先日 TensorFlow 研究会に発表者として行ってきました.
周りの人に勉強会の内容何か書かないのかと言われたのですが, 人数にビビって誰も喜ばなさそうな発表をしてしまったので, 代わりにここでは元々使う予定だった没ネタを消費しておきます.
目標
やりたいことはタイトルの通りとても単純です.
ポケモンの名前を入力したら種族値とタイプっぽいものが出てきて欲しいです.
Twitter の診断メーカーとかでありがちなやつを, もうちょい真面目にやってみる感じですね.
モデルの設計
入力の詳細
ポケモンの名前を 1 文字ごとに分解して, 各文字の出現回数と 2-gram を特徴量として使用しました.
例えばデデンネの場合は以下のようになります.
{
デ: 2, ン: 1, ネ: 1,
デデ: 1, デン: 1, ンネ: 1
}
n-gram の特徴量を作るのは自力でやると面倒なのですが scikit-learn の Vectorizer を使用すると 2, 3 行で細かい設定もしつつ n-gram 特徴量ができるわ必要な情報が一通り格納された vectorizer を簡単に保存できるわで, ウルトラスーパーミラクルおすすめです.
来世に備えて徳を積まなければならないとか, 特殊な事情が無い限りは絶対使った方が良いです.
出力の詳細
出力はちょっと面倒で, 大きく分けて以下の 3 つを出力しなければなりません.
- 種族値
- HP, 攻撃, 防御, 特攻, 特防, 素早さ, の 6 つの連続値 (回帰問題)
- タイプ 1
- 18 種類のカテゴリ (分類問題)
- タイプ 2
- 「無し」も含めた 19 種類のカテゴリ (分類問題)
それぞれ別々にモデルを立てて予測しても良いのですが, 何でもまとめて詰め込める柔軟性がニューラルネットの強み (だと個人的には思っている) ので, 全部を 1 つのネットワークに突っ込んでみました.
つまりこういうことです.
最後の層のユニット数は 6 + 18 + 19 個です.
種族値に相当する部分はそれをそのまま出力とし, 二乗誤差で損失を定義しました.
タイプに相当する部分は 18 or 19 個ずつでそれぞれ softmax に突っ込んだものを出力とし, 損失はそれぞれの cross entropy で定義しました.
最終的な目的関数はこれらの損失の重み付き足し合わせです.
データ収集
別に極秘データではないので, 頑張れば集まります. 頑張ってください.
使った分のデータだけ,コードと一緒に GitHub に上げておいた.
出来上がったコード
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.externals import joblib
from sklearn.feature_extraction import DictVectorizer
def inference(x_placeholder, n_in, n_hidden1, n_hidden2):
"""
Description
-----------
Forward step which build graph.
Parameters
----------
x_placeholder: Placeholder for feature vectors
n_in: Number of units in input layer which is dimension of feature
n_hidden1: Number of units in hidden layer 1
n_hidden2: Number of units in hidden layer 2
Returns
-------
y_bs: Output tensor of predicted values for base stats
y_type1: Output tensor of predicted values for type 1
y_type2: Output tensor of predicted values for type 2
"""
# Hidden1
with tf.name_scope('hidden1') as scope:
weights = tf.Variable(
tf.truncated_normal([n_in, n_hidden1]),
name='weights'
)
biases = tf.Variable(tf.zeros([n_hidden1]))
hidden1 = tf.nn.sigmoid(tf.matmul(x_placeholder, weights) + biases)
# Hidden2
with tf.name_scope('hidden2') as scope:
weights = tf.Variable(
tf.truncated_normal([n_hidden1, n_hidden2]),
name='weights'
)
biases = tf.Variable(tf.zeros([n_hidden2]))
hidden2 = tf.nn.sigmoid(tf.matmul(hidden1, weights) + biases)
# Output layer for base stats
with tf.name_scope('output_base_stats') as scope:
weights = tf.Variable(
tf.truncated_normal([n_hidden2, 6]),
name='weights'
)
biases = tf.Variable(tf.zeros([6]))
y_bs = tf.matmul(hidden2, weights) + biases
# Output layer for type1
with tf.name_scope('output_type1') as scope:
weights = tf.Variable(
tf.truncated_normal([n_hidden2, 18]),
name='weights'
)
biases = tf.Variable(tf.zeros([18]))
# y_type1 = tf.nn.softmax(tf.matmul(hidden2, weights) + biases)
y_type1 = tf.matmul(hidden2, weights) + biases
