この記事はレイトレアドベントカレンダー 2025 ⧉の記事として書かれました。
はじめに
2025年時点でのリアルタイムレンダリングでは、(特にミドルレンジ~ハイエンドPCや据え置きコンソールをターゲットとしたゲームタイトルにおいて)リアルタイムレイトレーシングを活用することが多くなってきました。また、従来のZバッファーベースのラスタライズによるレンダリングにおいても三角形メッシュをクラスター化し、メッシュシェーダーなどを活用して高密度なジオメトリを効率的にレンダリングする手法が発展を見せています。
「リアルタイムレイトレーシング」と「クラスター化した高密度ジオメトリのレンダリング」、これら2つは昨今のリアルタイムレンダリングにおいて注目度の高い技術ですが、実は(従来までの)リアルタイムレイトレーシングのプログラミングモデルではクラスター化レンダリングと相性が良くありません。本記事ではその問題の解消を目指したリアルタイムレイトレーシングにおける新たなプログラミングモデルである通称(というか現時点でのNVIDIAのマーケティング名称)「Mega Geometry」について紹介します。
追記1: どうやらDXRの新仕様 ⧉としてMega Geometryが検討されているようです。
仮想化ジオメトリとレイトレーシング
仮想化ジオメトリ
リアルタイムレンダリングにおいて処理負荷や使用メモリ、エイリアシングの抑制を目的として、カメラからの距離などに応じて使用するジオメトリやテクスチャーの詳細度を動的に変更するLevel of Detail (LoD)という技術があります。
古典的なLoDシステムでは、オリジナルの三角形メッシュ(最高詳細度)を段階的に簡単化することで複数レベルの三角形メッシュを作成し、必要に応じて使用するレベルを切り替えます。このときオブジェクトごとに丸ごと三角形メッシュのレベルが切り替わるため、画面上で非連続に変化が見えてしまうポッピング(popping)が発生します。また、詳細度の高いレベルを表示する際には、本当に必要な部分がごく一部であったとしてもレベル全体をメモリに持っておく必要があり処理負荷・メモリ使用量の点でも問題があります。

この古典的なジオメトリLoDシステムの問題点の解決を図ったものが、Unreal Engine 5のNaniteに代表される仮想化ジオメトリ(Virtualized Geometry)と呼ぶ技術です。
仮想化ジオメトリでは三角形メッシュをクラスターと呼ぶ少数の三角形グループ(典型的には128~256三角形)に分割し、ラスタライズ時はクラスターごとにレベルを決定することでポッピング問題や処理負荷の軽減を図ります。メッシュの部分ごとにLoDが変化するので古典的LoDに対してContinuous LoDと呼ばれることもあるようです。
またディスクからのストリーミングを組み合わせることで可能な限り必要最小限のクラスターのみをメモリ上に持つようにすることでメモリ使用量の削減にも寄与します。この部分が仮想化テクスチャー同様"仮想化"たる所以だと思われます。
クラスターごとのレベル決定を単純に実装すると、クラスター間でポリゴンの隙間(crack)が生じる問題があるのですが、Naniteなどでは賢い階層的クラスター分割、単純化、レベル決定アルゴリズムを用いることでこの問題を回避しています。詳細については参考資料[1]などをご参照ください。

Acceleration Structure
