みなさんGoogle Colaboratory使っていますか?最高ですよね。
Google Colaboratory はブラウザ上で動作するJupyter notebook環境です。しかもGPU,TPUマシンが無料で使えます。最高ですねえ。
ただ、利用時間についてのルールが2つ(後述)あり, Colaboratoryユーザーを萎え萎えさせるハマりどころでもありました。
「朝起きたらいつのまにか接続が切れてやがる。。。」
「12時間たってリセット(強制接続切れ)されたから、また立ち上げ直さないとなあ。」
「90分問題回避のために, ローカルでスクリプト動かし続けるのもなんだかなあ。」
こんなモヤモヤが少なからずみなさんにもあったのではないでしょうか。
数多のColaboratoryユーザーがこういった問題に対して対策を共有してくれています。
先駆者の方々みたいに私も貢献してえぇんです。
- 12時間後にまた手動でデータ読み込み・ファイル実行をしなければならない
- 90分問題回避のためにPCで常時スクリプトを起動させなければならない
本記事では, Colaboratory内でSeleniumを用いることで, 上記の課題を下記のように解決します。
-
データ保存・読み込み, ファイル実行を自動で行う
- これまで避けられなかった12時間リセット問題を気にせず, 12時間以上かかるようなプログラムを実行できる
-
実行ファイル自ら, 定期的に自らのページにアクセスする
- 90分セッション切れが起こらない
- ローカルPCでスクリプトを常時起動させる必要がなくなる
概要
- Colaboratoryファイル単体で90分問題回避
- Colaboratory内でSeleniumを用い, fileA→fileB→fileAとすることで12時間問題を自動で回避する
- Chromeで作成されているUser Profileを使用することで, Colaboratory内のSeleniumで別のColaboratoryファイルを開くための認証を回避する(日本語が下手...)
お品書き
かなり長い記事になってしまったので, 適宜飛ばしてみてください。
やっていること・検証結果・動作確認動画あたりがイメージ掴みやすいかもです。
やっていること

- インスタンス(GPUあり)を起動し, FileAを実行する。
- インスタンス起動時間を測定しておき, 11時間経過したタイミングでSeleniumを用いて,違うインスタンス(GPUなし:None)を起動&FileBを実行する。
- 12時間経過後, FileAのインスタンスが終了する。
- FileAのインスタンスが終了してから, FileB内でSeleniumを用いて上記
1.を実行する
そして, FileA,B共にセッション切れを回避するために, Seleniumを用いて以下の処理を行います。

使用環境
Google Colaboratory
- Ubuntu18.04
Ubuntu環境(Selenium で用いるUser Profiles を作成するため)
- Ubuntu18.04(Docker for Mac でGUI操作可能なUbuntu環境を構築。↓の記事を参考)
Dockerを導入してGUI操作可能なLinux(Ubuntu)コンテナを作成する
12時間&90分ルール
上記で述べたとおり, Google Colaboratory では利用時間にルールがあります。
12時間&90分ルール
Google Colaboratoryでは以下の条件を満たす場合, 実行中のプログラムがあってもインスタンスの状態がすべてリセットされていまいます。
【12時間ルール】新しいインスタンスを起動してから12時間経過
【90分ルール】ノートブックのセッションが切れてから90分経過
◆Google Colaboratoryの90分セッション切れ対策【自動接続】
本記事では12時間ルール・90分ルールをColaboratory内で解決することを示します。
あとGoogle Coloaboratory上でSeleniumを動かすのは、難しいらしいです(← WebDriverの起動が難しいっぽい)。もし可能だった場合、Google Coloaboratory_fileAでselenumを起動させてGoogle Coloaboratory_fileBを起動し、12時間切れる前にGoogle Coloaboratory_fileBでselenumを起動させてGoogle Coloaboratory_fileCを起動(...以下エンドレスリピート)みたいなウンコプログラムを記述していたのだがorz
◆Google Colaboratoryを定期実行する方法について考える
上記記事は, 私がColaboratoryの定期実行をする際に参考にさせていただいたものです。今回は上記のウンコプログラム, 実現させます。
準備
- User Profile 作成
- Githubでプライベートレポジトリ作成 & アクセストークン取得
- Colaboratoryファイル作成・実行
上記の順序で説明を行います。実際に試す場合は1と2が逆になっても構いません。
User Profile 作成
Seleniumを用いて, Google Colaboratory のファイルを自動実行するためにはGoogleにログインする必要があります。しかし, この記事にもある通りreCAPTCHAのぐにゃぐにゃ文字列をColaboratoryファイル内のセルで突破することは厳しそうです。