# Output layer for type2
with tf.name_scope('output_type2') as scope:
weights = tf.Variable(
tf.truncated_normal([n_hidden2, 19]),
name='weights'
)
biases = tf.Variable(tf.zeros([19]))
y_type2 = tf.matmul(hidden2, weights) + biases
# y_type2 = tf.nn.softmax(tf.matmul(hidden2, weights) + biases)
return [y_bs, y_type1, y_type2]
def build_loss_bs(y_bs, t_ph_bs):
"""
Parameters
----------
y_bs: Output tensor of predicted values for base stats
t_ph_bs: Placeholder for base stats
Returns
-------
Loss tensor which includes placeholder of features and labels
"""
loss_bs = tf.reduce_mean(tf.nn.l2_loss(t_ph_bs - y_bs), name='LossBaseStats')
return loss_bs
def build_loss_type1(y_type1, t_ph_type1):
"""
Parameters
----------
y_type1: Output tensor of predicted values for base stats
t_ph_type1: Placeholder for base stats
Returns
-------
Loss tensor which includes placeholder of features and labels
"""
loss_type1 = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(y_type1, t_ph_type1),
name='LossType1'
)
return loss_type1
def build_loss_type2(y_type2, t_ph_type2):
"""
Parameters
----------
y_type2: Output tensor of predicted values for base stats
t_ph_type2: Placeholder for base stats
Returns
-------
Loss tensor which includes placeholder of features and labels
"""
loss_type2 = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(y_type2, t_ph_type2),
name='LossType2'
)
return loss_type2
def build_optimizer(loss, step_size):
"""
Parameters
----------
loss: Tensor of objective value to be minimized
step_size: Step size for gradient descent
Returns
-------
Operation of optimization
"""
optimizer = tf.train.GradientDescentOptimizer(step_size)
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = optimizer.minimize(loss, global_step=global_step)
return train_op
if __name__ == '__main__':
# Set seed
tf.set_random_seed(0)
# Load data set and extract features
df = pd.read_csv('data/poke_selected.csv')
# Fill nulls in type2
df.loc[df.type2.isnull(), 'type2'] = '無'
# Vectorize pokemon name
pokename_vectorizer = CountVectorizer(analyzer='char', min_df=1, ngram_range=(1, 2))
x = pokename_vectorizer.fit_transform(list(df['name_jp'])).toarray()
t_bs = np.array(df[['hp', 'attack', 'block', 'contact', 'defense', 'speed']])
# Vectorize pokemon type1
poketype1_vectorizer = DictVectorizer(sparse=False)
d = df[['type1']].to_dict('record')
t_type1 = poketype1_vectorizer.fit_transform(d)
# Vectorize pokemon type2
poketype2_vectorizer = DictVectorizer(sparse=False)
d = df[['type2']].to_dict('record')
t_type2 = poketype2_vectorizer.fit_transform(d)
# Placeholders
x_ph = tf.placeholder(dtype=tf.float32)
t_ph_bs = tf.placeholder(dtype=tf.float32)