レイトレーシングではレイと三角形メッシュなどの交差判定を高速化するため、BVH (Bounding Volume Hierarchy)を初めとするAcceleration Structure (AS, 高速化機構)の構築を行います。ASを用いることでレイとシーン中の三角形との交差判定コストをBVHの場合はプリミティブ数Nに対してO(log(N))に抑えられます。一方で、ASの構築コストやメモリ使用量はBVHの場合はプリミティブ数におおよそ比例(O(N))します。
二段階AS
リアルタイムレンダリングの文脈においてはシーン中を物体が動き回ることが前提にあるので、まず物体ごとに三角形集合に対してASを構築し、さらに物体ごとに作成したAS(と付随するトランスフォーム)の集合に対して上位のASを構築します。こうすることで物体が動いた場合でも上位のASのみを再構築するだけで済むのでASの更新コストを低く抑えることができます。
- 物体ごとのASをBottom-Level Acceleration Structure, BLASと呼びます。
(読み方はビーラスが多数, OptiXではGeometry AS, GAS) - BLAS集合に対する上位のASをTop-Level Acceleration Structure, TLASと呼びます。
(読み方はティーラスが多数, OptiXではInstance AS, IAS)
と呼びます。
BLAS例 (BVHではAABBで囲まれたプリミティブ集合を再帰的に分割する)

リフィット
二段階ASにおいて、ある物体が移動(具体的には平行移動、回転、一様な拡縮)するだけならその物体のASを再構築する必要はないのですが、変形(スキニングなど)する場合にはBVHを変形後の三角形の状態に追従させる必要があります。このときASを一から再構築しても良いのですが、構築コストが問題になる場合には作成済みのASの構造を再利用して有効なASに更新させるリフィット(DXRなどではASのUpdateと呼んでいる)を使うことができます。リフィットは再構築よりもはるかに低コストに済みますが、変形量が大きい場合にはレイトレーシング性能が低下する問題があります。再構築とリフィットどちらを使うかはトレードオフになります。さらにリフィットではメッシュのトポロジーは変更することができません。対応できるのはあくまで頂点の移動までです。
組み合わせたときの問題
今までのリアルタイムレイトレーシングAPIではTLASとBLASの二階層しか使用できませんでした(例外としてOptiXでは任意階層が使えたが性能面でペナルティあり)。これではオブジェクトの一部のクラスターのみを差し替えたい場合でもオブジェクトに対応するBLAS全体の再構築が必要になります。さらに、ASの構築APIも頂点数や三角形数をCPUで指定する必要があり、仮想化ジオメトリのようなGPU-Drivenなレンダリングシステムと相容れない仕様でした。
また、2025年時点のリアルタイムレンダリングではレイトレーシングのみでのレンダリングは行われておらず、少なくともPrimary Visibility、つまりカメラから直接見える物体の判定にはZバッファーベースのラスタライズを使用しています。レイトレーシングは典型的には二次以降の可視性に関して使用されていますが、2025年時点では多くのハードウェアにおいてレイトレーシングのトラバーサル性能に余裕が無いことや、前述の仮想化ジオメトリ等との相性の悪さからPrimary Visibilityで扱うジオメトリとは異なるジオメトリからASを作成しています。そのため、G-BufferのジオメトリとASから得られる周辺のジオメトリに矛盾が生じ、影を描画するためのシャドウレイなどにおいてレイの原点に大きなオフセットをかける必要がありアーティファクトも発生するなど厄介な問題があります。
