はじめに
AI による Copilot プログラミングが盛り上がっている昨今、課題として「新人エンジニアをいかに育てるか」が、挙がっております。
私もここ10年ほど教育に携わることがあり、未経験者を教育する難しさを感じるところがあります。
そこで、Copilot ではなく、Pair の方向で AI を活用できないかと考え、マルチモーダルな AI を使ったペアプロサービスを実現してみました。
この記事では、サービスを作るにあたって得られたいくつかの知見を紹介したいと思います。
全体像
やってみたい事としては、以下の通りです。
- プログラミング画面をスキャンして、アドバイスしてくれる
- 音声入力したい
- ずんだもんのような、キャラクターがペアの方が面白い
Google Cloud Vertex AI は、画像や音声、テキストを同時に投入して、チャットできるマルチモーダル AI です。この仕組みを使って、実現してみましょう。今回は、以下の様な構成になります。
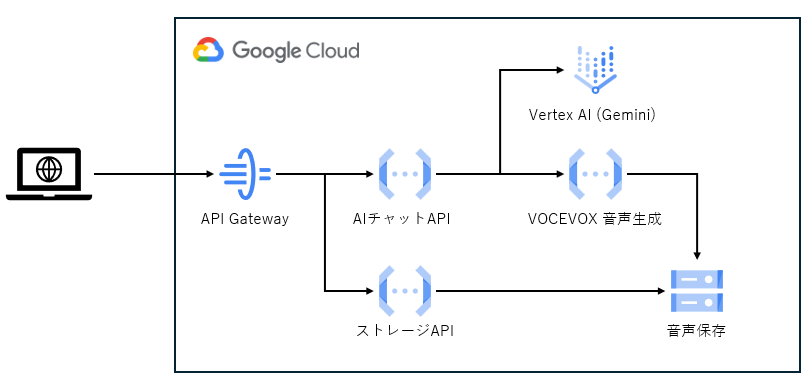
環境
フロントエンド: TypeScript (Angular v19.1.5)
バックエンド: Python v3.12
マルチモーダル AI への入力
GenerativeModel クラスを見ると分かるのですが、generate_content に投入できるチャット内容は ContentsType 型で定義されています。
この、ContentsType は Union 定義されております。
ContentsType = Union[
List["Content"],
List[ContentDict],
str,
"Image",
"Part",
List[Union[str, "Image", "Part"]],
]
このうち、最後のList["Part"] が、マルチモーダルを実現する定義です。
Part クラスを見ると、MIME を指定して様々なメディアを読み込ませることができます。
そこで、ブラウザ側でスクリーンショットと音声を取得し、multipart/form-data でバックエンドに送れば、実現可能だと分かります。
ずんだもんの音声生成の実現
ずんだもんに任意のテキストをしゃべってもらうには、VOICEVOX を利用するのが良いです。
VOICE VOX は GUI で音声生成するのですが、これをプログラムから呼びだす方法は色々あります。
今回は、Google Cloud 上で実現したかったため、VOICEVOX CORE を利用しました。
python と C++ をサポートしているため今回の環境に対して僥倖。
ただし、Google Cloud の FaaS 上で動作させるため、ライブラリの動的読み込みなどを実装しないといけない点がやや手間です。
ディレクトリ構成
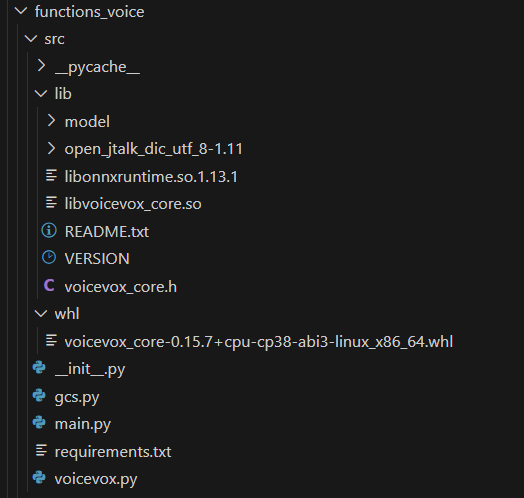
requirements.txt にローカルの whl を追加
./whl/voicevox_core-0.15.7+cpu-cp38-abi3-linux_x86_64.whl
他必要なパッケージ
ライブラリの手動読み込み
import ctypes
import pathlib
import os
_root_path = os.path.dirname(os.path.abspath(__file__))
# ライブラリの読み込み
ctypes.cdll.LoadLibrary(f"{_root_path}/lib/libonnxruntime.so.1.13.1")
ctypes.cdll.LoadLibrary(f"{_root_path}/lib/libvoicevox_core.so")
# 辞書ファイルを指定して初期化
import voicevox_core as vcore
_core = vcore.VoicevoxCore(open_jtalk_dict_dir=pathlib.Path(f"{_root_path}/lib/open_jtalk_dic_utf_8-1.11"))
# ずんだもんノーマル
_speaker_id = 3
if not _core.is_model_loaded(_speaker_id):
_core.load_model(_speaker_id)
def create_voice(text: str) -> bytes:
return _core.tts(text, _speaker_id)
フロントエンド
スクリーンショットの取得
まだ実験的な部分がありますが、ブラウザで画面キャプチャがサポートされています。
ScreenCaptureAPIを使って、画面映像の取得と画像生成をしてみましょう。
/** キャプチャオプション */
