Flowとは
GenStageのWrapper.
普段コレクションを操作する時に使うEnumっぽいインターフェースなので親しみやすい.
YoutubeにElixir作者のJoséの解説が上がっている.
https://www.youtube.com/watch?v=srtMWzyqdp8&feature=youtu.be&t=244
GenStageとは
コレクションをlazyかつ並列分散処理出来るElixirのbehaviour.
AkkaのBack-Pressureなどに影響された.
Back-Pressureとは
要求ドリブン(demand-driven)でデータの生成主体(producer), 消費主体(consumer)間で、cosumerの要求に従ってproducerがデータを渡すことでデータの流量を調節する仕組み。ConsumerはFlowを使うことでstageとして並列に並べられ、適切にproducerからデータが渡される。
Usage
インストール
依存に追加する
mix.exs
{:flow, "~> 0.12"}
$ mix deps.get
※追記: GenStageとFlowは標準ライブラリにせずに別プロジェクトで開発を続けるとJoséが宣言しているので今後も依存への追加が必要です
Example
例) 1から1000000のリストのそれぞれの値を2倍にする、という処理をFlowでやると以下のようになる
1..10000000
|> Flow.from_enumerable
|> Flow.map(& &1 * 2)
|> Enum.to_list
|> Enum.sort
※解説
-
1..100000001〜10000000までのリストを作成 -
Flow.from_enumerable与えられたEnumerableなデータをproducerとしてFlowのStructを作成
iex> 1..10000000 |> Flow.from_enumerable()
%Flow{operations: [], options: [stages: 8],
producers: {:enumerables, [1..10000000]},
window: %Flow.Window.Global{periodically: [], trigger: nil}}
-
Flow.map(& &1 * 2)それぞれのリストの値を2倍にする.
iex> 1..10000000 |> Flow.from_enumerable(stages: 8) |> Flow.map(& &1 * 2)
%Flow{operations: [{:mapper, :map,
[#Function<6.87737649/1 in :erl_eval.expr/5>]}], options: [stages: 8],
producers: {:enumerables, [1..10000000]},
window: %Flow.Window.Global{periodically: [], trigger: nil}}
-
Enum.to_listここでlazyに評価 -
Enum.sortそれぞれのstageのデータをmerge後はリスト内の順番が保証されないので一応ソート
Consumerが一度に要求するデータ量を制限する場合はFlow.from_enumerable/2にmax_demandオプションを渡す.
Flow.from_enumerable(max_demand: 1000)
ベンチマーク
Flowはstageを複数並列に並べることで並列処理を可能にしているのでstage数の違いにより差が生まれるか確認してみる.
Flow.enumerable/2のオプションとしてstagesを指定するとstage数を指定出来る.ちなみにオプションを指定しない場合のデフォルトのstage数はSystem.schedulers_online()の値.
