ストーブリーグって楽しいですねこんにちは!
このエントリーではみんな大好きプロ野球と,最近巷で流行っている&自分も仕事・趣味両方で活用しているpandas他を使った,野球統計学「セイバーメトリクス」の例を紹介したいと思います.
なお,この記事はPython Advent Calendar 2016 12/4分の記事となります&記事を読んでコードを写経して動かすまでの所要時間は33分4秒くらいを想定しています.
Starting Menmber
- 自己紹介
- 10分で理解するセイバーメトリクス(野球統計学)
- 20分で打者の特徴をPython+Pandasでサクッと見てみる
- まとめ(3分4秒)
なおこの記事は過去に書いた「たった数行のPythonコードで打者大谷翔平がどれだけ凄いのかを見てみる」をPythonプログラミング&野球統計学の視点で新たに書き起こしたものです.
自己紹介
- shinyorke(しんよーく、と読みます)
- HR(人事領域)系のスタートアップでエンジニアしてます.
- DjangoでWebアプリ開発(みんなで)&データベース・分析チームのメンバー(一人)
- Python歴5年ちょっと
- 「野球 Python」で探すと色々出てきます(成果が)
10分で理解するセイバーメトリクス(野球統計学)
Pythonのコードを書いてさあ打者を分析!...の前に,かるくセイバーメトリクスの紹介を.
ちゃんと書くと丸一日かけても終わらないので,この先のHackに必要なポイントのみ紹介します.
セイバーメトリクスとは?
こちらはWikipedia(セイバーメトリクス)からの引用となります.
セイバーメトリクス(SABRmetrics, Sabermetrics)とは、 野球においてデータを統計学的見地から客観的に分析し、選手の評価や戦略を考える分析手法である。
打率・打点・ホームラン,勝利,防御率,エラーetc...野球には様々な指標がありますが,これらを一旦さておいて,「仮説」を元に「客観的に分析」するための指標を作成,「選手の評価・戦略を考える」分析手法およびその思想がセイバーメトリクスです.
指標は既にあるデータ(打席,安打,投球イニングなどのスコアデータ)やスピードガンやカメラ・レーダーで捉えた詳細なセンサーデータなどを駆使して行います.
なお今回はスコアデータを使います(センサーデータはそもそもWeb上にあまり存在しない).
セイバーメトリクスの基本的な考え方
以下の3つを捉えておけばOKです.
- チームの得失点差がゼロの時勝率は5割である(ピタゴラス勝率)
- 打者は「アウトにならない」「一つでも前の塁に進む」事が正義!
- 投手&野手は「一つでも多くのアウトをとる」「相手に前の塁を狙わせない」こと!
1.は「ピタゴラス勝率」という考え方があり,こちらの勝率予測が全ての野球統計学の基礎となっています.
得失点がゼロなら5割,プラスで貯金,マイナスで借金の可能性が高い,なんとなくお察しですねと.
また,野球はアウトを3つとられない限り攻撃のターンが続くので,
- 打者は得点を増やすため,アウトをとられないプレーがベスト(ヒット,四死球など)
- 投手・野手は失点を減らすため,より一個でも多くのアウトを捕るべき(三振・ゴロ・フライ・盗塁阻止)
を大切にすべき!という指針が見えてきます.
(諸説あります&異論は認めますが)打者が犠牲バント・盗塁など「アウトになるリスクが高いプレー」はセイバーメトリクス上敬遠されます.
もうちょっと知りたい!という方は, 30分で解説した記事(自分の過去記事です&背景とか簡単なユースケースを紹介してます)があるのでこちらをご参考ください(ステマ)
20分で打者の特徴をPython+Pandasでサクッと見てみる
ここでようやっとプログラミングの話題です(待たせてスイマセン).
実際にPythonを使ってやってみましょう.
やること
- 北海道日本ハムファイターズからFA宣言した陽岱鋼(ヨウダイカン)選手のセイバーメトリクス指標を算出,年度ごとの変化を観察する.
- データソースはNPB公式から拝借する(小声)
事前準備
- Python3.4以上が動く環境(新しければ新しいほど良い)
- venv,virtualenvなどの仮想環境(危険なライブラリ・コードはありませんがOSのやつに突っ込むのはやめよう)
- パッケージ管理.推奨はpip,「いやオレ別の記事でanacondaとか見たし使ってるよ!」という方はanacondaなり何なりお好きな方法で.
