はじめに
最近、機械学習ネタを書いていなかったので、久々に、機械学習で記事を書こうとPyCaretを触っていたら色々新機能が増えており、中でも意外と便利な 「ゲインチャート」 が加わっていたので、使い方をご紹介してみたいと思います。
やること
ツールの使い方だけでは面白みが無いので、「ダイレクトマーケティングの効率化」 をお題(想定)としてゲインチャートがどう使えるか?を見て行きます。
設定
販促でお客様にカタログを送付するシナリオを考えます。
特に何も考えなければ、すべてのお客様にカタログを郵送すると思うのですが、やはり
コストがかかります。

本当は、
- 買う!、買うかも。なお客様にはカタログを郵送。
- 買わない。なお客様にはカタログは郵送しない。
がうまくコントロール出来ると、コストも下げられますし、エコですし、これを実現したい。
(ユーザ視点でも、不要なカタログは送付不要ですので、CS的にも良いかもです!)

使うデータセット
とは言え、適切なデータセットがあるわけではないので、Kaggleの下記データセットを一部いじって、「ダイレクトマーケティング」 っぽいデータを使った機械学習を進めていきたいと思います。
デモグラフィックデータで、「顧客特性」と「購入金額」を含み、このお題で使えそうです。
データ項目を簡単に確認しておきます。
- 元々は、#1~#9 の説明変数を用いて、目的変数の#10 支出額を説明、導出する為のデータセットですが
- 今回のテーマに合わせ分類問題としたいので、、
一定額以上の高額な支出が 見込めるか?否か? の2値分類としたいと思います。
| # | 列名 | 説明 | データ |
|---|---|---|---|
| 1 | Age | 顧客の年齢 | 年配/中年/若年 |
