はじめに
記事の題名に「世界モデル」と書いてりますが、"世界モデル" という概念についての解説記事ではありません。本稿はマルチモーダルLLMの機構に関する記事になっております。以下のモデルを本稿で扱っていきます。
- Molmo ( Multimodal Open Language Model ) モデル
- 論文
ディープラーニングに強く興味を持ってから数年はチャットをはじめとする自然言語処理系にはほとんど興味がありませんでした。なぜならディープラーニングが注目を浴びるきっかけとなったのは画像系であり、そこに実績があったわけなので、最初に社会的インパクトを与えるのは絶対に画像系や信号処理、数理最適だと考えていたからです。よって、自然言語処理においてそれなりのものが出来上がってくるのはまだまだ遠い先だと思っておりました。しかし、実際にはChatGPTにより自然言語処理を発端にAI業界に火がつき、業界全体が急速な発展をみせました。まさかChatGPTがそのトリガーになるとは思いもせず、実際に自然言語領域でこれだけの結果が出ているのを目の当たりにすると一足飛びでの発展に感じられ驚きました。インターネットにも繋がっていないモデルが、学習パラメータの中だけで膨大な情報を包摂し、さらにそれを論理的に考えるような機能まで獲得しているのですから。
しかし、それでもまだ自然言語処理には関心がそれほど湧かず、画像系、信号処理系、数理最適(需要予測など)への関心が主でした。やはりこういったもののほうが、技術難度的にも、発想の難度的にも社会実装までのハードルが低いと思いますし、それに役に立ってなんぼだという思いがあったからです。ところがある日、自動運転に関するどこかの記事でエッジケースなど学習データに入っているとは思えないケースへの対処のためにLLMを用いているという記事を見かけました。理屈としては膨大な学習データを踏まえたLLMは世界の常識を包摂した世界モデルとみなすことができ、これを使えば人間にとって常識的な判断がLLMを通して下せるということです。
つまり、潜在空間の中に世界の常識というとても現実的に設計しかねる情報を獲得しているという訳です。このように解釈できたとき、私は俄然興味が湧いてきました。
調べた限り世界モデルの定義などはなく、世界の構造を理解出来る能力があるモデルのことを世界モデルというのだと思います。LLMが世界モデルとして機能するかを調べる術として、学習データにない未知の状況について、まともな考えや判定を出来ることが基準になってくるかと思われます。
マルチモーダルLLMは世界モデルの一つであると述べている記事もあり、私もその理解で間違いないと思いました。
【前の記事】
【次の記事】
本稿の目的
マルチモーダル LLM の基礎的な 仕組みや構造、挙動 を理解することが目的です。
デバッグするような形でコードを解読していき、モデルの全体像 とマルチモーダル LLM の処理における 主要な部分 のみに焦点を当てて解説します。
対象とする読者層はあまり特定していませんが、ディープラーニングについては数式に基づいて理解出来ることが望ましいです。Transformer はしっかりと理解されてからお読みいただくとスムーズに読めるかと思います。
「実行環境」と「対象のLLMモデル」について
マシンスペック
一般的なPCのスペック(CPUのみ(GPUなし)、RAM 16GB)ではモデルを動かすには厳しいです。一応、私が普段使っているPC(CPU実行しか出来ない、RAM 16GB)で推論してみました。モデルサイズより小さな空き容量のメモリでもモデルを動かすことは可能です。部分的に処理部分を逐次ロードすることで推論していると思われます。実際にローカル環境で Molmo を動かしてみたのですが、1回の推論に1時間強かかりました。また、もしローカルで実行するとしてもローカルのリソースが完全に食われてしまうので現実的ではありません。
↓ 手元にある普段使いのPC(GPUなし,RAMの空き容量:5GB程度)では1時間以上かかっている
/molmo/.env/bin/python /molmo/sandbox/load_web.py
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavi
or in v4.48, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████| 7/7 [00:00<00:00, 51.88it/s]
Some parameters are on the meta device because they were offloaded to the disk and cpu.
2025-01-15 00:48:40
2025-01-15 01:53:19
This image captures a young black Labrador puppy, likely around six months old, sitting on a weathered wooden deck. The puppy's sleek, short
fur is entirely black, including its nose, eyes, and ears, which are slightly floppy. The dog is positioned in the center of the frame, looking up directly at the camera with a curious and attentive expression. Its front paws are visible, with one slightly tucked under its body, while its back paws are hidden from view. The wooden deck beneath the puppy is made of light brown planks with visible knots and signs of wear, adding a rustic charm to the scene. The overall composition is simple yet striking, with the puppy's glossy black coat contrasting beautifully against the light wooden background.
