データ分析基盤は学ぶべき内容の幅が広いですが、一旦全体像をまとめました。
進化が速い分野ですが、月日が経ってもあまり変わらない内容を中心に書いています。
参考書籍:
データマネジメント大全
データ分析基盤入門
実践的データ基盤の処方箋
データエンジニアリングの基礎
データ指向アプリケーションデザイン
ソフトウェアエンジニアリングの基礎
目次
1.データ分析基盤構築プロジェクトの基本ステップ
2.データサイエンスのニーズ階層
3.データエンジニアリングライフサイクル
3-1.生成
3-2.保存
3-3.取り込み
3-4.変換
4.テクノロジの選択
5.データエンジニアリングライフサイクルの底流
5-1.セキュリティ
5-2.データ管理
5-3.DataOps
5-4.データアーキテクチャ
5-5.オーケストレーション
5-6.ソフトウェアエンジニアリング
1.データ分析基盤構築プロジェクトの基本ステップ
1、プランニング
2、利用用途の決定
3、設計
4、構築
5、運用
1、プランニング
組織の目的と要望に沿って構築する必要があるため、プランニングにあたり、まず構築のための体制作りが重要。データ分析基盤構築の舵取りをするプロダクトオーナー、データ生成・蓄積・分析の現場担当者、ユーザーを巻き込み推進チームを構築する。その際、経営層も巻き込み現場主導の一過性で終わらないようにすることが重要。実際に構築するにあたっては、WBSを使用したスケジューリングを作成しタスクの棚卸し・納期の設定、担当者のアサインを行う。
2、利用用途の決定
プランニング後は要件定義を行い、「何のためにデータ分析基盤を構築するか」を明確にする。社内でデータ活用に困っているユースケースを活用すると良い。
3、設計
次にデータ分析基盤の技術的な設計を行う。
・どのデータを分析基盤上で使用したいか
・どのようにデータを収集するか
・収集したデータをどこに保管するか
・保管されたデータをどのように分析し、活用するか
ツールは様々あるため、目的に応じて選定を行う。
4、構築
実際に構築していく
・すでに自社内に蓄積されている構造化・非構造化データをデータレイクに移行する
・利用スコープに含まれるデータがデータレイクに蓄積されるようにデータ収集のワークフローを実装する
・汎用的に加工したデータをデータウェアハウスに配置する
・分析用に加工したデータマートを作成する
・データの可視化ツールを導入する
5、運用
一度構築したらそれで終わりではない。利用拡大に伴う機能改善や、モニタリング、効果測定をしていく。
・データ分析基盤が要望を満たす働きをしているか効果測定する
・データ分析基盤の利用状況をモニタリングする
・データ分析基盤の設計を定期的に見直す
・社内でコアユーザーを見つけ、データ分析基盤普及に協力してもらう
プランニング〜利用用途の決定 詳細
ユースケース
(顧客、ビジネスステークホルダーと協力)
ここでのユースケースは、データ分析基盤の用途を指す。
例えば、食品メーカーで考えられる施策として、
・サプライチェーン最適化
・在庫最適化
・売上や仕入れ数、広告コストのモニタリング
・商品開発におけるABテスト
などが挙げられるが、これらの施策に対し、以下の流れでユースケースを定める
ユースケースの定め方
1、事業についての目標、現状、課題、施策を洗い出す
2、データ活用施策の投資対効果を見立て、優先順位を定める
