こんにちは
今日から勉強のためにPythonでいろいろ作っていこうと思い、
Pythonを勉強しながら、成果物を作る様子をお見せします!
成果物は何作るん?
ニュース見出しチェッカーを作る
ニュース見出しチェッカーは特定のニュースサイトからトップニュースを抜き出して
見出しを一覧で表示してくれるツールのことです(俺調べ)
これを作ることで何が学べる?
Webページから情報を集める「Webスクレイピング」を学ぶことができる!
これをマスターすりゃ俺の夢である競馬予想AIの開発に一歩近づく...
とはいえやったことがあるので復習のつもりで作成していきます
副題として
GitやGithubの使い方を思い出す意味でもこれらを使用しながら
いろいろ成果物を作成していきたいと思います!
スマホに作ったやつを入れられたら最高なんだけどな...
とりあえずPCで見られるようにしないとか...
さっそく作っていこう
まずはGithubでリポジトリを作成
リポジトリとはプロジェクトの設計図やソースコードを保管しておくための
保管庫のようなものです
まずはGithubにログイン!
↓↓ Githubの公式サイトです ↓↓
https://github.co.jp/
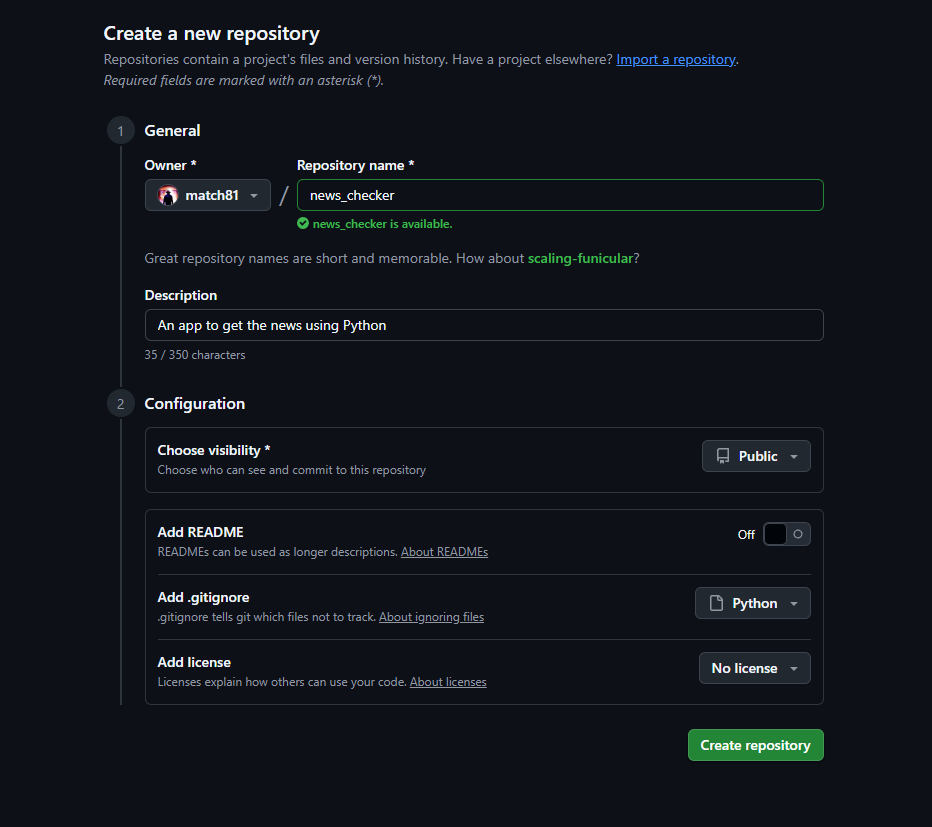
リポジトリを作りました!
基本的には"Repository name"と"Description"と"Add .gitignore"
を埋めていけば大丈夫かと思います!
リポジトリをコピー
リポジトリを作成した後、作業に移りたいので
そのための準備を進めていきます!