t_ph_type1 = tf.placeholder(dtype=tf.float32)
t_ph_type2 = tf.placeholder(dtype=tf.float32)
# build graph, loss, and optimizer
y_bs, y_type1, y_type2 = inference(x_ph, n_in=1403, n_hidden1=512, n_hidden2=256)
loss_bs = build_loss_bs(y_bs, t_ph_bs)
loss_type1 = build_loss_type1(y_type1, t_ph_type1)
loss_type2 = build_loss_type2(y_type2, t_ph_type2)
loss = tf.add_n([1e-4 * loss_bs, loss_type1, loss_type2], name='ObjectiveFunction')
optim = build_optimizer(loss, 1e-1)
# Create session
sess = tf.Session()
# Initialize variables
init = tf.initialize_all_variables()
sess.run(init)
# Create summary writer and saver
summary_writer = tf.train.SummaryWriter('log', graph_def=sess.graph_def)
tf.scalar_summary(loss.op.name, loss)
tf.scalar_summary(loss_bs.op.name, loss_bs)
tf.scalar_summary(loss_type1.op.name, loss_type1)
tf.scalar_summary(loss_type2.op.name, loss_type2)
summary_op = tf.merge_all_summaries()
saver = tf.train.Saver()
# Run optimization
for i in range(1500):
# Choose indices for mini batch update
ind = np.random.choice(802, 802)
batch_xs = x[ind]
batch_ts_bs = t_bs[ind]
batch_ts_type1 = t_type1[ind]
batch_ts_type2 = t_type2[ind]
# Create feed dict
fd = {
x_ph: batch_xs,
t_ph_bs: batch_ts_bs,
t_ph_type1: batch_ts_type1,
t_ph_type2: batch_ts_type2
}
# Run optimizer and update variables
sess.run(optim, feed_dict=fd)
# Show information and write summary in every n steps
if i % 100 == 99:
# Show num of epoch
print 'Epoch:', i + 1, 'Mini-Batch Loss:', sess.run(loss, feed_dict=fd)
# Write summary and save checkpoint
summary_str = sess.run(summary_op, feed_dict=fd)
summary_writer.add_summary(summary_str, i)
name_model_file = 'model_lmd1e-4_epoch_' + str(i+1) + '.ckpt'
save_path = saver.save(sess, 'model/tensorflow/'+name_model_file)
else:
name_model_file = 'model_lmd1e-4_epoch_' + str(i+1) + '.ckpt'
save_path = saver.save(sess, 'model/tensorflow/'+name_model_file)
# Show example
poke_name = 'サンダー'
v = pokename_vectorizer.transform([poke_name]).toarray()
pred_bs = sess.run(y_bs, feed_dict={x_ph: v})
pred_type1 = np.argmax(sess.run(y_type1, feed_dict={x_ph: v}))
pred_type2 = np.argmax(sess.run(y_type2, feed_dict={x_ph: v}))
print poke_name
print pred_bs
print pred_type1, pred_type2
print poketype1_vectorizer.get_feature_names()[pred_type1]
print poketype2_vectorizer.get_feature_names()[pred_type2]
# Save vectorizer of scikit-learn
joblib.dump(pokename_vectorizer, 'model/sklearn/pokemon-name-vectorizer')
joblib.dump(poketype1_vectorizer, 'model/sklearn/pokemon-type1-vectorizer')
joblib.dump(poketype2_vectorizer, 'model/sklearn/pokemon-type2-vectorizer')
学習させてみる
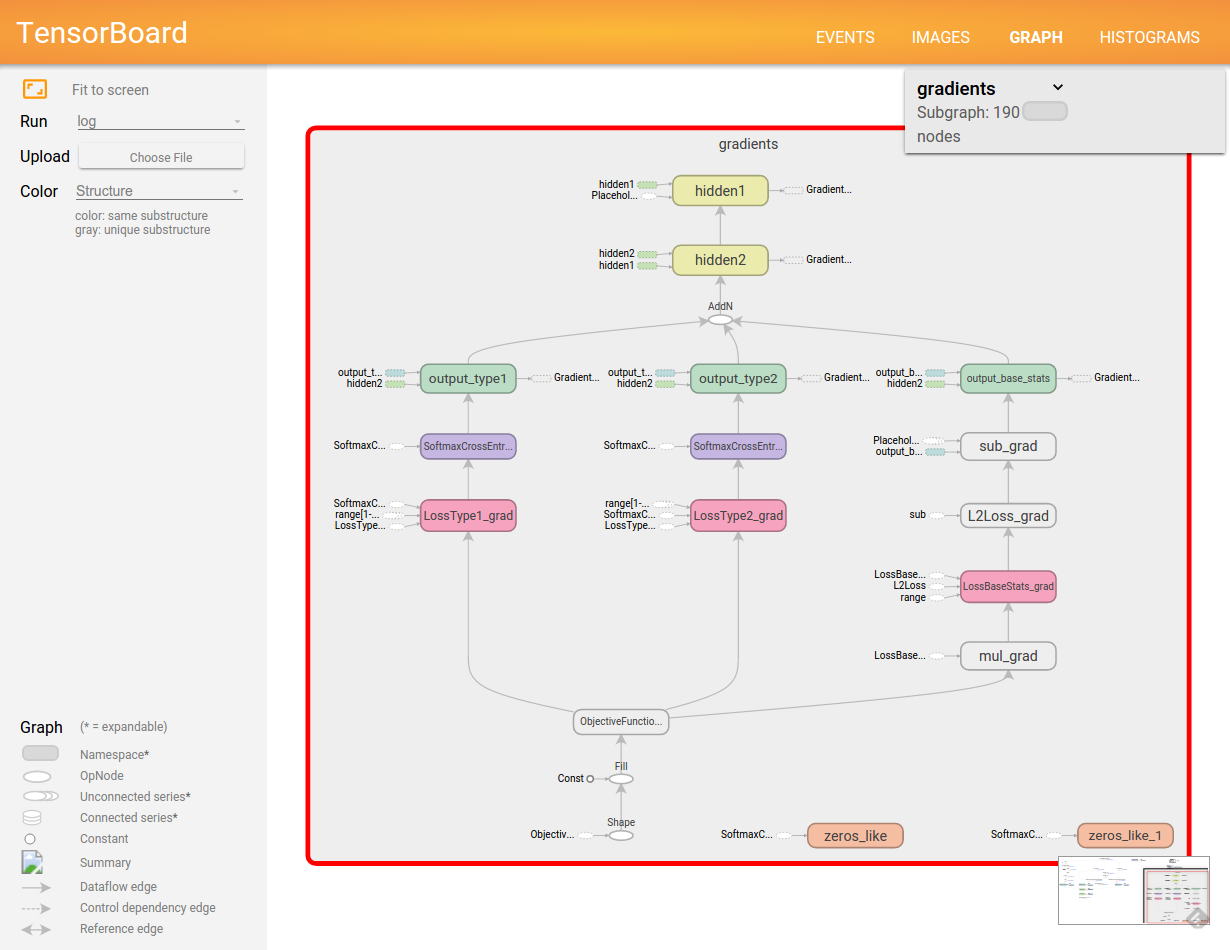
ネタがネタなだけに真面目にチューニングしたらどうなるというわけでもないので, 最低限タイプに関する損失と種族値に関する損失がバランス良く減っているかどうか確認するために TensorBoard を眺めていただけです.