解決策として, Chromeでユーザー毎に保存されているUser Profileを利用することにしました。User ProfileにはブックマークやCookie(id, パスワード)などなどが保存されています。それをColaboratory内のSelenium実行時に読み込ませることができれば, 認証を受ける必要がなくなるのではと考えました。
User Profileとは
User Profileとは, Chromeを利用するユーザー毎に紐つけられたアカウント情報をまとめたファイル群です。中にはブックマークやCookie(id, パスワード)などなどが保存されています。
一度GoogleやColaboratoryにログインすると,その中にデータが保存されることになります。ですので, 一度手動でログインする必要がありますが, Seleniumに読み込ませることで任意の認証処理を回避できます。
User Profile 作成
今回, Google Colaboratory 上で動いているマシンはUbuntu18.04(2019.11.11)なので,同じ環境でGoogleやColaboratoryにログインしたデータを保存したUser Profileを使うのが確実です。
最初,私はMacのUser ProfileをColaboratory内のSeleniumに読み込ませようとしていましたが, 認証を再度求められました。
その後, Docker for Mac でGUI操作可能なUbuntu環境を構築し, そこでChromeを開いてGoogleやColaboratoryにログインしました。そして, 作成されたUser ProfileをColaboratoryで使うことで成功しました。
Dockerを導入してGUI操作可能なLinux(Ubuntu)コンテナを作成する
User Profile 確認方法
User Profileを取得する方法はいくつかあります。私は二つ目の方法で新しく作成しました。
- Chrome上で確認する方法
(1) Chrome を起動し、アドレスバーに chrome://version と入力し Enter キーを押します。
(2) プロフィールパス に、その時使っているユーザーのプロフィールディレクトリパスが表示されます。
◆ChromeのUser Profileについて
- Seleniumで新しく作る方法
下記コードを実行すると, カレントディレクトリにUser Profileを作成してくれます。ですので, そのまま手動でGoogleやColaboratoryにログインしちゃってください!
プログラムを終了させるとあら不思議, User Profileができているではありませんか。次はこのUser ProfileをGitHubのプライベートレポジトリを使ってColaboratoryに読み込ませましょう。
import os
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import chromedriver_binary
userdata_dir = 'UserData' # カレントディレクトリの直下にUser Profile 作る場合
os.makedirs(userdata_dir, exist_ok=True)
options = webdriver.ChromeOptions()
# User Profile のpath設定
options.add_argument('--user-data-dir=' + userdata_dir)
driver = webdriver.Chrome(options=options)
try:
driver.get("https://google.com")
except:
driver.quit()
finally:
driver.quit()
注意点
MacのUser Profileでうまくいかなかったことの原因はまだ詰めきれていません...
OSの問題なのか, chromedriverの問題なのか。詳しい方教えていただけると嬉しいです。
Githubでプライベートレポジトリ作成 & アクセストークン取得
User Profileは個人情報の塊なので, どのようにColaboratoryに読み込ませるかは各自,自己責任でお願いします。私は以下の認証がめんどくさかったこと, GitHubでプライベートリポジトリを無制限に利用できることからGitHubを選択しました。

注意点
- プライベートレポジトリを作成して, そこにUser Profileをプッシュしましょう。
- これを機に必ず二段階認証にしましょう。
アクセストークン取得方法
プライベートリポジトリの作成方法は割愛します。アクセストークンの取得方法は下記の記事を参考にしました。
下記のコマンドは, 二段階認証を設定したプライベートリポジトリをcloneする時に使用するものです。
"git clone https://{アクセストークン}:x-oauth-basic@github.com/{ユーザー名}/{リポジトリ名}.git"
これでColaboratoryにUser Profile を読み込む準備が整いました!
