概要
前回までのところで、逆スタースキーマの基本的な動作の確認はできたものの、ディメンション・ファクトテーブル間のリレーションを認識していないと、データアイテムを組み合わせる事ができないため、自由分析を行う事ができないというお話をしました。
第①回:基本的なモデルの動作検証
https://qiita.com/shinyama/items/0567425a4a47ad7d6efa
今回は、逆スタースキーマモデルで自由分析を行う要件を「統合ディメンション表」を作成する事により達成した話です。
統合ディメンション表とは
統合ディメンション表とは、理想的には全てのディメンション表を、一つの表にまとめたもの、となります。
例えば、顧客表、製品マスタ表、日付マスタ表、などをまとめて、1つの統合ディメンション表にデータを持ちます。
統合ディメンション表を作成した後のモデルを図に書くと、以下のイメージになります。
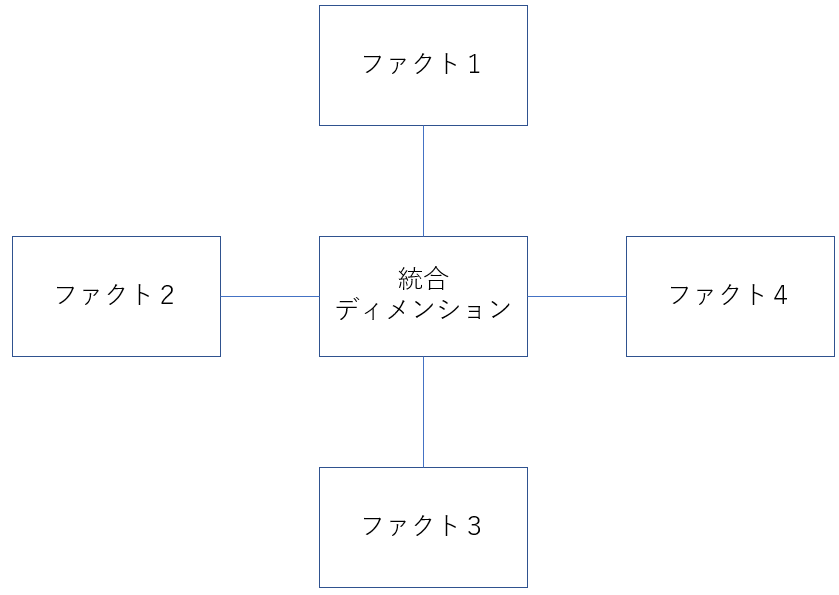
統合ディメンションは、理想的には全てのディメンション表をまとめたもの、と書きましたが、実際には全てのディメンション表(マスター表)を、都合良く結合できるための共通のキーなんて存在しません。
