追記 2020/07/02
本記事は sagemaker-containers について言及をしていますが、本pip moduleはdeprecatedとなっており、sagemaker-training-toolkitを参照していただくことを強くおすすめします。
追記終わり。
どうも@shirakiyaです。普段はアルゴリズムソリューションを提供しているベンチャー企業にて機械学習を使ったWebアプリケーションの開発をしています。
この記事ではAmazon SageMakerのトレーニングで任意の処理を実行しつつ学習済みモデルを得る方法に関し、
- 全て自前でコンテナを用意してトレーニングする方法
- Amazon SageMaker コンテナを用いてトレーニングする方法
の2種類のそれぞれについて説明を行います。
Amazon SageMakerトレーニング概要
この記事の読者にはあまり説明不要かと思いますがそもそもAmazon SageMaker(以下Sagemakerと言います)とは以下の3つの機能の集合体であるAWS機械学習サービスです。1
- データの整形やモデルの開発
- モデルをトレーニングする(本記事ではこれを「トレーニング」と言います)
- モデルをデプロイする
追記(2019/12/01)
「サンプルデータの生成」から「データの整形やモデルの開発」に変更しました。
Notebookインスタンスから提供されるJupyter Notebookを使ってサンプルデータの生成以外にも色々できるためです。
「トレーニング」は簡単に言うと「学習を行い、学習済みモデルを作成すること」を完全マネージドで行うことができる機能です。個人的に感じているSageMakerのトレーニングを使うメリットは、
- JupyterLab/Jupyter Notebookが利用可能なインスタンスを簡単に立てることができる
- そのノートブックインスタンス経由でSageMakerが用意しているアルゴリズムを簡単に試すことができる
- 学習で利用するインスタンスの「インスタンスタイプ(CPU/Memory)」「GPUの有無」を簡単に指定可能
- SageMaker APIへのリクエスト一つで、Dockerコンテナを立てて学習を行うことができる
- スポットインスタンスを用いたトレーニングが提供されている(マネージドスポットトレーニング)
と考えています。(他にもメリットはあるかと思いますが、詳細については公式ページから確認してください。)
この最後の「SageMaker APIへのリクエスト一つで、Dockerコンテナを立てて学習を行うことができる」が素晴らしく、EC2・ECS・AWS Batch等と違いインフラレイヤーを管理する必要がなく、このマネージドさがアプリケーションを構築するエンジニアにとっては大きなメリットと考えられるところだと思います。
(余談)ただこのトレーニングの構築について、やや公式ドキュメントの構成や書き方が(個人的に)わかりづらく苦労したポイントだったので今回この記事を書こうと思ったのでした
Amazon SageMaker トレーニングは具体的に何をしている?
気になるところはこのSageMakerのトレーニングとは具体でどういう動きをするのかだと思います。それが図示されているのが以下の公式で掲載されている図です。(Amazon SageMaker によるモデルのトレーニング - Amazon SageMaker より引用)
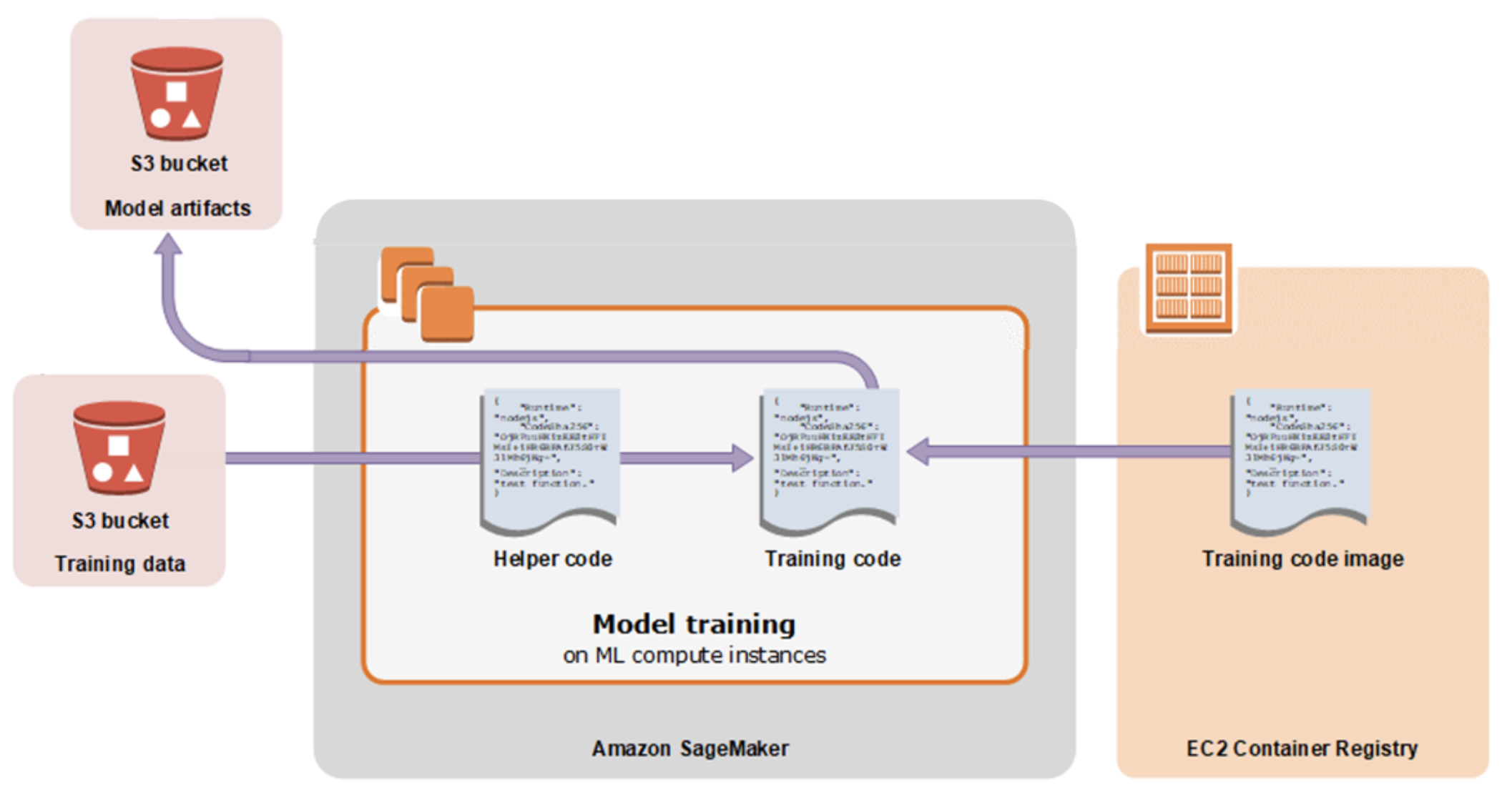
一般的なトレーニングの動きを流れで説明すると、
- (Helper code → Training code)Helper codeから(ハイパーパラメータ等の情報と共に)トレーニングジョブ開始のリクエストを送る
- (Training code image(ECR) → Training code)ECR上のTraining codeが格納されたDockerイメージを元に学習コンテナが立つ(※Dockerイメージ自体にTraining codeが入ってないケースもありえる)
- (Training data(S3) → Training code)S3にある学習関連データが学習コンテナに配置される
- Training codeの実行
- (Training code → Model artifacts(S3))学習済みモデルをS3へ保存する
1に登場するHelper codeはSageMakerのJupyter Notebookで作成されたコードでも、別アプリケーションのコードでも理論上OKです。なおSageMakerの公式チュートリアル2で、Jupyter Notebookで構築しているのがコードがHelper codeに該当します。
この動きの点から、データセット・Helper codeは、Training code image / Training code をどのように準備するのかがSageMaker トレーニングの構築には重要なポイントです。
Amazon SageMaker トレーニング の構築/実行方法はいくつかある