なおこの記事は,
- pyenv + virtualenvでPython3.5.2が動く仮想環境
- パッケージ管理はpip
- macOS 10.12.1(Sierra)
を前提に説明します(ご自身の環境によって読み替えてもらえればと)
&断片的なコードスニペットが登場しますが最後にまとめた奴も出します.
(平たく言えば最後の奴をコピペしたら真似できるはず)
ライブラリのインストール
今回は以下の構成でコードを書きます.
- 実行環境はJupyter(IPythonおよびnotebookをベースに読み書きします)
- データの取得・前処理・計算にpandas
- データの取得に必要(pandasが部分的に依存)するbeautifulsoup4等,htmlをいじるライブラリ
- グラフ描画(matplotlib,seaborn)
pipをお使いの方はこちらの1行を実行で事足ります(anacondaなどの人はうまく読み替えてやってください).
> $ pip install ipython pandas beautifulsoup4 numpy lxml html5lib jupyter matplotlib seaborn
環境を起動する
Jupyter notebookを起動します.
> $ jupyter notebook
データフレームの取得と掃除(前処理)
ライブラリのインポートなど
グラフを書くのでMagic Function(%ではじまるやつ)を書きます&pandasをimportします.
ついでに,この後のデバッグをやりやすくするためnotebookの表示列と行の数を指定します.
%matplotlib inline
import pandas
# 表示列・行を増やす(30列, 10行)
pandas.options.display.max_columns = 30
pandas.options.display.max_rows = 10
データフレームを取得
pandasのread_htmlメソッドで取得します.
裏側はbeautifulsoupやhtml5libなど使ってうまい具合Tableタグをスクレイピングしています.
url = 'http://npb.jp/bis/players/21825112.html' # 陽岱鋼さんのHP(npb.jp)
df = pandas.io.html.read_html(url) # tableタグをスクレイピング!dfのリスト(中身はpandas.core.frame.DataFrameのオブジェクト)で返ってきます
このページの中に複数のTableがあるのでどの行が打撃成績かを調べます.
先に答えを言うとindex=3(4行目)が打撃成績です.
多分こうなるはず.
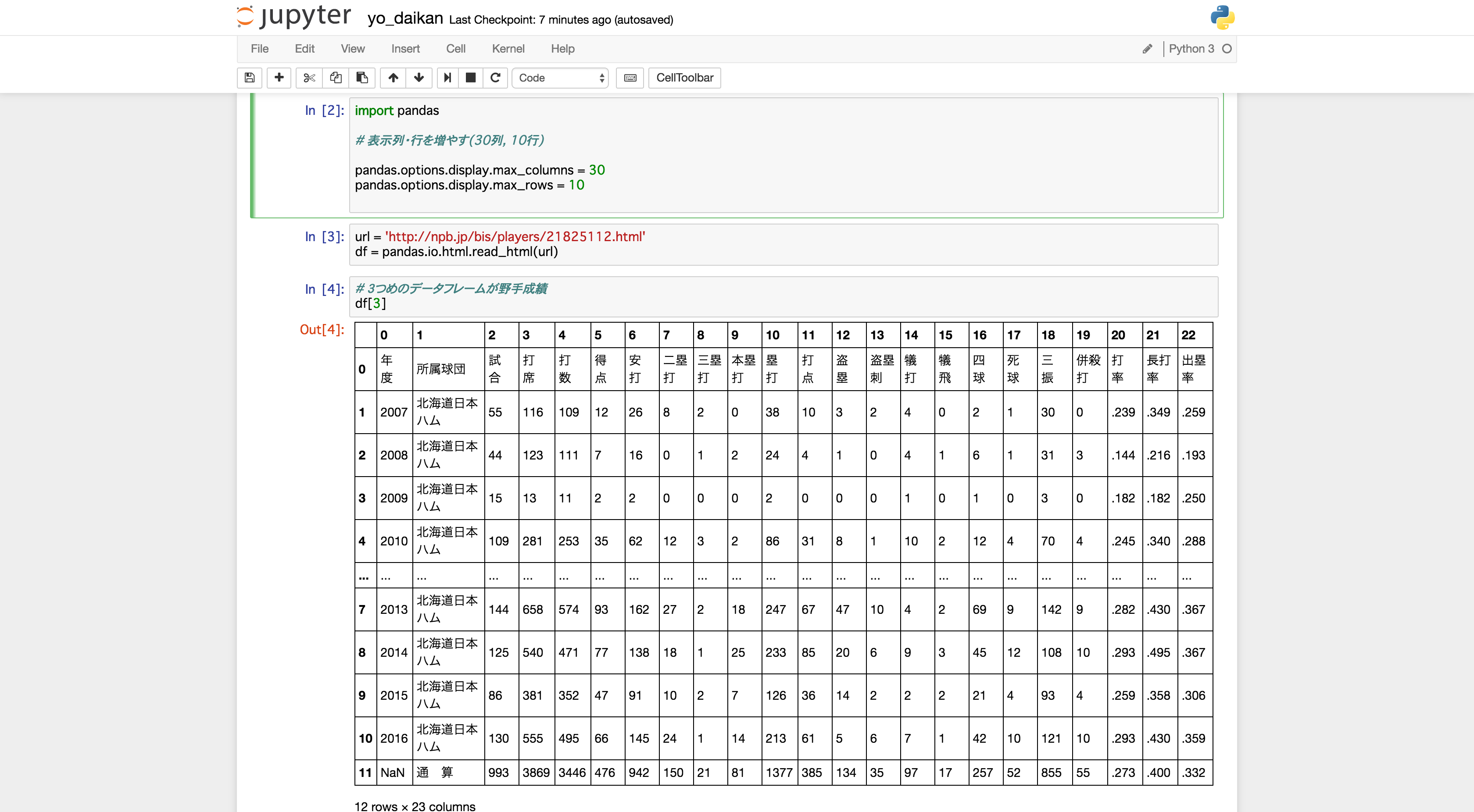
前処理
ページ内にある複数のTableから,必要なTableを選択&データ型などをこの後の処理がし易いようにお掃除します.
# ごみとなるデータを捨てて別のデータフレームに移動(indexおよび, 2010年以前の成績&通算)
atbats = df[3].drop([0, 1, 2, 3,4, 11])
また,このデータはカラムがindex(実際の日本語カラムはデータ扱いになってる)なのでカラムを付け直します.
日本語でもOKですが,個人的には野球英語の略称を推奨します(MLBとか見てる人にはお馴染みだと思う).
また,データ型も普通のobject(read_csvのようにデータ型をよしなに変えてくれない)なのでちゃんと型を指定してあげます.