ここまで長々と読んでくださって本当にありがとうございます。
なかなかに書き疲れるものですね〜。
実装
では、いよいよ実装に入ります!!!
Colaboratory内でSeleniumを使うためのセットアップは以下の記事を参考にしました。
Selenium on Colaboratory と時間制限回避手法に関するポエム
Colaboratoryファイル作成
本記事で作成したファイルは以下です。
- colab_selen.ipynb(FileA)
- return_selen.ipynb(FileB)
gitPython
gitPythonの実装も以下の記事を参考にしました。
Selenium on Colaboratory と時間制限回避手法に関するポエム
GitPythonドキュメント
実際にgitPythonを使ったcloneは以下のように実装しました。
%cd /content
repository_path = "{リポジトリ名}"
# ディレクトリ存在確認
if not os.path.isdir(repository_path):
git.Git().clone("https://{アクセストークン}:x-oauth-basic@github.com/{ユーザー名}/" + repository_path + ".git")
else:
pass
# クローンしたディレクトリに移動
%cd my-selenium-profile
pushまではこんな感じです。
class SeleniumColaboratory():
def __init__(self, mode="2"):
# カレントディレクトリをpathに設定
self.path = os.getcwd()
self.store_path = self.path + "/elapsed_time.txt"
"~~~~~~~~~~~~~~~~~~~~~~~~省略~~~~~~~~~~~~~~~~~~~~~~~~"
def git_push(self):
try:
repo = git.Repo.init()
repo.index.add(self.store_path)
repo.index.commit("add elapsed_time.txt")
origin = repo.remote(name="origin")
origin.push()
return "Success"
except:
return "Error"
def main(self):
# GitHubにプッシュ
result = self.git_push("学習データや中間生成物")
Selenium関連
GitHubからcloneしたディレクトリに入っているUserData_Ubuntuを, Seleniumに読み込ませるためには以下の処理を行います。
# User Plofile path
userdata_dir = "UserData_Ubuntu"
options = webdriver.ChromeOptions()
# User Plofile 読み込み
options.add_argument("--user-data-dir=" + userdata_dir)
Seleniumセットアップ処理の全体はこのような感じです。
class SeleniumColaboratory():
def __init__(self, mode="2"):
# カレントディレクトリをpathに設定
self.path = os.getcwd()
self.store_path = self.path + "/elapsed_time.txt"
# User Plofile path
userdata_dir = "UserData_Ubuntu"
options = webdriver.ChromeOptions()
# User Plofile 読み込み
options.add_argument("--user-data-dir=" + userdata_dir)
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
# open it, go to a website, and get results
self.driver = webdriver.Chrome("chromedriver",options=options)
他のColabratoryファイルにアクセスするには下記まとめコード内の
def access_another_colabo(self, path):
#新規タブを開いて更新処理
self.driver.execute_script("window.open()") #make new tab
self.driver.switch_to.window(self.driver.window_handles[-1]) #switch new tab
self.driver.get(path)
# ページの要素が全て読み込まれるまで待機
WebDriverWait(self.driver, 60).until(EC.presence_of_all_elements_located)