| 2 | Gender | 性別 | 男性/女性 |
| 3 | OwnHome | 住居 | 持ち家 or 賃貸 |
| 4 | Married | 結婚 | 独身 or 既婚 |
| 5 | Location | 家~店舗の距離 | 遠い/近い |
| 6 | Salary | 所得 | 連続値(ドル) |
| 7 | Children | 子供の人数 | 連続値(人数) |
| 8 | History | 過去の購入量 | 低/中/高 |
| 9 | Catalogs | カタログ送付数 | 連続値(送付数) |
| 10 | AmountSpent | 支出額 (目的変数) | 連続値(ドル) |
では、始めます
Kaggleのデータということで、KaggleのNotebook(Kernel)で進めたいと思います。
Google Colabとかを使う方は、データをダウンロードして頂ければと。
準備
KaggleのNotebookに、PyCaretをpipします。
相性の問題か、3.0RCや2.3の最近のVerだとうまくいかなかったので、2.3.6を使います。
pip install pycaret==2.3.6
そして、必要なものを一式、importしておきます。
import numpy as np
import pandas as pd
import seaborn as sns
import pycaret
print(pycaret.__version__) # 2.3.6ならOK
データ確認と前処理
まずは、pandasでロードし、データを確認します。
質的データは文字列、量的データは数値で表現されているので、そのままで大丈夫そうです。