環境
- CPU: Intel® Core™ i7-3770 CPU @ 3.40GHz × 8
CPUバウンドな処理
以下のようなCPUバウンドな処理をstage数を1〜32の間で変化させて処理時間に変化があるか確認してみる
1..10000000
|> Flow.from_enumerable(stages: 1)
|> Flow.map(& &1 * 2)
|> Enum.to_list
※1000万件のリストを受け取りそれぞれの値を2倍にする
stages: 1
iex> :timer.tc(fn -> \
1..10000000 \
|> Flow.from_enumerable(stages: 1) \
|> Flow.map(& &1 * 2) \
|> Enum.to_list end) \
|> elem(0) \
|> Kernel./(1000000)
13.325468
※単位は秒
stages: 2
iex> :timer.tc(fn -> \
1..10000000 \
|> Flow.from_enumerable(stages: 2) \
|> Flow.map(& &1 * 2) \
|> Enum.to_list end) \
|> elem(0) \
|> Kernel./(1000000)
6.988174
stages: 4
iex> :timer.tc(fn -> \
1..10000000 \
|> Flow.from_enumerable(stages: 4) \
|> Flow.map(& &1 * 2) \
|> Enum.to_list end) \
|> elem(0) \
|> Kernel./(1000000)
3.833715
stages: 8
iex(78)> :timer.tc(fn -> \
1..10000000 \
|> Flow.from_enumerable(stages: 8) \
|> Flow.map(& &1 * 2) \
|> Enum.to_list end) \
|> elem(0) \
|> Kernel./(1000000)
2.848776
stages: 16
iex> :timer.tc(fn -> \
1..10000000 \
|> Flow.from_enumerable(stages: 16) \
|> Flow.map(& &1 * 2) \
|> Enum.to_list end) \
|> elem(0) \
|> Kernel./(1000000)
2.748695
stages: 32
iex> :timer.tc(fn -> \
1..10000000 \
|> Flow.from_enumerable(stages: 32) \
|> Flow.map(& &1 * 2) \
|> Enum.to_list end) \
|> elem(0) \
|> Kernel./(1000000)
2.78359
結果
概ね期待通りの結果になった。stage数が1の時は逐次処理と変わらないのでEnumで逐次処理した時とあまり変わらない.
以下はEnumでリストを逐次処理した場合.
stage数が1の時とほぼ同じ処理時間になる.
iex> :timer.tc(fn -> \
1..10000000 \
|> Enum.map(& &1 * 2) end) \
|> elem(0) \
|> Kernel./(1000000)
12.479895
Core i7 3770kのスレッド数は8なのでstageを8以上に増やしても大して結果に変化がなくちゃんとCPUを使い切っているのが分かる.
IOバウンドな処理
基本的にCPUバウンドな処理ではCPUのスレッド数=System.schedulers_online()で取得出来る値が最適なstage数にはなるがIOバウンドな処理の場合はstage数を増やすとより良い結果を得られる、と公式ドキュメントに書いてあったので試してみる.
データ
https://github.com/arangodb/example-datasets/blob/master/RandomUsers/names_10000.json
のサンプルの1万件のJSONをパースしてファーストネームのカウントをする、という処理をする.
IOバウンドにするため上のファイルを64個用意して64万件のデータにする.
基本的に一つの巨大なファイルからストリームを並列に読み込むことは出来ず、FlowやBEAMの利点を生かせないので実運用で集計処理をする場合もファイルの粒度を細かくして並列度を上げるといい.
$ mkdir files
$ for i in `seq 1 64`; do cp names_10000.json files names_10000_$i.json; done
Flow.from_enumerables/2に渡すためFileストリームのリストを作る
iex(1)> streams = for file <- File.ls!("files") do
...(1)> File.stream!("files/#{file}", read_ahead: 100_000)
...(1)> end
stages: 4
iex> :timer.tc(fn -> \
streams \
|> Flow.from_enumerables(stages: 4) \
|> Flow.map(&Poison.decode!/1) \
|> Flow.map(& &1["name"]["first"]) \
|> Flow.partition \
|> Flow.reduce(fn -> %{} end, fn name, acc -> Map.update(acc, name, 1, & &1 + 1) end) \
|> Enum.sort(fn {_, count1}, {_, count2} -> count1 >= count2 end) end) \
|> elem(0) \
|> Kernel./(1000000)
9.474862
stages: 8
iex> :timer.tc(fn -> \
streams \
|> Flow.from_enumerables(stages: 8) \
|> Flow.map(&Poison.decode!/1) \