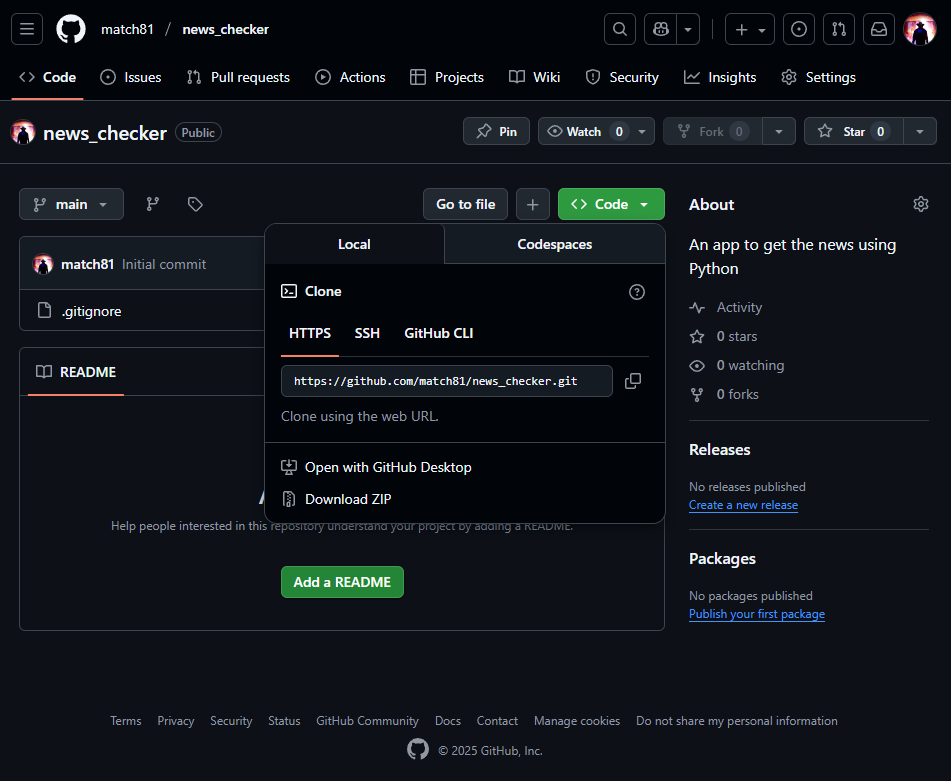
緑色の"<> Code"というところをクリックして
HTTPが選択されていることを確認して右側のコピーボタンを
クリックしてURLをコピーします
今回は私の環境であるWindowsで開発を行いますので、
Mac環境の方は自分の環境に合わせてお読みいただくか
すでにMac環境で詳しく解説されいる方の記事を
参考にしていただければと思います!
コピーしたら今度はPowerShellを開きます
今回は分かりやすいようにプロジェクトを保存しておく
場所を作成したうえで開発をしていきます
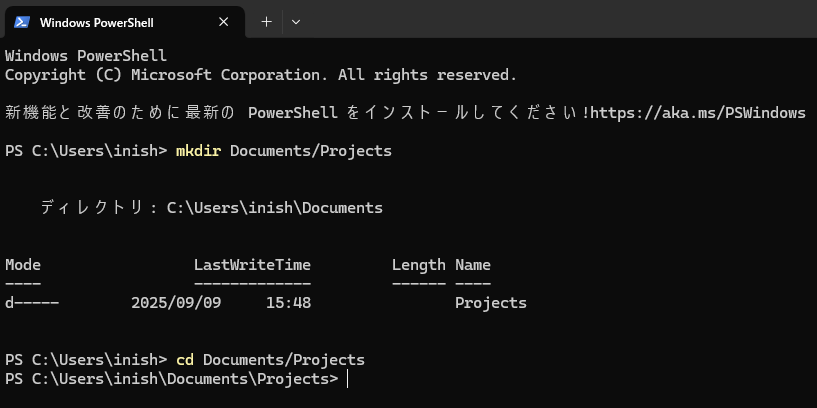
↑のような感じでフォルダを選択します
↓にコピー用のコマンドを書いておきます
#Documentの中にProjectというフォルダを作成するため
mkdir Documents/Projects
#プロジェクトを保存したい場所に移動するため
cd Documents/Projects
ここでGitを使用しますのでインストールされていない方は
Gitをインストールしてください!
↓↓ Gitのインストールはこちら! ↓↓
https://git-scm.com/downloads
んで、クローンを実行します
#クローンを実行
git clone <コピーしたURL>
コピーしたURLを入れて実行すればOKです
次にプロジェクトフォルダに移動して終わりです
#プロジェクトフォルダに移動する
#今回の私はnews_checkerという名前にしてます
cd news_checker
仮想環境の作成と有効化
※今回はWindows版ですのでご注意ください
※Windows版とMac/Linux版で異なりますのでご確認ください
※PowerShellのセキュリティレベルの変更が必要な場合もあります
※Pythonのインストールは各自でお願いいたします
ターミナルで先ほどのフォルダにいることを確認してから
以下のコマンドを実行します
#venvという新しいフォルダを作成
python -m venv venv
次に仮想環境を有効化していきます
以下のコマンドを実行します
#仮想環境を有効化するコマンド
.\venv\Scripts\activate
ここまで来たら最後にライブラリをインストールします!