df = pd.read_csv("/kaggle/input/direct-marketing/DirectMarketing.csv")
df
とりあえず、describeしておきます。
df.describe()
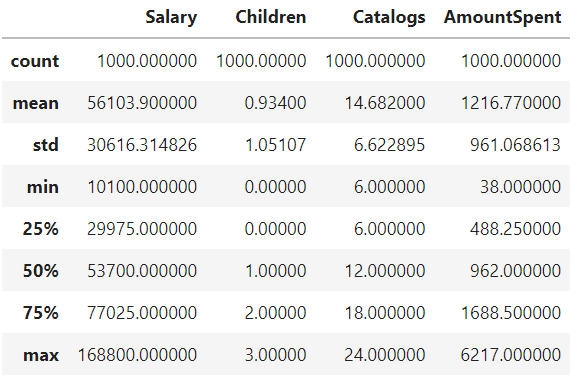
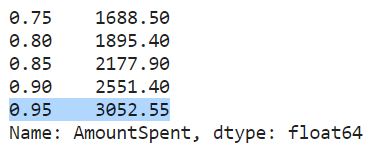
が、目的変数のAmountSpentを観るのに、四分位だと荒いので、、
5%刻みでのパーセンタイルを確認してみようと思います。
df["AmountSpent"].quantile(
np.arange(
0.75, # 75%タイルから
1, # 100%タイルまで
0.05 # 5%刻みで表示
)
)
sns.histplot(
df["AmountSpent"],
bins=20
)
なんとなく、購買金額の上位5%程度の顧客を買う!、買うかも。と見なすとリアリティがありそうです。
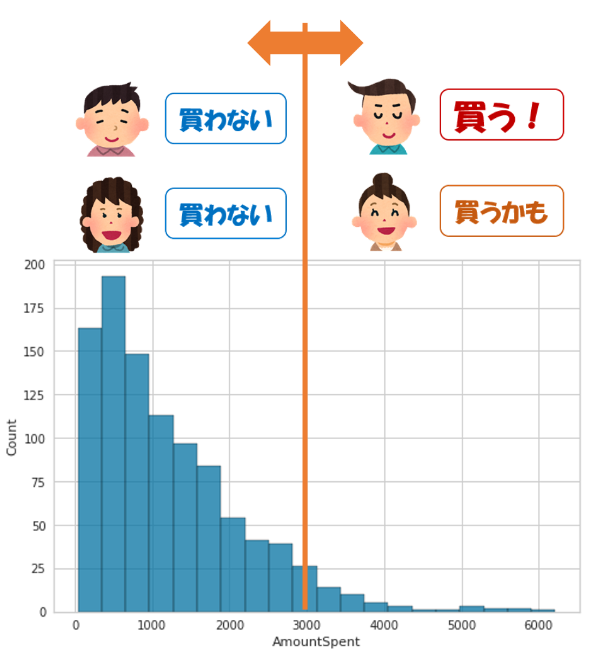
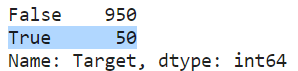
なので、AmountSpent > 3052 のユーザについて、購買フラグ(target)を立てます。
df["Target"] = df["AmountSpent"] > 3052
df["Target"].value_counts()
最後に、今回は目的変数がAmountSpentではなく、Targetですので、AmountSpentを消しておきます。
合わせて、こういったダイレクトマーケティング向けのデモグラフィーで、顧客の年収(Salary) が入手できているのも正直、違和感はあるのと、リークしそうなので合わせて削除しておきます。