|> Flow.map(& &1["name"]["first"]) \
|> Flow.partition \
|> Flow.reduce(fn -> %{} end, fn name, acc -> Map.update(acc, name, 1, & &1 + 1) end) \
|> Enum.sort(fn {_, count1}, {_, count2} -> count1 >= count2 end) end) \
|> elem(0) \
|> Kernel./(1000000)
9.887758
stages: 16
iex> :timer.tc(fn -> \
streams \
|> Flow.from_enumerables(stages: 16) \
|> Flow.map(&Poison.decode!/1) \
|> Flow.map(& &1["name"]["first"]) \
|> Flow.partition \
|> Flow.reduce(fn -> %{} end, fn name, acc -> Map.update(acc, name, 1, & &1 + 1) end) \
|> Enum.sort(fn {_, count1}, {_, count2} -> count1 >= count2 end) end) \
|> elem(0) \
|> Kernel./(1000000)
9.282843
stages: 32
iex> :timer.tc(fn -> \
streams \
|> Flow.from_enumerables(stages: 32) \
|> Flow.map(&Poison.decode!/1) \
|> Flow.map(& &1["name"]["first"]) \
|> Flow.partition \
|> Flow.reduce(fn -> %{} end, fn name, acc -> Map.update(acc, name, 1, & &1 + 1) end) \
|> Enum.sort(fn {_, count1}, {_, count2} -> count1 >= count2 end) end) \
|> elem(0) \
|> Kernel./(1000000)
9.389618
stages: 64
iex> :timer.tc(fn -> \
streams \
|> Flow.from_enumerables(stages: 64) \
|> Flow.map(&Poison.decode!/1) \
|> Flow.map(& &1["name"]["first"]) \
|> Flow.partition \
|> Flow.reduce(fn -> %{} end, fn name, acc -> Map.update(acc, name, 1, & &1 + 1) end) \
|> Enum.sort(fn {_, count1}, {_, count2} -> count1 >= count2 end) end) \
|> elem(0) \
|> Kernel./(1000000)
6.912277
stages: 128
iex> :timer.tc(fn -> \
streams \
|> Flow.from_enumerables(stages: 128) \
|> Flow.map(&Poison.decode!/1) \
|> Flow.map(& &1["name"]["first"]) \
|> Flow.partition \
|> Flow.reduce(fn -> %{} end, fn name, acc -> Map.update(acc, name, 1, & &1 + 1) end) \
|> Enum.sort(fn {_, count1}, {_, count2} -> count1 >= count2 end) end) \
|> elem(0) \
|> Kernel./(1000000)
6.730907
stages: 256
iex> :timer.tc(fn -> \
streams \
|> Flow.from_enumerables(stages: 256) \
|> Flow.map(&Poison.decode!/1) \
|> Flow.map(& &1["name"]["first"]) \
|> Flow.partition \
|> Flow.reduce(fn -> %{} end, fn name, acc -> Map.update(acc, name, 1, & &1 + 1) end) \
|> Enum.sort(fn {_, count1}, {_, count2} -> count1 >= count2 end) end) \
|> elem(0) \
|> Kernel./(1000000)
7.590904
結果
入力元のIOと同じ数以上のstageがある時に性能が良くなった.
stage数が多すぎるとオーバーヘッドになるのか逆に遅くなることもあった.
partitioning
最初のベンチマークではデータの重複を考慮しないでやったので問題ないけど, 集計処理などでデータの重複など考慮しないといけない場合は上記のベンチマークでやったようにFlow.partition/1を使うとうまく処理出来る.
Flow.partition/1をするとpartitionというstageが新たに作成され、同じデータはハッシュ関数により同じstageにルーティングされて処理されることが保証される.
イメージとしてはproducerとconsumerの間に新しくルーティング用のstageが追加され、そこから適切なstageに向けてデータがdispatchされるという感じ.
なぜ別のstageで同じデータが個別にカウントされるのが困るのかというと、Flowでの処理が終わった後個別にカウントされたstage間のデータを更に同一のキーにまとめなければいけないため、そこの処理は逐次処理になってしまうから.
ちなみにpartitioningを入れるとデータのハッシュ化とDispatchにより処理時間が増えるので集計処理じゃない場合とか重複を考慮しないでいい場合は使わないでよさそう.