# カラム名を付与する(野球英語の略称)
atbats.columns = ['year', 'team', 'g', 'pa', 'ab', 'r', 'h', '_2b', '_3b', 'hr', 'tb', 'rbi', 'sb', 'cs', 'sh', 'sf', 'bb', 'hbp', 'so', 'dp', 'ba', 'slg', 'obp']
# 各カラムを前処理する
import numpy as np
atbats['year'] = atbats['year'].fillna(0).astype(np.float64)
atbats['g'] = atbats['g'].fillna(0).astype(np.float64)
atbats['pa'] = atbats['pa'].fillna(0).astype(np.float64)
atbats['ab'] = atbats['ab'].fillna(0).astype(np.float64)
atbats['r'] = atbats['r'].fillna(0).astype(np.float64)
atbats['h'] = atbats['h'].fillna(0).astype(np.float64)
atbats['_2b'] = atbats['_2b'].fillna(0).astype(np.float64)
atbats['_3b'] = atbats['_3b'].fillna(0).astype(np.float64)
atbats['hr'] = atbats['hr'].fillna(0).astype(np.float64)
atbats['tb'] = atbats['tb'].fillna(0).astype(np.float64)
atbats['rbi'] = atbats['rbi'].fillna(0).astype(np.float64)
atbats['sb'] = atbats['sb'].fillna(0).astype(np.float64)
atbats['cs'] = atbats['cs'].fillna(0).astype(np.float64)
atbats['sh'] = atbats['tb'].fillna(0).astype(np.float64)
atbats['sf'] = atbats['sf'].fillna(0).astype(np.float64)
atbats['bb'] = atbats['bb'].fillna(0).astype(np.float64)
atbats['hbp'] = atbats['hbp'].fillna(0).astype(np.float64)
atbats['so'] = atbats['so'].fillna(0).astype(np.float64)
atbats['dp'] = atbats['dp'].fillna(0).astype(np.float64)
atbats['ba'] = atbats['ba'].fillna(0).astype(np.float64)
atbats['slg'] = atbats['slg'].fillna(0).astype(np.float64)
atbats['obp'] = atbats['obp'].fillna(0).astype(np.float64)
この状態までもって行けたら後は楽しい可視化と指標計算の時間です.