3、期待される効果と必要なコストを算出し、総合的に判断して優先順位を決める
上記ユースケースを実現するためにデータ分析基盤を整備することになるが、
データ基盤構築の目的=ユースケースの実現であり
開発・運用コスト < ユースケースの便益
が前提となる。
つまり実務においては、最初にユースケースを検討→データ活用方法検討→データ収集・投資の判断という流れとなる。
ユースケースについては、課題やニーズを深掘りし、解像度を上げていくことが重要かと思われるが、そこら辺については下記の書籍が個人的には参考になった。
解像度を上げる――曖昧な思考を明晰にする「深さ・広さ・構造・時間」の4視点と行動法
サービスレベルの設定・計測
サービスレベル=サービスの品質水準
サービスレベルはユースケース毎に以下の流れで設定、計測する。
1、目標設定
例えば、
・営業支援システムにおいて、「週次の売上データの集計が月曜日の8時までに終わっている」
・労務で使用するシステムにおいて、「勤怠情報の更新が毎朝7時までに終わっている」
といったものが挙げられる。使用する人や部署によりサービスレベルは異なる。例えば、前者の営業支援システムでの遅延率が5%は許容範囲かもしれないが、後者の労務システムでは許容できないなど。
2、関係者との合意
仮に遅延率目標を1%とした場合、それが達成可能かどうかをデータエンジニアやデータ生成者に確認する。
3、現状の計測
遅延率目標1%に対し、現状ではどの程度達成できているかを計測する。
課題の設定
現状の計測の結果、未達であれば何が問題かを分析する。
必要な施策の実施
問題を取り除くことができる施策を実施。
結果の振り返り
最後に、実施した施策によって結果がどうなったかを検証する。
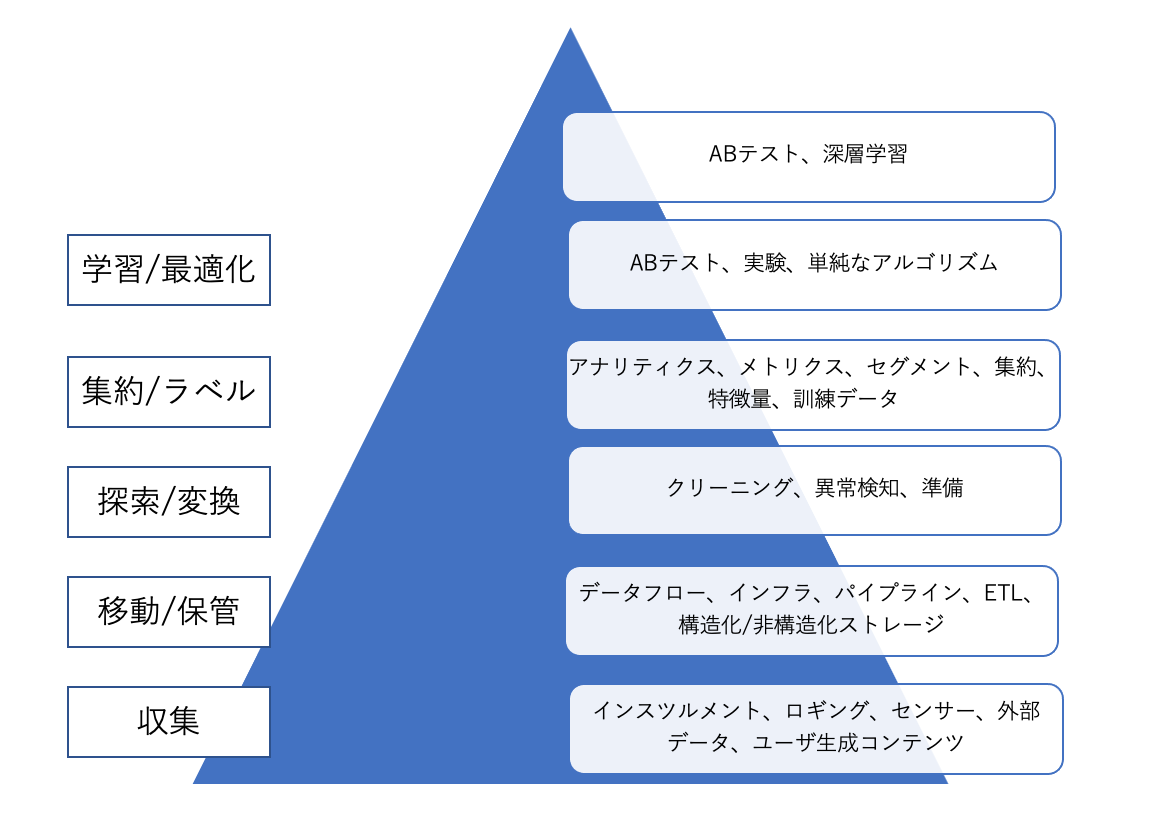
2.データサイエンスのニーズ階層
(エンジニア、アナリスト・サイエンティスト視点)
データサイエンティストやデータアナリストといったいわゆる「分析者」は90%以上の時間をピラミッドの最上層である分析、実験、機械学習に集中することが理想である。データエンジニアがこの階層の下層部分に注力することで、分析者が分析を成功させるための強固な基盤が構築できる。
データサイエンスが高度なアナリティクスやMLを行うのに対して、データエンジニアリングはデータの取得とデータからの価値の取得の間の溝をまたぐ役割を果たす。
3.データエンジニアリングライフサイクル
まず、本書の核となる概念がデータエンジニアリングライフサイクルと言われる下の図。
サイクルはまずデータが生成されるところから始まり、データを取り込み、分析できる形に変換、そして分析者へ提供という流れとなるが、データエンジニアはこの一連の流れを管理する役目を持つ。そして、この一連のライフサイクルを適切に構築する上で、図底流の6つの概念についても深い知見を持つ必要がある。
データ自体は入り口(データソース)から出口(ユースケース)に向かって流れていくが、思考の順番(ユースケースから考える)とは異なるので、あくまでデータ自体の流れとして捉える

3-1.生成
データの生成を知るには以下を理解する必要がある。
・大元のソースシステムがどのように動作しているか。
・データはどのような方法で生成されるか。人が入力、IoTデバイスからetc...