# 指定のURLにアクセスできているか確認(認証ページに飛ばされていないか確認)
cur_url = self.driver.current_url
print(cur_url)
self.click_change_runtime()
# 全てのセルを実行する
self.click_runall()
で実装しています。
自分のファイルにアクセスすることで, セッション切れを起こさないようにしているのは下記まとめコード内の
def auto_access(self, path):
try:
#新規タブを開いて更新処理
self.driver.execute_script("window.open()") #make new tab
self.driver.switch_to.window(self.driver.window_handles[-1]) #switch new tab
self.driver.get(path)
# ページの要素が全て読み込まれるまで待機
WebDriverWait(self.driver, 60).until(EC.presence_of_all_elements_located)
# 指定のURLにアクセスできているか確認(認証ページに飛ばされていないか確認)
cur_url = self.driver.current_url
print(cur_url)
self.click_change_runtime()
time.sleep(30)
except urllib3.exceptions.NewConnectionError as e:
print(str(e))
print("********Portal New connection timed out***********")
time.sleep(30)
except urllib3.exceptions.MaxRetryError as e:
print(str(e))
time.sleep(30)
print("*********Portal Max tries exceeded************")
で実装しています。
また, 他のColaboratoryのファイルを開くだけでなく, ファイルを実行する必要があります。実行順序としては以下になります。
- ランタイムの変更をする
- すべてのセルを実行する
よって, 以下の赤線を引っ張っている要素をクリックしなければなりません。
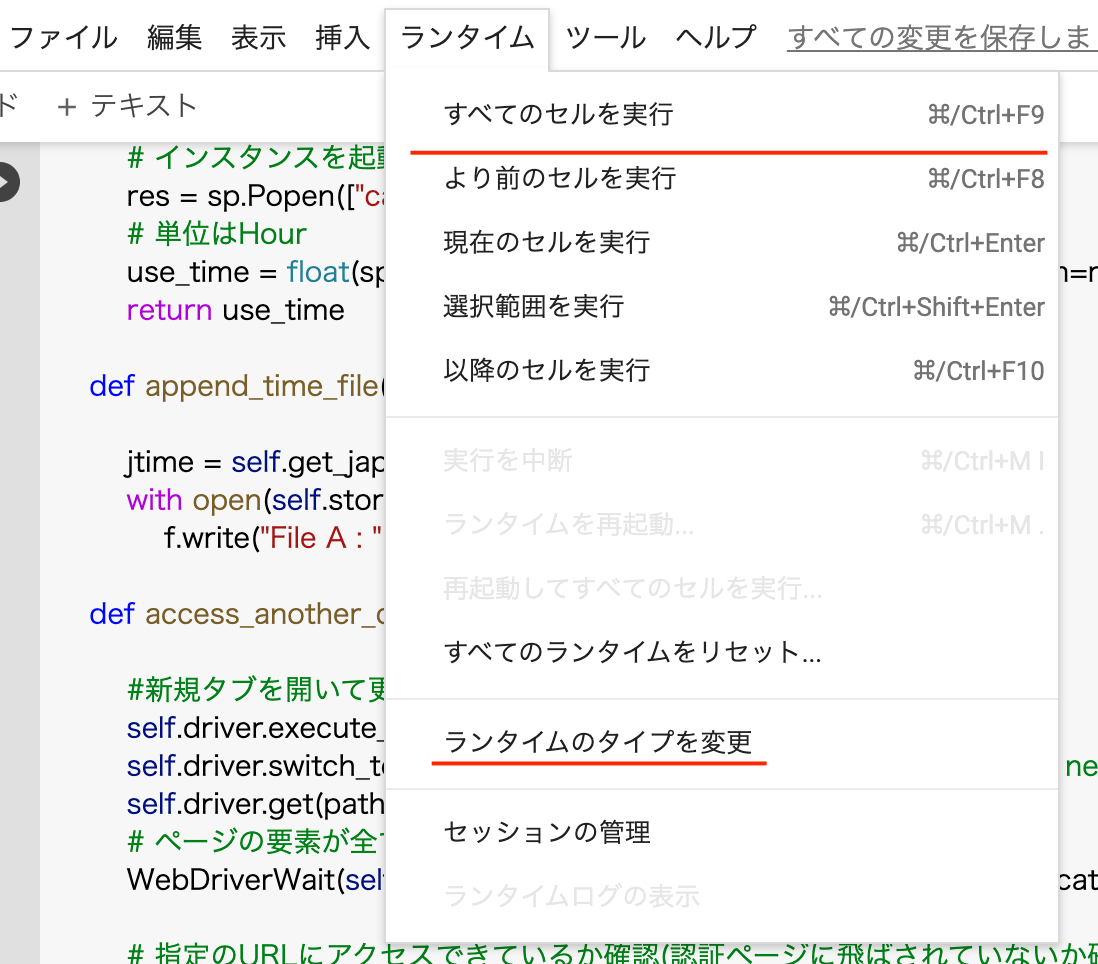
「すべてのセルを実行」をクリックするには下記まとめコード内の
def click_runall(self):
# ランタイムクリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,"runtime-menu-button")))
select_dropdown.click()
time.sleep(1)
# 全てのセル実行ボタンをクリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,":1s")))
select_dropdown.click()
で実装しています。
ランタイムの変更を設定するためには, 一度インスタンスの種類を設定し, Seleniumにて設定を行います。下記まとめコード内の
def set_mode(self, mode):
if mode == "None":
self.mode = "1"
elif mode == "GPU":
self.mode = "2"
elif mode == "TPU":
self.mode == "3"
else:
self.mode = "1"
def click_change_runtime(self):
# ランタイムクリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,"runtime-menu-button")))
select_dropdown.click()
# ランタイムのタイプ変更クリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,":23")))
select_dropdown.click()
# ドロップダウンクリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,"input-4")))
select_dropdown.click()
# 待たずにクリックしてしまうことがあるので
time.sleep(1)
# XPATH避けたい
# ランタイム選択
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.XPATH,"//*[@id='accelerator']/paper-item[" + self.mode + "]")))
select_dropdown.click()
# 保存ボタンクリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,"ok")))
select_dropdown.click()