df_train = df.drop(
columns=
[
"AmountSpent",
"Salary"
],
axis=1
)
df_train
これで前処理完了です!
PyCaretでモデル作成
では、ここからPyCaretを動かして行きます。まずは、setupなのですが、、
量的変数を正しく認識できるように、numeric_featuresにて、カラム名を指定しておきます。
from pycaret.classification import *
s = setup(
data=df_train,
target="Target",
numeric_features=
[
"Children",
"Catalogs"
],
)
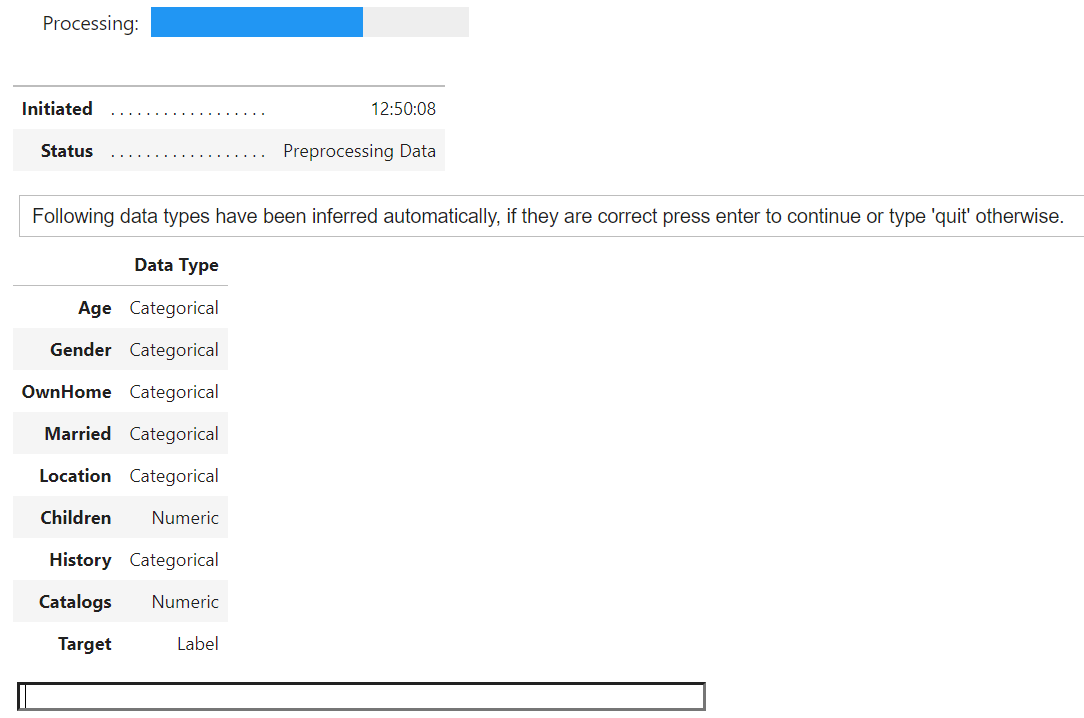
Data Typeが正しいことを確認したので、Enterを押下し、ステップを進めます。
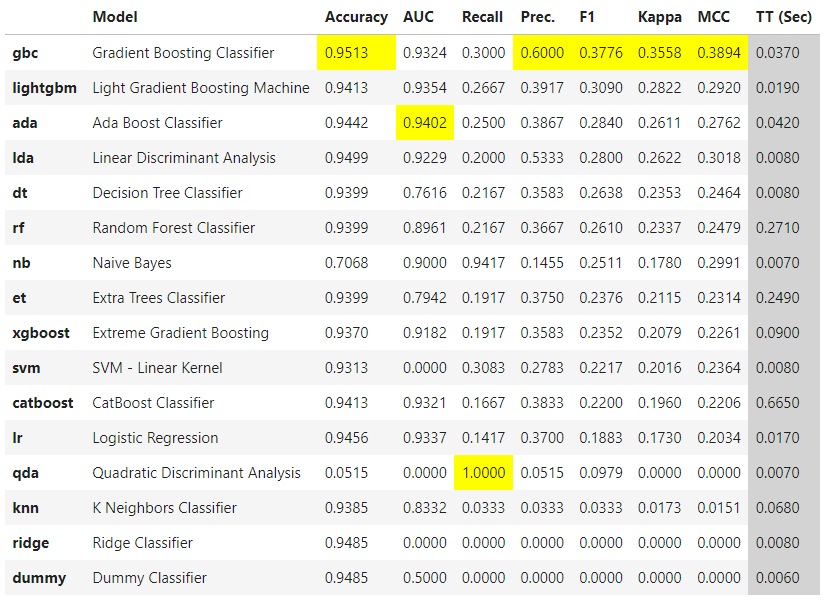
モデルをfittingしていくのですが、評価指標としては、 F-measure(F1)を指定します。
best = compare_models(
sort="F1"
)
- 要件として、Precision/Recallのバランスを取りたいので、その調和平均であるF-measureを使います1
- 今回の学習データは、正例:負例=1:19といった不均衡データで注意が必要ですが、マイノリティを正例としているのでF-measureでも正しく評価できます。
- なお、そういった事を気にしたく無い場合 MCC(マシューズ相関係数/Matthews Correlation Coefficient) を指定するという方法もあります。