そのため現実的には、最小粒度のデータを持っているファクト表から、キーの組み合わせをSQLで抽出し、足りないキーがある場合は他のファクトから結合・抽出し、統合ディメンションをビューとして作成していく事にしました。
統合ディメンション表の検証
統合ディメンションの動作を、簡単なモデルとデータで行ってみました。
以下のモデルで、DIMB1が統合ディメンションとなり、実体は最小粒度データを持つFACTB2のPROD、COUNTY、PERSON、YEARというキー列をSELECT文で抽出したビューとなります。
このモデルであれば、分析の軸となるデータ項目は常にDIMB1に存在するので、自由分析の際にエンドユーザーは常にDIMB1のデータアイテムを使用すれば良い事になります。

しかしながら、このモデルでは、しばしば遭遇する出力データが不正確になる問題が発生します。
FACTB1とFACTB2で、粒度が違う事が問題の原因です。
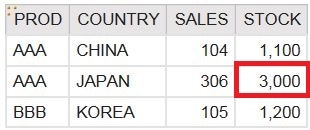
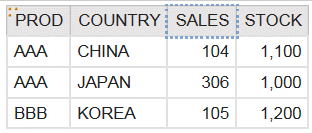
以下のように、DIMB1.PROD、DIMB1.COUNTRY、FACTB2.SALES、FACTB1.STOCKをリストに置くと、STOCKの値が3倍された値になります。
