はじめに
【前の記事】
- Molmo ( Multimodal Open Language Model ) モデル
- Molmoモデル(量子化バージョン)
モデルのアーキテクチャ(個別要素)
ここからモデルの内部を詳しく覗いていくつもりですが、ソースコードを一行一行順番に説明していたら流石にキリがありません。本稿では、一つの具体的なデータを用いて、そのデータがどのように処理されていくのかの流れを追うことで、内部の機構を見ていくことにします。あくまで、本稿の数字は例示したデータにおける数字です。データの次元など、入力データによって動的に変化しますので、勘違いなさならないようにしてください。
前処理 (Pre-processor)
処理ロジックにいくつかの要点
一番初めの「前処理」から見ていくのですが、正直、ここが一番理解しづらい部分かと思います。前処理では、後続のモデル内における処理を考えて前処理されるので、何故そのような前処理をしているのかといった部分が見えてこないからです。全体の流れをわかったうえで見ると、大した複雑性はありませんが、よくわからない状態で見ると逆にさっぱりわからないということになるでしょう(どんな勉強も大抵そうですが…)。
種明かしからするみたく、天下り的な順序での説明になってしまいますが、実際の処理データや実装を見る前に以下の部分については簡単に理解しておきましょう。
クロップ分割( crop )とパッチ分割( patches )の違い
モデルアーキテクチャを表す図をみてもわかるように、まず画像は格子状に分割されます。この分割を「クロップ」といいます。各クロップは独立して ViT に入力され、それぞれ個別に処理されます。このクロップは ViT に入力されるとき、実際にはさらに細かく分割されて ViT に入力されます。この分割のことを「パッチ」といいます。クロップの重なり部分のパッチ特徴量はコネクタや LLM へは渡さず、渡されるパッチ特徴が高解像度画像(元の画像)を正確にタイルするようにしています。重なりによりタイル状画像の解像度は若干低下しますが、より多くのクロップを使用することでその影響を補うことができ、重なりは結果を大幅に改善します。
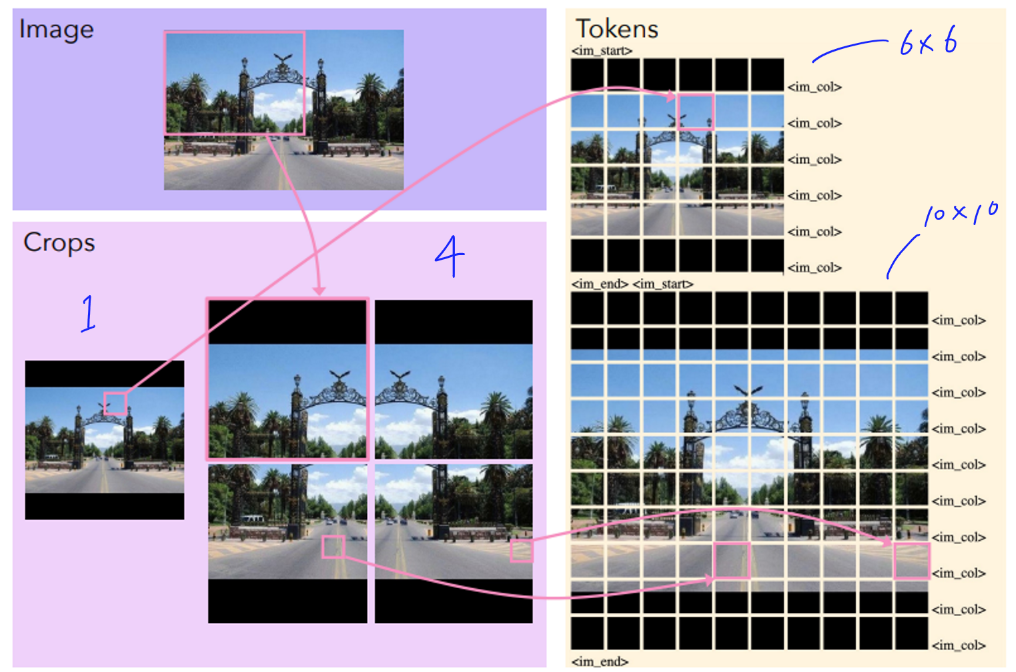
クロップの分割数の決め方
今回の例の場合だとクロップの分割は「3×3」となりますが、クロップの分割はいつも一定の分割数でしょうか?答えはノーです。ではこれは一体どの様なロジックでこの分割数になっているのでしょうか?
