この記事は、自身のブログ、Data Science Struggleを翻訳したものになる。
概略
Kaggleのようなコンテストだと複数のアルゴリズムを組み合わせたモデルを良く見る。ロジスティック回帰やラッソ回帰の結果を用いてxgboostでモデルを作成するといったようなものだ。
今回は実際に、cifar-10のデータセットを用いて、CNNとKNNを組み合わせて予測を行い、実際の精度を見てみる。
手順
行うことはシンプルであり、CNNで予測したスコアを訓練データとしてKNNでモデルを作成し、その予測を最終予測結果とする。
具体的な手順は以下のようになる。
- データを3つに分割する
- 一つ目のデータからCNNモデルを作成する
- 二つ目のデータと三つ目のデータに対してCNNモデルで予測を行う
- 二つ目のデータのCNN予測スコアを用いてKNNモデルを作成する
- 三つ目のデータのCNN予測スコアに対して、KNNモデルで予測を行う
流れを図で表すと以下のようになる。
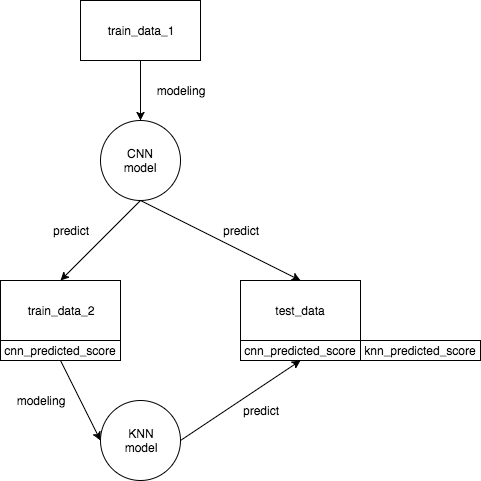
なぜデータを3つに分割するのか?
一般的に、モデルの作成、予測を行う時にはデータは訓練データとテストデータの二つに分割する。しかし、今回の場合はKNNモデルによる訓練、予測の段階で使用するのはtrain_data_2とtest_dataの二つだけとなる。
我々がモデルを作成し、その予測精度を図る時に重視するのは訓練データとテストデータの同質性だ。訓練データとテストデータはもちろん同一のものではない。しかし、それぞれのラベルの持つデータ量の割合や変数の分布などの性質はほぼ同一であるべきだ。
今回の場合、もしもデータを三つではなく二つに分割したならば、訓練データを用いて作成したCNNのモデルでその訓練データとテストデータの予測を行い、そのスコアをKNNモデルで作成することになる。こうした時、そもそもCNNモデルがこの該当訓練データによって作成されているのでKNNモデル作成で使用されるデータは訓練データとテストデータの同質性が保たれているとは言えない。
ゆえに、今回はデータを三つに分割する。
データ
使用するデータは10のカテゴリを持つカラー画像データセットのcifar-10。
import numpy as np
import keras
from keras.datasets import cifar10
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Conv2D, MaxPooling2D, Flatten, Activation
from keras.regularizers import l1_l2
from keras.utils import to_categorical
from sklearn.model_selection import train_test_split
# read data
(x_train_orig, y_train_orig), (x_test, y_test) = cifar10.load_data()
# split data
x_train_1, x_train_2, y_train_1, y_test_2 = train_test_split(x_train_orig, y_train_orig, train_size=0.7)
上記のコードでライブライのインポートとデータ獲得、データ分割を行う。
CNNモデリング
def model_1(x_train, y_train, conv_num, dense_num):
input_shape = x_train.shape[1:]
# make teacher hot-encoded
y_train = to_categorical(y_train, 10)
# set model
model = Sequential()
model.add(Conv2D(conv_num, (3,3), activation='relu', input_shape=input_shape))
model.add(Dropout(0.2))
model.add(Conv2D(conv_num, (3,3), activation='relu'))
model.add(Dropout(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(conv_num * 2, (3,3), activation='relu'))
model.add(Conv2D(conv_num * 2, (3,3), activation='relu'))
model.add(Dropout(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(dense_num, activation='relu', W_regularizer = l1_l2(.01)))
model.add(Dropout(0.2))
model.add(Dense(int(dense_num * 0.6), activation='relu', W_regularizer = l1_l2(.01)))
model.add(Dense(10, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
# training
history =model.fit(x_train, y_train, batch_size=256, epochs=50, shuffle=True, validation_split=0.1)
return history
history_1 = model_1(x_train_1, y_train_1, 32, 256)
上記がCNNモデリングのコード。kerasでのCNNモデリングについては詳細は別記事で。
学習には50 epochを設定している。実際のところこれはパラメーターを決めるのには学習不足であるが、自分の環境では学習に時間がかかりすぎるのと、この実験がKNNとCNNの組み合わせ実験なのでここは妥協。毎日、空からGPUが降ってくるのを祈ってる。
念のために学習がどのように進んでいるのかをプロット。
import matplotlib.pyplot as plt
def show_history(history):
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train_accuracy', 'test_accuracy'], loc='best')
plt.show()
show_history(history_1)
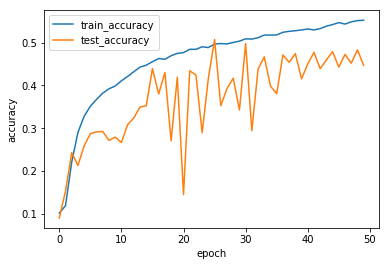
訓練不足だしtest accuracyも安定してない。
CNNモデルによるpredict
predictions_1 = history_1.model.predict(x_train_2)
prediction_test = history_1.model.predict(x_test)
'predictions_1'はKNNモデル作成に使用する訓練データになり、'prediction_test'はテストデータとなる。
KNNモデル
KNN(k-nearest neighbor classifier)は非常にシンプルな機械学習アルゴリズムだ。ラベルを求めたいデータの近傍k個のデータのラベルの多数決で定める。
この場合は、説明変数はcifar-10が有する10カテゴリに対応するCNNモデルの10個のスコアになる。
from sklearn.neighbors import KNeighborsClassifier
# make models
knn_2 = KNeighborsClassifier(n_neighbors=2)
knn_4 = KNeighborsClassifier(n_neighbors=4)
knn_8 = KNeighborsClassifier(n_neighbors=8)
knn_16 = KNeighborsClassifier(n_neighbors=16)
knn_32 = KNeighborsClassifier(n_neighbors=32)
knn_2.fit(predictions_1, y_test_2)
knn_4.fit(predictions_1, y_test_2)
knn_8.fit(predictions_1, y_test_2)
knn_16.fit(predictions_1, y_test_2)
knn_32.fit(predictions_1, y_test_2)
# predict
kn_2_pr = knn_2.predict(prediction_test)
kn_4_pr = knn_4.predict(prediction_test)
kn_8_pr = knn_8.predict(prediction_test)
kn_16_pr = knn_16.predict(prediction_test)
kn_32_pr = knn_32.predict(prediction_test)
上記のコードは近傍kの値を変えて5つのモデルを作成、そのモデルによる予測を行っている。
精度を確認する。
from sklearn.metrics import accuracy_score
for i in range(1,6):
val = str(pow(2, i))
eval("print(\"k=" + val + ":{}\".format(accuracy_score(kn_" + val + "_pr, y_test)))")
結果は以下の通り。
k=2:0.447
k=4:0.5049
k=8:0.5302
k=16:0.5492
k=32:0.5599
今回の状況だとCNN+KNNモデルのいくつかははCNNのみのモデルより精度が良い。
CNN作成時の訓練epochを増やしてもう少ししっかりと精度を見たいところ。