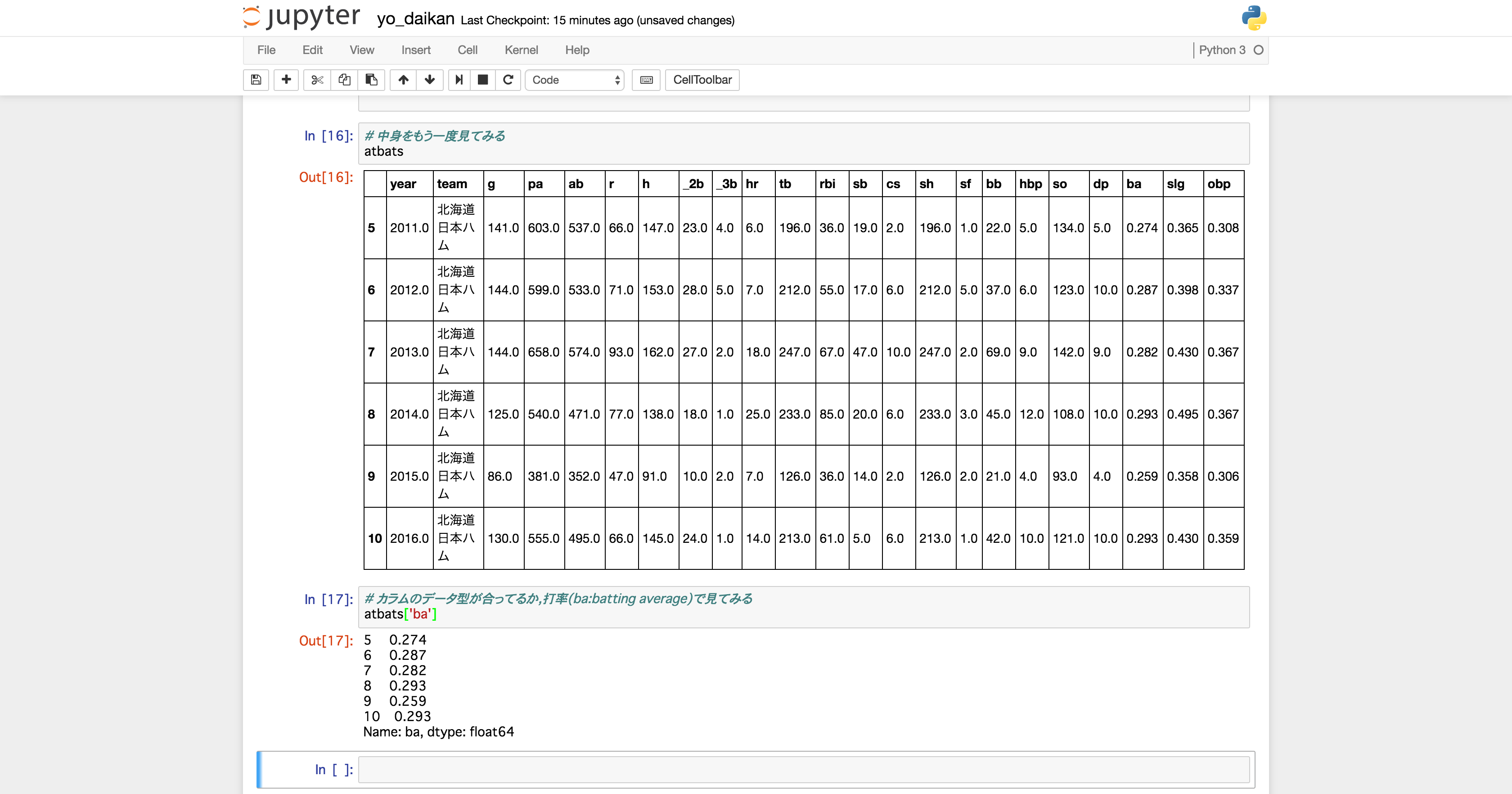
分析の時間!
まずは指標をグラフ化してみる
ここではseabornを使います.
2011-2016までの打率の遷移を見てみましょう.
# グラフを描く(seabornで)
import seaborn as sns
# 打率(ba, batting average)を折れ線グラフに
sns.pointplot(x="year", y="ba", data=atbats)
きっとこんなグラフが出てきます.