・データ生成の頻度と速度
・生成されるデータのバラエティ
ソースシステムの評価について:重要なエンジニアリング上の考慮点
ここでは、データの保存される期間、エラーの発生頻度、データの遅延有無、上流システムの特性、データ品質チェックなどについて考慮する必要がある。
重要な概念・キーワード
ファイルと非構造化データ
遭遇することが多いファイルフォーマット:Excel、CSV、TXT、JSON、XML
変更データキャプチャ(CDC)
データベースで発生した各変更イベント(挿入、更新、削除)を抽出する手法。
ログ
最低でも「誰が」「何を」「いつ」起こしたかを記録しなければいけない
ログのソースとしてよく知られているもの
・OS
・アプリケーション
・サーバ
・コンテナ
・ネットワーク
・IoTデバイス
インサートオンリー
レコードを更新せず、作成された時刻を示すタイムスタンプを付けて新しいレコードを挿入する。
メッセージとストリーム
メッセージ:2つ以上のシステム間で通信されるデータのこと
ストリーム:イベントレコードの追記のみのログである
データベーステクノロジの理解に役立つ観点
・データベース管理システム
・ルックアップ
・クエリオプティマイザ
・スケーリングと分散
・モデリングパターン
・CRUD
・一貫性
RDBMS
正規化されたスキーマ、ACIDコンプライアンス、高いトランザクションレートの全てをサポートするため、急速に変化するアプリケーション状態を保存するのに理想的。
NoSQL
メリット:
リレーショナル制約を削除することで、性能、スケーラビリティ、スキーマの柔軟性を向上させることができる。
デメリット:
強力な一貫性、JOIN、固定されたスキーマなど様々なRDBMSの特徴を放棄してしまう。
REST API
REST API (Representational State Transfer Application Programming Interface)とは、Webサービス間で情報をやり取りするためのルールや規約の集合体
データ共有
クラウドデータ共有のコアとなるのは、マルチテナントシステムがテナント間でデータを共有するに足るセキュリティポリシーをサポートすること。具体的には、細粒度のアクセス権限を持つパブリッククラウド上のオブジェクトストレージシステムは、データ共有のプラットフォームになり得る。
3-2.保存(ストレージ)
データ保存を知る際に重要な概念としてデータアクセス頻度が挙げられている。
| データ種類 | 内容 | 例 |
|---|---|---|
| ホットデータ | 最も頻繁にアクセスされるデータ | ECサイトの売上データなど |
| ウォームデータ | 週1や月1などたまにアクセスされるデータ | 月一の売り上げレポートなど |
| コールドデータ | いざという時以外は、ほとんどアクセスされないデータ | コンプライアンスや障害に備えて保存しておくデータ |
ストレージシステムの選択
ストレージシステムはどのような視点で選択、採用すべきかはユースケース、データ量、取り込み頻度、取り込むデータのフォーマット、サイズなどにより変わってくる。高性能であれば良いわけではなく、職場のデータ環境を分析し、適切なシステムを選択することが重要。
ストレージシステムの評価について:重要なエンジニアリング上の考慮点
アーキテクトが要求を満たす書き出し・読み込み速度、下流が要求するSLA(サービスレベルアグリーメント)、規制コンプライアンスに対応できるかなどを考慮する必要がある。
ストレージエンジンの選択
ストレージエンジンとは、データベースの物理的な読み書きを担当する低レベルコンポーネントであり、アプリケーションのワークロード特性に応じた選定が重要。
一から構築する必要はないが、選択を誤るとパフォーマンスに大きく影響する
2系統のストレージエンジン
・アプリケーションデータベース(OLTP)
頻繁な読み書きと更新に最適化
・OLTPデータベースは底レイテンシーと高並行性をサポート
・ACID特製
・OLTPは長期的にはアナリティクス向きではない。どこかの時点で構造的な制限や競合するトランザクションワークロードとの資源競合によって、性能問題に直面する。
・オンラインアナリティクス処理システム(OLAP)
大量データのスキャンや集計処理に最適化
・個々のレコードに対するルックアップの効率は高くない。