クロップ数は固定ではなく、入力画像に合わせて動的に決定されます。具体的には、image_preprocessing_molmo.py/select_tiling() 関数が、画像のリサイズ(アップスケーリングまたはダウンスケーリング)の必要性を最小限に抑えながら、指定されたクロップサイズと最大クロップ数の制約内で画像を分割する最適なグリッド構成をルールベースに決定します。Vision Transformer(ViT)の多くは固定サイズの正方形画像しか処理できないため、グリッド内の各正方形がViT の入力サイズと一致するように画像を複数のクロップに分割し、それぞれを高解像度で処理することで、OCR や詳細なキャプショニングなどに必要な細かい情報を保持します。今回のように、各クロップ画像のサイズが 336×336 ピクセルで、1 枚のクロップを 14×14 ピクセルのパッチに分割する場合、各クロップは 24×24 個(合計576個)のパッチに分割されます。なお、以下は事前に config で定めているハイパーパラメータです。
- クロップの一辺の長さ : 336
- パッチの一辺の長さ : 14
パッチ分割自体は動的に変化する要素はなく、ViT の入力サイズとパッチサイズは固定であるため、クロップのように複雑な処理を必要としません。
コード全文 ( select_tiling() )
def select_tiling(h, w, patch_size, max_num_patches):
"""Decide how best to divide in image of size [w, h] in up to max_num_patches of size patch_size"""
original_size = np.stack([h, w]) # [1, 2]
original_res = h * w
tilings = []
for i in range(1, max_num_patches+1):
for j in range(1, max_num_patches+1):
if i*j <= max_num_patches:
tilings.append((i, j))
# sort so argmin and argmax favour smaller tilings in the event of a tie
tilings.sort(key=lambda x: (x[0]*x[1], x[0]))
candidate_tilings = np.array(tilings, dtype=np.int32) # [n_resolutions, 2]
candidate_resolutions = candidate_tilings * patch_size # [n_resolutions, 2]
# How much we would need to scale the image to fit exactly in each tiling
original_size = np.stack([h, w], dtype=np.float32) # [1, 2]
required_scale_d = candidate_resolutions.astype(np.float32) / original_size
required_scale = np.min(required_scale_d, axis=-1, keepdims=True) # [n_resolutions, 1]
if np.all(required_scale < 1):
# We are forced to downscale, so try to minimize the amount of downscaling
ix = np.argmax(required_scale)
else:
# Pick the resolution that required the least upscaling so that it most closely fits the image
required_scale = np.where(required_scale < 1.0, 10e9, required_scale)
ix = np.argmin(required_scale)
return candidate_tilings[ix]
前処理データ
ここから、具体的なデータの中身について迫っていきたいと思います。
# 【1】
# load the processor ←(前処理用オブジェクトのインスタンス化)
processor = AutoProcessor.from_pretrained(repo_name, **arguments)
# 【1】
# load image and prompt ←(前処理)
inputs = processor.process(
images=[Image.open("img/lucy.jpg")],
text="Describe this image.",
)
inputs = {k: v.to(model.device).unsqueeze(0) for k, v in inputs.items()}
processorオブジェクトのクラスを調べると以下のようになっています。全体像のパートにおけるクラス同士の関係を見てもわかるように、preprocessing_molmo.py が image_preprocessing_molmo.py を呼び出して使っており、前処理のメインのロジックはほとんど image_preprocessing_molmo.py 側で実装されているようです。
クラス名: MolmoProcessor
モジュール名: transformers_modules.cyan2k.molmo-7B-D-bnb-4bit.51097c4251a023d72485963c1ab69f3b6d6a1ec6.preprocessing_molmo
クラス定義ファイル: /root/.cache/huggingface/modules/transformers_modules/cyan2k/molmo-7B-D-bnb-4bit/51097c4251a023d72485963c1ab69f3b6d6a1ec6/preprocessing_molmo.py
■ 前処理に関係するファイル
・image_preprocessing_molmo.py
・preprocessing_molmo.py
さて、次は実際の「 元データ(前処理前データ) 」と「 前処理後データ 」を見ていきます。
元データ(前処理前データ)のデータ形式は「JPEG」と「テキスト」です。前処理後データは inputs オブジェクトに格納されていますが、この時点ではどの様なデータになっているでしょうか?それぞれデータを調べてみます。
まずは、元データ(前処理前データ) です。processor.process() の引数部分を見てください。
特に変わった部分はなさそうです。
・images
‐ 画像フォーマット: JPEG
‐ カラーモード: RGB
‐ 幅x高さ: (1536, 1536)
・text
- "Describe this image."