で実装しています。
まとめコード畳んでいます↓↓↓
まとめコード
import os
# set options to be headless, ..
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import subprocess as sp
from datetime import datetime, timedelta, timezone
import urllib3
import time
class SeleniumColaboratory():
def __init__(self, mode="2"):
userdata_dir = "UserData_Ubuntu"
# カレントディレクトリをpathに設定
self.path = os.getcwd()
self.store_path = self.path + "/elapsed_time.txt"
options = webdriver.ChromeOptions()
options.add_argument("--user-data-dir=" + userdata_dir)
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
# open it, go to a website, and get results
self.driver = webdriver.Chrome("chromedriver",options=options)
# FIleB path
self.access_path = "https://colab.research.google.com/drive/1s3LeBakro8zDX_FGAZfhmgnNZktjwJtD"
# FilleA path for auto-access
self.access_path_2 = "https://colab.research.google.com/drive/1wT6ZpKLNr24R5qEfH-0jotifhBVrfA9S"
self.mode = str(mode)
jtime = self.get_japan_time()
initial_text = "------------------ " + jtime.strftime("%Y-%m-%d") + " ------------------\n"
self.append_time_file(initial_text)
def click_runall(self):
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,"runtime-menu-button")))
select_dropdown.click()
time.sleep(1)
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,":1s")))
select_dropdown.click()
def click_change_runtime(self):
# ランタイムクリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,"runtime-menu-button")))
select_dropdown.click()
# ランタイムのタイプ変更クリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,":23")))
select_dropdown.click()
# ドロップダウンクリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,"input-4")))
select_dropdown.click()
# 待たずにクリックしてしまうことがあるので
time.sleep(1)
# XPATH避けたい
# ランタイム選択
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.XPATH,"//*[@id='accelerator']/paper-item[" + self.mode + "]")))
select_dropdown.click()
# 保存ボタンクリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,"ok")))
select_dropdown.click()
def check_time(self):
# インスタンスを起動してからの時間を返す
res = sp.Popen(["cat", "/proc/uptime"], stdout=sp.PIPE)
# 単位はHour
use_time = float(sp.check_output(["awk", "{print $1 /60 /60 }"], stdin=res.stdout).decode().replace("\n",""))
return use_time
def append_time_file(self, txt):
with open(self.store_path, mode='a') as f:
f.write(txt)
def access_another_colabo(self, path):
#新規タブを開いて更新処理
self.driver.execute_script("window.open()") #make new tab
self.driver.switch_to.window(self.driver.window_handles[-1]) #switch new tab
self.driver.get(path)
# ページの要素が全て読み込まれるまで待機
WebDriverWait(self.driver, 60).until(EC.presence_of_all_elements_located)
# 指定のURLにアクセスできているか確認(認証ページに飛ばされていないか確認)
cur_url = self.driver.current_url
print(cur_url)
self.click_change_runtime()
# 全てのセルを実行する
self.click_runall()
def auto_access(self, path):
try:
#新規タブを開いて更新処理
self.driver.execute_script("window.open()") #make new tab
self.driver.switch_to.window(self.driver.window_handles[-1]) #switch new tab
self.driver.get(path)
# ページの要素が全て読み込まれるまで待機
WebDriverWait(self.driver, 60).until(EC.presence_of_all_elements_located)
# 指定のURLにアクセスできているか確認(認証ページに飛ばされていないか確認)
cur_url = self.driver.current_url
print(cur_url)