実行環境
これでは全くお話にならないので、 量子化モデルの使用 と クラウドGPU を利用します。
クラウドで量子化モデルを実際にロードしてみるとVRAM 8GB程度なので、デバッグのために色々コードを触ることを想定しても VRAM 16GB 程度あれば十分です。
クラウドのGPUには Google Colab を使います。Colabの圧倒的な手軽さと安さは素晴らしいです。ハードウェアのタイプは T4 GPU を選びます。こちらは無料でも使えますが、1日の内にあっという間に使用上限を迎えてしまうので、Google Colab Pro にしっかりと課金されることを強くおすすめします。本当に手軽に支払いが済み、すぐに使えるようになる為、使い勝手(UX)は抜群です。サブスクリプションだけでなく買い切りタイプの購入方法もあり、解約忘れや使い過ぎなどの心配はありません。課金すると A100 VRAM 40GB が使えるようにはなりますが、T4で十分です。T4使用を想定すると、たった1000円で70時間程度使えますので本当に課金する価値はあります。
対象モデル
本稿で扱うモデルは Molmo ( Multimodal Open Language Model ) です。Molmo は一つの特定のモデルを指す言葉ではなく、VLMs(vision-language models)のファミリーを指します。Molmoファミリーは以下の4つです。
- MolmoE-1B
- Molmo-7B-O
- Molmo-7B-D
- Molmo-72B
それぞれの違いは主にパラメーター数 - Decoder Only LLM(※アーキテクチャで後述)の違いによるもので、基本的な機構の組み立ては共通しています。
今回は Molmo-7B-D モデルを対象に扱います。あくまでモデルの挙動の理解に焦点を当てているため、パラメータ数の大きすぎない基本的なモデルが良いという判断です。前述の通り、そのままのモデルでは本稿の目的からすると不必要に重いので、量子化モデルを使用します。
量子化モデルはこちらのページ内にある、Model tree for allenai > Molmo-7B-D-0924 > Quantizations から選ぶことが出来ます。今回扱うモデルは「cyan2k/molmo-7B-D-bnb-4bit」です。
- Molmoモデル(量子化バージョン)
ローカル環境 ‐ ソースコードを参照編集するための環境
Google Colab でモデルを実行するとしても、Colab 上でサイドバーから .py ファイルを開き、長いコードを読み解いたり編集したりするのはさすがに骨折り過ぎるでしょう。VSCode 等のエディタが無ければ、「文字列検索」や、「定義元ジャンプ」、「コードのハイライト機能」、「コード折りたたみ」などの機能を使えないためコードを読み解くにはあまりに面倒です。そこで、モデルの実行はせずともコードを参照編集する環境だけはローカルに構築しておきます。
まずはじめに、全体的な手順を以下に示します。
- Docker ホスト側にモデルのアプリコード一式を配置
- アプリコード一式を
git initで Git 管理 - コンテナ構築・実行
- VSCode でコンテナにアタッチ
説明へ入る前に一つ申し上げておきたいことは、モデルの挙動を調べるにあたり、初めから Github を使ってコードを管理するのがおすすめだということです。なぜなら、単にコードを参照編集するだけなのでわざわざ Git で管理する必要はないと思いましたが、これが大きな間違いで、私は後で不便さに気がついて Git の設定のためにかなり手間を取ってしまったからです。やはり、初めの横着が後の後悔でした。
コード内の調べたい箇所や機能、ロジックごとに pickle 保存やコメントアウト、print デバッグをしていくとたちまちコードが散らかってしまいます。そうならないよう Git でコードを管理してから、共通化して残したい差分はそのままコミットし、それ以外の暫定的に編集した箇所は Branch を切って丸々退避させておくと かなり楽 になります。
ローカル環境はきれいに保ちたいので Docker を使います。コンテナを構築する前に、Docker ホスト側の任意のディレクトリにモデルのアプリコード一式を保存します。git clone する方法でもよいですし、直接 Web サイトからダウンロードして手動で配置しても構いません。ローカルでは推論を実行しないので、重みのダウンロードは不要です。そして保存コードに対して Git リポジトリをつくってコードを管理します( git init )。
次にコンテナを構築します。Docker ホストのアプリディレクトリをマウントし、必要なライブラリをインストールしただけの簡単なものでよいでしょう。アプリコードをホスト側に配置して外部マウントしている理由は、Git の GUI ツールを使うためです。
下記に Dockerfile を載せていますが、うまくインストールされていないパッケージがあったため参考程度に御覧ください。細かな修正はコンテナ内でご自身の環境に合わせて適宜実行してください。
# ベースイメージとして最新のUbuntuを使用
FROM ubuntu:latest
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y \
wget \
python3 \
python3-pip \
python3.12-venv \
&& rm -rf /var/lib/apt/lists/*
# 作業ディレクトリを /app に設定
WORKDIR /app
# 仮想環境を作成し、仮想環境をアクティベートしてパッケージをインストールする
RUN python3 -m venv .env && \
. .env/bin/activate && \
pip install --upgrade pip && \
pip install transformers[torch] && \
pip install einops torchvision
# /appディレクトリをボリュームとして宣言(永続化用)
VOLUME ["/app"]
# コンテナ起動時のデフォルトコマンド(bashを起動)
CMD ["/bin/bash"]
# [WSL terminalにて実行] Windowsコマンドプロンプトで行うとマウントが正しくされないので注意。
docker build -t custom_molmo .
