はじめに
- PyCaret2.0が、Nightlyビルド版で公開されており、試してみました。
- PyCaret自体については、以前投稿させて頂いた下記もご確認ください。
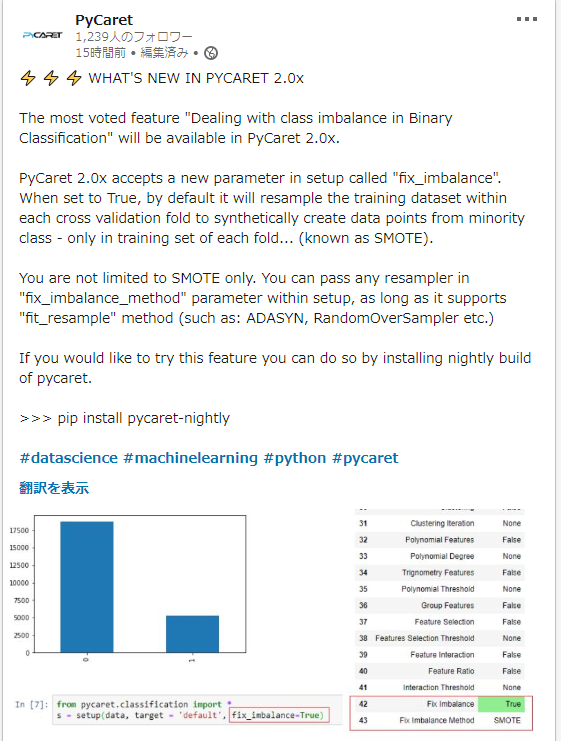
- v2では下記のように、不均衡データに対しての前処理が追加されているようなので、試してみたいと思います。
試し方
- pipしてください。
pip install pycaret-nightly
- pipすると、version 2.0.0を試すことができます。
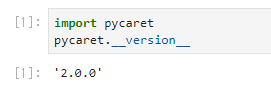
試す
不均衡データに対する前処理
- v2では、2値分類での不均衡(正例、負例の一方がごく少数)データに対する前処理が追加されています。
- 指定方法は簡単で、setupする際の引数にて、fix_imbalance=True を指定します。
from pycaret.classification import *
exp1 = setup(
data,
target = 'default',
fix_imbalance=True # この行を追加
)
- この指定により、不均衡データに対する前処理が実施されます。
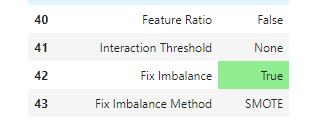
実施される前処理(SMOTE)
- 上記画像のとおり、SMOTE(Synthetic Minority Over-sampling TEchnique)がデフォルトの様です。
- SMOTEについては、Qiitaにも解説記事ありますのでリンクさせていただきます。
他の前処理
- 冒頭の記事にあったとおり、ADASYNやRandomOverSampler等にも対応しているようです。
- 内部的には、v2(Nightlyビルド版)では、依存ライブラリに、imbalanced-learnが追加されています。
- docstringにも下記の記述がありますね。
fix_imbalance_method: obj, default = None
When fix_imbalance is set to True and fix_imbalance_method is None, 'smote' is applied
by default to oversample minority class during cross validation. This parameter
accepts any module from 'imblearn' that supports 'fit_resample' method.
他の前処理の指定方法
- 上記のdocstringの指示のとおり、imblearnのclassを指定してみたいと思います。
- imblearn.over_samplingから指定するover_samplingアルゴリズムをimportして指定します。
from pycaret.classification import *
from imblearn.over_sampling import ADASYN, BorderlineSMOTE, KMeansSMOTE, RandomOverSampler, SMOTE, SMOTENC, SVMSMOTE
exp1 = setup(
data,
target = 'default',
fix_imbalance=True,
fix_imbalance_method=ADASYN() # この行で指定
)
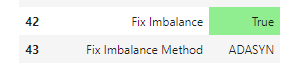
指定できたアルゴリズム
- 下記の通りです。
- imblearn.over_sampling.ADASYN
- imblearn.over_sampling.BorderlineSMOTE
- imblearn.over_sampling.KMeansSMOTE
- imblearn.over_sampling.RandomOverSampler
- imblearn.over_sampling.SMOTE ※デフォルト
- imblearn.over_sampling.SVMSMOTE
モデル評価時の表示上の工夫
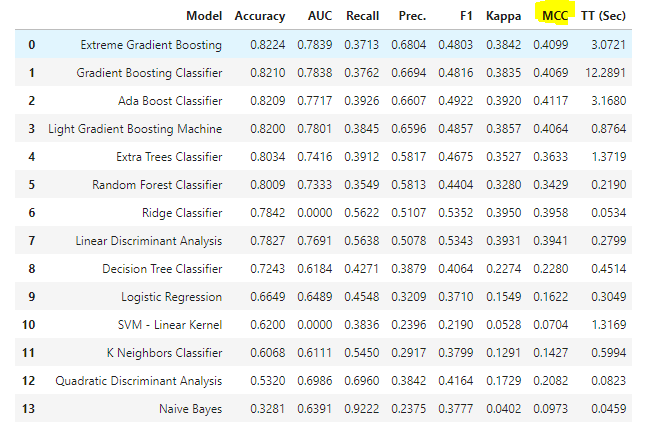
- 不均衡データに対する前処理の実装と共に、精度一覧上にMCC(Matthews相関係数)が追加されています。
- 少数(マイノリティ)クラスを正例としている場合では、F-measureでも良いのですが、そういった考慮ができていない状況でも、MCCは不均衡データに対する学習精度を正しく評価できるので良いですね。
- 不均衡データ時の、F-measureとMCCの関係性はこちらのブログが参考になるのでリンクさせていただきます。
最後に
- 今回は、v2の不均衡データに対する対応をご紹介しました。
- これ以外にも、mlflowへの対応等が計画されているようで、v2の正式リリースが楽しみです。
- 雑な記事となりましたが、最後までお付き合い頂きありがとうございます。
関連記事