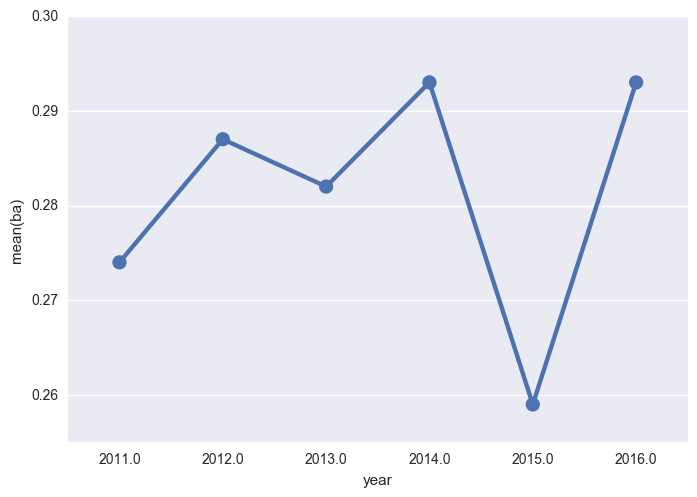
2015年の数字が落ちていることがわかります.
この年は2014年から痛めた肩やら腿に加え,シーズン中の怪我で一番パフォーマンスが出なかった年です(自分の記憶&Wikipediaより).
その他にもデータがいくつかあるので,興味ある方は是非グラフにして遊んでみてください.
なお,seabornの使い方はなんやかんやで公式HPをチェックして見るのが良さ気です.
いよいよ,セイバーメトリクスの世界へ!!!
今回は簡単な指標でチャレンジします.
OPS(On the base Plus Slugging)
出塁率+長打率,アウトにならない能力(出塁率)と塁に進む能力(長打率)の足し算で大まかな攻撃力を把握
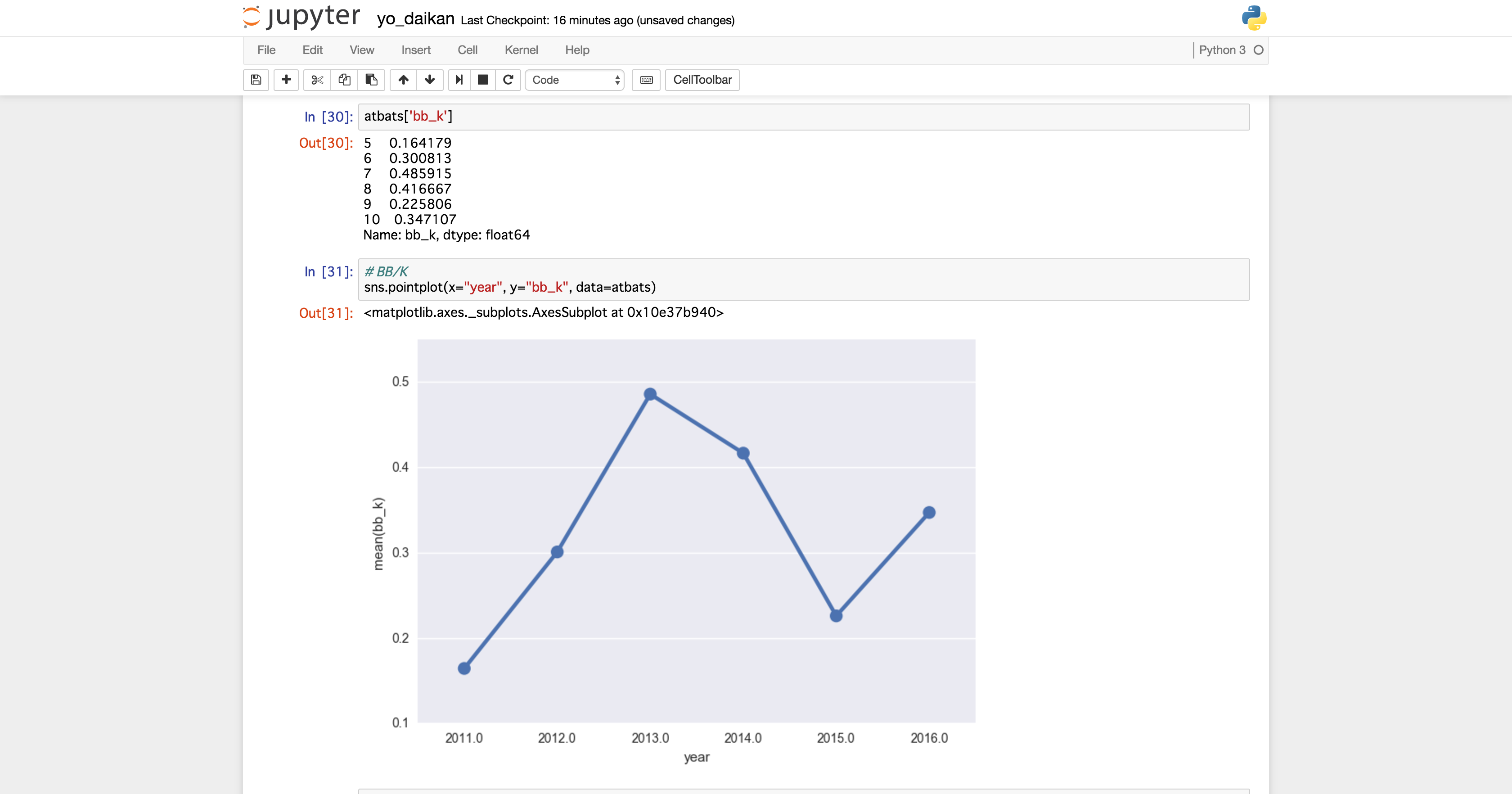
BB/K(Base on Balls per Strike out)
- 四球/三振
- 三振一個あたり何個四球を選んでいるか
- 選球眼および打席での我慢強さのバロメーターとなる(1前後が望ましい,理想は1.5〜2).
コード
データフレーム同士の四則演算で行えます.
# OPSとBB/Kを計算する
atbats['ops'] = atbats['obp'] + atbats['slg'] # OPS