# partitionngなし
iex> :timer.tc(fn -> 1..10000000 |> Flow.from_enumerable(stages: 8) |> Flow.map(& &1 * 2) |> Enum.to_list end) |> elem(0) |> Kernel./(1000000)
2.770232
# partitioningあり
iex> :timer.tc(fn -> 1..10000000 |> Flow.from_enumerable(stages: 8) |> Flow.partition |> Flow.map(& &1 * 2) |> Enum.to_list end) |> elem(0) |> Kernel./(1000000)
4.742253
Task.async_stream, Enumとの比較
同じような処理をFlowとTask.async_stream/4, Enumでの逐次処理でどう違うのかobserverで見てみる
1..1000000
|> Enum.each(& IO.inspect &1)
1000万件の数字のリストをIO.inspect/1でコンソールに出力する処理をそれぞれEnum, Task.async_stream, Flowで書いて確認する
Enum版
iex(47)> :timer.tc(fn -> 1..1000000 |> Enum.each(& IO.inspect &1) end) |> elem(0) |> Kernel./(1000000)
...中略...
12.517052
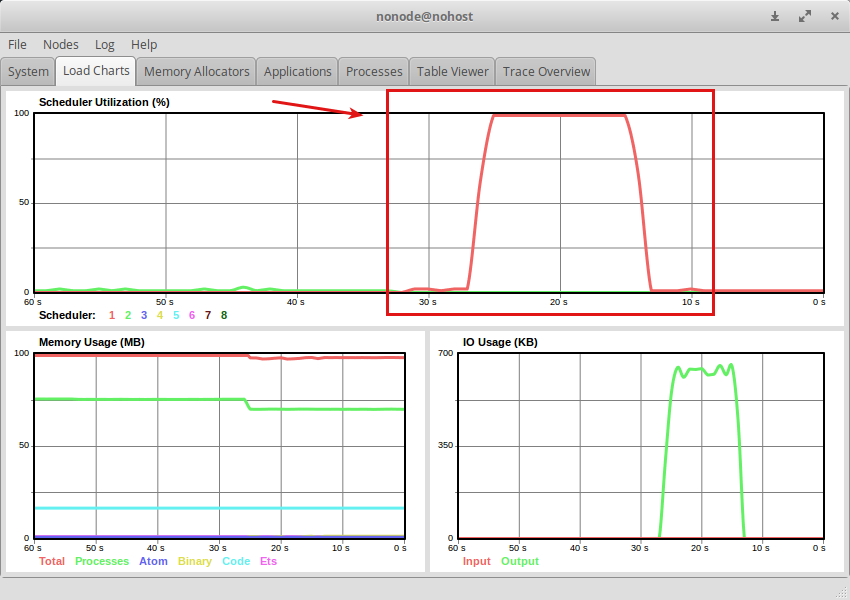
Enumは1つのスケジューラーのみ使っていてシングルスレッドで回していることが分かる.
このスレッドがボトルネックになりそうなことは簡単に想像がつく.
Task.async_stream版
iex> :timer.tc(fn -> 1..1000000 |> Task.async_stream(IO, :inspect, []) |> Enum.to_list end) |> elem(0) |> Kernel./(1000000)
...中略...