#ライブラリのインストール
pip install requests beautifulsoup4
ここまでで開発の準備が完了しました!
ここからいよいよコーディングパートになります
準備ができたのでようやくコーディングに
Pythonファイルを作成する
今回はVScodeを使用します
VScode上でnews_checkerフォルダを開きます
開いたら新しくmain.py(今回はこう名付けましたがお好きな名前で)
というファイルを作成します
そこにコードを書いていきます
コーディング
今回はあくまで練習なのでYahoo!ニュースのトップページを
使用していき、ニュースを取得するコードを作成します
以下、そのままコピペで使えます(解説もします)
# 必要なライブラリ(道具)をインポートする
import requests
# 情報を取得したいWebサイトのURL
# 今回は練習としてYahoo!ニュースのトップページを使います
URL = "https://www.yahoo.co.jp/"
print("Webサイトから情報を取得します...")
try:
# requests.get()で、指定したURLにアクセスして情報を取得する
# サーバーからの返事がresponseという変数に入る
response = requests.get(URL)
# HTTPステータスコードが良いか(200 OKか)を確認する
# 200は「リクエスト成功」を意味する universal なコードです
response.raise_for_status()
print("情報の取得に成功しました!")
# 取得したHTMLの中身を、最初の500文字だけ表示してみる
# 全部表示すると長すぎるので、頭の部分だけ見て確認
print("--- 取得したHTML(先頭部分) ---")
print(response.text[:500])
print("---------------------------------")
except requests.exceptions.RequestException as e:
# アクセスに失敗した場合(インターネット接続がない、URLが間違っているなど)
print(f"エラー:情報の取得に失敗しました。")
print(e)
プログラムを実行してみる!
コマンドプロンプトを開いて、news_checkerフォルダにいることと
仮想環境が有効になっている(先頭に"venv"と表示されている)こと
の以上2点を確認したうえで、以下のコマンドを実行します!
#プログラムの実行
python main.py
成功すれば"情報の取得に成功しました!"と表示されます
最後にこの状態をGithubに保存します!
Githubに保存
変更内容を確認する
#Gitリポジトリの現在の状態を確認するコマンド
#何が変更されて次になにをすべきかを教えてくれる!
git status
保存したいファイルを指定
#保存したいファイルを指定
git add main.py
変更内容の記録をする(コミットする)
#コメントアウトで何をしたかが分かるメモを残します!
git commit -m "WebサイトからHTMLを取得する基本機能を作成"
Githubに送信する(プッシュする)
#リポジトリに記録が送信される!
git push
ちなみにちゃんとGithubのユーザー設定をしてから
コミット&プッシュをしましょう!
そうじゃないといつまでもGithubにプッシュされません!
コードの解説
import requests
この文でライブラリのインポートをします
requestsというライブラリを使います!という宣言をしてる文です
URL = "https://www.yahoo.co.jp/"
これはURLという変数にウェブサイトのアドレスを入れておく文です
いわゆる代入というやつです
try:
# この中の処理を試してみて...
...
except requests.exceptions.RequestException as e:
# もし上でエラーが起きたら、代わりにこちらを実行する
...
これはもしもの場合の安全装置です
try:ブロックの中のコードを実行しようと試みるが、
もし途中でエラーが発生してもプログラムを強制終了せずに
except:ブロックの処理を実行します
これがないとエラーが起きた瞬間にプログラムが
クラッシュしてしまいますのでめちゃ大事な文になってます
response = requests.get(URL)
インポートしたrequestsライブラリのget()を使用して
変数URLに入っているアドレスにアクセスをしています
サーバーからの応答がそのままresponseという名前の変数に格納されます
response.raise_for_status()
サーバーからの応答が成功だったか失敗だったかを確認します
もし失敗であればここでエラーを発生させて処理を中断して、
exceptブロックに処理を移します
print("情報の取得に成功しました!")
print(response.text[:500])
response.textには、取得したWebページのHTMLが
すべての文字列として入っていますが、全部表示すると
画面が文字だらけになってしまうので、[:500]という
スライシング(切り取り)機能を使っています
print(f"エラー:情報の取得に失敗しました。")
print(e)
try:ブロックの途中でエラーが発生した場合にのみ実行される
print(e)のeには、発生したエラーの詳細情報が入っています
これを表示することで、なぜ失敗したのかという原因を
突き止めるヒントが得られます!