詳細は、下記をご確認ください。
そして、best estimatorである勾配ブースティング分類器を可視化していきます。
evaluate_model(
estimator=best
)
これでやっと、今回使いたい、累積ゲインチャートを描く事ができました!
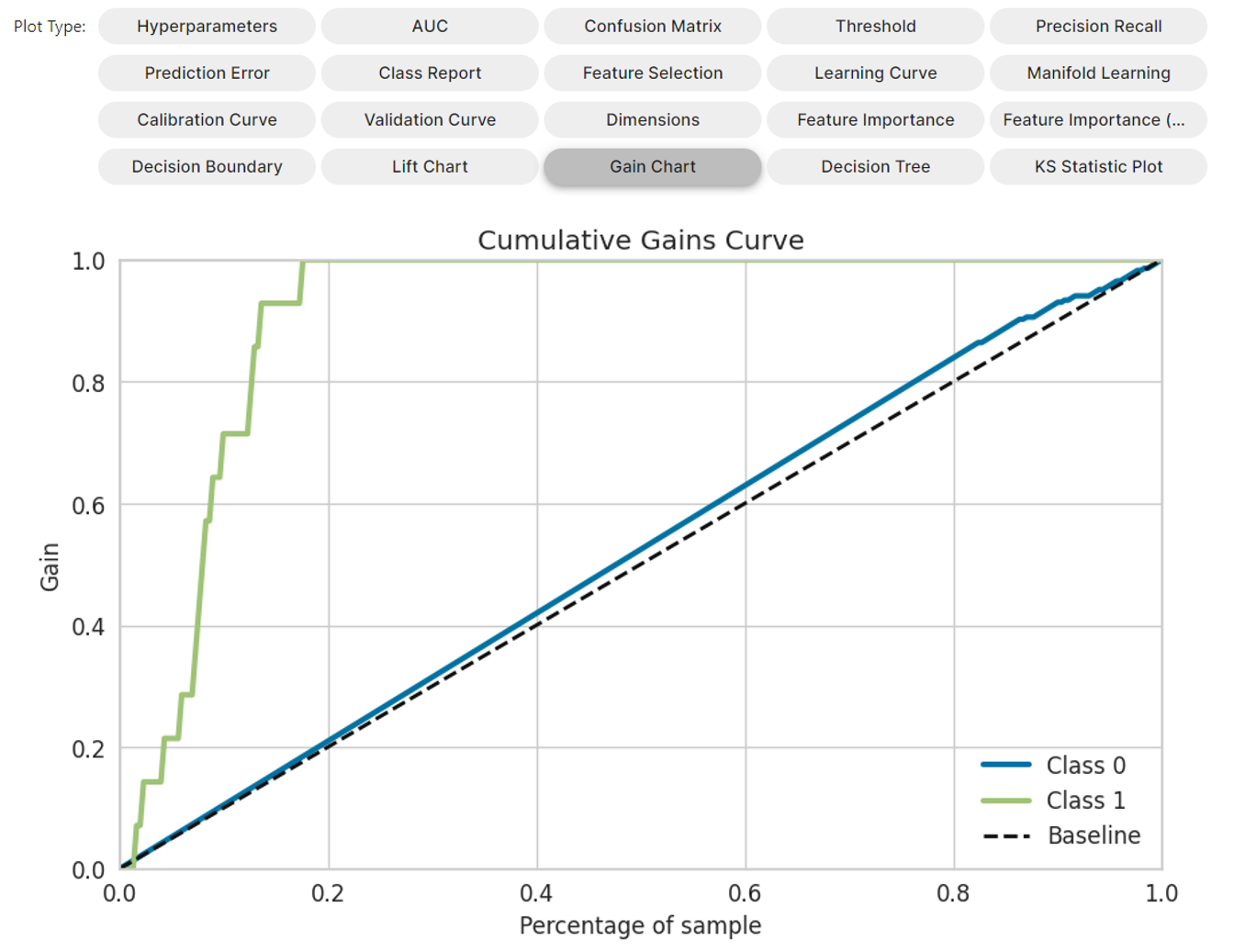
累積ゲインチャートについて
上記のゲインチャートの縦軸、横軸ですが、下記の通りです。
- 横軸 : 分類器が予測した「購入しそうな順2」に並んだ顧客
- 縦軸 : その「顧客」までの累積の反応率(真陽性率・Recall)
反応率(真陽性率・Recall)とは
実際にP(買う)の顧客のうち、P(買う)と正しく予測できた割合です。
Recall = \frac{TP}{TP + FN}
= \frac{\color{red}{①正しくP(買う)と予測できた数}}{\color{blue}{②実際にP(買う)の顧客の全量}}
混同行列で見ていくと、、

こんな感じです。ここで、TPとFNの意味について考えてみたいと思います。
- $ TP $:実際に「買う」お客さんで、予測として「買う」と予測できた。
- $ FN $:実際に「買う」お客さんだが、予測としては「買わない」と予測してしまった。
となります。では、Recallが100%とはどういった状況でしょうか。
Recallが100% = \frac{TP}{TP + FN} = \frac{100}{100 + 0} \Leftrightarrow FN = 0
式でみれば自明ですが、$ FN $が0人のとき、Recallが100%となります。
つまり、Recall100%で$FN=0$とは、