self.click_change_runtime()
time.sleep(30)
except urllib3.exceptions.NewConnectionError as e:
print(str(e))
print("********Portal New connection timed out***********")
time.sleep(30)
except urllib3.exceptions.MaxRetryError as e:
print(str(e))
time.sleep(30)
print("*********Portal Max tries exceeded************")
def set_mode(self, mode):
if mode == "None":
self.mode = "1"
elif mode == "GPU":
self.mode = "2"
elif mode == "TPU":
self.mode == "3"
else:
self.mode = "1"
def git_push(self):
try:
repo = git.Repo.init()
repo.index.add(self.store_path)
repo.index.commit("add elapsed_time.txt")
origin = repo.remote(name="origin")
origin.push()
return "Success"
except:
return "Error"
def get_japan_time(self):
# タイムゾーンの生成
JST = timezone(timedelta(hours=+9), 'JST')
# GOOD, タイムゾーンを指定している.早い
return datetime.now(JST)
def main(self):
while True:
elapsed_time = self.check_time()
print(elapsed_time)
jtime = self.get_japan_time()
append_text = "File A : " + str(elapsed_time) + " Hour (" +str(jtime.strftime("%H:%M:%S")) + ")\n"
self.append_time_file(append_text)
# 11時間越えたら
if elapsed_time > 11:
# GitHubにプッシュ
result = self.git_push()
self.set_mode("None")
# ColaboratoryファイルBを開く
self.access_another_colabo(self.access_path)
self.set_mode("GPU")
self.auto_access(self.access_path_2)
break
else:
self.set_mode("GPU")
self.auto_access(self.access_path_2)
# 60分ごとにチェック
time.sleep(3600)
print("Done.")
Selenium 注意点
- ショートカットキーがきかなかった
検証結果
まとめコード
import os
# set options to be headless, ..
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import subprocess as sp
from datetime import datetime, timedelta, timezone
import urllib3
import time
class SeleniumColaboratory():
def __init__(self, mode="2"):
userdata_dir = "UserData_Ubuntu"
# カレントディレクトリをpathに設定
self.path = os.getcwd()
self.store_path = self.path + "/elapsed_time.txt"
options = webdriver.ChromeOptions()
options.add_argument("--user-data-dir=" + userdata_dir)
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
# open it, go to a website, and get results
self.driver = webdriver.Chrome("chromedriver",options=options)
# FIleB path
self.access_path = "https://colab.research.google.com/drive/1s3LeBakro8zDX_FGAZfhmgnNZktjwJtD"
# FilleA path for auto-access
self.access_path_2 = "https://colab.research.google.com/drive/1wT6ZpKLNr24R5qEfH-0jotifhBVrfA9S"
self.mode = str(mode)
jtime = self.get_japan_time()
initial_text = "------------------ " + jtime.strftime("%Y-%m-%d") + " ------------------\n"
self.append_time_file(initial_text)
def click_runall(self):
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,"runtime-menu-button")))
select_dropdown.click()
time.sleep(1)
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,":1s")))
select_dropdown.click()
def click_change_runtime(self):
# ランタイムクリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,"runtime-menu-button")))
select_dropdown.click()
# ランタイムのタイプ変更クリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,":23")))
select_dropdown.click()
# ドロップダウンクリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,"input-4")))
select_dropdown.click()
# 待たずにクリックしてしまうことがあるので
time.sleep(1)