・images の画像

次にこちらが 前処理後データ ( inputs オブジェクト)です。
inputs は4つのデータを内包する dict で、中身は全て tensor 形式のオブジェクトであり、次元等は以下のようになっています。これを見ただけではまだ、各データが何を表しているのかさっぱりわからないと思います。このあと、各データについて説明を付けたので、続きをご覧ください。
key: input_ids | shape: torch.Size([981]) | Dtype: torch.int64
key: images | shape: torch.Size([10, 576, 588]) | Dtype: torch.float32
key: image_input_idx | shape: torch.Size([10, 144]) | Dtype: torch.int32
key: image_masks | shape: torch.Size([10, 576]) | Dtype: torch.float32
-
input_ids [981]
最終的に LLM に入力する際のデータの雛形として、画像もテキストも一次元化して並べる形式になっています。下記画像では「152066」が黄色で着色されており、ここにはパッチ特徴量が格納される予定です。実際にはほとんどが画像特徴用に予約されており、ところどころにある非着色の部分は画像の始まりや改行を表す特殊トークンが予約されています。末端の要素は単語 ID になっており、まだ埋め込み前なので単語ごとに ID が付与された状態です。このデータ自体はあくまで一次元ですが、後続のモデル内処理において特徴量用の次元が拡張され、そこに実際の特徴量が格納されます。Model 側のコードではこの配列が変数 x に相当し、ここをベースにあとでテキストと画像の両方の特徴量を埋めていくことになります。
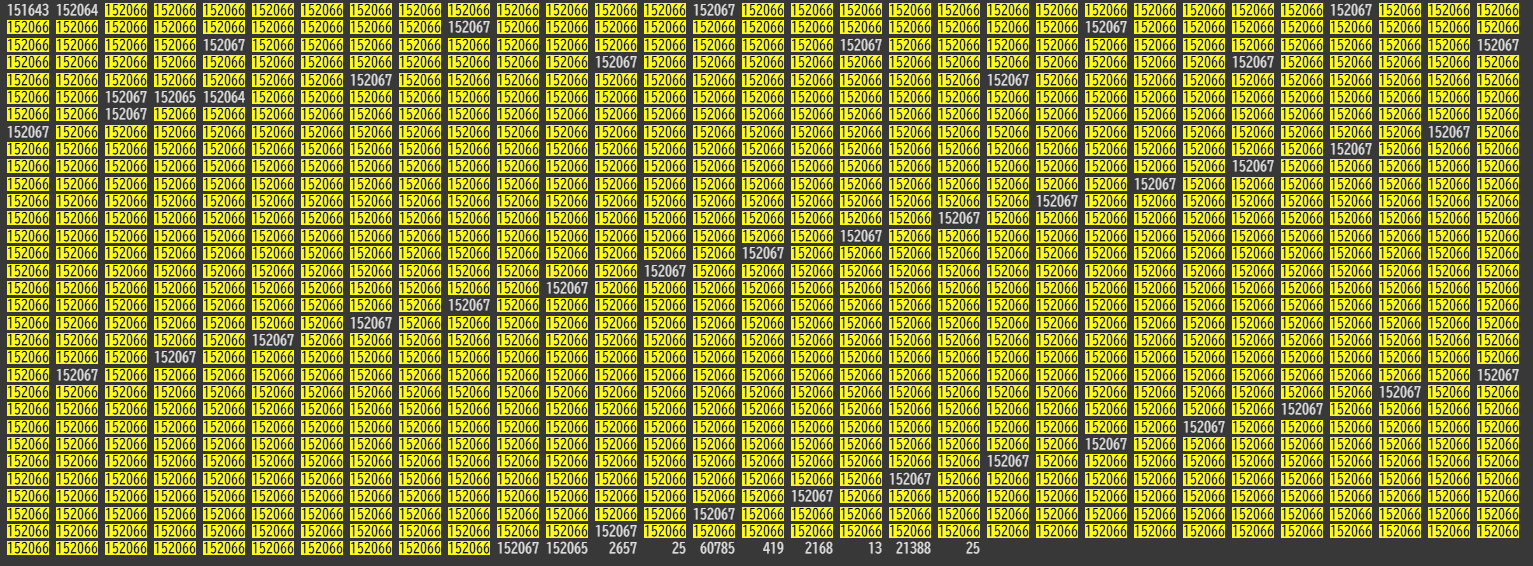
-
images [10, 576, 588]
クロップした画像情報そのもので、グローバルクロップとローカルクロップを合わせて計10枚の元データを表します。
1クロップに対し、パッチ数は 576 枚 ( $\left(\frac{\text{crop_size}}{\text{patch_size}}\right)^2 =\ \left(\frac{336}{14}\right)^2 =\ 24^2$ ) 、
1パッチに対し、ピクセル数は 588( $ \text{patch_size}^2 \times \text{channel} =\ 14^2 \times 3$ )です。
