こちらは NewsPicksアドベントカレンダーの9日目の記事です。
はじめに
こんにちは。NewsPicks エンジニアの鶴房です。
フロントエンドの刷新プロジェクトにおいて、主にインフラとバックエンドを担当しています。
今回は私が以前起こしてしまったサービス全停止の障害の原因と、その再発防止策に関して記載します。
尚、弊社ではRDBMSとしてMySQLを利用しているので、この記事はMySQLに関する内容になります。
障害事象
今年の夏頃、約30分の間、NewsPicksのほぼ全てのサービスが停止してしまいました。
ユーザーは、その間、ログインも、記事を読むことも、記事にコメントすることもできない状態でした。
アプリを開くと、エラーメッセージが表示されるだけの状態で、障害の解消までずっとその状態が続いていました。
障害の直接原因
障害の直接の引き金になったのは、タイトルにある通りALTER TABLEの実行でした。
以下のようなごく普通のSQLです。
ALTER TABLE
`xxxxx_table`
ADD
COLUMN `yyyy_column` bit(1) DEFAULT b'0' COMMENT 'コメント'
実行対象のテーブルは、行数が桁違いに多いとかでもなく、400行程度でした。
数ヶ月に一度更新されるくらいしか変更もされない、安定したマスターテーブルです。
もちろん開発環境において適用のテストも済ませており、開発環境においてもほぼ一瞬でステートメントが完了することを確認済の状態です。
障害の根本原因
MySQLに詳しい方であれば既に察しがついているかと思いますが、今回の障害はDDLの実行によるテーブルのメタデータロックが原因でした。
また、キャッシュ機構の不具合により、ほぼ全ての画面のリクエストにおいて、該当のテーブルに対しての読み込みが発生する状態でした。
これらの問題の合わせ技により、ほぼ全てのユーザーからのリクエストが当該テーブルのメタデータロックの影響を受け、タイムアウトしてしまい、今回の障害が発生しました。
以下、何が起きたのか詳しく説明しています。
メタデータロック
メタデータロックに関して、詳しい説明はWeb上にたくさん良質な記事があるのでそこに譲り、この記事では簡単に説明をします。
MySQLの5.6より、オンラインDDLと呼ばれる、DDL実行中ずっとテーブルのロックを取るのではなく、他のDMLを処理しつつDDLを実行してくれる機能が追加されています。
今回問題となったALTER TABLEのクエリも、オンラインDDLとして実行されています。
非常に便利な機能ですが、オンラインDDLには注意点があり、オンラインDDLの開始前、完了前にそれぞれ短時間ではあるもののテーブルのメタデータに関する排他的アクセスが必要となります。
つまり、オンラインDDLの開始前と完了前にDDLの対象テーブルに実行中のトランザクションがあった場合、そのトランザクションがコミットまたはロールバックするまで待機する必要があります。
なので、以下のような場合、後続のクエリすべてがロック解放待ちになってしまい実行されない状態になります。
・DMLが、当該テーブルのメタデータの共有ロックを取る。
・DDLが当該テーブルのメタデータの排他ロックを取ろうとする。