・最新のカラム型データベースは大量のデータをスキャンするために最適化されており、スケーラビリティとスキャン性能を向上させるためにインデックスを使用しない
3、OLTPとOLAPの違い
| 区分 | OLTP | OLAP |
|---|---|---|
| 主な用途 | 一般ユーザーによる日常的な操作 | アナリストによるデータ分析 |
| 代表操作 | 商品購入、予約登録、口座振替など | 売上集計、顧客分析、傾向把握など |
| データ構造 | 行指向ストレージ | 列指向ストレージ |
| クエリ負荷 | 軽量・高頻度 | 重量・低頻度(集計が中心) |
| 更新頻度 | 高い(トランザクションごと) | 低い(読み取り中心) |
インデックス
インデックスは、データベースから特定の値を高速に検索するための補助構造。
主なインデックスの種類:
▪️Bツリー(Balanced Tree)
・最も一般的なインデックス構造
・多くのリレーショナルデータベース(MySQL、PostgreSQLなど)や一部NoSQLで採用
・データは階層構造のツリーに配置されており、ページ(固定サイズのブロック)単位で管理
・範囲検索や順序付きデータの処理に強い
▪️ハッシュインデックス
・キーに対してハッシュ関数を適用し、対応する位置にデータを格納
・等価検索(完全一致)には高速だが、範囲検索はできない
・主にインメモリ型のストアやKVS(キー・バリュー・ストア)で用いられる
▪️SSTable(Sorted String Table)
データがキーでソートされた状態でファイルに格納されている
・主に書き込み性能を重視したストレージエンジン(例:LSMツリー)で使用される
主な特徴:
データをまとめてファイルに書き込む(追記型)
古いデータは後でマージ処理によって統合(コンパクション)
▪️LSMツリー(Log-Structured Merge Tree)
SSTableを階層的に管理し、書き込み性能を最大化する構造
書き込みは一旦メモリ内(MemTable)に保存 → バッファが満杯になるとディスクへ追記
定期的に複数のSSTableをマージし、ストレージの整合性を維持
特徴:
書き込みが高速(追記型)
読み取り時は複数のSSTableをスキャンする必要があるため、読み取り性能はやや劣る
代表的な実装:LevelDB、RocksDB、Cassandra
▪️Bツリー vs LSMツリー(使い分けの観点)
| 特徴 | Bツリー | LSMツリー |
|---|---|---|
| 読み取り性能 | 高速(ランダムアクセスに強い) | やや遅い(複数ファイルをスキャン) |
| 書き込み性能 | 中程度(更新のたびにツリーを調整) | 非常に高速(追記&バルクマージ) |
| 範囲検索 | 得意 | 可能だが最適化が必要 |
| ユースケース | OLTP(更新が多くない) | 高頻度の書き込みや大量挿入に強い(ログ、分析系) |
ETLの一般的な流れ
1、データの抽出(Extract)
OLTPシステムからリードオンリーの形でデータをコピー
2、データの変換(Transform)
分析しやすいスキーマ(例:スタースキーマ)へ整形・クレンジング
3、データの格納(Load)
データウェアハウスにロードされ、OLAPで活用される
ETLではなく、ELT(Extract, Load, Transform)もある。
データウェアハウス
データウェアハウスは、OLTPシステムから切り離された分析用データベースであり、アドホックなクエリをOLTPの負荷に影響を与えることなく実行可能にする仕組み。
スタースキーマとスノーフレークスキーマ
スタースキーマ
データウェアハウスでよく使われる構造。
中央にファクトテーブル(数値の記録)、周囲にディメンションテーブル(属性情報)を配置。
ファクトテーブルにはトランザクションや測定値などが格納される
スノーフレークスキーマ
スタースキーマのディメンションテーブルをさらに正規化し、階層的なサブディメンションに分割した形。
冗長性を削減できるが、クエリが複雑になることがある。
列指向ストレージ(Columnar Storage)
多くのOLTPでは行指向ストレージが使われている
・1行分のデータが連続して格納されており、トランザクション処理に適している。
一方、OLAPでは列指向ストレージが効果的:
・各列ごとにデータをまとめて格納