Mega Geometry
前述のような従来のリアルタイムレイトレーシングプログラミングモデルの問題点を改善するものとして、NVIDIAがBlackwell世代のGPUにあわせて「Mega Geometry (Cluster APIとも)」と呼ぶ技術を発表しました。
Blackwellとあわせて発表された技術ですが、既存のRTX GPUもソフトウェア観点ではMega Geometryを使えます。ただしBlackwellのホワイトペーパー[2]を見る限り、「Triangle Cluster Compression Engine」や「Triangle Cluster Intersection Engine」といったハードウェアユニットが確認できるので、BlackwellではAS構築やトラバーサル時におけるハードウェア支援が新設されてより高速に使えるようになっているようです。
Mega Geometryでは従来のBLASやTLASに加えて新たなAS種別やGPU-DrivenなAPIが導入されています。
CLAS: Cluster-Level Acceleration Structure
Mega Geometryでは新たなASであるCluster-Level Acceleration Structure (CLAS, シーラス)が導入されます。CLASは名前から想像できるようにクラスター単位で構築するASで、比較的少数の三角形集合(~256 tris)を入力とします。CLASはASではあるものの、直接レイトレース対象にはできません。
Cluster BLAS
CLAS単体では三角形メッシュ全体をカバーできないので、複数のCLASを用いてメッシュ全体を表現します。このCLAS集合に対してもASを構築します。このASをCluster BLAS (Cluster GAS)と呼びます。Cluster BLASの機能・役割的には従来のBLASに相当します。CLASはCluster BLASを通じてレイトレース可能になります。
従来のBLASとCluster BLASの違いとして、従来のBLASは単一のメモリブロックでしたが、Cluster BLASは傘下のCLASそれぞれを参照するだけなので実体がメモリ上に散らばります。以下の図に示されているようにCluster BLASは複数のCLASを参照します。またひとつのCLASは複数のCluster BLASから参照される可能性があります。従来のBLASも複数のジオメトリを入力にとれましたが、それらの内容はBLASのメモリブロックにコピーされていました。
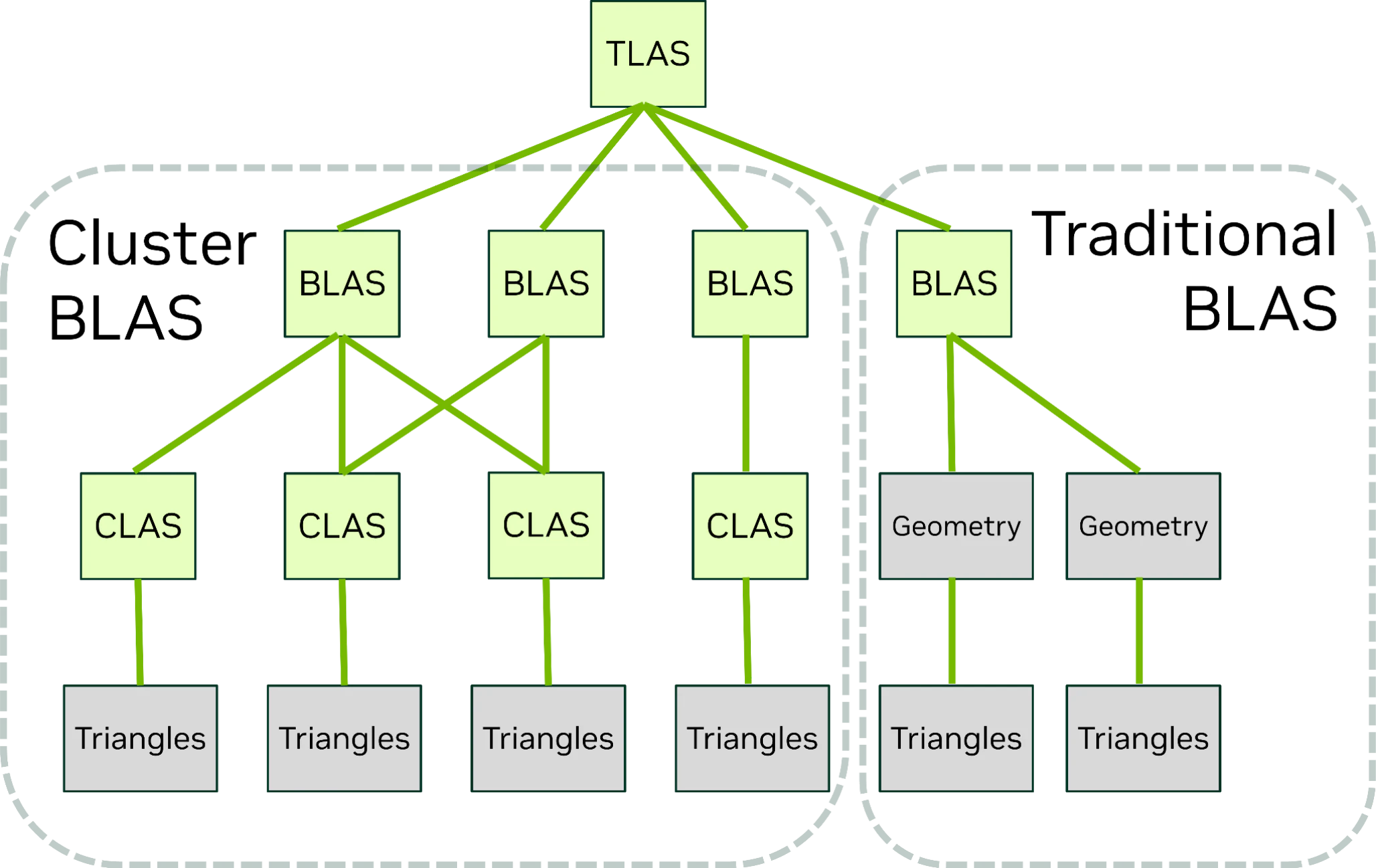
NVIDIA RTX BLACKWELL GPU ARCHITECTURE ⧉より
