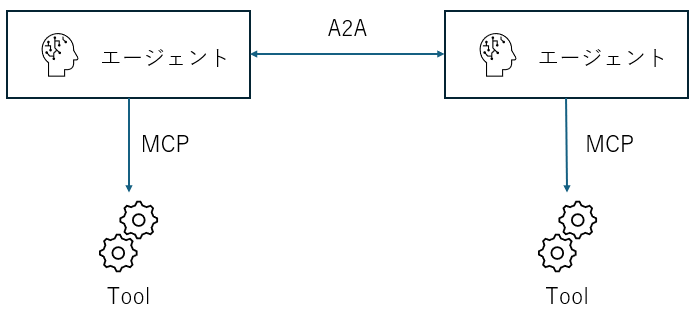
A2A のパケット
以下の転送プロトコルをベースにして、A2A のパケットを乗せる形をとっています。私が実装をし始めてから増えててびっくりしました。
- JSON-RPC 2.0 (今回採用)
- gRPC
- HTTP REST
A2A のシーケンス
上記のベースプロトコルに則る形ですが、クライアントからの要求応答や Service-Sent Events によるストリーム応答などがあります。今回は、SSE を使ってずんだもん音声を生成しながら音声出力する方法を実現したいと思います。
バックエンド実装
構成
構成は以下のような形です。認証に Entra ID を使っているため、認証用の API Proxy を使っています。
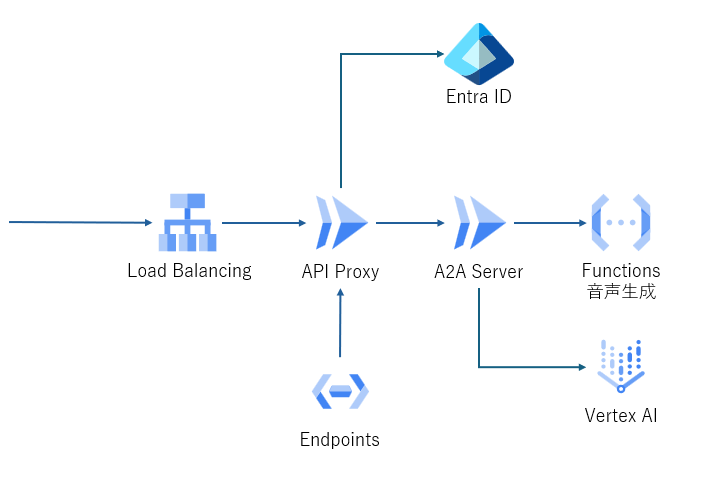
A2A SDK
バックエンドは、公式が python 用の SDK を公開しているため、そちらを使用します。
PyPI a2a-adk: https://pypi.org/project/a2a-sdk/
公式も実装サンプルがあるので、至れり尽くせりですね。
実装イメージ
モジュール構成は、おおよそ3層構造になっています。
- main: サーバ起動を責務とする
- agent_executor: リクエスト受付、応答を責務とする
- agent: エージェントの実処理を責務とする
サンプルを見ると分かりますが、A2A のプロトコルのキモは agent_executor を見ると良いです。
おおよそ、RequestContext オブジェクトにリクエストメッセージが入り、適時ステータス処理をして、EventQueue オブジェクトに応答メッセージを追加する形です。
SSE を実現するには、処理が終わり次第 EventQueue に結果をどんどん追加していけば、良いことが分かります。そこで、本エージェントは、クライアントから依頼された説明文を要約し、それをずんだもん音声で応答してくれるエージェントとします。ずんだもん音声は句読点で分割し、Functions で並列生成すれば応答速度が速くなると目論見ました。
分かりやすいサンプル(travel planner agent): https://github.com/a2aproject/a2a-samples/blob/main/samples/python/agents/travel_planner_agent/agent_executor.py
フロントエンド実装
前回から、大きく変えたのは、以下の2点です。
-
エージェントを2つに分け、画像からコメントをするエージェントと、ずんだもん要約エージェントの2つ通信するようにする
-
SSE 応答に対応して、順次音声を結合する
Javascript 向け A2A SDK もあります。至れり尽くせりですね。
ただ今回はクライアントクラスを使うことができず、メッセージ型クラスを活用するにとどまりました。理由は後述します。
ポイント
asyncio.queue
SSEでストリーム応答しているはずなのに、なぜか応答は全てのメッセージが送られまで受信できないという現象に見舞われました。その原因その1が asyncio.queue です。
バックエンド側 EventQueue の内部において、キューは asyncio.queue で管理されています。enq と deq でスレッドを分離することで、エージェントの生成と応答を疎結合にする狙いでしょうか。asyncio は、python で非同期処理を実現するための便利な公式パッケージです。これに含まれる queue も便利で、get() メソッドでキューに要素が追加することを待つことができます。
しかし、キューに要素が追加されたとして、待ちスレッドはいつ復帰するのでしょうか? 普通のスレッド管理であれば Functions の応答待ちでコンテキストスイッチが入ってもおかしくありません。しかし、実際には Functions 待ち状態でもスレッドは切り替わりませんでした。
そこで、queue に対して、全て deq されるまで待つという join() 関数を使ってみたところ、無事にストリーム応答するようになりました。
async def queueing(task: a2a.types.TaskStatusUpdateEvent | a2a.types.TaskArtifactUpdateEvent):
await event_queue.enqueue_event(task)
await event_queue.queue.join()
Cloud Endpoints
SSEでストリーム応答できない原因その2が Google Cloud API Gateway です。
Google Cloud で API を公開する場合に API Gateway は有用です。今回のように、外部の IdP として定義する場合に、定義ファイルを作成するだけで認証させることができます。
ただし、API Gateway はレスポンスサイズが規定されており、Stream 応答はサポートされていません。
このため、Cloud Run による ESPv2 プロキシサーバ + Cloud Endpoints を使って、API 管理を行います。
EventSource vs Fetch API
ブラウザで SSE を受信するために EventSource クラスが用意されています。
しかし、EventSource は送信ヘッダなどを指定することができません。今回は、Authorization ヘッダを付けた通信をするために、やむなく Fetch API を使って実装することにしました。
private request_stream(url: string, request: SendStreamingMessageRequest): Observable<SendStreamingMessageSuccessResponse> {
return new Observable<SendStreamingMessageSuccessResponse>((sub) => {
(async () => {
const headers = {
'Content-Type': 'application/json',
...await this.create_authorization_header()
};
const res = await fetch(url, {
headers: headers,
method: 'POST',
body: JSON.stringify(request),
});
const reader = res.body.getReader();
const decoder = new TextDecoder("utf-8");
try {
let buffer = "";
while (true) {
const { done, value } = await reader.read();
if (done) {
break;
}
const text = decoder.decode(value);
// 以下パケット解析処理 (省略)
}
finally {
reader.releaseLock();
}
sub.complete();
})();
});
}
と、ここで改めて Javascript 版 a2a-sdk を確認したところ、最新版の 0.3.3 では、fetch 処理をオプションで変更でき、ヘッダ追加可能になっているようです。今後皆様は、そちらをご利用ください。
おわりに
自身で Web ブラウザからエージェントに対しマルチモーダルや、文脈をもったコミュニケーションを取ろうとすると、そのプロトコル作成は手間だと以前の実装をする際に感じたところです。A2A はそういった意味で、エージェント開発を十分に助けるプロトコルだなと思いました。