・前述のDMLのトランザクションが完了していない場合、DDLは排他ロックが取れないので、その完了を待つ
・DDLがロック取得を試みた後に実行されるDMLはすべてDDLのロック解放待ちになる。
あえて雑に例えてみると、行列のできるラーメン屋において、行列に店を一時的に貸切にしたいVIP(DDL)が並んでいる場合、その前にいた店内の全ての一般客が退店しないと、VIPが貸切にできず、その後ろにいる一般客もずっと待たされるようなイメージでしょうか。
なので、多くの場合、ロック待ちの復旧には、ずっと居座っている客の強制退店(= process kill)が必要です。
https://gihyo.jp/article/2022/09/mysql-rcn0180 さんの記事の説明がわかりやすかったので、詳しく知りたい方は併せてご覧ください。
今回は、後述するキャッシュ機構の不具合により、該当のテーブルには常時かなりの数の読み込みクエリが飛んでおり、DDLがロック待ちになった時点で、すぐに数千件以上の後続のDMLがprocess listに溜まっていた状態でした。
これによって、DDLの実行以降にNewsPicksへアクセスしたユーザーのリクエストはDDLのロック解放待ちとなり、ずっとロックが解放されないので、全てのユーザーのAPIへのリクエストがタイムアウトになってしまい、30分の間、誰も何も開けないという状態になってしまいました。
キャッシュ機構の不具合
上記の状況を引き起こした遠因にキャッシュの不具合がありました。
今回の対象テーブルは、ほとんど更新のないマスタテーブルだったので、サーバー側でキャッシュをしていたのですが、キャッシュロジックの不具合により、キャッシュキーがnullの場合にキャッシュが効かず、実データを読み込む仕様になっていました。
運の悪いことに当該テーブルに対するリクエストの多くの部分のキャッシュキーがnullだったので、全てのユーザーのほとんどのリクエストがRDBMSに対してクエリを実行し、今回のロックの問題の影響を受けてしまいました。
復旧作業に関して
待ちプロセスがあまりにも多すぎたので、process killでの対応はせず、Aurora MySQLのwriterプロセスを再起動することで、対応しました。
再起動後、障害は復旧しました。
ALTER TABLEに関しても再起動により実行がキャンセルされていたので後日、夜間の停止メンテナンス時に適用しました。
再発防止のルール
さて、ここからが如何にして再発防止をしたかの話です。
NewsPicksにおいて、ALTER TABLEを発端とした障害は今までも度々起きていました。
ただ、「行数の大きなテーブルにALTERしないでね。」「オンラインDDLの類型でないDDL(=実行中ずっとテーブルロックするもの)は実行しないでね」と言ったルールしかなく今回のような類型の障害を予防できるものではありませんでした。
障害を起こしてしまった当事者として、全ての開発者が安心してリリースできるように道を整えるのは大事な責務ですし、私としてはこのようなことは今回で最後にしたいという思いがありました。
そこで、過去NewsPicksにおいて起きたDDL絡みの障害のレポートを全て読み込み、以下のようなルール作り、github actionsを使ってALTER TABLEを含むPRへコメントすることにしました。