atbats['bb_k'] = atbats['bb'] / atbats['so'] # BB/K
結果はこちら!
OPS
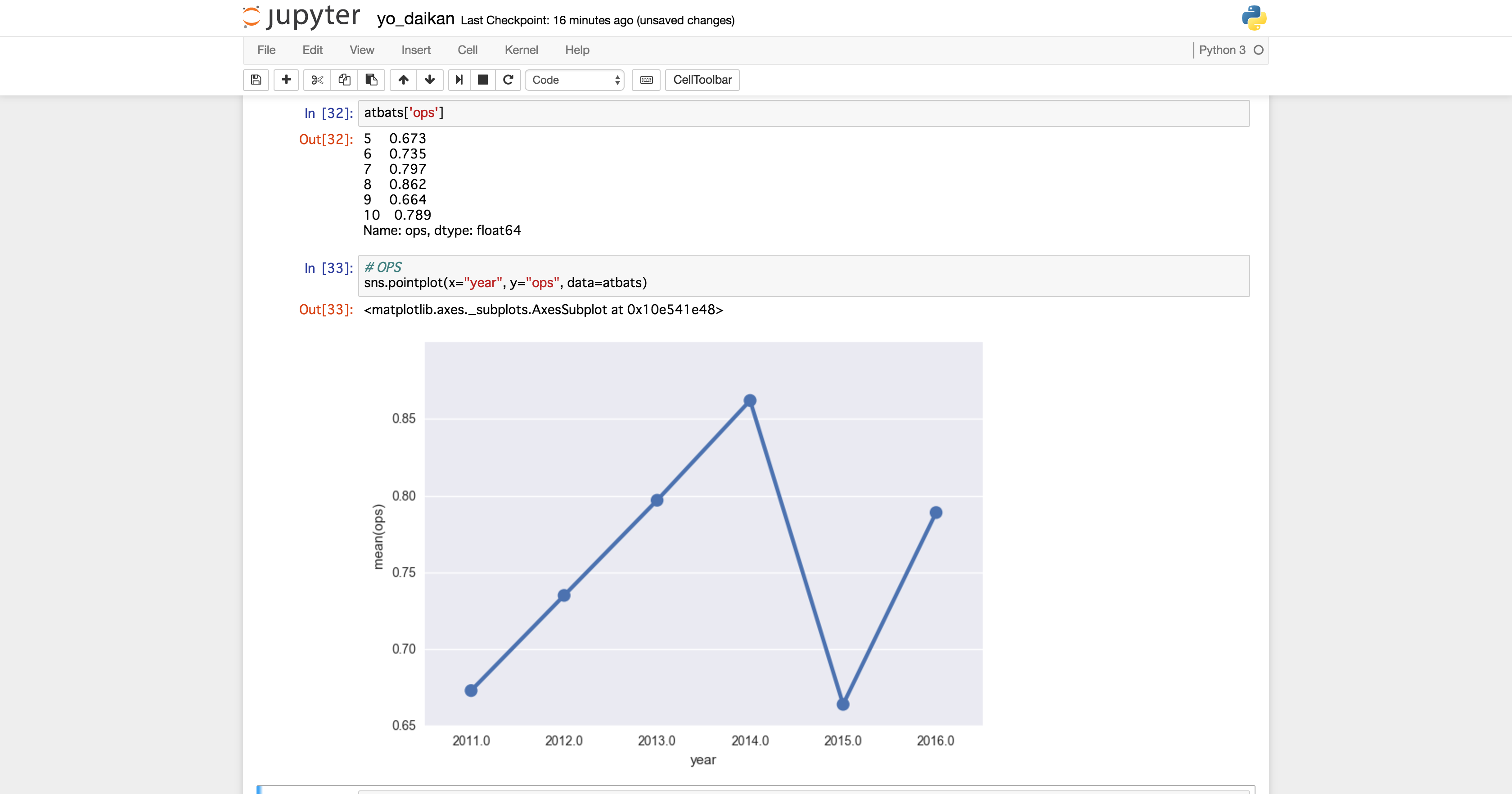
BB/K
考察
- 元々リードオフ(一番バッター)タイプの陽様のOPSはまあまあ合格点(.750〜.800ぐらいが理想)
- ただ,クリーンアップとか打たせちゃいけない
- 2014年の数字を維持できたら最強なのだが,やっぱ2015年の故障の影響で数字がアレなのは心配(2016年が戻ってるとはいえ)
- BB/Kの数字が良くない
- 一番打者なのに扇風機な可能性
再チャレンジ!〜一個四球を選ぶ度に何個三振しているか
BB/Kの反対でK/BBというものもあるのでそちらでも見てみましょう.
※本来は投手を評価する指標(1四球あたりの三振数)
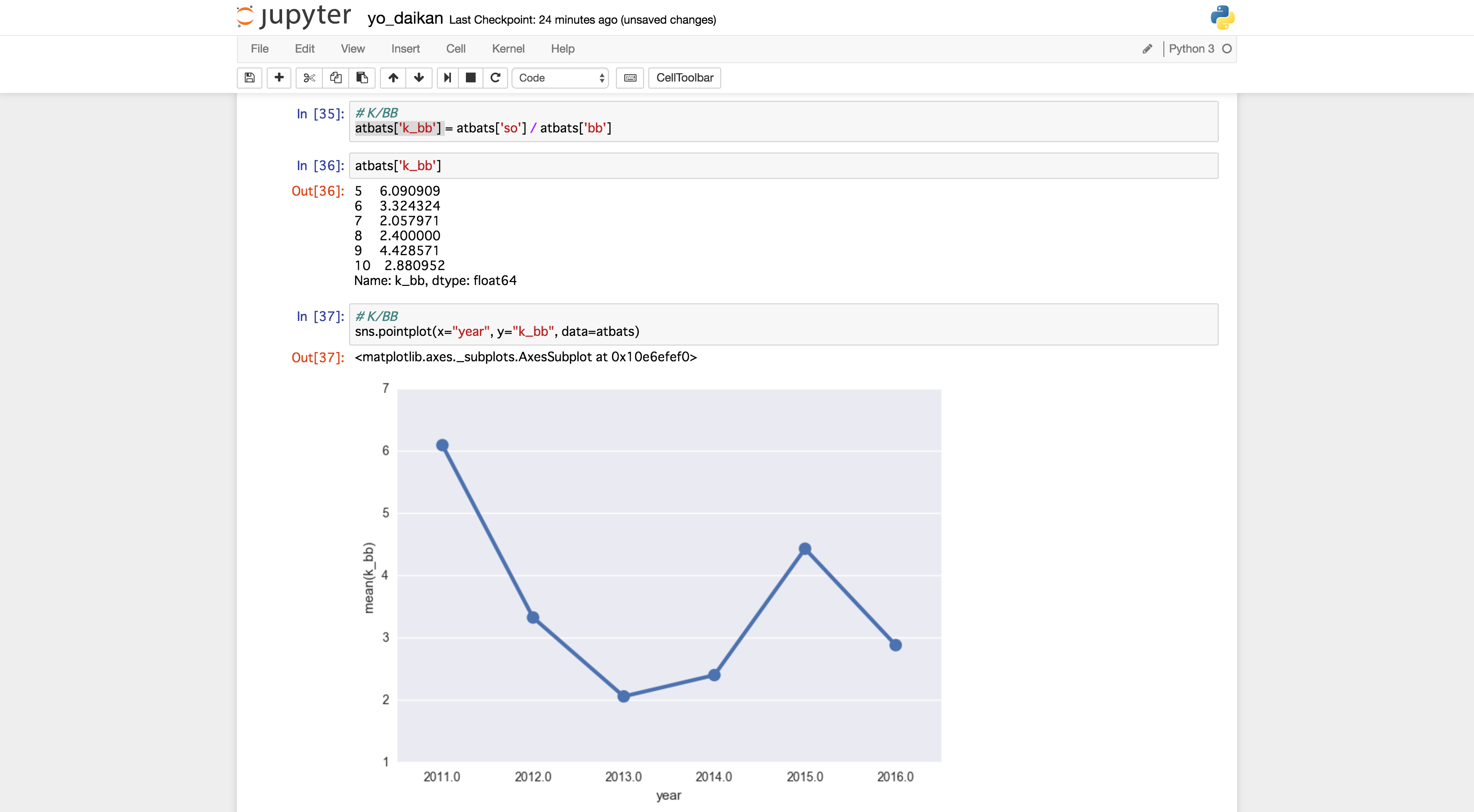
今年の陽岱鋼は四球1個あたり約3つ三振していたことがわかります.
2011年の6.09,2015年の4.42ほどひどい数字じゃないにしても,K/BBが1.5〜2.0ぐらいに収まらないと,
OPS的には1番バッタータイプ,でも出塁機会より三振が多い