・典型的な分析クエリでは、数列しか使われないため不要な列の読み取りを省略できる
→結果として、読み取りパフォーマンスが大幅に向上
特に効果的な場面:
数百万〜数億レコードから「特定の列だけ集計」するようなクエリ
▪️マテリアライズドビュー
頻繁に実行される分析クエリの結果を、あらかじめ計算し保存しておく仕組み
通常のビューは「クエリの別名」に過ぎず、参照時に毎回実行されるが、
マテリアライズドビューは実際のクエリ結果をディスクに書き込み、キャッシュとして機能する。
メリット:
複雑なクエリの応答時間を短縮。
日次や週次での更新を行えば、リアルタイム性とパフォーマンスのバランスが取れる
3-3.取り込み
データエンジニアリングライフサイクルの中で最大のボトルネックは、ソースシステムとそこからのデータ取り出しであるとも言われる。
データ取り込みステージにおける重要な考慮点:
・取り込むユースケー
・再利用の可否
・誰に渡すデータか
・アクセス頻度
・データサイズ
など
データパイプラインとは:
データエンジニアリングライフサイクルのステージを経てデータを移動させるアーキテクチャ、システム、プロセスの組み合わせ
1、重要な検討事項
・ユースケース
・データを再利用して、取り込みを1度のみで終わらせられるか
・データは最終的にどうなるか
・ソースにおけるデータの更新頻度
・予想されるデータ量
・データのフォーマット(下流で変換して使えるか)
・データ品質
頻度
・データの配送にはレイテンシーがある。なので純粋にリアルタイムではなく、「ニアリアルタイム」
・ストリームデータ処理でも、下流ではバッチ処理されるのが一般的
スループットとスケーラビリティ
・データ量が増加し、要件が変化するにつれて、非常に重要になる
・必要なスループットに合わせて柔軟に拡大・縮小できるようにシステムを設計しよう
・データ生成の速度は一定ではなく波があることが多い。動的にスケーラブルなシステムであっても、システムがスケールしてストレージシステムがバーストに対応できるようになるまでの時間を稼ぐためのバッファが必要。
信頼性と耐久性
・データが取り込まれていれば、下流のプロセスが一時的に壊れても理論的には後から復旧可能
・リスクを評価し、データを失った場合の影響とコストに基づいて、適切なレベルの冗長性と自己修復性を構築しよう。
2、バッチ取り込みに関する検討事項
スナップショットまたは差分抽出
・ネットワークトラフィックとターゲットストレージの使用量を最小限に抑えるには差分抽出が理想的
・フルスナップ取り込みはシンプルなので依然として一般的に使われている
ファイルのエクスポートと取り込み
一般的なファイル交換方法:オブジェエクとストレージ、SFTP、EDI、SCPなど
挿入、更新とバッチサイズ
バッチ指向のシステムは少数の大きなバッチ操作に最適化されているので、多数の小さなバッチ操作を行うと性能が低下することが多い。
データの移行
データ移行においてスキーマ管理は非常に重要な検討事項
3、メッセージ取り込みとストリーム取り込みの検討事項
スキーマ進化
スキーマ進化:フィールドが追加・削除される、値の型が変更されるなど
・イベントデータ処理において多く発生する
・データパイプラインや受信側に意図しない影響を与える可能性がある
解決策:
・スキーマのバージョン管理
・デッドレターキューでイベントの問題を調査
・利害関係者とコミュニケーションを取り、スキーマ進化を事前に把握
遅延到着データ
・遅延到着したデータを処理するには、ある程度遅れて到着したデータを処理しないようにカットオフ時間を設定する必要がある。
順序と多重配送
・ストリーミングプラットフォームは一般に分散システムで構築されるため複雑な問題が起こる
例:メッセージが順番通りに送られない、複数回配送されるなど
3-4.変換
| 段階 | 説明 |
|---|---|
| 第1段階 | データを正しい型にマッピングし、レコードを標準的なフォーマットにし、おかしなデータを削除する。 |
| 第2段階 | このステージでは、データスキーマを変換し、正規化を行う場合もある。 |
| 第3段階 | 更に下流では、レポート作成のための大規模な集計を行ったり、ML処理のためにデータを特徴量化することがある。 |
変換フェーズで考慮するべき点
・変換のコストとROIは?ビジネス的な価値は?
・変換は可能な限り簡潔で、自己完結するようにできているか
・変換がサポートするビジネスルールは?