このimagesは、後続の Vision Transformer(OpenAI CLIP)に入力されて特徴ベクトルへと埋め込まれたうえで、最終的にinput_idsに収められます。 -
image_input_idx [10, 144]
画像パッチの番地を示す配列で、プーリング後や特殊トークンを考慮した形になっています。これはクロップ間の重複部分を表すデータでもあり、各パッチ特徴量がどこに格納されるかを示す番地のような役割を果たします。 -
image_masks [10, 576]
画像領域とパディングされた非画像領域を区別するための配列です。今回のデータではそもそもサンプルが正方形なため、すべて「画像を表す特殊トークン」や True のマスクが設定されているかと思います。
実装上の前処理データとの対応
前処理データについてわかってしまえば、前処理の実装を読み解くことは容易いかと思います。その為、あまり実装について書くことはないのですが、調べる上でひとつ分かりづらいと思った点があったのでそれだけ以下に書いておきます。それは、様々なデータの変数名が似通っているが、メソッドごとで微妙に異なり、最終的にどの前処理後データと対応するのかが分かりづらいという点です。いくつかについてのみ、処理途中の変数名と前処理後データを対応させてまとめましたので、実装を読む際にはご参考にしてください。
MolmoImageProcessor.preprocess()
-
image_tokens: shape = (972,)
・前処理後データのinout_idsとなるデータ。
-
crops: shape = (10, 576, 588)
・前処理後データのimagesとなるデータ。 -
patch_ordering: shape = (1440,)
・前処理後データのimage_input_idxとなるデータ。

-
patch_idx: shape = (10, 144)
・前処理後データのimage_input_idxとなるデータ。
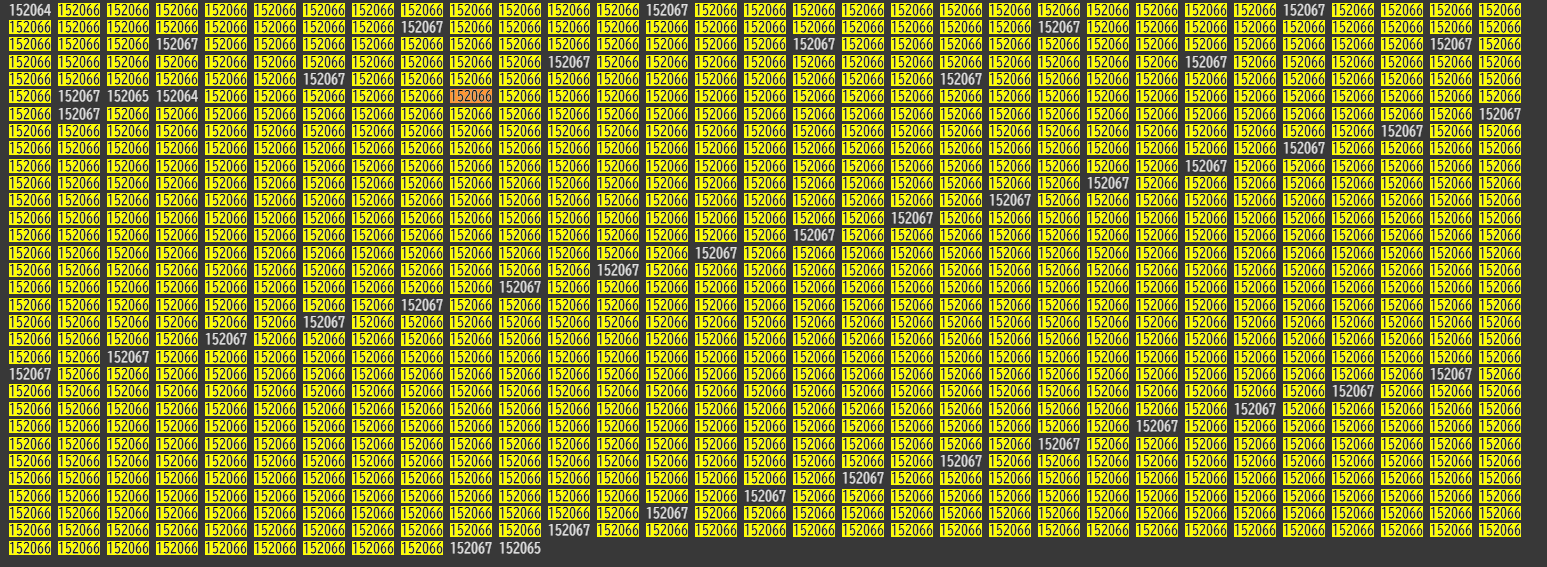
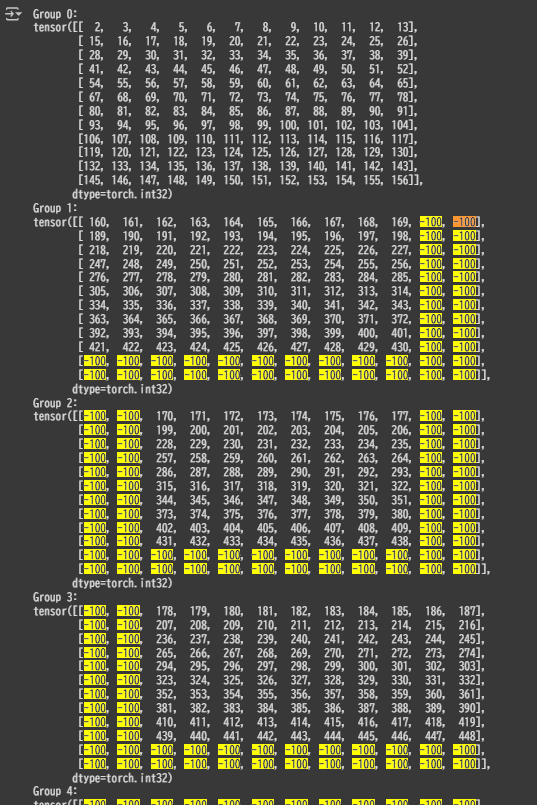
MolmoImageProcessor.build_image_input_idx()にて、patch_orderingに変換処理をするような形でpatch_idxが作られます。このメソッドは、トークン列中の画像パッチトークンの位置と、画像パッチの順序付けを使って「トークンID → パッチID」のマッピング処理をするものです。patch_orderingの段階ではパッチに対して左上から右下にかけて通し番号が振られているだけでしたが、patch_idxになると改行トークンがあるので、トークン位置12の次が改行後は14になっています。下図はわかりやすいよう(10, 12, 12)に reshape しています。一番上の最初の要素がグローバルクロップで、残り9枚は局所画像クロップのデータになります。各クロップの端に位置するマージンの領域に関して、overlap_marginsは4パッチですが、2 × 2 のプーリングをするとラップ長は 2 パッチ分になるので下記画像のように 長さが 2 になります。