docker run -it --name molmo_code -v /app/molmo:/app custom_molmo
Google Colab 編
デバッグ方法(Colab環境)
モデルの推論は Colab 上で実行するため、デバッグの要領でブレークポイントを置いたり、変数を参照したりすることは出来ません。これではコードを確認しながら正しく挙動を読み取るのが大変です。
Colab 上で LLM を動作させる前提であれば、VSCode のようにブレークポイントは置けませんが、Python 標準の pdb というライブラリを使えば Colab でも標準出力を通じてインタラクティブなデバッグ操作が可能です。
Colab の左サイドバーにあるファイルから調べたい .pyファイルを開き、コードの中の所望の箇所に以下のプログラムを直接挿入することで、ブレークポイントとして動作させることが可能になります。Colab のコードセルの出力にデバッグコマンドを入力するためのフォームが現れ、フォームを通じて対話的にデバッグが出来ます。
import pdb; pdb.set_trace()
さて、pdb でブレークポイントを仕掛けることは紹介しましたが、そもそも対象となるファイルがどこにあるのか分からないと意味がありません。そこで、.py ファイルを探す方法を紹介しておきます。Hugging Face の Transformers モジュールは、モデルのコードを裏で自動的にダウンロード・キャッシュするため、システム上のどのパスにファイルが格納されているかが見えにくくなっています(「Hugging Faceの基本」で後述)。LLMをインスタンス化する際に「どのクラス定義ファイルが読み込まれているのか」を把握したい場合は、以下のようなコードを用いると、インスタンスから定義元クラスファイルのパスを取得できます。
# インスタンスのクラスを取得
cls = model.__class__
# クラス名
print(f"クラス名: {cls.__name__}")
# クラスが定義されているモジュール
module_name = cls.__module__
print(f"モジュール名: {module_name}")
# モジュールのファイルパスを取得
import sys
if module_name in sys.modules:
module = sys.modules[module_name]
file_path = getattr(module, '__file__', None)
print(f"クラス定義ファイル: {file_path}")
else:
print(f"モジュール {module_name} は見つかりませんでした。")
環境構築からモデル出力まで(Colab環境)
Molmo の量子化済みのモデルでは、こちらの Github リポジトリをクローンし、READMEにあるファイルを実行することでモデルを呼び出せるようにしてくれています。しかし、今回は GoogleColab 上でコードを触りながらモデルの挙動を調べたいので、RUNに関するコードをColabのセルにコピーして使うことにします。
つまり、README通りの処理に行うが、RUNに関しては molmo-7B-O-bnb-4bit.py を実行するのではなく、直接Colabのセルにコピペして使うということです。以下にすべての手順を示しています。
!nvidia-smi
Colab では割り当てられる GPU は実行毎にランダムとなります。したがって、上記出力における cuda のバージョンによって以下の!pip install torch torchvision --index-url https://download.pytorch.org/whl/cu124の末尾を変えます。
!git clone https://github.com/cyan2k/molmo-7b-bnb-4bit.git
!pip install torch torchvision --index-url https://download.pytorch.org/whl/cu124
!pip install torch torchvision
!pip install einops tensorflow-cpu transformers accelerate bitsandbytes
%cd /content/molmo-7b-bnb-4bit
%%time
from transformers import (
AutoModelForCausalLM,
AutoProcessor,
GenerationConfig,
)
from PIL import Image
repo_name = "cyan2k/molmo-7B-D-bnb-4bit"
arguments = {"device_map": "auto", "torch_dtype": "auto", "trust_remote_code": True}
# 【1】
# load the processor
processor = AutoProcessor.from_pretrained(repo_name, **arguments)
# 【2】
# load the model
model = AutoModelForCausalLM.from_pretrained(repo_name, **arguments)
# 【1】
# load image and prompt
inputs = processor.process(
images=[Image.open("img/lucy.jpg")],
text="Describe this image.",
)