16.709609
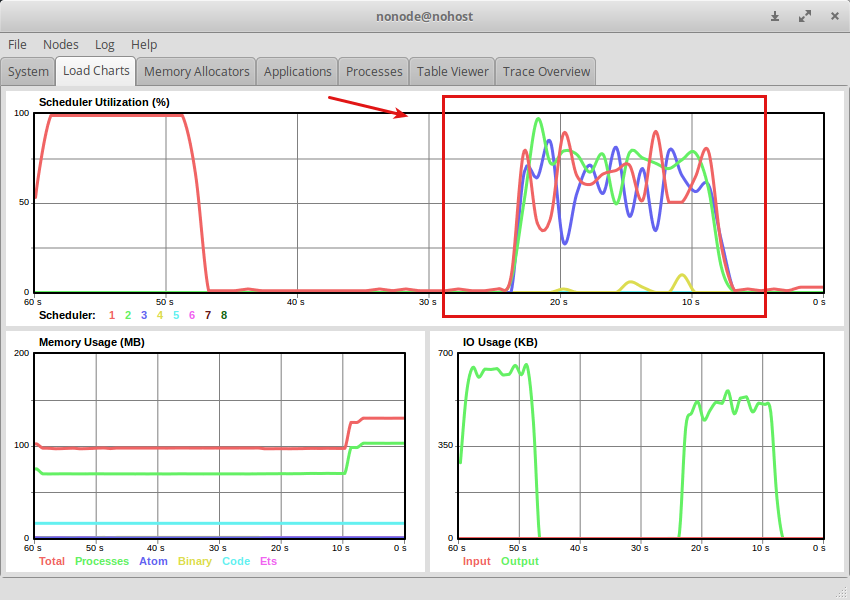
処理時間はシングルスレッドで回しているEnumより遅いがスケジューラーをうまく使って分散して処理してることが分かる.
Flow版
iex> :timer.tc(fn -> 1..1000000 |> Flow.from_enumerable |> Flow.each(& IO.inspect &1) |> Enum.to_list end) |> elem(0) |> Kernel./(1000000)
...中略...
7.437603
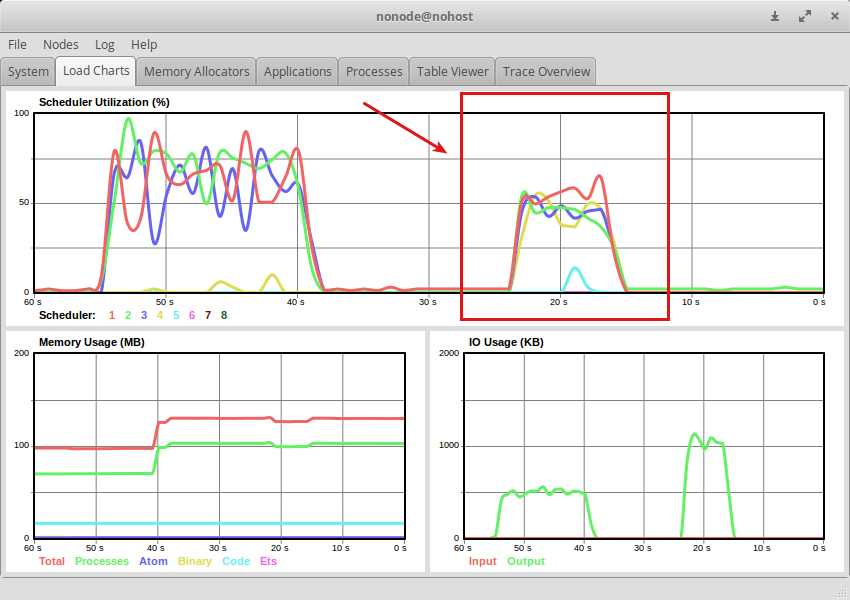
Flowは一番処理時間も短くスケジューラーの使用率も低く効率的に並列分散処理していることが分かる.
ただstage間では処理の順番は保証されないため処理の途中を見ると以下のような出力になる.
...中略...
999353
999716
998867
998401
997963
999354
999717
...中略...
まとめ
Flowでlazyな並列分散処理を行い、ベンチマークでCPUを使い切って処理していることを確認した.
大量のデータの逐次的な処理だけでなく集計にも力を発揮しそう.
ステージ数については
- CPUバウンドな処理: デフォルトのステージ数
- IOバウンドな処理: IOの数に合わせてステージ数を増やす
な時最適な結果を得られそうだった
またTask.async_streamとFlowのそれぞれの使いどころについては
- Task.async_stream: 標準ライブラリで簡単に並列処理したい場合
- Flow: 実行順序を保証しなくていい場合. 一度に処理する量を調節したい場合. より高速に並列処理したい場合
というところで使い分けが出来そうだった.