※本稿記載の内容は、フェイクを入れています。予めご了承ください
タイトルどおりです。
個人的にAWSのように緩やかに課金されていくスタイルのクラウドサービスでは、
あまり多くのサービスを使いたくありません。
そのため、できる限り使用サービスを少なくする方向で
csvをDynamoDBにインポートする環境を構築しました。
実装だけ確認したい場合は以下よりご確認ください。
要件
- 顧客が持つRDBのデータの一部を、用途に合わせてNoSQLに移管したい
- 顧客の持つデータベースにセキュリティ上、直接アクセスすることはできない(DMSは使用できない)
- 顧客はデータベースから抽出したCSVを提供する(SJIS形式/約5000万件/5ファイル分割 & ヘッダーあり)
- サーバーレスでなければならない(EC2やEKSを管理したくない)
- CSVをDynamoDBに入れる必要がある
- DynamoDBはオンデマンドでも良い(WCUを考慮する必要はない)
- 顧客が提供したデータの中身は完全ではない(pkやskがNull、ブランクのデータが存在する)
失敗例
予めLambdaで1ファイル分CSVパース→DynamoDBへのインポート処理を実施したところ、
3時間程度処理にかかり、15分以内(Lambdaの最大実行時間)に処理が終わらないことが判明。
2,3日で以下のような仕組みを作りました。
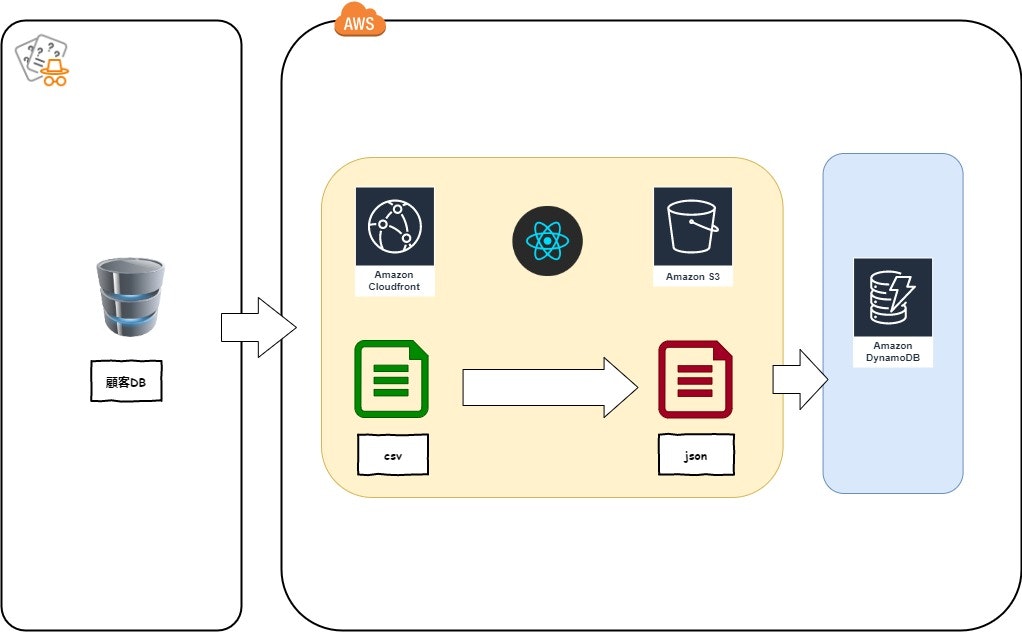
- 技術要素
- React
- Papa parse(CSV parser)
- AWS sdk for javascript(batchWriteで25件ずつ書き込みする)
- React
Reactで作成したhtmlをCloud Frontからアクセス、csvをブラウザ上からアップロードし、csvからjsonにパース中のチャンクデータをリアルタイムにDynamoDBに書き込む大作戦です。
フロントエンドでは割とあるあるな仕様ですね。
本来であれば処理用にバックエンドサーバーを建てるところですが、
サーバーレスをご希望のためフロントだけで処理ができるように実装を行いました。
また、フロント側の技術的制約として、1ファイルで3GBほどのcsvファイルでしたので、
ファイルを一括で読み込むと、ブラウザが音も立てずにメモリヒープして亡くなられる事象が確認されました。
(あたりまえ?)
