When
2017/04/01
At
Self Introduction
ちきさん
(Tomohiro Noguchi)
Twitter/GitHub/Qiita: @ovrmrw
I've started to learn Elixir 1 month ago.

What I talk about
 Reading a JSON file and doing MapReduce.
Reading a JSON file and doing MapReduce.
(JSONファイルを読み込んでMapReduceしたい。)
Differences between Eager, Lazy and Flow(Concurrent).
(Eager, Lazy, Flow(Concurrent)の違いについて。)
Flow & GenStage is extremely fast.
(Flowめちゃくちゃ速い。)
===
GitHub repository for this slide. ovrmrw/elixir_file_read_eager_lazy_flow
JSON file to read (300,000 lines) (100MB)
{"name":{"first":"Lue","last":"Laserna"},"gender":"female","birthday":"1983-09-18","contact":{"address":{"street":"19 Deer Loop","zip":"90732","city":"San Pedro","state":"CA"},"email":["lue.laserna@nosql-matters.org","laserna@nosql-matters.org"],"region":"310","phone":["310-8268551","310-7618427"]},"likes":["chatting"],"memberSince":"2011-05-05"}
{"name":{"first":"Jasper","last":"Grebel"},"gender":"male","birthday":"1989-04-29","contact":{"address":{"street":"19 Florida Loop","zip":"66840","city":"Burns","state":"KS"},"email":["jasper.grebel@nosql-matters.org"],"region":"316","phone":["316-2417120","316-2767391"]},"likes":["shopping"],"memberSince":"2011-11-10"}
{"name":{"first":"Kandra","last":"Beichner"},"gender":"female","birthday":"1963-11-21","contact":{"address":{"street":"6 John Run","zip":"98434","city":"Tacoma","state":"WA"},"email":["kandra.beichner@nosql-matters.org","kandra@nosql-matters.org"],"region":"253","phone":["253-0405964"]},"likes":["swimming"],"memberSince":"2012-03-18"}
{"name":{"first":"Jeff","last":"Schmith"},"gender":"male","birthday":"1977-10-14","contact":{"address":{"street":"14 198th St","zip":"72569","city":"Poughkeepsie","state":"AR"},"email":["jeff.schmith@nosql-matters.org"],"region":"870","phone":[]},"likes":["chatting","boxing","reading"],"memberSince":"2011-02-10"}
{"name":{"first":"Tuan","last":"Climer"},"gender":"male","birthday":"1951-04-06","contact":{"address":{"street":"6 Kansas St","zip":"07921","city":"Bedminster","state":"NJ"},"email":["tuan.climer@nosql-matters.org"],"region":"908","phone":["908-8376478"]},"likes":["ironing"],"memberSince":"2011-02-06"}
{.....}
{.....}
(データは arangodb/example-datasets からお借りしました)
Reading JSON file and doing MapReduce.
What I want to do is so-called "word counting"
- Read file in stream
- (ファイルをストリームで読み込む)
- Parse JSON string to Map data line by line
- (1行1行はJSONなのでパースする)
- Get only the first name from the Map
- (パース後のMapからfirst nameだけを取り出す)
- Count how many times the same name appeared
- (同じfirst nameが何回登場したかカウントする)
- Sort in descending order of the count
- カウントの降順でソートする
Read file in stream
def map_reduce(file) do
File.stream!(file) # ★
Parse JSON string to Map data line by line
def map_reduce(file) do
File.stream!(file)
|> Enum.map(&json_parse/1) # ★
Get only the first name from the Map
def map_reduce(file) do
File.stream!(file)
|> Enum.map(&json_parse/1)
|> Enum.map(fn person ->
%{name: %{first: first}} = person
first
end) # ★
Count how many times the same name appeared
def map_reduce(file) do
File.stream!(file)
|> Enum.map(&json_parse/1)
|> Enum.map(fn person ->
%{name: %{first: first}} = person
first
end)
|> Enum.reduce(%{}, fn name, acc ->
Map.update(acc, name, 1, & &1 + 1)
end) # ★
Sort in descending order of the count
def map_reduce(file) do
File.stream!(file)
|> Enum.map(&json_parse/1)
|> Enum.map(fn person ->
%{name: %{first: first}} = person
first
end)
|> Enum.reduce(%{}, fn name, acc ->