必要な情報を抜き出す!
見出しのアドレスを調べる
まずは、ニュースサイトを開きます!今回はYahooでやります
見出しを右クリックすると「検証」と出てくるので
それをクリックします!すると...
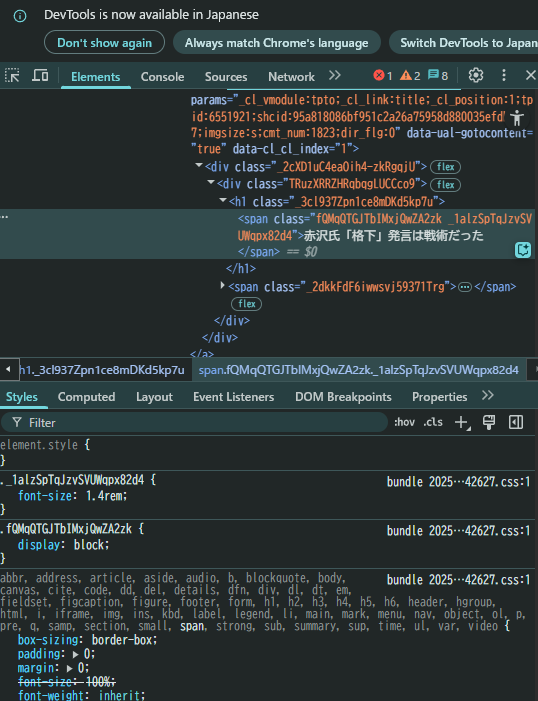
↑のような画面が出てきます!
<span class="fQMqQTGJTbIMxjQwZA2zk _1alzSpTqJzvSVUWqpx82d4">
それで、↑↑の部分はこのあと使いますのでメモしておきましょう!
ここから見出しの文を取ってくるのでメモしておかないと
コードが完成できません!
コードを更新する
ここでmain.pyを更新します
以下、そのままコードを使用できます!上書きしてください!
# 必要なライブラリ(道具)をインポートする
import requests
from bs4 import BeautifulSoup # BeautifulSoupを追加
# 情報を取得したいWebサイトのURL
URL = "https://www.yahoo.co.jp/"
print("Webサイトから情報を取得します...")
try:
# requests.get()で、指定したURLにアクセスして情報を取得する
response = requests.get(URL)
response.raise_for_status() # エラーチェック
print("情報の取得に成功しました!")
# BeautifulSoupを使って、取得したHTMLを解析(パース)する
# response.textでHTMLの文字列を取得し、"html.parser"で解析するよう指定
soup = BeautifulSoup(response.text, "html.parser")
# soup.find_all()を使って、指定した要素をすべて見つけ出す
# 最初の引数に「タグ名」、次のclass_引数に「クラス名」を指定します
elements = soup.find_all("span", class_="fQMqQTGJTbIMxjQwZA2zk _1alzSpTqJzvSVUWqpx82d4") # 例:Yahooニュースの主要トピックス
print("\n--- ニュース見出し一覧 ---")
# 見つかったすべての要素を一つずつ処理する(forループ)
for element in elements:
# .get_text()で、HTMLタグを取り除いたテキスト部分だけを取得する
title = element.get_text()
print(title)
print("--------------------------")
except requests.exceptions.RequestException as e:
# アクセスに失敗した場合
print(f"エラー:情報の取得に失敗しました。")
print(e)
ここで、python main.pyを実行してニュースの見出しが
一覧で出てくれば、成功です!

(ヨッシャ...Webスクレイピング習得だぜ...)
Githubに保存
忘れてはいけないのがGithubに保存する手順です
git status
git add main.py
git commit -m "見出しを抽出して表示する機能を追加"
git push
というわけで完成!
まだまだこれからバージョンアップしていけそう
一旦、完成しましたね!
Webスクレイピングは基本ですのでまだまだここから
いろいろ改良しがいがありますね!
色々考えてみて今後もバージョンアップをしていこうと思います!
Githubの使い方も思い出してきた
だいぶ古い記憶を辿りつつ、調べつつで進めましたが
ちゃんとGithubを使用することができてよかったです
これからも活用していこう!
今度はGithub上でAI開発しましょうかね
今はColab上でやっているので...
繋ぐ方法あればぜひ教えていただきたいです...
まとめ
というわけでWebスクレイピングを使用しつつ
ニュースの見出しを出力する「ニュース見出しチェッカー」を
作ってみました!
今後のアップデートに期待だぜ!
それではまた今度!