前回のCNNとKNNの複合による分類精度の観測の続き、訓練エポックを増やしてリトライ
この記事は、自身のブログ、Data Science Struggleを翻訳したものになる。
概略
以前CNN + KNNによるモデリングを試したとき、訓練エポック数が足りずに消化不良だったのでCNNモデリングのフェーズで200epoch回したもので結果を再確認。
実際に回す
使用したのは以下のコード
import numpy as np
import keras
from keras.datasets import cifar10
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Conv2D, MaxPooling2D, Flatten, Activation
from keras.regularizers import l1_l2
from keras.utils import to_categorical
from sklearn.model_selection import train_test_split
# read data
(x_train_orig, y_train_orig), (x_test, y_test) = cifar10.load_data()
# split data
x_train_1, x_train_2, y_train_1, y_test_2 = train_test_split(x_train_orig, y_train_orig, train_size=0.7)
def model_1(x_train, y_train, conv_num, dense_num):
input_shape = x_train.shape[1:]
# make teacher hot-encoded
y_train = to_categorical(y_train, 10)
# set model
model = Sequential()
model.add(Conv2D(conv_num, (3,3), activation='relu', input_shape=input_shape))
model.add(Dropout(0.2))
model.add(Conv2D(conv_num, (3,3), activation='relu'))
model.add(Dropout(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(conv_num * 2, (3,3), activation='relu'))
model.add(Conv2D(conv_num * 2, (3,3), activation='relu'))
model.add(Dropout(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(dense_num, activation='relu', W_regularizer = l1_l2(.01)))
model.add(Dropout(0.2))
model.add(Dense(int(dense_num * 0.6), activation='relu', W_regularizer = l1_l2(.01)))
model.add(Dense(10, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
# training
history =model.fit(x_train, y_train, batch_size=256, epochs=200, shuffle=True, validation_split=0.1)
return history
history_1 = model_1(x_train_1, y_train_1, 32, 256)
訓練の進み方をプロットで確認。
import matplotlib.pyplot as plt
def show_history(history):
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train_accuracy', 'test_accuracy'], loc='best')
plt.show()
show_history(history_1)
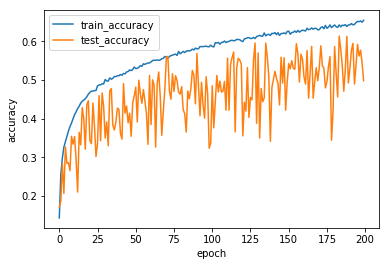
train accuracyはおよそ0.6、test accuracyはおよそ0.5となっており、過学習状態。
CNNオンリーのモデルの予測とCNN+KNNのモデルの予測を確認。
predictions_1 = history_1.model.predict(x_train_2)
prediction_test = history_1.model.predict(x_test)
from sklearn.neighbors import KNeighborsClassifier
knn_2 = KNeighborsClassifier(n_neighbors=2)
knn_4 = KNeighborsClassifier(n_neighbors=4)
knn_8 = KNeighborsClassifier(n_neighbors=8)
knn_16 = KNeighborsClassifier(n_neighbors=16)
knn_32 = KNeighborsClassifier(n_neighbors=32)
knn_64 = KNeighborsClassifier(n_neighbors=64)
knn_128 = KNeighborsClassifier(n_neighbors=128)
knn_256 = KNeighborsClassifier(n_neighbors=256)
knn_2.fit(predictions_1, y_test_2)
knn_4.fit(predictions_1, y_test_2)
knn_8.fit(predictions_1, y_test_2)
knn_16.fit(predictions_1, y_test_2)
knn_32.fit(predictions_1, y_test_2)
knn_64.fit(predictions_1, y_test_2)
knn_128.fit(predictions_1, y_test_2)
knn_256.fit(predictions_1, y_test_2)
kn_2_pr = knn_2.predict(prediction_test)
kn_4_pr = knn_4.predict(prediction_test)
kn_8_pr = knn_8.predict(prediction_test)
kn_16_pr = knn_16.predict(prediction_test)
kn_32_pr = knn_32.predict(prediction_test)
kn_64_pr = knn_64.predict(prediction_test)
kn_128_pr = knn_128.predict(prediction_test)
kn_256_pr = knn_256.predict(prediction_test)
from sklearn.metrics import accuracy_score
for i in range(1,9):
val = str(pow(2, i))
eval("print(\"k=" + val + ":{}\".format(accuracy_score(kn_" + val + "_pr, y_test)))")
import numpy as np
outcome = [np.argmax(i) for i in prediction_test]
print("CNN:{}".format(accuracy_score(outcome, y_test)))
この過学習が起きてる状況ではtest accuracyは以下の通りとなり、KNN(k=64)などはCNNのみのモデルに比べて0.1ポイント高い。
k=2:0.5069
k=4:0.5627
k=8:0.5933
k=16:0.6024
k=32:0.6055
k=64:0.6093
k=128:0.607
k=256:0.6011
CNN:0.4928
集合知によりテスト正答率は訓練正答率に近づいている。