inputs = {k: v.to(model.device).unsqueeze(0) for k, v in inputs.items()}
# 【2】
# generate output; maximum 200 new tokens; stop generation when <|endoftext|> is generated
output = model.generate_from_batch(
inputs,
GenerationConfig(max_new_tokens=200, stop_strings="<|endoftext|>"),
tokenizer=processor.tokenizer,
)
# only get generated tokens; decode them to text
generated_tokens = output[0, inputs["input_ids"].size(1) :]
generated_text = processor.tokenizer.decode(generated_tokens, skip_special_tokens=True)
# print the generated text
print(generated_text)
上記3つのセル全てを実行するのにかかる時間は 10分程度 です。量子化済みのモデルでも重みが7GBあるので、それをダウンロードするための時間がほとんどを占めています。
モデルのアーキテクチャ(全体像)
Hugging Faceの基本
Hugging Faceでは、Transformers というライブラリがモデルを利用するためのインターフェイスとしての役割を果たしています。
基本的なモデルの利用法について説明します。Github のようにリポジトリをクローンしてきて README の通りに利用を開始するのとは少し違うので注意が必要です。
まず Hugging Face では、重み(学習済みパラメータ)を含むモデルの実体(ソースコード一式)は、 Hugging Face 独自のリポジトリに入っています。そして、モデルを呼び出して利用するまでの流れは次のようになります。
Hugging Face 上のモデルを実行するには、まず該当モデルの README を参照して、必要なライブラリや依存パッケージをローカル環境にインストールします。次に、Python環境下で Transformers ライブラリが提供するモデルローダークラスに、README に記載されているモデル識別子(ユニークな文字列)を引数として渡してインスタンス化します。すると Transformers が自動的にローカルのキャッシュディレクトリへモデルの重みやコードをダウンロードし、メモリ上にロードしてくれます。これが一般的な利用手順です。
モデルアーキテクチャの全体像
論文から モデルのアーキテクチャを表す図 を引用し以下に示します。
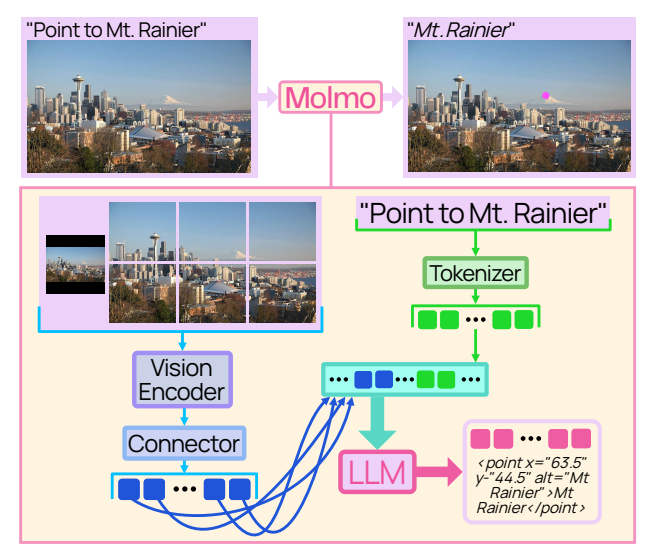
論文では、Molmo モデルは以下の4つのコンポーネントから構成されると述べられています。図には前処理を表すオブジェクトは書かれていないように見受けられます。
- 前処理 ( Pre-processor )
- 画像エンコーダ ( ViT Image Encoder )
- コネクタ ( Connector )
- LLM ( Decoder-only Transformer )
本稿でも上記4つのコンポーネントを中心にモデルの中身を読み解いていきます。
モデルのソースコード
ソースコードのリンクはこちら
LLMの処理に関して主要なファイルのみ抜粋して説明します。「前処理」と「モデル本体」が主要な処理となるのでこちら3つのファイルを中心に説明します。
■ 前処理
・image_preprocessing_molmo.py
・preprocessing_molmo.py
■ モデル本体
・modeling_molmo.py
※全てのソースコード
■ Configuration Files
・config_molmo.py
・config.json
・generation_config.json
・preprocessor_config.json
・processor_config.json
・tokenizer_config.json
■ 学習済みパラメータ
・model-00001-of-00002.safetensors
・model-00002-of-00002.safetensors
・model.safetensors.index.json
■ Tokenizer Files
・added_tokens.json
・merges.txt
・special_tokens_map.json
・tokenizer.json
・vocab.json
■ 前処理
・image_preprocessing_molmo.py
・preprocessing_molmo.py
■ モデル本体
・modeling_molmo.py
■ Documentation
・README.md
■ Git Attributes
・.gitattributes
全体像(前処理)
下記ファイルの実装に関して、全体像を眺めてみます。処理の流れが把握しやすくなるよう、実際の実装に即してクラス及びメソッド単位で処理の包含関係をまとめた概念図になります。処理内容に関しても簡単な注釈を入れています。ファイル内にあるクラスを漏れなく記載し、全体を見渡せるようにしています。
■ 前処理
・image_preprocessing_molmo.py
・preprocessing_molmo.py
クラスが赤色、メソッドが青色となっています。
-【前処理】
└── -MolmoProcessor
├── '__init__()'
│ └── super().__init__(...)