Map.update(acc, name, 1, & &1 + 1)
end)
|> Enum.sort(fn {_, count1}, {_, count2} -> count1 >= count2 end) # ★
end
The result is below.
[{"Clair", 191}, {"Jae", 190}, {"Quinn", 187}, {"Andrew", 185}, {"Daryl", 182},
{"Brandon", 181}, {"Juan", 181}, {"Andre", 181}, {"Bernie", 181}, {"Dan", 179},
{"Sean", 179}, {"Dorian", 179}, {"Hong", 179}, {"Mickey", 179}, {"Louis", 178},
{"Jan", 178}, {"Sammie", 178}, {"Minh", 178}, {"Numbers", 177}, {"Avery", 176},
{"Michal", 176}, {"Jewell", 176}, {"Terrell", 176}, {"Julio", 175},
{"Russell", 175}, {"Logan", 175}, {"Elisha", 175}, {"Cruz", 175},
{"Sung", 175}, {"Deon", 175}, {"Noel", 174}, {"Jessie", 174}, {"Donald", 174},
{"Sidney", 174}, {"Blair", 174}, {"Arthur", 174}, {"Tory", 174},
{"David", 174}, {"Roy", 173}, {"Martin", 172}, {"Cody", 172}, {"Carrol", 171},
{"Adrian", 171}, {"Paris", 171}, {"Micah", 171}, {"Kasey", 171},
{"Antonia", 171}, {"Julian", 170}, {"Drew", ...}, {...}, ...]
It is understood that the name of Clair was the most frequent in 191 times.
(Clairという名前が191回で最も多く登場したということがわかる。)
Differences between Eager, Lazy and Flow(Concurrent)
Eager (逐次処理)
def map_reduce(:eager, file) do
File.stream!(file)
|> Enum.map(&json_parse/1)
|> Enum.map(fn person ->
%{name: %{first: first}} = person
first
end)
|> Enum.reduce(%{}, fn name, acc ->
Map.update(acc, name, 1, & &1 + 1)
end)
|> Enum.sort(fn {_, count1}, {_, count2} -> count1 >= count2 end)
end
-
Simple. Easy to understand.
-
Bad for memory.
-
Run on single thread. (slow for big data)
-
シンプルでわかりやすいが、各マップ処理でファイルの全行(30万行)を展開しているので大量にメモリを使う。
-
シングルスレッドで動作する。
-
データ量が極めて少ないときは有効。
Lazy (遅延処理)
def map_reduce(:lazy, file) do
File.stream!(file)
|> Stream.map(&json_parse/1) # Enum ==> Stream
|> Stream.map(fn person -> # Enum ==> Stream
%{name: %{first: first}} = person
first
end)
|> Enum.reduce(%{}, fn name, acc ->
Map.update(acc, name, 1, & &1 + 1)
end)
|> Enum.sort(fn {_, count1}, {_, count2} -> count1 >= count2 end)
end
-
Good for memory.
-
Run also on single thread. (slow for big data)
-
マップ処理を
EnumからStreamに変更することでメモリに優しくなる。 -
でもやっぱりシングルスレッドで動作する。
Flow (Concurrent) (並行処理)
def map_reduce(:flow, file) do
File.stream!(file)
|> Flow.from_enumerable # added
|> Flow.map(&json_parse/1) # Enum ==> Flow
|> Flow.map(fn person -> # Enum ==> Flow
%{name: %{first: first}} = person
first
end)
|> Flow.partition # added
|> Flow.reduce(fn -> %{} end, fn name, acc -> # Enum ==> Flow
Map.update(acc, name, 1, & &1 + 1)
end)
|> Enum.sort(fn {_, count1}, {_, count2} -> count1 >= count2 end)
end
-
Concurrent both Map and Reduce.
-
Giving up ordering (but it's not a big deal).
-
Flow.from_enumerableから先は並列で動作する。(リデュース処理も並列!) -
並列化のためにorderingを捨てているので、最後にソートしているがEager, Lazyの場合とは微妙に異なる結果になる。(カウントが同じときの名前の並びが変わる)
Speed Comparison
CPU: Intel Core i5-2400 (4 cores)
- Eager ... 12.2 sec

- Lazy ... 10.4 sec

- Flow(Concurrent) ... 2.7 sec

===
Flow is extremely fast because it uses GenStage to draw full performance of multi-core with back-pressure concept.
(FlowはGenStageを使って、マルチコアの性能をback-pressureでフルに引き出すのでめちゃくちゃ速い。)
CPU usage graph
Eager ... uses only 1 core.
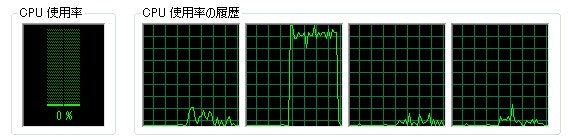
Lazy ... sticks to the upper limit rather than Eager.
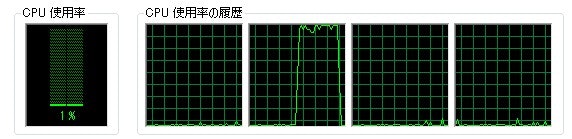
Flow(Concurrent) ... All cores stick to the upper limit.

This video will help you to understand GenStage and Flow easily.
GenStage and Flow - José Valim (Lambda Days 2017) (YouTube)
===
(ElixirはYouTubeで動画漁ってると結構キャッチアップできる)