という痛い感じになりそうです.
北海道日本ハムファイターズはデータをかなり詳しく見てる(割には犠牲バント薦めるのが謎ですが)チームで,この辺の数字悪化がFAに繋がった可能性もなくはなさそうです(実際はもっと詳しい数字&ここでは表せない守備も影響しています).
まとめ(3分4秒)
今回のコードスニペット(1分)
断片的に書いてたスニペットをまとめたものがこちらになります.
感想&言いたいこと(2分)
Python(またはPyData)的な意味で
主に,言いたいことメイン(経験者的に)
-
いきなり機械学習とかでもいいけど,身近なテーマから始めてライブラリやお作法を覚えるのがいいと思うよ!
- 好きこそものの上手なれ,ですよと
- いきなり仕事で試行錯誤はキツイので手慣れてるテーマでやると幸せになれますよ
- データの取得はコツを掴めばすぐだけど,前処理はやっぱ大変
- HPから削り取るだけ,とはいえデータ型合わせたり確かめ算したりと地道な作業が多々ある
- 取ってきたデータをすぐ使えると思うなよ!
-
手段は問わないが,環境の仮想化は必須!
- venv,virtualenv何でもいいから実行環境は仮想化すべき
- なぜかって,データ操ってると使いたいライブラリがとっかえひっかえ出て来る