├── 'special_token_ids' (プロパティ)
│ └── → 'get_special_token_ids()'
├── 'get_tokens_input()'
│ └── プロンプト整形と tokenizer.encode() によるトークン化
└── 'process()'
├── _merge_kwargs() によるパラメータ統合
│ (MolmoProcessorKwargs, MolmoTextKwargs, MolmoImagesKwargs)
│
├── 【テキスト処理】
│ └── tokens 未指定の場合 → -MolmoProcessor: 'get_tokens_input()'
│
├── 【画像処理】 # (images を渡された場合)
│ ├── 画像データ前処理 (PIL, RGB変換, EXIF対応, 配列化)
│ └── → -MolmoImageProcessor: 'multimodal_preprocess()'を呼び出し
│ ├── '__init__()'
│ │ └── super().__init__(...) による初期設定
│ └── 'multimodal_preprocess()'
│ ├── 画像が None の場合はテキストのみ返す
│ └── 画像がある場合:
│ ├── -MolmoImageProcessor:'preprocess()'
│ │ ├── → 'image_to_patches_and_tokens()'
│ │ │ ├── base_image_input_size の変換 (int → tuple)
│ │ │ ├── → 'select_tiling()' による最適なタイル分割決定
│ │ │ ├── → 'resize_and_pad()' によるリサイズ&パディング処理
│ │ │ └── → ループ内で 'pad_to_bounding_box()' によるパッチ順序生成
│ │ └── → 'build_image_input_idx()' による patch_order の再配置・マッピング処理
│ │
│ ├── テキストトークンと画像トークンの統合処理
│ └── 画像マスク (image_masks) の処理
│
└── 【後処理】
├── BOS/EOSトークン追加 (tokens の先頭にパディング)
└── 出力テンソルへの変換 (torch.from_numpy() による torch.Tensor 化)
────────────────────────────
【補助関数】
────────────────────────────
├── 'get_special_token_ids()'
├── 'pad_to_bounding_box()'
├── 'normalize_image()'
├── 'resize_and_pad()'
└── 'select_tiling()'
全体像(モデル本体)
前処理同様、モデル本体についての全体像になります。
■ モデル本体
・modeling_molmo.py
-【推論処理(モデル本体)】
-MolmoForCausalLM (PreTrainedModel)
├── '__init__()'
│ ├── インスタンス生成 -Molmo
│ │ └── '__init__()'
│ │ ├── transformer -ModuleDict # 【テキスト処理部分】Tokenizer
│ │ │ ├── wte: ('__init__()', 'reset_parameters()', 'forward()')
│ │ │ │ → -Embedding (または nn.Embedding)
│ │ │ ├── emb_drop: ('__init__()', 'forward()')
│ │ │ │ → -Dropout
│ │ │ └── ln_f: ('LayerNorm.build()')
│ │ │ → -LayerNorm / -RMSLayerNorm / -LayerNormFp32
│ │ ├── blocks: List of -MolmoBlock # 【Decoder only LLM 本体】
│ │ │ └── 'build()' により実際は -MolmoSequentialBlock
│ │ │ ├── '__init__()'
│ │ │ │ ├── Sets dropout, 正規化層 ('attn_norm', 'ff_norm')
│ │ │ │ ├── Projection層 ('att_proj', 'ff_proj')
│ │ │ │ ├── Optional: -RotaryEmbedding
│ │ │ │ └── (共通メソッド:'reset_parameters()', 'attention()', 'forward()')
│ │ │ └── 'forward()' ( Attention 処理 + Feed-Forward 処理 + 残差接続)
│ │ └── Optionally, vision_backbone: # 【画像処理部分】Vision Encoder(CLIP) & Connector
│ │ └── -OLMoPretrainedVisionBackbone (inherits from -OLMoVisionBackbone)
│ │ ├── '__init__()'
│ │ │ ├── Creates image_vit:
│ │ │ │ └── -VisionTransformer
│ │ │ │ ├── '__init__()'
│ │ │ │ │ ├── class_embedding, positional_embedding
│ │ │ │ │ ├── patch_embedding (-Linear)
│ │ │ │ │ ├── pre_ln (-LayerNormFp32)
│ │ │ │ │ └── transformer (-BlockCollection)
│ │ │ │ └── 'forward()'
│ │ │ ├── Sets up image_pooling_2d:
│ │ │ │ ├── -MultiHeadDotProductAttention
│ │ │ │ └── -MultiHeadAttentionPool (など、設定により異なる)
│ │ │ └── Sets up image_projector:
│ │ │ └── -MLP or ModuleList(-MLP, -Residual) or -Linear
│ │ └── 'forward()'
│ │ ├── Calls 'encode_image()' (→ -VisionTransformer で画像特徴抽出)
│ │ ├── 画像パッチの再編成・Pooling
│ │ └── image_projector による最終マッピング
│ └── (その他補助メソッド: 'reset_parameters()', 'reset_non_vision_parameters()', etc.)