SageMakerではトレーニング構築/実行に以下の方法が提供されています。これらは要するに Traning code image / Training codeをどう準備するかのオプション です。
| 方法 | 説明 |
|---|---|
| SageMakerによって提供されるアルゴリズムを使用する方法 | SageMakerが用意しているアルゴリズム(Training code)をそのまま利用し、学習済みモデルを得る。学習モデルに独自の処理を入れられない一方で、Training codeを用意しなくて済む。https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/algos.html |
| Amazon Marketplaceによって提供されるアルゴリズムを使用する方法 | Amazon Marketplaceで提供されているアルゴリズム(Training code)を利用し、学習済みモデルを得る。https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/sagemaker-mkt-find-subscribe.html |
| Apache Spark を使用する方法 | Apache Sparkを使ってデータの供給・前処理・モデル作成を行う方法。SageMaker側で学習済みモデルをホストすることができる。https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/apache-spark.html |
| 構築済みのコンテナを利用する方法 | TensorFlow, MXNet, PyTorch, Chainer, Scikit-learnを利用する場合、AWSが提供する構築済みのコンテナが利用できるため、1つのTraining Codeファイルを用意するだけでトレーニングが実行でき便利。https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/pre-built-containers-frameworks-deep-learning.html |
| 独自アルゴリズムを使った方法 | Training code image、Traning codeを全て自前で用意する方法。学習時での独自の処理や特有の依存ライブラリがあるがある場合など。https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/your-algorithms.html |
( https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/how-it-works-training.html を参考。)
追記(2019/12/01)
「TensorFlowまたはApache MXNetを使用するカスタムPythonコードを送信する方法」から「構築済みのコンテナを利用する方法」に変更しました。
TensorFlow・Apache MXNetだけでなく、PyTorch・Chainer・Scikit-learnもサポートされていることがわかったためです。
今回この記事で説明を行うのはこの表の最後の行、独自アルゴリズムを使った方法についてです。
実際、日本語の自然言語処理を行う場合だと形態素解析器にMeCabを使うケースもあるかと思いますが、当然SageMakerから提供されるアルゴリズムの中にはMeCabを用いた自然言語処理に関するものは存在しません。3 そうなるとMeCabを予めインストールした環境を用意する必要があります。これは一例ですが、このように任意の環境・任意のアルゴリズムを用いてトレーニングがしたいということが多々あります。
それ、ちゃんとAamazon SageMakerでできます。
かなり前置きが長くなってしまいましたが、次に本題である独自アルゴリズムを使ってトレーニングを構築する方法について述べていきます。
独自アルゴリズムを使ってトレーニングを組む方法
SageMakerで独自アルゴリズムを使ってトレーニングを組む方法は大きく2つあります。
- 全て自前でコンテナを用意してトレーニングする方法
- Amazon SageMaker コンテナを用いてトレーニングする方法
2の「Amazon SageMaker コンテナ」とは sagemaker-containers というPythonライブラリのことで、Train code imageと呼ばれるDockerイメージにこのライブラリを用いるかどうかで用意するTrarning codeの実装が異なります。今回はこの違いに注目しつつトレーニングに必要な実装を説明していきます。
SageMakerのTraining code imageについて
SageMakerトレーニングで用いられるディレクトリ
SageMakerトレーニングで用いるTrarning code image(Dockerイメージ)は以下のディレクトリ構造が予約されています。