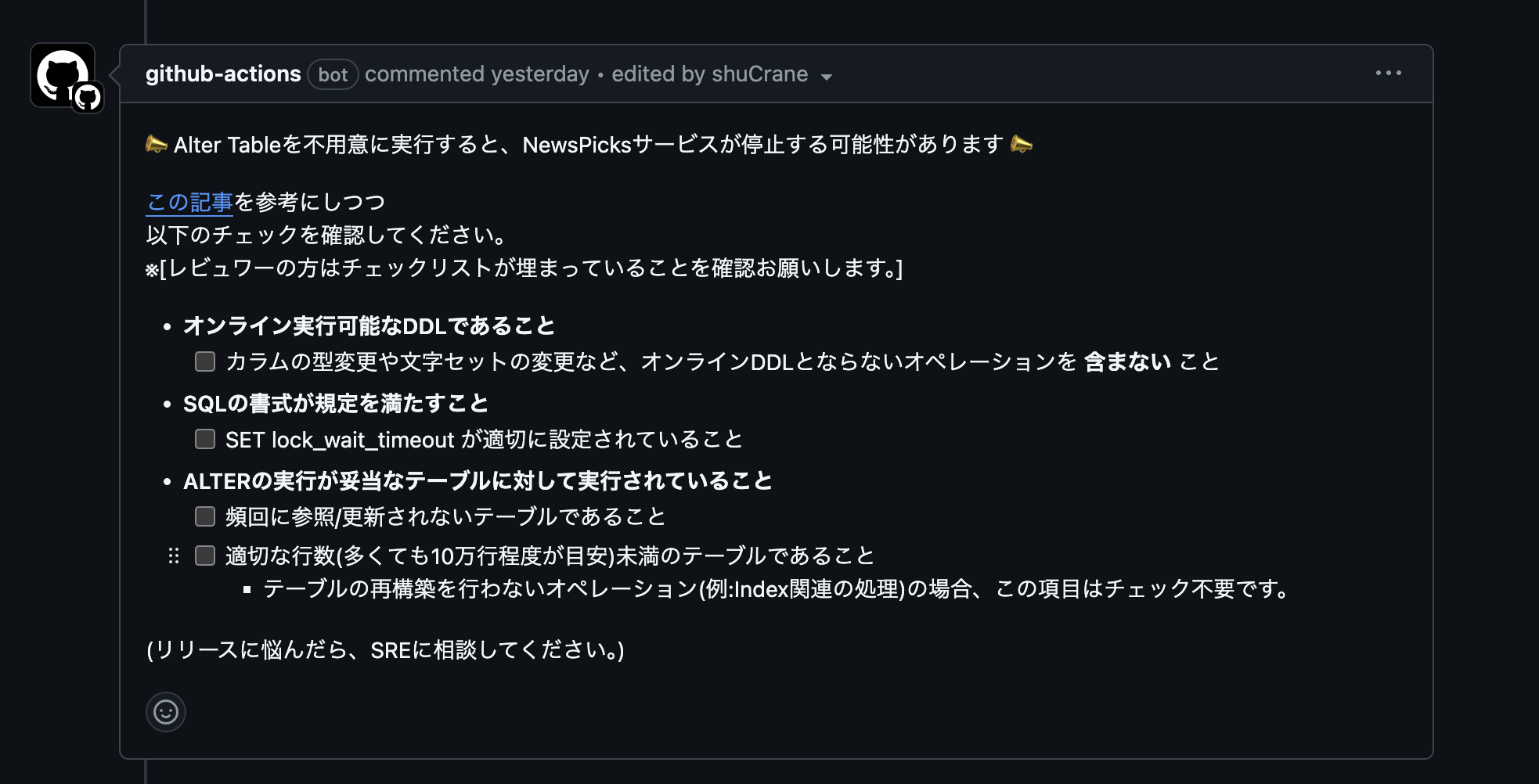
このルールの制定後、ルールの中身に関して詳しく説明会を開きました。
また、機械的にチェックできる項目に関しては、ビルドフローでチェックを走らせ、不合格の場合はビルドが落ちるようになっています。
各開発者はルールを守ってきちんとチェックボックスを運用してくれていて、
今のところ、ルール制定後から、ALTER TABLEを起因とするユーザー影響のある障害は起きていません。
以下、ルール作りの意図について簡単に解説していきます。
オンライン実行可能なDDLであること
これは前述の
「オンラインDDLの類型でないDDL(=実行中ずっとテーブルロックするもの)は実行しないでね」
というルールを踏襲したものです。
ALTERの実行中にずっとテーブルに対して排他ロックを取ることはほぼ確実にユーザー影響を発生させていまうので、数ヶ月に一度ある夜間停止のメンテナンスに相乗りして実行するルールになっています。
set lock_wait_timeout に関して
こちらは、今回の障害のように、メタデータの排他ロックの待ちが発生したときに何秒間まで待つかどうかを設定する変数です。
初期値はなんと一年です。
なので、今回の障害に関して、何もしなければ最悪1年間サービスが止まっていた可能性があります。
サービスが止まるくらいであればtimeoutでALTER TABLEが失敗する方がマシなので、タイムアウトの設定を行うようにしました。
頻回参照/更新に関して
前提として、今回のような類型のメタデータロックが発生する場合、共有ロックをなかなか解放しないロングトランザクションが原因であることがほとんどであると思います。
ただし、今回問題を起こしたテーブルは、我々の知る限りロングトランザクションが貼られるようなテーブルではありませんでした。
そこで、以下の二つを根拠にこのルールを制定しています。
・今回のテーブルの特徴である頻回参照や更新が終わらないトランザクションを生み出した原因である可能性が高いのではないか、という仮説。
・頻回参照更新のテーブルは、データロックが起きたときに影響が甚大になるので特に障害を起こすことを避けるべきであるということ
そもそものロングトランザクションに関しては、チェックボックスを要する必須のルールに追加ませんでした。
理由として、ロングトランザクションのクエリが特定のテーブルに発行されているかどうかも調べる方法がわかっていないため、チェックボックスを設けると開発者とレビュワーの負担になると考えたためです。
もちろん、開発者やレビュワーにロングトランザクションの心当たりがある場合は、ALTERの適用を避けるルールになっています。
行数の制限に関して
MySQLにおいて、行数の大きなテーブルに対してALTER TABLEを実行すると、オンラインDDLであっても、何かと問題が起きるというのはよく知られていることだと思います。
特にテーブル再構築を要するクエリに関しては負荷が大きいので行数を制限しています。
尚、Indexの追加のようなテーブル再構築を伴わない、比較的軽い処理に関しては、厳格な制限は行わなくても良いと考えているので、例外としています。