├── 'forward()' of -MolmoForCausalLM
│ └── Wraps -Molmo.forward() → テキスト埋め込み、位置情報・画像統合、Transformerブロック適用、最終層正規化、出力ロジット計算
└── その他生成系メソッド
├── 'generate_from_batch()'
├── 'prepare_inputs_for_generation()'
├── 'tie_weights()'
└── 'resize_token_embeddings()'
────────────────────────────
【その他主要ビルディングブロック】 # 上記モデルのサポート部分
────────────────────────────
┌── -RotaryEmbedding (nn.Module)
│ ├── '__init__()'
│ ├── 'get_rotary_embedding()'
│ ├── 'rotate_half()'
│ ├── 'rotate_every_two()'
│ ├── 'apply_rotary_pos_emb()'
│ └── 'forward()'
├── -Activation (nn.Module, 抽象クラス)
│ └── Classmethod 'build()' → returns one of:
│ ├── -QuickGELU ('forward()', property 'output_multiplier')
│ ├── -GELU
│ ├── -ReLU
│ ├── -SiLU
│ ├── -LlamaSwiGLU
│ └── -SwiGLU
├── -LayerNormBase (nn.Module)
│ └── Classmethod 'build()' → -LayerNorm / -RMSLayerNorm
├── -LayerNorm, -RMSLayerNorm, -LayerNormFp32
├── -MultiHeadDotProductAttention (nn.Module)
│ ├── '__init__()'
│ ├── 'reset_parameters()'
│ ├── '_split_heads()'
│ ├── '_merge_heads()'
│ └── 'forward()'
├── -MultiHeadAttentionPool (nn.Module)
│ └── (類似の内部メソッド)
├── -MLP (nn.Module)
│ ├── '__init__()'
│ ├── 'reset_parameters()'
│ └── 'forward()'
├── -Residual (nn.Module)
│ └── 'forward()' (x + submodule(x))
├── -ViTMLP (nn.Module)
├── -VisionTransformer (nn.Module)
│ ├── '__init__()'
│ ├── 'add_pos_emb()'
│ └── 'forward()'
├── -BlockCollection (nn.Module)
│ └── Contains a ModuleList of -ResidualAttentionBlock
├── -ResidualAttentionBlock (nn.Module)
│ └── 'forward()' (x + attention(ln(x)) then + feed_forward(ln(x)))
├── -OLMoVisionBackbone and -OLMoPretrainedVisionBackbone (nn.Module)
├── -FullMolmoConfig, -VisionBackboneConfig (dataclasses)
└── その他(ユーティリティ関数: 'ensure_finite_()', 'init_weights()', 'causal_attention_bias()' など)
実際の model オブジェクトの構造
前処理よりもモデル本体側のコード量がかなり多いので、モデル本体側についてはより丁寧な説明のために、具体的なインスタンスの構造についても言及しておきます。
こちらの図は、model オブジェクトのサブモジュールの構造(メンバにセットされているクラス)を出力した図です。当然ですが先程の図とかなり似ています。こちらには全てのクラスの情報が羅列されるような形となっているため、一つ前の図を大まかに把握したあとに見るのが良いかと思います。
- LLM側( transformer )には Attention レイヤーに相当するクラスはないのか?