opt
├── train
│
└── ml
├── train <-- 学習を行うPythonスクリプト。今回は適当にtrainという名前を付けているが何でもOK
├── input
│ ├── config
│ │ ├── hyperparameters.json <-- トレーニング作成時に指定したハイパーパラメータが記載されたJSON
│ │ ├── inputdataconfig.json <-- データチャネルの詳細情報が記載されたJSON
│ │ └── resourceconfig.json <-- 分散型トレーニングで利用するコンテナ情報が記載されたJSON
│ └── data
│ └── {チャネル名} <-- チャネルとはトレーニング作成時に学習用データのラベルのようなもの
│ └── ここに設定したS3のlocation以下の内容がsyncされる
├── model
│ └── ここに置かれたデータがトレーニング終了時に出力先として設定したS3のパスに転送される
└── output
└── failure <-- train失敗の理由を書き込む
/opt/ml/以下がSageMakerが用いるディレクトリで、これらのディレクトリ・ファイルの配置を理解するのがSageMakerトレーニングで独自アルゴリズムを使って構築する際には重要です。
SageMaker トレーニングのコンテナの実行
SageMaker トレーニングではTraning code imageを使ってコンテナを実行する際、以下のコマンドが実行されます。
docker run {image} train
このことから train という実行可能なコマンドにパスを通しておく必要があります。
(sagemaker-containersを使わず)全て自前でトレーニングする方法
Training code
学習を行う側のサンプルコードを以下に示します。
# !/usr/bin/env python
import json
import os
import pandas as pd
HYPERPARAMETER_JSON_PATH = "/opt/ml/input/config/hyperparameters.json"
TRAIN_DIR = "/opt/ml/input/data/train" # <-- ①
MODEL_DIR = "/opt/ml/model" # <-- ②
class Model:
def __init__(self, params):
self.params = params
def fit(self, data):
pass
def save(self, model_dir):
pass
def train(hyperparameters):
# 学習データの取得
train_filepath = os.path.join(TRAIN_DIR, "train.csv")
data = pd.read_csv(train_filepath)
# モデルの学習
model = Model(hyperparameters)
model.fit(train_data)
# モデルの保存
model.save(MODEL_DIR)
if __name__ == "__main__":
with open(HYPERPARAMETER_JSON_PATH, "r") as f: # <-- ③
hyperparameters = json.load(f)
train(hyperparameters)
ここでのポイントは3つです。
①データは/opt/ml/input/data/{チャネル名}以下に配置されている_
上記のサンプルコードでは train というチャネルを設定している場合を想定したものです。
②モデルの保存などはパスを指定して保存する
SageMakerトレーニングでは前述の通り /opt/ml/model/ 以下に保存したデータが自動でS3に転送されるため、トレーニングの生成物として保存したいデータはこのディレクトリ以下に置きます。
③hyperparameterはJSONファイルから取得する
後述しますが、SageMakerトレーニング作成時に指定するhyperparametersは/opt/ml/input/config/hyperparameters.jsonから読む必要があります。
※これらのポイントを抑えるためにも、全て自前で書く場合はSageMakerが予約しているディレクトリの知識が必要だったというわけです。
Training code image のDockerfile
上記のtrain.pyを使ってトレーニング時に使用するイメージのDockerfileをサンプルとして以下に示します。ここでは自前の学習プログラムを/opt/ml/code/ 以下に置くことにし、依存モジュールをインストールするためにrequirements.txtをpip installすることとしています。
FROM python:3.6.9
ENV PROGRAM_DIR=/opt/ml/code
RUN mkdir -p $PROGRAM_DIR