private displayMediaOptions: DisplayMediaStreamOptions = {
video: true,
audio: false,
};
/** 開始ボタン押下 */
public async pressed_start(el: HTMLVideoElement) {
el.srcObject = await navigator.mediaDevices.getDisplayMedia(this.displayMediaOptions);
}
関数一つで、スクリーンキャプチャが開始されることに驚きました。また、画面全体のキャプチャから、ウインドウを選択してキャプチャするなど、かなりブラウザ側で実装されているようです。
それでは、スクリーンショット取得側の実装は以下の通りです。
VideoElement の内容を CanvasElement で描くという手法で画像を取得します。
/** スクショボタン押下 */
public pressed_ss(v: HTMLVideoElement, c: HTMLCanvasElement) {
if (!v.srcObject) {
return;
}
c.width = v.clientWidth;
c.height = v.clientHeight;
const context = c.getContext("2d");
context.drawImage(v, 0, 0, c.width, c.height);
const mime = 'image/png';
c.toBlob(async (blob) => {
if (!blob) {
throw Error('blob is null')
}
const file = blob as Blob;
}, mime);
}
上記以外に、映像のフレームを直接取得する方法もあるようですが、実験段階のようなので、今回は上記の手法を採用しました。
音声の取得
音声は、スクリーンショットより難しくなく、getUserMedia() で取得開始したのち、requestData() にて要求すると ondataavailable() コールバックが呼ばれてデータを取得する、という流れです。
private voice_recoder: MediaRecorder | null = null;
public async start_voice_rec(audio: HTMLAudioElement, dl: HTMLAnchorElement) {
const stream = await navigator.mediaDevices.getUserMedia({
audio: true
});
this.voice_recoder = new MediaRecorder(stream, { mimeType: "audio/mp4" });
this.voice_recoder.ondataavailable = (ev: BlobEvent) => {
audio.src = URL.createObjectURL(ev.data);
dl.href = URL.createObjectURL(ev.data);
dl.download = "audio.m4a";
dl.click();
};
this.voice_recoder.start();
}
public async stop_voice_rec() {
if (this.voice_recoder) {
this.voice_recoder.stop();
this.voice_recoder.requestData();
}
}
今回は、AI に音声を食わせるため chrome でサポートされているm4a形式で取得しています。ブラウザによってエンコード可能な形式は変わると思うので、MediaRecorder.isTypeSupported() メソッドで調査すると良いです。
おわりに
作ったサービスは、以下のようにデュアルディスプレイを前提にし、エディタ用の画面とチャット用の画面を表示しながら、プログラミングを行うことを想定しています。
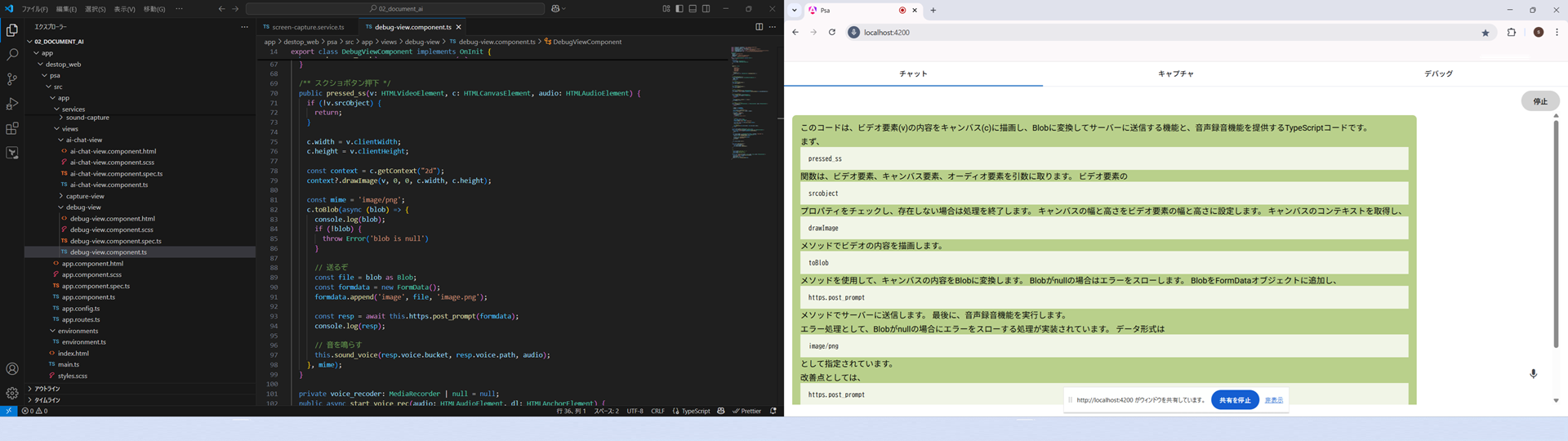
試しに、サンプルコードを「レビューしてみて」とお願いしてみた結果になります。
意外にも左側のエクスプローラなど、コードに不要な情報が多いながらも、ちゃんとコード部分を OCR されてコメントしており、驚きました。
レビュー結果はコードの解説が多く、最後の方で型の指摘やエラー処理の実装を促す程度のコメントを出す程度でした。
レビュー用のプロンプトをマルチモーダルに投入できれば、もう少しマシになるかもしれません。
また、新人教育目的なら、コード解説に特化するだけでも使いどころがあるように思います。