ViT 側( vision_backbone )では MultiHeadDotProductAttention() のように Attention クラスがセットされていますが、LLM側には Attention に相当するクラスがセットされていません。実際には、MolmoBlock() 内のメソッドとして Attention 機能は実装されています。
- MolmoForCausalLM
└── model: -Molmo
├── transformer: -ModuleDict
│ ├── wte: -Embedding()
│ ├── emb_drop: -Dropout(p=0, inplace=False)
│ ├── ln_f: -RMSLayerNorm()
│ ├── blocks: -ModuleList
│ │ └── 0-27: 28 x -MolmoSequentialBlock # <--------- x 28
│ │ ├── dropout: -Dropout(p=0, inplace=False)
│ │ ├── act: -SwiGLU()
│ │ ├── attn_out: -Linear4bit(in_features=3584, out_features=3584, bias=False)
│ │ ├── ff_out: -Linear4bit(in_features=18944, out_features=3584, bias=False)
│ │ ├── rotary_emb: -RotaryEmbedding()
│ │ ├── attn_norm: -RMSLayerNorm()
│ │ ├── ff_norm: -RMSLayerNorm()
│ │ ├── att_proj: -Linear4bit(in_features=3584, out_features=4608, bias=True)
│ │ └── ff_proj: -Linear4bit(in_features=3584, out_features=37888, bias=False)
│ └── ff_out: -Linear(in_features=3584, out_features=152064, bias=False)
└── vision_backbone: -OLMoPretrainedVisionBackbone
├── image_vit: -VisionTransformer
│ ├── patch_embedding: -Linear4bit(in_features=588, out_features=1024, bias=False)
│ ├── pre_ln: -LayerNormFp32((1024,), eps=1e-05, elementwise_affine=True)
│ └── transformer: -BlockCollection
│ └── resblocks: -ModuleList
│ └── 0-22: 23 x -ResidualAttentionBlock # <--------- x 23
│ ├── attention: -MultiHeadDotProductAttention
│ │ ├── wq: -Linear4bit(in_features=1024, out_features=1024, bias=True)
│ │ ├── wk: -Linear4bit(in_features=1024, out_features=1024, bias=True)
│ │ ├── wv: -Linear4bit(in_features=1024, out_features=1024, bias=True)
│ │ ├── wo: -Linear4bit(in_features=1024, out_features=1024, bias=True)
│ │ └── residual_dropout: -Dropout(p=0.0, inplace=False)
│ ├── feed_forward: -ViTMLP
│ │ ├── w1: -Linear4bit(in_features=1024, out_features=4096, bias=True)
│ │ ├── act: -QuickGELU()
│ │ └── w2: -Linear4bit(in_features=4096, out_features=1024, bias=True)
│ ├── attention_norm: -LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
│ └── ffn_norm: -LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
├── image_pooling_2d: -MultiHeadDotProductAttention
│ ├── wq: -Linear4bit(in_features=2048, out_features=1024, bias=True)
│ ├── wk: -Linear4bit(in_features=2048, out_features=1024, bias=True)
│ ├── wv: -Linear4bit(in_features=2048, out_features=1024, bias=True)
│ ├── wo: -Linear4bit(in_features=1024, out_features=1024, bias=True)
│ └── residual_dropout: -Dropout(p=0.0, inplace=False)
├── image_projector: -MLP
│ ├── w1: -Linear4bit(in_features=1024, out_features=18944, bias=False)
│ ├── w2: -Linear4bit(in_features=18944, out_features=3584, bias=False)
│ ├── w3: -Linear4bit(in_features=1024, out_features=18944, bias=False)
│ ├── act: -LlamaSwiGLU()
│ └── dropout: -Dropout(p=0.0, inplace=False)
└── image_feature_dropout: -Dropout(p=0.0, inplace=False)
" Molmo.forward() " の処理フロー
生成処理において中心的な位置にあるのが Molmo クラスの forward() メソッドです。これから各処理を詳しく見ていきますが、その中心となる Molmo.forward() の全体的な流れをまず押さえておくことで、コード全体の動きがつかみやすくなります。後ほど詳しく解説しますので、まずはその大まかな役割とステップをざっくりと把握しておくと良いでしょう。
1. 入力の検証と初期設定
(処理の意図) 入力引数の形状をチェックし、不整合を防ぐ
• past_key_values から past_length を算出
• images と input_embeddings/past_key_values の同時指定を防止
- input_ids, images, image_input_idx, image_masks, attention_mask の形状チェック
- past_key_values があれば n_layers と照合し、past_length を計算
- images と input_embeddings/past_key_values の同時指定を拒否
----------------------------------------
2. テキスト埋め込みの取得
(処理の意図) 単語 ID を d_model 次元の埋め込みベクトルに変換する
• input_embeddings があればそれを利用