3-5.データの提供
1、アナリティクス
以下3分野がある。
・BI
・オペレーショナルアナリティクス
・組込みアナリティクス
2、機械学習
機械学習のプロフェッショナルである機械学習エンジニア、データサイエンティストなどとコミュニケーションしコラボレーションできるのが大事である。そのためにはMLの基本技術や関連するデータ処理要件、社内でのそのモデルのユースケース、社内の様々な分析チームの役割に精通している必要がある。
また、データエンジニアが他のチームと連携して、どちらのチームも単独で作れないようなツールを作ることが理想。
3、リバースETL
リバースETLとは、データエンジニアリングライフサイクルで処理され出力されたデータを、ソースシステムにフィードバックするもの。分析結果やスコアリングされたモデルなどを実運用システムやSaaSプラットフォームにフィードバックすることができる。
4.テクノロジの選択
アーキテクチャ=What、Why、When
ツール=How
テクノロジを選択する際に考慮すべき事項
・チームのサイズと容量
・市場投入までのスピード
・相互運用性
・コスト最適化とビジネス価値
・現在 vs 未来:不変テクノロジー vs 一過性テクノロジ
・設置場所(オンプレ、クラウド、ハイブリッドクライド、マルチクライド)
・構築 vs 購入
・モノリス vs モジュール
・サーバレス vs サーバ
・最適化、性能、ベンチマーク戦争
・データエンジニアリングライフサイクルの底流
以下詳細:
・市場投入までのスピード
立ち上げ、学習、反復、改善というフィードバックを構成する必要がある
・相互運用性
用いるテクノロジが簡単に接続できるか。モジュール化して設計し、新しいプラクティスや代替手段が利用可能になったら簡単にテクノロジを入れ替えられるようにしておく。
・コスト最適化とビジネス価値
組織はデータプロジェクトにプラスのROIを期待している。制御可能な基本的コストを理解しよう。
(総所有コスト(TCO)、所有の総機会費用、FinOps)
・現在 vs 未来:不変テクノロジー vs 一過性テクノロジ
現在と近い将来に最適なテクノロジーを選ぶべきだが、将来起きる予期できないことや進化に対応できるものにしよう。
普遍テクノロジー:クラウド(S3などのオブジェクトストレージ、ネットワーク、サーバー、セキュリティ)
一過性テクノロジー:JavaScriptのフロントエンド
・設置場所(オンプレ、クラウド、ハイブリッドクライド、マルチクライド)
クラウドに価値を見出す鍵は、クラウドの価格モデルを理解し、それに最適化すること。
いったんデータがクラウドに存在すると、取り出して別の場所にプロセスを移行するのはコストが高い。
・構築 vs 購入
ビジネスに競争上の優位がもたらせるなら構築やカスタマイズに投資する
そうでないなら市場にあるものを使う方が良い。(巨人の肩に乗る)
・モノリス vs モジュール
モノリス:1つのシステムで複数の機能を実現する
モノリスは理解しやすく、複雑さが小さいことが魅力だが、柔軟性の潜在的損失、機会費用、摩擦の大きい開発サイクル。
モノリスとモジュールを評価する際:
・相互運用性
・「狩猟トラップ」を避ける(簡単に入り込めるが抜け出すのは難しい)
・柔軟性
・サーバレス vs サーバ
最終的には抽象度の高いものが勝つ。まずサーバーレスの利用を検討し、サーバレスでうまくいかなければサーバを使おう。サーバを使う場合にも、可能であればコンテナやオーケストレーションを使おう。
4.データエンジニアリングにおける主要な底流
データエンジニアリングサイクルの過去と未来:
これまではテクノロジレイヤに焦点が置かれていたが、ツールとプラクティスの継続的な抽象化と簡素化により、データエンジニアの視点はよりバリューチェーンの上流へと遡り、データ管理やコストの最適化といった従来の企業活動や、DataOpsのような新しい活動を含むようになっている。
つまり、データエンジニアとして、技術よりもよりビジネス側の視点に焦点を移すべき(移すことができる)時が来たということだろうか。
4-1.セキュリティ
・データセキュリティとアクセスセキュリティの両方を理解し、最小権限の原則を実行するべし。
最小権限の原則:
必要な時に必要な人にだけ権限を与える
データは通信中であれ保存された状態であれ、不必要に可視状態になるべきではない。
→暗号化、トークン化、データマスキング、難読化、シンプルで堅牢なアクセス制御を用いる。
クラウドとオンプレミス両方のセキュリティのベストプラクティスを理解する。
→ユーザーとIAMのロールポリシー、グループ、ネットワークセキュリティ、パスワードポリシー、暗号化など。