# XPATH避けたい
# ランタイム選択
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.XPATH,"//*[@id='accelerator']/paper-item[" + self.mode + "]")))
select_dropdown.click()
# 保存ボタンクリック
select_dropdown = WebDriverWait(self.driver, 20).until(EC.element_to_be_clickable((By.ID,"ok")))
select_dropdown.click()
def check_time(self):
# インスタンスを起動してからの時間を返す
res = sp.Popen(["cat", "/proc/uptime"], stdout=sp.PIPE)
# 単位はHour
use_time = float(sp.check_output(["awk", "{print $1 /60 /60 }"], stdin=res.stdout).decode().replace("\n",""))
return use_time
def append_time_file(self, txt):
with open(self.store_path, mode='a') as f:
f.write(txt)
def access_another_colabo(self, path):
#新規タブを開いて更新処理
self.driver.execute_script("window.open()") #make new tab
self.driver.switch_to.window(self.driver.window_handles[-1]) #switch new tab
self.driver.get(path)
# ページの要素が全て読み込まれるまで待機
WebDriverWait(self.driver, 60).until(EC.presence_of_all_elements_located)
# 指定のURLにアクセスできているか確認(認証ページに飛ばされていないか確認)
cur_url = self.driver.current_url
print(cur_url)
self.click_change_runtime()
# 全てのセルを実行する
self.click_runall()
def auto_access(self, path):
try:
#新規タブを開いて更新処理
self.driver.execute_script("window.open()") #make new tab
self.driver.switch_to.window(self.driver.window_handles[-1]) #switch new tab
self.driver.get(path)
# ページの要素が全て読み込まれるまで待機
WebDriverWait(self.driver, 60).until(EC.presence_of_all_elements_located)
# 指定のURLにアクセスできているか確認(認証ページに飛ばされていないか確認)
cur_url = self.driver.current_url
print(cur_url)
self.click_change_runtime()
time.sleep(30)
except urllib3.exceptions.NewConnectionError as e:
print(str(e))
print("********Portal New connection timed out***********")
time.sleep(30)
except urllib3.exceptions.MaxRetryError as e:
print(str(e))
time.sleep(30)
print("*********Portal Max tries exceeded************")
def set_mode(self, mode):
if mode == "None":
self.mode = "1"
elif mode == "GPU":
self.mode = "2"
elif mode == "TPU":
self.mode == "3"
else:
self.mode = "1"
def git_push(self):
try:
repo = git.Repo.init()
repo.index.add(self.store_path)
repo.index.commit("add elapsed_time.txt")
origin = repo.remote(name="origin")
origin.push()
return "Success"
except:
return "Error"
def get_japan_time(self):
# タイムゾーンの生成
JST = timezone(timedelta(hours=+9), 'JST')
# GOOD, タイムゾーンを指定している.早い
return datetime.now(JST)
def main(self):
while True:
elapsed_time = self.check_time()
print(elapsed_time)
jtime = self.get_japan_time()
append_text = "File A : " + str(elapsed_time) + " Hour (" +str(jtime.strftime("%H:%M:%S")) + ")\n"
self.append_time_file(append_text)
# 11時間越えたら
if elapsed_time > 11:
# GitHubにプッシュ
result = self.git_push()
self.set_mode("None")
# ColaboratoryファイルBを開く
self.access_another_colabo(self.access_path)
self.set_mode("GPU")
self.auto_access(self.access_path_2)
break
else:
self.set_mode("GPU")
self.auto_access(self.access_path_2)
# 60分ごとにチェック
time.sleep(3600)
print("Done.")
以下の処理を行い, 本記事の90分・12時間問題解決策が有用であることを検証しました。
FileAの処理
- 1時間ごとに, 以下の形式で
elapsed_time.txtに書き込む(1行目は初回のみ) - Seleniumを用いて, 1時間ごとにFileAにアクセスする
- インスタンス起動時間が11時間を越えたタイミングで, Seleniumを用いてFileAからFileBを実行する
- 同タイミングで, GitHubに
elapsed_time.txtをpushする
1 ------------------ {日本日時} ------------------
2 {ファイル名}:{インスタンス起動時間}({日本時間})