三角形集合に対して直接構築する従来のBLASと比較して、Cluster BLASはCLAS集合に対して構築するため、ASとしてのプリミティブ数は従来のBLASに比べて単純計算2桁以上(CLASあたり~256三角形持つため)少なくなります。前述の通りBVHなどのAS構築時間はプリミティブ数Nに対しておおよそO(N)となるため、従来のBLASを再構築するのに比べて圧倒的に高速に構築できます。もちろん、内包するCLASをすべて構築、Cluster BLASも構築、という状況であればトータルの処理時間は似たようなものになりますが、Cluster BLASでは構築済みのCLASに変更がなければ再利用することができます。
注意点として、あるメッシュをCLAS + Cluster BLASと従来のBLASで構築すれば後者のほうがレイトレーシング性能は高くなる(と期待される)ことがあります。従来のBLASはメッシュを構成する三角形集合全体に対して直接最適化を考えるASを構築する一方、CLAS + Cluster BLASでは各クラスター内での最適化とクラスター列をプリミティブとするCluster BLASの最適化、それぞれが独立でしか考えられないためです。あくまでCLAS + Cluster BLASはレイトレーシング時間に対して相対的にASの構築時間が大きくなるケースで意味を持ちます。
CLAS構築API
CLASを構築するAPIはOptiXでは以下のようになっています。DXRやVulkanでも関数名などは違いますが本質的には同じ仕様になっています。
OptixResult optixClusterAccelBuild(
OptiXDeviceContext context,
CUstream stream,
const OptixClusterAccelBuildModeDesc* buildModeDesc,
const OptixClusterAccelBuildInput* buildInput,
CUdeviceptr argsArray,
CUdeviceptr argsCount,
unsigned int argsStrideInBytes);
context や stream はDXRやVulkanにおけるコンテキスト、コマンドバッファーであって特に気にする点ではありません。先に5-7番目の引数について見てみます。5つ目の引数 CUdeviceptr argsArray はGPUアドレスで、ここでは後述する「クラスターごとの引数を表す構造体」の配列を指します。そして CUdeviceptr argsCount もGPUアドレスで、クラスター引数配列の要素数を指します。ここで注目すべき点は以下です。
- CLASごとの引数がGPUアドレスによる間接的な指定で内容を動的に変更可能。
- CLAS構築が
argsCountで指定された数まとめて行われる。 - またその数自体GPUアドレスによる間接的な指定で動的に変更可能。
クラスターごとの引数を表す構造体は以下のようなデータを持ちます。
struct OptixClusterAccelBuildInputTrianglesArgs {
unsigned int clusterId;
...
unsigned int triangleCount : 9;
unsigned int vertexCount : 9;
unsigned int positionTruncateBitCount : 6;
unsigned int indexFormat : 4;
...
unsigned short indexBufferStrideInBytes;
unsigned short vertexBufferStrideInBytes;
...