WORKDIR $PROGRAM_DIR
COPY requirements.txt $PROGRAM_DIR/requirements.txt
RUN pip install -U pip && \
pip install -r requirements.txt --no-cache-dir
COPY train.py $PROGRAM_DIR/train # <-- ①
ENV PATH=$PATH:$PROGRAM_DIR # <-- ②
RUN chmod +x train # <-- ③
ここでのポイントは3つあります。
①trainコマンドを用意する
前述の通り、SageMakerトレーニングのコンテナ起動時にはtrainというコマンドが叩かれるため、その対象となるべくentrypointとなるスクリプトはtrainというファイル名にしておきます。
②trainコマンドにパスを通す
③実行権限を与える
trainと叩かれるため、パスを通し・実行権限を与えておく必要があります。
トレーニングの実行
トレーニングを実行するのはAWS環境・開発環境で分けて記載すると以下の方法があります。
- AWS環境で実行
- AWSコンソールからトレーニングジョブを作成する
- sagemaker-sdkから実行する
- 開発環境で実行
-
docker run {イメージ名} trainを実行する - sagemaker-sdkからlocalモードで実行する
-
AWSコンソールからトレーニングジョブを作成することや、docker runを叩いていて実行することは特別説明しなくてもよいかと思いますので、今回はsagemaker-sdkを利用するケースについて説明を追加します。
sagemaker-sdkから実行する
sagemaker-python-sdk を用いることでトレーニングジョブを簡単に作成することができます。
from sagemaker.estimator import Estimator
estimator = Estimator(
image_name="sample_image:latest",
role="sample-SageMaker-role",
train_instance_type="ml.p2.xlarge",
train_instance_count=1,
hyperparameters={"learning_late": 0.01},
)
estimator.fit({"some_channel": "s3://my_bucket/my_training_data/"})
このとき予め"sample_image:latest"がECRに存在すること、また必要なポリシーがアタッチされた"sample-SageMaker-role"という名称のIAMロールが存在することを前提にしています。estimator.fit()を呼ぶことでトレーニングジョブが作成され学習が行われます。
詳しい使い方の説明はsagemaker-python-sdkの公式ドキュメントにあるので、そちらを参照すると良いと思います。
sagemaker-sdkからlocalモードで実行する
sagemaker-sdkのトレーニングジョブ作成はlocalモードという実行方法を用意してくれています。localモードでトレーニングを開始すると、実行した環境でコンテナを立てて学習が行われます。
Estimatorにtrain_instance_type="local"を渡すことでlocalモードとして実行されます。
from sagemaker.estimator import Estimator
estimator = Estimator(
image_name="sample_image:latest",
role="sample-SageMaker-role",
train_instance_type="local", # <-- "local"を指定する
train_instance_count=1,
hyperparameters={"learning_late": 0.01},
)
estimator.fit({"some_channel": "file://data/train"}) # <-- ローカルにあるディレクトリを指定(相対パス)
ただしこのlocalモードは注意ポイントがいくつかあります。
- イメージはローカルにあるイメージを利用してくれます(
image_nameにはローカルのイメージ(tag)を指定する必要がある) - ロールはAWS上のIAMロールが利用される(AWS上の指定したIAMロールが存在しなければならない)
- 学習の生成物はS3に転送される
AWS上のリソースと切り離せないことになるため、完全に個人の開発PC等のローカル環境に閉じないことに注意する必要がありそうです。
(これらのポイントから察するに、ノートブックインスタンスから利用されることを見込んだ機能のように思えますね。)
sagemaker-containers を用いてトレーニングする方法