FileBの処理
- 上記
1.と同様の処理を行う - Seleniumを用いて, 0.5時間ごとにFileBにアクセスする
- インスタンス起動時間が1.5時間を越えたタイミングで, Seleniumを用いてFileBからFileAを実行する
- 同タイミングで, GitHubに
elapsed_time.txtをpushする - インスタンスが終了するまで上記
2.を繰り返す
12時間問題
FileBから始めてしまったのですが, GitHubにpushされたelapsed_time.txtを確認すると問題なく2回転していることがわかります。
------------------ 2019-11-15 ------------------
File B : 0.148172 Hour (11:02:53)
File B : 0.659194 Hour (11:33:32)
File B : 1.16914 Hour (12:04:08)
File B : 1.67921 Hour (12:34:45)
------------------ 2019-11-15 ------------------
File A : 0.371208 Hour (12:35:44)
File A : 1.38115 Hour (13:36:19)
File A : 2.39099 Hour (14:36:55)
File A : 3.40073 Hour (15:37:30)
File A : 4.41073 Hour (16:38:06)
File A : 5.42056 Hour (17:38:41)
File A : 6.43057 Hour (18:39:17)
File A : 7.4407 Hour (19:39:54)
File A : 8.45084 Hour (20:40:30)
File A : 9.46208 Hour (21:41:11)
File A : 10.4723 Hour (22:41:48)
File A : 11.4827 Hour (23:42:25)
------------------ 2019-11-15 ------------------
File B : 0.070075 Hour (23:43:33)
File B : 0.579919 Hour (00:14:09)
File B : 1.09002 Hour (00:44:45)
File B : 1.59973 Hour (01:15:20)
------------------ 2019-11-16 ------------------
File A : 0.0631278 Hour (01:16:18)
File A : 1.07302 Hour (02:16:53)
File A : 2.08286 Hour (03:17:29)
File A : 3.09267 Hour (04:18:04)
File A : 4.10244 Hour (05:18:39)
File A : 5.11231 Hour (06:19:15)
File A : 6.1223 Hour (07:19:51)
File A : 7.13236 Hour (08:20:27)
File A : 8.14249 Hour (09:21:04)
File A : 9.15265 Hour (10:21:40)
File A : 10.163 Hour (11:22:17)
File A : 11.1734 Hour (12:22:55)
90分問題
セッションが切れることなく, 処理を続けられていることが確認できます。
------------------ 2019-11-14 ------------------
File A : 0.0933806 Hour (21:44:54)
File A : 1.10327 Hour (22:45:30)
File A : 2.11307 Hour (23:46:05)
File A : 3.12278 Hour (00:46:40)
File A : 4.13269 Hour (01:47:16)
File A : 5.14361 Hour (02:47:55)
File A : 6.15773 Hour (03:48:46)
File A : 7.16782 Hour (04:49:22)
File A : 8.17792 Hour (05:49:58)
File A : 9.18807 Hour (06:50:35)
File A : 10.1983 Hour (07:51:12)
File A : 11.2088 Hour (08:51:50)
動作確認動画
ローカルPCのブラウザで実行したセッションは, 既に12時間経っているためリセットされていますが, Colaboratory内のSeleniumで開いたブラウザ上で新たにファイルが実行されているため、その他のセッションで実行されていることが確認できます。

ソースコードまとめ
-
colab_selen.ipynb(FileA)
https://colab.research.google.com/drive/1wT6ZpKLNr24R5qEfH-0jotifhBVrfA9S -
return_selen.ipynb(FileB)
https://colab.research.google.com/drive/1s3LeBakro8zDX_FGAZfhmgnNZktjwJtD
おわりに
Seleniumを用いることでColaboratoryファイルだけで90分・12時間問題を回避する方法を示すことができました。よって, 12時間を越える処理(例: Deep Learningモデルの学習)を行う場合でも, 自動で行えるようになりました!
ソースコードのコメントは出来るだけ残していますが, 説明不足な部分もあるかと思います。
もっと丁寧に書きたかったのですが, 本記事を書くのにちょっと時間を使いすぎているので, 教授に怒られる前に戻りたいと思います!それではまた!
参考文献
- Dockerを導入してGUI操作可能なLinux(Ubuntu)コンテナを作成する
- Python3のdatetimeはタイムゾーンを指定するだけで高速になる
-
コマンドライン用の個人アクセストークンを作成する
seleniumでリンクを別タブで開く
Selenium on Colaboratory の先駆者の方々
- Colaboratory上でSeleniumが使えないか試した(そしてダメだった) - Qiita
- GoogleColaboratoryにSeleniumの実行環境を用意する(失敗) - Qiita
- ColaboratoryでSeleniumが使えた:javascriptで生成されるページも簡単スクレイピング - Qiita
- python - WebDriverException: Message: Service/content/chromedriver unexpectedly exited. Status code was: -6 with ChromeDriver Google Colab and Selenium - Stack Overflow