CUdeviceptr indexBuffer;
CUdeviceptr vertexBuffer;
...
};
この場であまり重要ではないメンバーに関しては省略しています。クラスターごとの頂点データや三角形データの指定ができることがわかります。 clusterId で設定した任意の32-bitデータはClosest-Hit Shader内で取得できます。少し面白い点として positionTruncationBitCount で指定したビット数、CLAS内に保持する頂点座標の下位ビットを切り捨てることができます。頂点座標が32-bit floatの精度を必要としていない場合切り捨てることによってCLASのメモリ消費を抑えられます。
続いて optixClusterAccelBuild の4つ目の引数 OptixClusterAccelBuildInput を見てみます。 optixClusterAccelBuild はCLASだけでなく後述のテンプレートやCluster BLASにも同じAPIを使用するので4つ目の引数 OptixClusterAccelBuildInput はtagged unionになっており、CLAS構築時の内容は次のようになっています。
struct OptixClusterAccelBuildInputTriangles {
OptixClusterAccelBuildFlags flags;
unsigned int maxArgCount;
OptixVertexFormat vertexFormat;
...
unsigned int maxTriangleCountPerArg;
unsigned int maxVertexCountPerArg;
unsigned int maxTotalTriangleCount;
unsigned int maxTotalVertexCount;
unsigned int minPositionTruncateBitCount;
};
ここではCLAS構築品質設定や同時に構築を行う最大CLAS数、CLAS間で共通なパラメターの保守的な見積もり値などを設定します。CLAS集合が必要とするメモリサイズやスクラッチメモリを問い合わせるAPI (optixClusterAccelComputeMemoryUsage)にもこの構造体を渡します。
最後に optixClusterAccelBuild の3つ目の引数を見ます。 optixClusterAccelBuild には3種類の動作モード、Implicit Destinationsモード, Explicit Destinationsモード, Get Sizesモードがあります。Implicitモードを使ったときの内容は次のようになっています。
struct OptixClusterAccelBuildModeDescImplicitDest {
CUdeviceptr outputBuffer;
size_t outputBufferSizeInBytes;
CUdeviceptr tempBuffer;
size_t tempBufferSizeInBytes;
CUdeviceptr outputHandlesBuffer;
unsigned int outputHandlesStrideInBytes;
CUdeviceptr outputSizesBuffer;
unsigned int outputSizesStrideInBytes;
};
ここで outputBuffer はCLAS集合が書き出されるメモリ、 tempBuffer はスクラッチメモリ、 outputHandlesBuffer はCLASそれぞれのハンドルが書き出されるメモリ、そして outputSizesBuffer はCLASそれぞれのサイズが書き出されるメモリです。Implicitモードの場合、 optixClusterAccelBuild で構築するCLASそれぞれは outputBuffer 中で順不同で書き込まれます。一方で outputHandlesBuffer と outputSizesBuffer には optixClusterAccelBuild の argsArray で渡したクラスター引数通りの順番でハンドル(CLASの場合はメモリアドレス)とサイズが書き込まれます。
Explicitモードの場合は、各CLASは別途指定したアドレスに書き出されます。その際各CLASを格納するのに必要なメモリサイズはGet Sizesモードで問い合わせます。
Cluster Template
CLASは前述のクラスター引数 OptixClusterAccelBuildInputTrianglesArgs で指定したデータから直接構築するだけでなく、BLASのリフィットのように事前に構築しておいたASのテンプレートに従って高速に構築することもできます。このとき使用するテンプレートのことをクラスターテンプレート(Cluster Template)と呼びます。クラスターテンプレート自体の作成時にはCLAS作成時と同じ OptixClusterAccelBuildInputTrianglesArgs を使用します。そしてテンプレートからCLASを実体化する際に以下に示す代わりのクラスター引数で情報を置き換えます。
struct OptixClusterAccelBuildInputTemplatesArgs {
unsigned int clusterIdOffset;
...