4-2.データ管理
データ管理のキーワード:
データガバナンス
人、プロセス、技術を用いて、適切な安全性制御でデータを保護しつつ、組織全体でデータの価値を最大化させること
発見可能性
エンドユーザは業務に必要なデータに迅速かつ確実にアクセスできる必要があるので、データの出所や他のデータとの関連、データの意味を知ることができるようにしなければならない。
メタデータ
データに関するデータ。
データ品質
望ましい状態に向けてデータを最適化することであり、「期待したものが得られたか?」という問いに答えるもの。
| 内容 | 詳細 |
|---|---|
| 正確性 | 事実として正しいか。重複はないか。数値は正しいか。 |
| 完全性 | レコードは完全か。全ての必須項目に有効な値が得られているか。 |
| 適時性 | レコードは期限内に得られたか。 |
4-3.DataOps
DataOpsとはDevOpsと統計的プロセス制御をデータに適用すること。
初期の段階で手間をかけておけば、プロダクトの迅速なデリバリー、データの信頼性と精度の向上、ビジネス全体の価値の向上などの形で、長期的に大きな利益が得られる。
DevOpsには主に以下が含まれる
・自動化
・観測と監視
・インシデント対応
4-4.データアーキテクチャ
データエンジニアがやるべきこと:
ビジネスからの要請を理解し、新ユースケースから来る要求を集める
↓
これらの要請を翻訳し、データ取り込みする新しい方法を設計する
この際、コストと簡潔なオペレーションとの間でバランスを取る必要がある。
したがって、以下領域間のトレードオフを考える力必要がある。
・デザインパターン
・テクノロジ
・ソースシステムのツール
・データの取り込み
・補完、変換、提供
アーキテクトが期待されていること
・アーキテクチャ決定を下す
・アーキテクチャを継続的に分析する
・最新のトレンドを把握し続ける
・決定の順守を徹底する
・多様なものに触れ、経験している
・事業ドメインの知識を持っている
・対人スキルを持っている
・政治を理解し、舵取りをする
技術的な深さよりも技術的な幅を重視すると良い。
技術的な幅:詳しくはないが知っているもの、十分に知っているものを組み合わせる
例:1種類のキャッシュソフトウェアの専門家であるよりも、10種類のキャッシュソフトウェアそれぞれの長所と短所をよく押さえているほうが価値がある。
良いデータアーキテクチャの原則
AWS Well-Architected Frameworkによる原則
| No | 内容 |
|---|---|
| 原則1 | オペレーショナルエクセレンス |
| 原則2 | セキュリティ |
| 原則3 | 信頼性 |
| 原則4 | コスト最適化 |
| 原則5 | 持続可能性 |
Google Cloudの「5つの原則」
| No | 内容 |
|---|---|
| 原則1 | 自動化を前提に実装する |
| 原則2 | 状態をスマートに設計する |
| 原則3 | マネージドサービスを優先する |
| 原則4 | 深い防御を実践する |
| 原則5 | 常に設計し続ける |
『データエンジニアリングの基礎』から
| No | 内容 |
|---|---|
| 原則1 | 共通コンポーネントを賢く選択する |
| 原則2 | 障害に備える |
| 原則3 | スケーラビリティ設計 |
| 原則4 | アーキテクチャーはリーダーシップである |
| 原則5 | 常に設計し続ける |
| 原則6 | 疎結合システムを構築する |
| 原則7 | 可逆な決定をする |
| 原則8 | セキュリティを優先する |
| 原則9 | FinOpsを活用する |
アーキテクチャの法則
・アーキテクチャはトレードオフがすべて
・「どうやって」よりも「なぜ」の方が重要
アーキテクトらしく考えることの4つの側面
| No | 内容 |
|---|---|
| 1 | アーキテクチャと設計の違いを理解し、アーキテクチャを機能させるために、開発チームとどう協力するかが分かっている |
| 2 | ある程度の技術的な深さを維持しながらも、他人には見えないソリューションや可能性を見出せるような広範な技術知識を持つ |
| 3 | 様々なソリューションと技術の間にあるトレードオフを理解し、分析し、調整できる |
| 4 | ビジネスドライバーの重要性を理解し、それがどのようにアーキテクチャの関心ごとに反映されるかを理解している |
アーキテクチャと設計