また、ReactではNode.jsのfsが使用できないのでCSV-parserなどのnpmパッケージは使用できず、
実質Papa parse以外のパーサーが使用できない状態でした。
作ってるうちに、あれ?これフロントだけでやるとエラーハンドリングとか難しくね?
ということには気づいていました。
気づいていたんです。
結果
pkがNull?そんなデータ送ってくんなや。。条件分岐で除外だ除外
Papa parseが超巨大csv x encoding:SJISだと0.000006%くらいの確率で文字化け発生する・・・
※合計で数百件パース結果が変/データを少なくして入れ直すと直る/原因不明
などの障害はありましたが、もぐらたたきのように一つ一つ潰していきました。
データの挿入をしようとして弾かれたデータの解析と、文字化け対応に一番時間を食った気がします。
その結果・・・
49,745,624 // 全体データ数
49,745,539 // 入ったデータ
・・・・・・惜しい!
いや、惜しいじゃない。我々エンジニアの世界ではデータ欠落=死を意味します。
本移行するとき85件のためにデータ総なめして差異を入れないといけないやつです。
そんなことしたら3徹4徹当たり前の世界に突入します。
どこで間違えたのか
自身の技術スキル不足及びアーキ選定です。
- パースされたchunkデータをリアルタイム変換、除外する曲芸実装では正確性の担保が取りづらい
- SQSなどのキューでエラー管理をしていない
- 不正データの件数の確認をしていない
- 件数多すぎ
今回の失敗から得られた教訓は、Lambdaでは処理が終わらないとはいえ、
リアルタイム処理だけにこだわる必要はありませんでした。
- 一度S3にCSVをアップロードし、Lambdaで処理を通せる範囲までcsvを分割、SQSでタスクと件数の管理を行う。
- DynamoDBに件数管理テーブルを持つ(1書き込みに対してパラレルでこちらにも件数書き込みを行う)
などもできると思います。
ただし、個人的には
1.SQS+キューを飛ばすLambdaも管理する持ち物になるので使用するサービスが増える
2.コスト高い
ので好みでは有りませんでした。
成功例
AI戦国時代の昨今、流行のAWS Glueを使用することにしました。
しかしながら、glueは2020年3月現在、dynamoDBの直接Importには対応しておりません。
本当にお願いしますよ、AWSさん
そのため、内部でAWS SDKを呼び出し、書き込み自体も分散処理させてしまえば早いのではないかとの結論に至りました。
絵にすると以下のような形です。
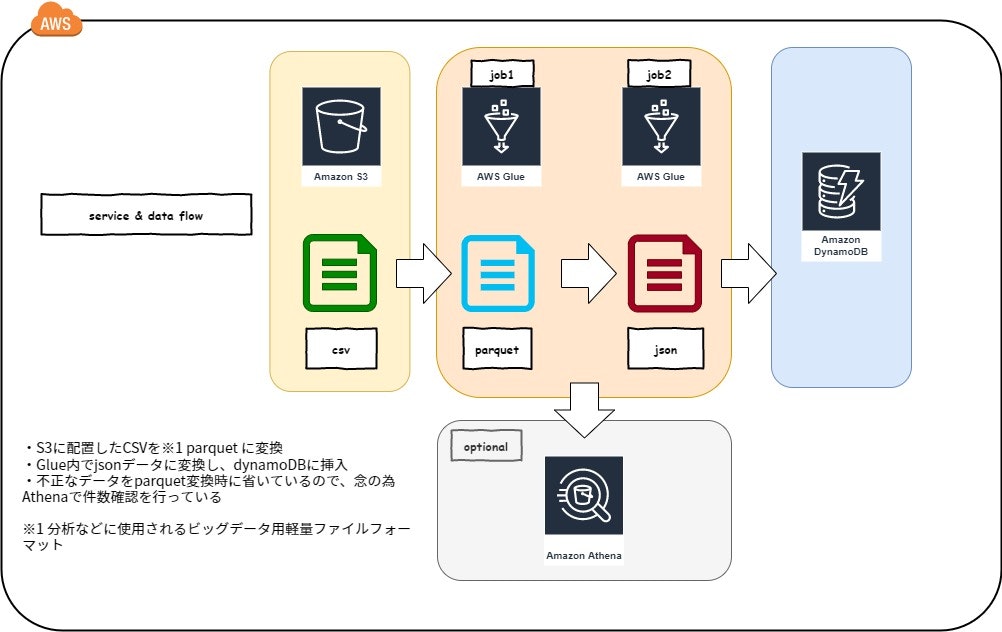
csvファイルをS3に配置してAthenaで件数確認。
のち、parquet変換時に欠損データの除外と保存を行い、
正常データをdynamoDBにglueのジョブ内で分散書き込みさせるぜ大作戦です。
このへんはcloudwatchでcron&Lambdaでworkflow叩いて自動化しても良いかもしれませんね。
ここには記載してありませんが、受領するcsvは予めiconvでUTF-8に変換を行いました。
Git Bashなどが入っている環境で
iconv -f CP932 -t UTF-8 part1_fxxkin.csv > conv1.csv
とするだけです。
実装
python自体、私があまり扱う言語ではありませんので、検証がてら動いたものベースでの貼り付けとなります。
また、S3の環境などは予めglue内で指定する必要がありますので、コピペしただけでは動きません。
ご使用になられる親愛なる諸氏は、うまいこと変換してください。
import sys
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark.sql.functions import trim
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "default", table_name = "csv", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database="default", table_name="csv",
transformation_ctx="datasource0")
################################################################
## DynamicFrameをDataFrameに変換し、csvファイル内のデータを整形をしています
################################################################
datasource0df = datasource0.toDF()
## csvのフィールドに謎のカンマが入っていたり
datasource0df = datasource0df.replace(",", "-")
## エスケープが多かったり
datasource0df = datasource0df.replace('"', "").replace('\"', "")
## Dynamodbに入れられない空文字が入っていたりするのを変換
datasource0df = datasource0df.replace("", None)