- A)実際に、「買う」お客さんの全員を、「買う」と予測した集合($TP + FP$)に含む。
- B)実際には「買わない」のお客さんだが、「買う」と予測してしまう誤り($FP$)は特に意識しない
ダイレクトマーケティングに応用する
Recallが高い予測モデルを利用すれば、実際に「買う」お客さんを逃すことなく、 DM、カタログ、クーポン等の販促施策を実行できます。
仮に、Recallが高い予測モデルにて、$ P $(買う)と予測された顧客全員に販促施策を実行します。
そのとき、この販促施策はどういった特性を持つかを、先述のA,Bに対応づけて考えると、
- A)実際に、「買う」お客さんの全員に、DM、カタログ等の販促施策が実行可能
- B)実際には「買わない」お客さんにも、DM、カタログ等を送ってしまうが、それはしょうがない。
つまり、Aの特性を優先し、想定見込み客の全量に対して販促施策を打つことを優先する。
そういった活用が可能です。
読み解きかた
読み解くのに必要な知識は説明できたので、実際にこのチャートを読み解いていきます。
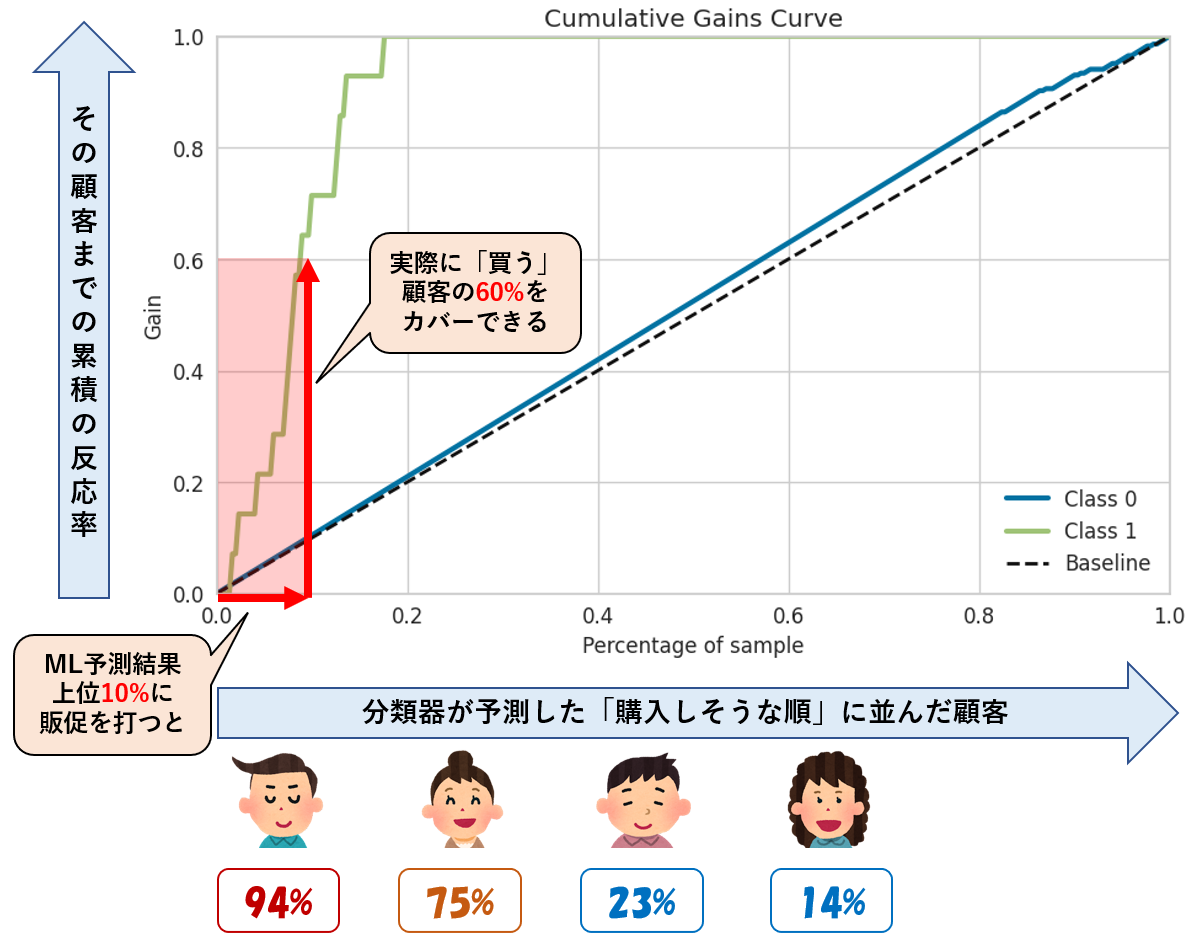
①上位10%に販促を打つと、ターゲットの60%をカバー可能
まずは、下記を読み解いていきます。
横軸は、分類器が予測した「購入しそうな順」に並んだ顧客ですので、左側の「0.0~0.1」の範囲には、「購入しそうな顧客」のTop10%(優良そうな顧客)が含まれています。
この顧客のトップ10%に、販促を打ったら、「実際に買う」とラベル付された顧客の何%をカバー出来るでしょうか?
そうです、0.1のところの縦軸の値を読み取れば良いのです。