遊んでみる
こんな感じでモデルを読み込んで遊んでみます.
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.externals import joblib
import pn2bs
# Placeholder
x_ph = tf.placeholder(dtype=tf.float32)
t_ph = tf.placeholder(dtype=tf.float32)
y_bs, y_type1, y_type2 = pn2bs.inference(x_ph, n_in=1403, n_hidden1=512, n_hidden2=256)
# Create session
sess = tf.Session()
# Load TensorFlow model
saver = tf.train.Saver()
saver.restore(sess, "model/tensorflow/model_lmd1e-4_epoch_1500.ckpt")
# Load vectorizer of scikit-learn
pokename_vectorizer = joblib.load("model/sklearn/pokemon-name-vectorizer")
poketype1_vectorizer = joblib.load("model/sklearn/pokemon-type1-vectorizer")
poketype2_vectorizer = joblib.load("model/sklearn/pokemon-type2-vectorizer")
poke_name = 'ゴンザレス'
v = pokename_vectorizer.transform([poke_name]).toarray()
pred_bs = sess.run(y_bs, feed_dict={x_ph: v})
pred_type1 = np.argmax(sess.run(y_type1, feed_dict={x_ph: v}))
pred_type2 = np.argmax(sess.run(y_type2, feed_dict={x_ph: v}))
result = {
'name' : poke_name,
'hp' : pred_bs[0][0],
'attack' : pred_bs[0][1],
'block' : pred_bs[0][2],
'contact': pred_bs[0][3],
'defense': pred_bs[0][4],
'speed' : pred_bs[0][5],
'type1' : poketype1_vectorizer.get_feature_names()[pred_type1],
'type2' : poketype2_vectorizer.get_feature_names()[pred_type2],
}
print result['name']
print result['hp']
print result['attack']
print result['block']
print result['contact']
print result['defense']
print result['speed']
print result['type1']
print result['type2']
結果の例です.
特に言うことはありませんが, 各々何かを察してください.
| Name | H | A | B | C | D | S | Type 1 | Type 2 |
|---|---|---|---|---|---|---|---|---|
| テンソルフロー | 92 | 102 | 84 | 85 | 65 | 73 | フェアリー | 悪 |
| メガピカチュウ | 74 | 80 | 50 | 97 | 85 | 80 | 電気 | 無 |
| ゴンザレス | 81 | 103 | 107 | 86 | 103 | 65 | ドラゴン | 電気 |
| メガゴンザレス | 100 | 137 | 131 | 118 | 117 | 103 | ドラゴン | 悪 |
今後の課題 (取り組むとは言っていない)
- 今の設定だとタイプ 1: 水, タイプ 2: 水, などの意味不明なポケモンが誕生する可能性がある
- 2-gram をカウントするとき BOS, EOS も 1 文字と見做して使った方が良いかも
- Dropout の存在忘れてた
まとめ
ニューラルネットは凸性とか関数の良い性質を全力でドブに投げ捨てた分, モデリングの柔軟性がすごいなーと思いました.
例えば SVM で同じことをやろうとすると, まず種族値のような多次元の出力を求められた時点でどうしようかなと立ち止まることになるだろうし, ましてやついでにタイプに関する分類問題も一緒に解いてくれなどと言われた日には, 寝言は寝て言えよという気持ちになります.
とは言えニューラルネットに 9 回裏 2 アウトの打席を任せられるかというと, うーんという感じ.
そんな感じ.
追記
2016-01-26
今でも時々ストックしてくれている人がいるのにまともに試せる状態で公開していないのは少し申し訳ない気がしてきたので、一応動くものを GitHub に上げておいた.
入力された名前に応じて Google Charts か何かでレーダーチャートとか出したら格好良いと思ったけど,bot に叩かせて遊びたかったので Web API にした.
使ってみると多分バレると思うから先に白状しておくと,既存のポケモンを入れたときに実際と全然違うステータスになると萎えるので,わざと過学習気味のモデルを採用している.