CUdeviceptr clusterTemplate;
CUdeviceptr vertexBuffer;
unsigned int vertexStrideInBytes;
};
三角形情報はテンプレート作成時に指定するデータなので実体化時には指定しません。ここでは基となるテンプレートアドレスに加えて、頂点データやクラスターIDの修正量を指定します。
クラスターテンプレートを用いたCLASの実体化はリフィットと似ていますが、異なる点として
- テンプレートを差し替えることでトポロジーを変更可能な点や、
- Cluster BLAS自体は再構築するので木構造としての上層が常に高品質になり、大きな変形量に対してもトラバーサル性能が安定する点
があります。リフィットに比べて再構築は重たい処理ですが、Cluster BLASの場合木のサイズが小さいので高速に実行できます。
Cluster BLAS構築API
Cluster BLASの構築もCLAS集合の構築と同じAPI optixClusterAccelBuild を用います。つまりCluster BLASもCLAS同様次の特徴を持っています。
- Cluster BLASごとの引数がGPUアドレスによる間接的な指定で内容を動的に変更可能。
- Cluster BLAS構築が
argsCountで指定された数まとめて行われる。 - またその数自体GPUアドレスによる間接的な指定で動的に変更可能。
構築API自体は同じですが、引数として渡す(union内の)構造体が異なります。Cluster BLASごとの引数と、Cluster BLAS集合全体の共通設定を表す構造体はそれぞれ以下のようになっています。
struct OptixClusterAccelBuildInputClustersArgs {
unsigned int clusterHandlesCount;
unsigned int clusterHandlesBufferStrideInBytes;
CUdeviceptr clusterHandlesBuffer;
};
struct OptixClusterAccelBuildInputClusters {
OptixClusterAccelBuildFlags flags;
unsigned int maxArgCount;
unsigned int maxTotalClusterCount;
unsigned int maxClusterCountPerArg;
};
Cluster BLASごとに渡すデータは非常に限られていて、CLASハンドル配列だけです。そして全体設定もかなり少なく、Cluster BLASの構築品質設定と同時に構築を行う最大Cluster BLAS数、Cluster BLAS間で共通なパラメターの保守的な見積もり少々です。
Partitioned TLAS
CLASに比べると地味ですが大きな追加としてもう一つ、Partitioned TLASという概念があります。従来はシーンすべてを内包するような巨大なTLASにおいて、一部のオブジェクトが動いただけでTLAS全体の再構築やリフィットが必要でした。ビルがたくさんある街のシーン中など、シーンの大部分が静的であると考えられる場合にはTLAS全体の再構築は非効率な処理になります。Partitioned TLASではBLASに対するCLAS + Cluster BLASのようにTLASを二階層にすることでTLASの再構築を効率化します。
さいごに
以上、紹介したようにMega Geometryで新設されたAPIでは、AS構築に関わるほとんどのパラメターをGPU上で動的に指定可能になっておりGPU-Drivenレンダリングとの相性が改善されていることがわかります。また、GPU-DrivenかつクラスターごとのAS構築が可能になったことで、レイトレーシングでも高密度なジオメトリを効率的に扱えるようになることが期待されます。既存のZバッファーベースの仮想化ジオメトリシステムと同一のジオメトリを扱えるようになることで従来必要だったダーティなハックも不要になると嬉しいですね。個人的にはいっそPrimary Visibilityもレイトレで完結できるともっと嬉しいなと思います。
Mega Geometryは優れたAPIだと思いますが、現状最大の欠点はDXRやVulkan Ray Tracingの標準仕様にはなっていないことですね。次のDXRやVulkan Ray Tracingの仕様で標準化されることを願います。
-> DXRの新仕様 ⧉ で検討中の様子。