縦軸の値は0.6。つまり、Top10%の顧客での累積のRecallは0.6ですので、販促でターゲットとしたい、実際に購入につながる顧客の60%をカバー出来ることを意味します。
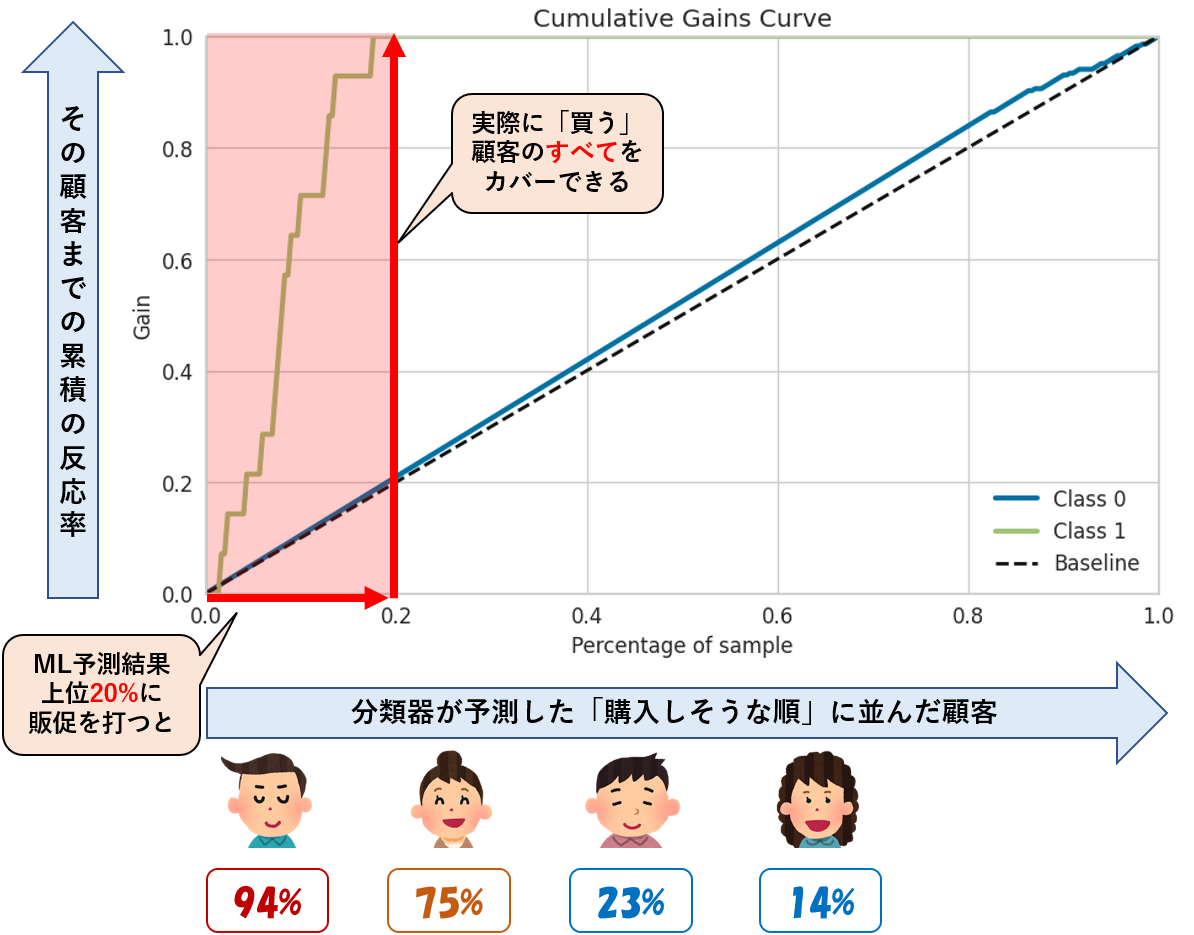
②上位20%に販促を打つと、ターゲットのすべてをカバー可能3
Top20%に販促を打つと、「実際に買う」とラベル付された顧客の何%をカバー可能でしょうか?
0.2のときの累積Recallは1.0ですので、このモデルにおいてはすべてのターゲットをカバー可能です。3
③理想の完璧な分類器だと
今回の設定では、P「買う」のラベルのデータは、全体の5%だったので、、
完璧な分類器では、上位5%に販促を打った時点で、Recall100%となります。
つまり、下記の赤線の様な累積ゲインチャートが描かれるのですが、、、
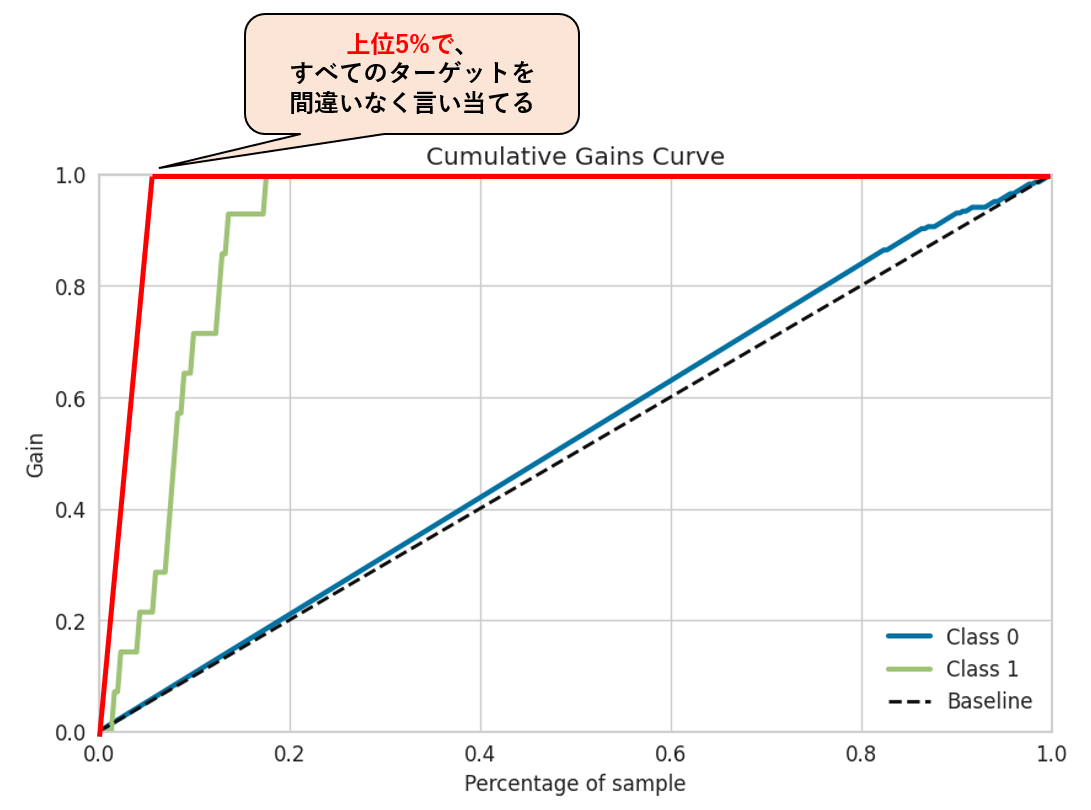
そんな完璧な分類器は現実的に作成困難で、リークしている可能性が高いので、
今回の結果をどう読み解けばよいかというと、
- Recall100%を上位5%で言い当てる完璧モデルと比べると、上位20%でRecall100%になる今回のモデルは見劣りするかもしれませんが、、
- 何も考えずに、すべての顧客に販促を打つ状況から比較すると、上位20%への販促でもRecall100%で全数販促と効果は一緒ですので、カタログ費用や郵送費用は80%削減(出来るかもしれない)
と考えることが出来るのでは無いでしょうか?
まとめ
- PyCaretのVerUpに伴い追加された、累積ゲインチャートについて説明しました。
- グラフの見方だけを説明してもつまらないので、ダイレクトマーケティングのトイデータを用いて、販促業務の改善といった例題で、累積ゲインチャートの使い方を見ていきました。