• なければ wte(input_ids) で埋め込みを取得
• 結果 x.shape = (batch_size, seq_len, d_model)
----------------------------------------
3. 画像特徴の抽出と統合 '論文対応: ViT encoder + Connector'
(処理の意図) 画像パッチを LLM と同じ空間に持ち込み、文脈に組み込む
• vision_backbone(images, image_masks) → ViT でパッチ特徴抽出
• プーリング+MLP で d_model 次元に射影
• image_input_idx を用い、x の対応位置に +=
----------------------------------------
4. 位置情報付与とドロップアウト適用
(処理の意図) トークンの順序情報を組み込み、過学習を抑制する
• rope=False の場合は wpe による位置エンベディングを加算
• emb_drop(x) でドロップアウトを適用
• normalize_input_embeds=True の場合は √d_model でスケーリング
----------------------------------------
5. アテンションマスクとバイアスの準備
(処理の意図) 不要なトークンへの注意を遮断し、因果律を保つ
• attention_mask → reshape (B,1,1,seq_len) → 1→0 に反転 → −inf マスク
• attention_bias が無ければ causal bias を生成
• attention_mask + attention_bias → ensure_finite_ で数値安定化
----------------------------------------
6. Transformer ブロックの適用 '論文対応: Decoder‑only Transformer LLM'
(処理の意図) 自己注意と FFN で文脈依存表現を生成する
• for block in transformer.blocks:
x, cache = block(x, attention_bias, position_ids, past_key_values, use_cache)
• 必要に応じて attn_key_values や all_hidden_states を収集
----------------------------------------
7. last_logits_only の処理
(処理の意図) 生成時に「次の1語だけ」を高速に計算する
• last_logits_only=True → x = x[:, -1, :] または append_last_valid_logits で指定位置を抽出
• 出力形状を (batch_size, 1, d_model) に整形
----------------------------------------
8. 最終正規化とロジット計算
(処理の意図) 隠れ状態を語彙ごとのスコア(ロジット)に変換し、必要ならスケール調整する
• x = ln_f(x) (最終 LayerNorm)
• weight_tying=True → logits = F.linear(x, wte.weight)
False → logits = ff_out(x)
• scale_logits=True → logits.mul_(1/√d_model)
----------------------------------------
9. 出力の返却
(処理の意図) 上流処理にモデルの出力を渡す
• return ModelOutput(logits, attn_key_values, hidden_states)
備考
更新情報(実装)
最近のアップデートでは、以前の MolmoSequentialBlock() クラスが OLMoLlamaBlock()に置き換えられています。
更新情報( Issue )
Transformer のバージョン依存によって一部コードが動作しなくなる問題の報告が上がっています。以下の Issue で詳細が共有されているので、もし同様のエラーが発生した場合はそちらを確認してください。
テキストのみでの推論
量子化モデル( cyan2k )の前処理実装ファイルを、allenai のオリジナル Molmo の前処理実装ファイルにそのまま置き換えることで、images=None を指定した場合でも正しく動作します。これにより画像がなくてもテキストのみで推論を行うことが可能になります。なお、cyan2k の実装では画像なしの推論を実行するとエラーが発生するため注意してください。
inputs = processor.process(
images=None,
text="Describe this image.",
)
重みファイルの場所
モデルの学習済み重みはソースコード本体とは別の場所に保管されています。Transformers を使ってモデルを呼び出す際、重みはシンボリックリンクを経由してキャッシュディレクトリ内の以下のパスから読み込まれます。
root@1cf45163581c:~/.cache/huggingface/hub/models--allenai--Molmo-7B-D-0924/blobs# ls -lh
total 30G
-rw-r--r-- 1 root root 4.7G Jan 13 08:43 13c402c3dacb85a010c22f3472090e5b1cbefe8386a7cc79755c8820503a9635
-rw-r--r-- 1 root root 2.0K Jan 13 07:57 2322810b01f38dbfe7e6581da01df60cd92087e0
-rw-r--r-- 1 root root 3.6G Jan 13 10:06 2c84ff3f7adcfdf9eec4247291ca1fcad02cf7005c84801f31223711df54846a
-rw-r--r-- 1 root root 806 Jan 13 07:57 3071ce53b36aa803b93758e5f7d56865f428d98c
-rw-r--r-- 1 root root 4.7G Jan 13 08:26 3877e2be156fa08e67adc932cf812e7be6a41f1cb2e6be17044ab778a6a10965
-rw-r--r-- 1 root root 4.4G Jan 13 09:36 38a5046ae726c9e5cdeb27f891486c35c921f95fd582ee6a5b897b9e554a80c9
-rw-r--r-- 1 root root 4.4G Jan 13 09:18 604f0181f708d1d6c56e8cd06aea74e43922985afbcd83d62e3fed3565837804
-rw-r--r-- 1 root root 4.0G Jan 13 09:52 6b034831173c907ec577af6a8297a4fdb5385ecd861b13c0c12f3d0072b080c4
-rw-r--r-- 1 root root 69 Jan 13 10:06 b0d282ee31d19141d61c6740dcbf23218565a795
-rw-r--r-- 1 root root 94K Jan 13 07:57 d68da0483cd551ccda92b1217dfa1013474c1b4d
-rw-r--r-- 1 root root 4.5G Jan 13 09:00 ed917e44b920a8b56a7db53e8a0641a447dd8630e36d76abef857a6883306b9a
-rw-r--r-- 1 root root 62K Jan 13 08:07 f07ec9f8129893547d831c0ef68b54921e16e25d
次の記事