ただし、非常に行数が大き場合 (環境によるので、一概に何行とは言えませんが..) には、そういった軽い処理であっても、CPUやメモリを食ってしまい問題を引き起こすことがあるので、先ほどのgithub actionsのメッセージの[テーブル再構築を要さない場合]の例外記載に関しては更新予定です。
今後のルールの更新の予定
NewsPicksでは、恥ずかしながら長いことMySQL5.7系を使っていたのですが、先日晴れて8.0系にアップデートしました。
これにより INSTANT 形式の DLLを実行することが可能になったりと、ポジティブな変更を享受できるようになりました。
これにより、上述のルールを緩和できるケースがあるので、今後更新していく予定です。
キャッシュの監視とキャッシュ機構の改善
ルール制定の他に、今回の障害のもう一つの原因となってしまったキャッシュの問題に関しても改善に取り組んでいます。
弊社ではNew RelicというAPMツールを利用しているのですが、New Relicの機能を利用してキャッシュごとのキャッシュヒット率を常に監視しています。
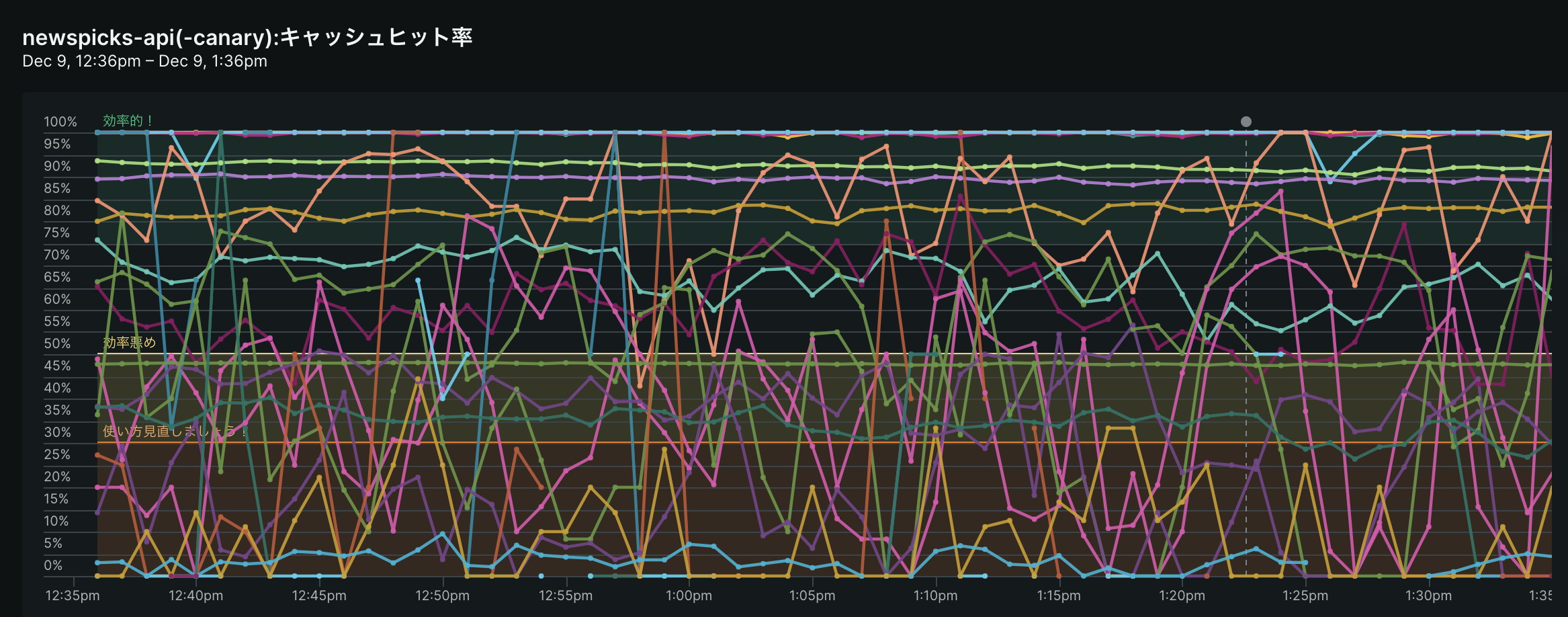
キャッシュヒット率が低く、またクエリ件数のボリュームが大きなものに関して、以下のような問題があります。
・今回のような障害の原因となる危険性を孕んでいる。
・そもそもパフォーマンス悪化の原因になっている。
なので、私を中心に、これらのクエリのキャッシュ戦略を見直していきました。
先ほどのグラフを見れば分かるとおり、まだまだキャッシュヒット率の低いクエリはたくさんあるのですが、20-80の法則に則って上位のボリュームが大きな部分を中心に、どんどん対応していきました。
結果として、Web版のアプリケーション全体の応答速度が10%程度向上し、スループットも向上しました。
この改善は非常にコスパが良かったと感じているので、ぜひ皆さんもチャレンジされてみると良いと思います。
尚、このキャッシュ監視機構に関して、作成者の飯野が別日にアドベントカレンダーを投稿しているので、詳しく知りたい方は併せてご覧ください。
https://tech.uzabase.com/entry/2024/12/07/080000
まとめ
非常に大きな障害を起こしてしまい、障害時やその直後はどうしようと非常に狼狽えていたのですが、弊社の非常に心理的安全性の高い職場環境にも助けられ、きちんと再発防止策を制定し、キャッシュの改善まで行い結果としてパフォーマンス改善も実施することができました。
筆者はバックエンドのアプリケーション開発が専門性の中心なので、DBにはあまり精通しておらず、障害が起きた当時は、狼狽えるばかりでしたが、再発防止のタスクを任せていただき、必要に応じて助けてもらった会社や組織に非常に感謝しています。
読んでいただいた皆さんも、障害が起きたときにネガティブな面だけに注目せずに、改善のチャンスだと思って取り組んでいきましょう!
最後に、筆者もまだまだ勉強中の身なので、不適切/不正確な記述があるかもしれません。
そういった記述の気づいた方、こうすればもっと良くなるなどのアイディアのある方は、ぜひコメントしていただければと思います。
最後まで読んでくださりありがとうございました。