- トイデータの特性か、かなり性能の良いモデルができてしまい、上位20%でそれまでの累積Recall100%という状況でしたが、考え方はお伝え出来たと思います。
- ぜひ、皆さんの身近なテーマで、PyCaretを活用いただければと思います。
- なお、反響があれば、類するテーマで別の記事も書いてみたいと思います。
補足
今回は簡単のために、問題を単純化して扱いましたが、実際には、
- モデルが重視する特徴量が、現場のマーケターの感覚と一致するか(納得性)
- 過去の累積データは、今回対象とする商材のマーケティングを説明可能か、適切か?
- 累積顧客データは基本的に過去からの蓄積されたデータであり、集計期間をどう取扱か?
- 施策を繰り返す場合に、前回の販促の介入効果を割り引いた検討が必要(差の差等)
- LTVを考慮した場合の販促検討
等々、色々検討すべき事項はあると思います。
実際の累積ゲイン曲線
利用したトイデータの特性か、今回作ったモデルは、よく出来すぎていました。
実際には、こんな感じとなります。
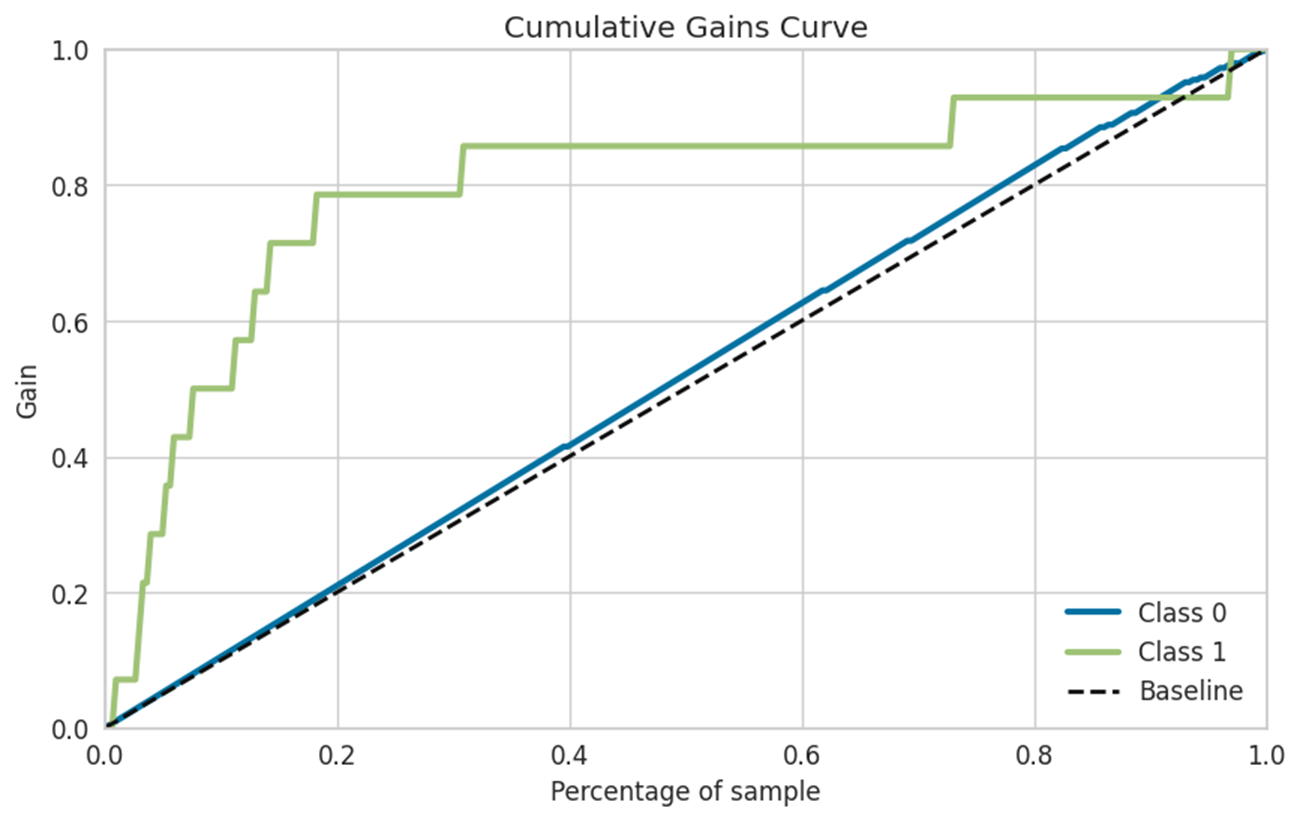
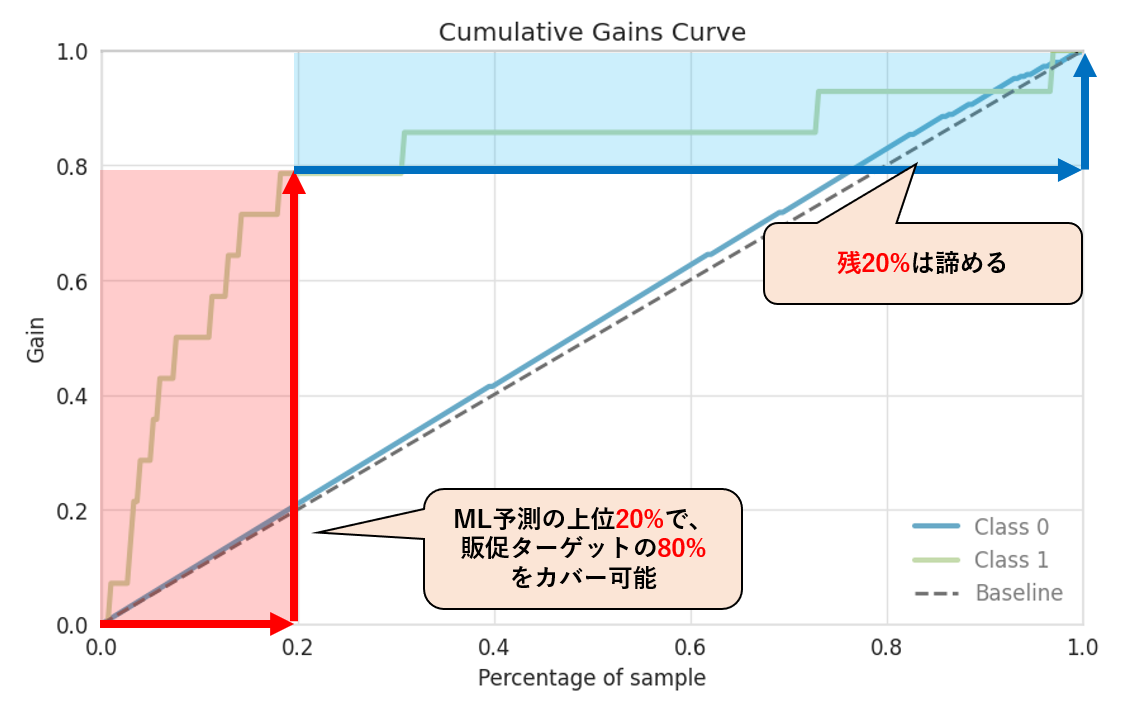
つまり、
- ML予測結果に基づき上位20%に販促を打てば、ターゲットの80%がカバー可能
- カバー率100%にするためには、残りの80%の顧客(ほぼ全数)に販促を打つ必要があり
- 残20%のターゲットへの販促は諦める。
- もしくは、残20%のターゲット向けの販促は別手段(Email等)で実施する。
等々の議論があるかと思います。
リンク
以前に書いたPyCaretの記事をリンクしておきます。