アーキテクトは、ビジネス要件を分析してアーキテクチャ特性(-ility)を抽出・定義し、問題領域に適したアーキテクチャパターンやスタイルを選択し、コンポーネント(システムの構成要素)を作ることに責任を持つ
※-ility:Scalability, Agilityなど
アーキテクチャはトレードオフだが、どのソリューションが適しているかは「場合による」。デプロイ環境やビジネスドライバー、企業文化、予算、期間など多くの要因に依存する。
ビジネスドライバーを理解する
要件をアーキテクチャ特性(スケーラビリティ、パフォーマンス、可用性など)へ変換する必要がある。そのためには、事業ドメインの知識をある程度持ち、主要なビジネスステークホルダーと健全で協力的な関係を築く必要がある。
アーキテクチャの運用特性
| 用語 | 定義 |
|---|---|
| 可用性 | どれくらいの期間利用できるか |
| 継続性 | 障害復旧能力 |
| パフォーマンス | ストレステスト、ピーク分析、機能の使用頻度、容量、応答時間の分析 |
| 回復性 | 災害時からどれだけ早く回復させるかなど |
| 信頼性 / 安全性 | どれだけの影響があるか、人命に影響はないかなど |
| 堅牢性 | 接続切れた際や障害時に、エラーや境界条件を処理できるか |
| スケーラビリティ | ユーザー数、リクエスト数が増えてもシステムが動作できる能力 |
アーキテクチャの構造特性
| 用語 | 定義 |
|---|---|
| 構成容易性 | エンドユーザーがインターフェースを通してソフトウェエアの設定を簡単に変更できる |
| 拡張性 | 新しい機能をプラグインで追加可能にすることを意識する |
| インストール容易性 | プラットフォームへのインストールのしやすさ |
| 活用性/再利用性 | 複数の製品で共通のコンポーネントを利用できる |
| ローカライゼーション | 多言語への対応 |
| メンテナンス容易性 | 変更の適用、システムの拡張性が簡単に行えるか |
| 可搬性 | システムは複数のプラットフォームで動作する必要があるか |
| アップグレード容易性 | 旧バージョンから新バージョンへのアップグレードが簡単にできるか |
アーキテクチャの横断的特性
| 用語 | 定義 |
|---|---|
| アクセシビリティ | 色覚障害、難聴などの障害を持つユーザー含め、全てのユーザーのアクセスしやすさ |
| 長期保存性 | データが削除されるタイミング |
| 認証 | ユーザーが何者かを確認するためのセキュリティ要件 |
| 認可 | ユーザーがアプリケーションの特定の機能のみにアクセスできることを保証 |
| 合法性 | システムはどのような法的制約の中で運用されているか |
| プライバシー | 従業員から取引を隠せるか |
| セキュリティ | データやネットワークの暗号化の必要性、リモートユーザーのアクセスに対する認証 |
| サポート容易性 | アプリケーションにはどの程度の技術的サポートが必要か |
| ユーザビリティ | ユーザーが目標を達成するのに必要なトレーニングのレベル |
アーキテクチャ特性を明らかにする
ドメインのステークホルダーと協力してアーキテクチャ特性を定義する際は、サポートするアーキテクチャ特性の数を可能な限り絞ろう
→たくさんをサポートしすぎると、複雑化する
アーキテクチャ特性の最終的なリストをどうすべきか
アンチパターン: 優先順位づけする
おすすめ: ステークホルダーにリストの中から最も重要な上位3つを選んでもらう
ビジネス側、アーキテクト側でそれぞれの専門用語を使っていると会話が噛み合わなくなることがある。そのため翻訳が必要となる。
例:
| ドメインの関心ごと | アーキテクチャ特性 |
|---|---|
| 合併、買収 | 相互運用性、スケーラビリティ、適応性、拡張性 |
| 市場投入までの時間 | アジリティ、テスト容易性、デプロイ容易性 |
| ユーザー満足度 | パフォーマンス、可用性、耐障害性、テスト容易性、デプロイ容易性、アジリティ、セキュリティ |
特性は1つだけでは成り立たない
例:パフォーマンスが重要だと判断して、システムが高速でも正しく計算できていなければ意味がない。可用性、スケーラビリティなども考慮が必要となる。
4-5.オーケストレーション
オーケストレーションとは多数のジョブを、事前に決められた感覚で可能な限り素早く効率的に動作するように調整すること。
4-6.ソフトウェアエンジニアリング
データの取り込み、変換、データサービスのいずれであっても、データエンジニアは、Spark、SQL、Beamなどのフレームワークや言語に精通し、活用する技術を持っていなければならない。
以上