datasource0_tmp = DynamicFrame.fromDF(datasource0df, glueContext, "nested")
## @type: ApplyMapping
## @args: [mapping = [("name", "string", "pk", "string"),("no", "string", "sk", "string")]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame=datasource0_tmp,
mappings=[("name", "string", "pk", "string"),
("no", "string", "sk", "string")],
transformation_ctx="applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame=applymapping1, choice="make_struct", transformation_ctx="resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame=resolvechoice2, transformation_ctx="dropnullfields3")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://parquet"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
datasink4 = glueContext.write_dynamic_frame.from_options(frame=dropnullfields3, connection_type="s3",
connection_options={
"path": "s3://parquet"},
format="parquet", transformation_ctx="datasink4")
job.commit()
DynamoDBにparquetをjsonに変換して流し込む。
import json
import sys
import boto3
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
glueContext = GlueContext(SparkContext.getOrCreate())
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## 関数内でboto3のインスタンスを生成しないと、各executorでpickleできず、以下エラーでるので注意
## PicklingError: Could not serialize object: TypeError: can't pickle SSLContext objects
def insert_dynamodb(row):
try:
## 別環境へ書き込む場合はboto3.sessionを使用し、credentialsを上書きしてください
dynamo= boto3.resource('dynamodb', region_name='ap-northeast-1')
table_name = "sample_table"
table = dynamo.Table(table_name)
with table.batch_writer() as batch:
return batch.put_item(Item=json.loads(row))
except Exception as error:
raise error
## @type: DataSource
## @args: [database = "default", table_name = "parquet", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database="default", table_name="parquet",
transformation_ctx="datasource0")
datasource0df = datasource0.toDF()
df_json = datasource0df.toJSON()
results = df_json.map(insert_dynamodb).collect()
結果
data count by Athena
49,745,624 // 全体データ数
16 // 除外したデータ数
49,745,608 // 入ったデータ
やったぜ。
まとめ
慣れた技術で作ったはいいものの、思った通りに処理が進まず、
新しい技術だからと深堀りせずに使用しなかった技術を使用してみると思ったよりも高速かつ正確に処理が進みました。
私が優れたエンジニアではないということもありますが、どの現場でも慣れたものを使いたくなると思います。
しかし、それは余計な手間を増やしているだけかもしれません。
勉強しないエンジニアは悪だと自戒も込めて投稿させていただきました。
batch_writer()すげぇ。
皆様はどのような手法で要件を解消されるでしょうか?