これは、DIMB1を見て頂けるとわかりますが、PROD=AAA、COUNTRY=JAPANでの組み合わせは、PERSONとYEARのバリエーションにより3行存在するからです。
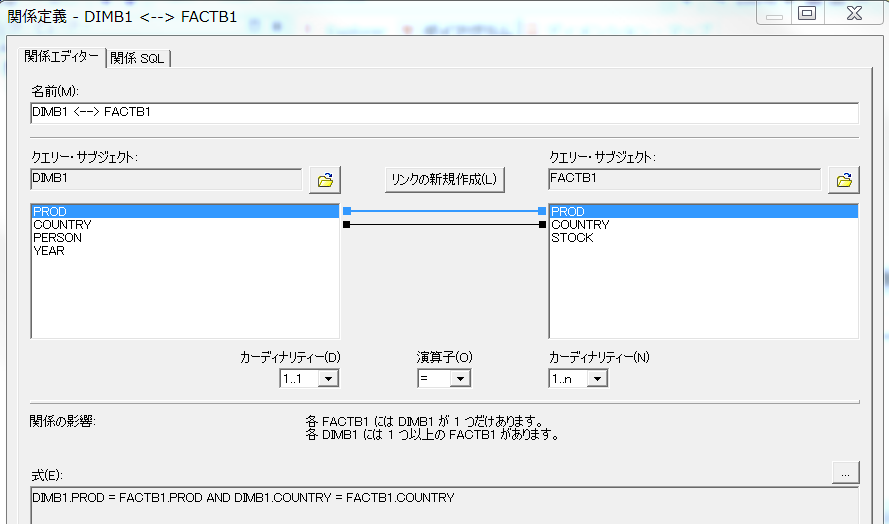
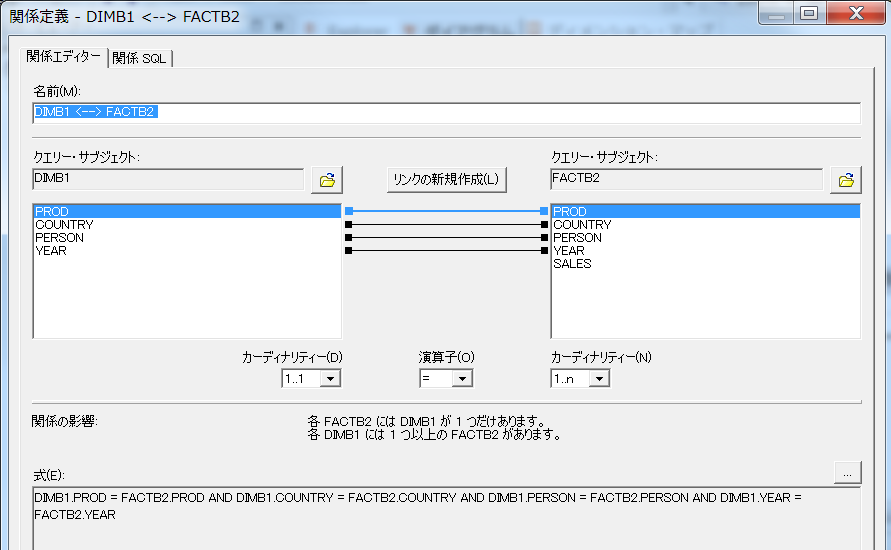
※参考までに、各テーブル間のリレーション定義を貼っておきます。
行列式の使用
この問題を解決するために、DIMB1に行列式を設定します。
行列式とは、粒度違いのファクト表をつなぐディメンションに設定し、粒度違いのデータを組み合わせた際の問題の解消を行うための設定です。
実際の設定画面を以下に添付します。
各ファクトに共通のPRODとCOUNTRYは「グループ化」に指定し上位に配置、FACTB2のみにユニークなPERSONとYEARは「一意に識別」に指定し下位に配置しています。
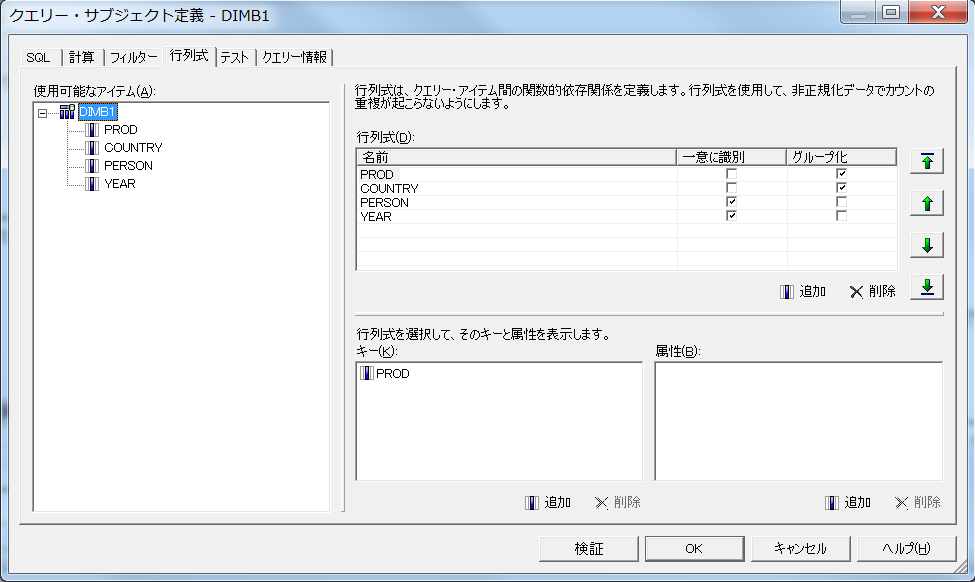
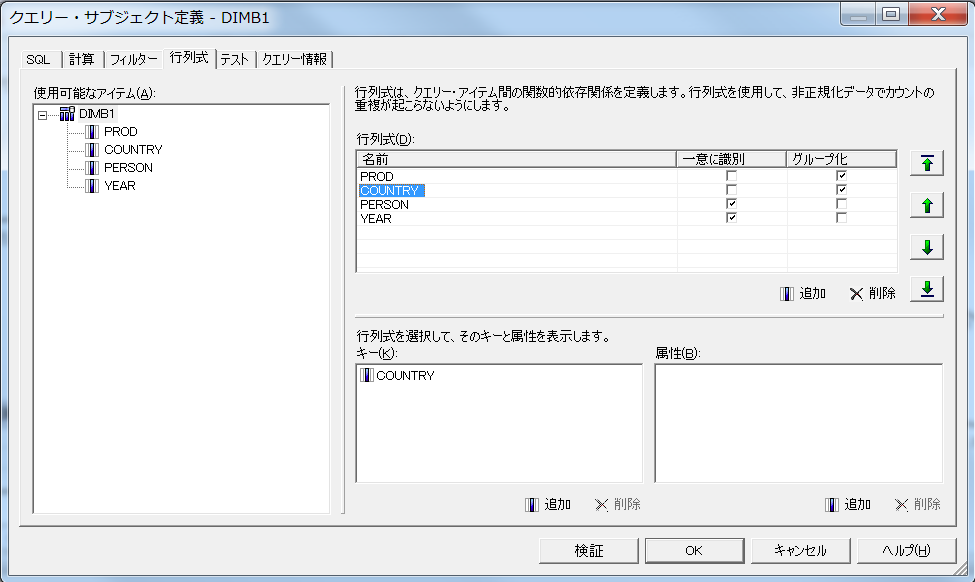
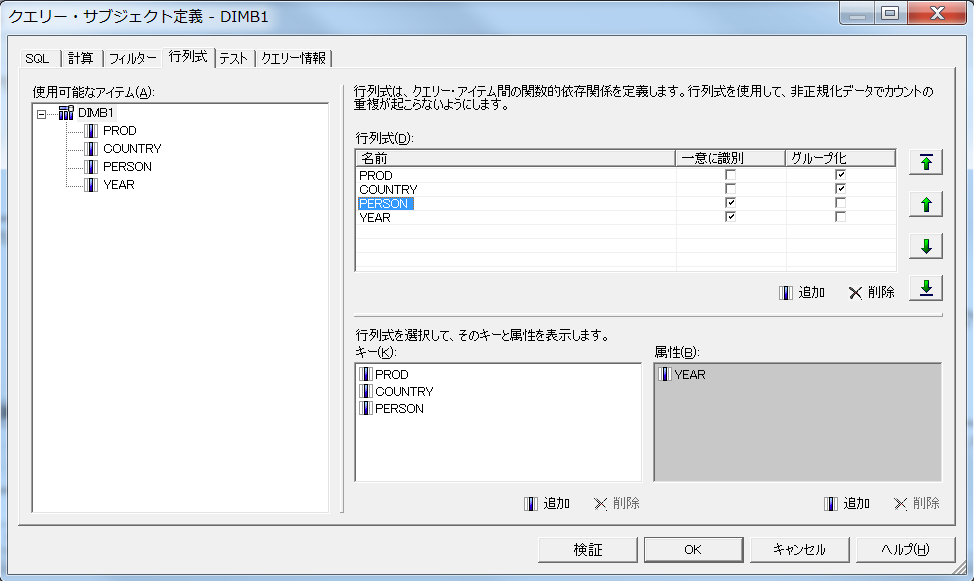
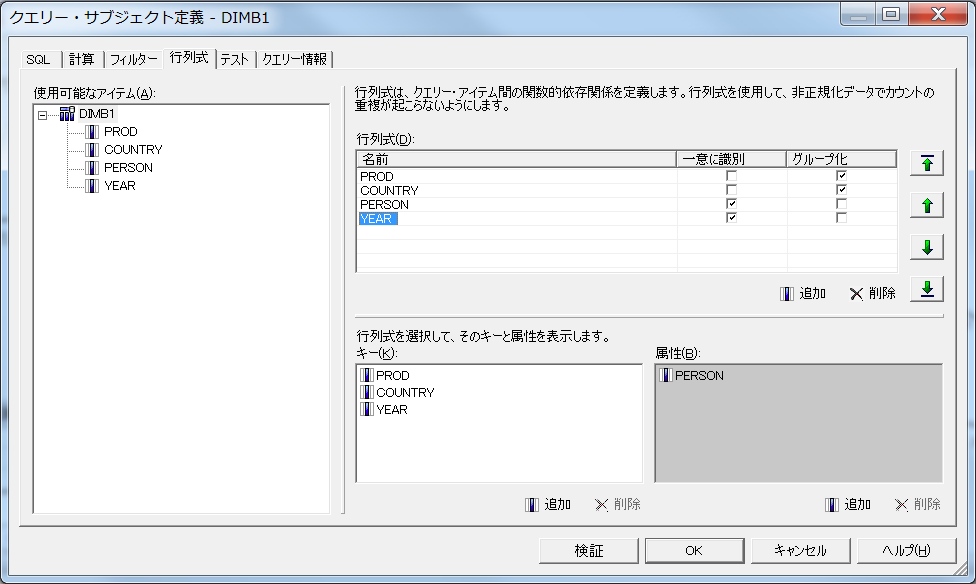
このモデルで、先ほどのリストを実行すると、正しい値が表示されます。
DIMB1.PROD、DIMB1.COUNTRY、FACTB2.SALES、FACTB1.STOCK
次の問題 - 属性データはどうやって使用するのか
ここまでの概念を実装すると、統合ディメンションのキーアイテムと、各ファクト表の数値データを自由に組み合わせて、自由分析を行う事ができるようになります。
では、属性データはどのように使用すれば良いのでしょうか。
属性データとは、例えばPROD列は製品のキーで、AAAとかBBBで表現していますが、実際の「製品名」を本来分析に使いたいと思いますが、そういう属性データをどうやってこのモデルに登場させれば良いかという話しです。
次回にご説明します!
目次
第①回:基本的なモデルの動作検証
https://qiita.com/shinyama/items/0567425a4a47ad7d6efa
第②回:自由分析への対応
https://qiita.com/shinyama/items/5bb75bae2e67d6e9cac0
第③回:属性データのモデル取り込み
https://qiita.com/shinyama/items/b66d59a92a58533f7c2b
第④回:パフォーマンス・チューニング
https://qiita.com/shinyama/items/b4b28844b4235db70032