- この記事も簡単そうに見えて何気に試行錯誤してる
- 個人的にはvenvでもvirtualenvでも何でもいいけど,「これだ!」と思ったものは使いこなせるようになるべき!
- 「僕の環境、突然動かなくなった!」と言われても...
- と,いう思いがあって敢えて「仮想環境は!」的な前書きをした
野球(またはセイバーメトリクス)的な意味で
-
指標の計算と考察は楽しい!
- PythonでもExcelでも何でもいいので自力でやってみると発見はたくさんある
- マスコミとか解説が以下に適当にしゃべってるか,とか←発見の例
- データだけで一日潰せるので好きな人はぜひやってみてみて
- 陽岱鋼について
- まずはちゃんと身体を癒やして欲しい
- 結局のところ,2014年の怪我を境に選手としてのピークが落ちてる感ある
- 三振が多い,でいて出塁も期待できないリードオフは不幸(長打力あるとはいえ)
- どこのチームに合うか!?
- うーーん...
- これはもう少し分析して考えたい
- まずはちゃんと身体を癒やして欲しい
最後にひと言(4秒)
なんでや阪神関係ないやろ!
...明日はkimihiro_nさん,よろしくお願いします!
【オマケ】参考書籍(野球)
もっとセイバーメトリクスを学びたい方は.
この辺を抑えれば間違いないかと!