sagemaker-containersを使うことで以下のようなメリットが得られます。
- 前述したSageMakerが予約しているディレクトリ・ファイルのパスは環境変数に格納してくれる(隠蔽されている)
- hyperparametersはコマンドライン引数として与えられる(JSONファイルのパースが必要ない)
- 簡単に同じDockerイメージでSageMakerエンドポイントとしても動作するようにできる(※今回は説明しない)
Training code
学習を行う側のサンプルコードを以下に示します。
import argparse
import os
import pandas as pd
class Model:
def __init__(self, learning_rate=0.01):
self.learning_rate = learning_rate
def fit(self, data):
pass
def save(self, model_dir):
pass
def train(args):
# 学習データの取得
train_filepath = os.path.join(args.train_dir, "train.csv")
data = pd.read_csv(train_filepath)
learning_rate = args.learning_rate
# モデルの学習
model = Model(learning_rate=learning_rate)
model.fit(data)
# モデルの保存
model.save(args.model_dir)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--learning-rate", type=float, default=0.01)
parser.add_argument("--model-dir", type=str, default=os.environ["SM_MODEL_DIR"])
parser.add_argument("--train-dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"])
args, _ = parser.parse_known_args()
train(args)
ここから見て取れるように、sagemaker-containersを使わないパターンと違い、以下のポイントに注目できます。
- hyperparametersをコマンドライン引数として受け取る
- 学習済みモデルを置くディレクトリや、チャネルのデータが置かれているディレクトリを知らなくて済んでいる
- 直接実行されることがないためshebangは必要ない
Training code image のDockerfile
上記のtrain.pyを使ってトレーニング時に使用するイメージのDockerfileをサンプルとして以下に示します。ここでは自前の学習プログラムを/opt/ml/code/ 以下に置くことにし、依存モジュールをインストールするためにrequirements.txtをpip installすることとしています。
FROM python:3.6.9
ENV PROGRAM_DIR=/opt/ml/code
RUN mkdir -p $PROGRAM_DIR
WORKDIR $PROGRAM_DIR
COPY requirements.txt $PROGRAM_DIR/requirements.txt
RUN pip install -U pip && \
pip install sagemaker-containers==2.5.9 && \
pip install -r requirements.txt --no-cache-dir
COPY train.py $SAGEMAKER_CODE_DIR/train.py
ENV SAGEMAKER_PROGRAM train.py # <-- *
コード中*と付けたところがポイントです。sagemaker-containersはdocker run {image} trainが実行された際、sagemaker-containersが用意しているtrainコマンドが環境変数SAGEMAKER_PROGRAMを使いpython $SAGEMAKER_PROGRAM --hyperparameter1=xxx ...と呼び出します。なので、SAGEMAKER_PROGRAMに学習時に実行するファイルを指定しておく必要があります。
トレーニングの実行
sagemaker-containersを用いた場合のトレーニング方法は、前述の自前で用意する方法と同じなので省略します。
さいごに
今回はサンプルコードを完全に説明用のショートなものを使っていて伝わりにくい部分もあったかと思いますが、実際任意のコンテナ環境・学習コードが使えるわけです。学習実行基盤としてSageMakerトレーニングに関して全てを説明したわけではありませんが、この記事を読まれた方がSageMakerトレーニングの可能性の認識を広げられていれば幸いです。