後で LLM への入力シーケンスをフラット化して一次元にしたとき、patch_idxの情報がないとどこに何が格納されているのかわからなくなり、データに対して狙った演算や操作をすることが難しくなります。この情報さえあれば、後続の処理でファンシーインデックスを使い狙った位置にアクセスしてデータの操作が可能です。下記画像で言えば、「(LLMへ入力するために一次元化した)入力データの前から160番目の要素(トークン位置160)は、ローカルクロップ一枚目の左上の右隣のパッチの情報ですよ」ということを表してます。

-
img_mask: shape = (10, 576)
・前処理後データのimage_masksとなるデータ。
MolmoImageProcessor.image_to_patches_and_tokens()
-
joint
・前処理後データのinput_idsとなるデータ。
joint トークン列は画像の「グリッド構造」をテキストのトークンとして表現し、各パッチの位置や区切り情報をモデルに伝えるための「目印」として利用されます。image_col_token_idを使って各行の終わりを示し、行の区切りを明示するなど、jointは後続の処理において画像特徴量と対応付けるために必要なデータです。
[ image_start_token_id,
image_patch_token_id, image_patch_token_id, image_patch_token_id, image_patch_token_id, image_col_token_id,
image_patch_token_id, image_patch_token_id, image_patch_token_id, image_patch_token_id, image_col_token_id,
image_patch_token_id, image_patch_token_id, image_patch_token_id, image_patch_token_id, image_col_token_id,
image_end_token_id ]
-
patch_ordering_arr
・前処理後データのimage_input_idxとなるデータ。 -
mask_arr
・前処理後データのimage_masksとなるデータ。
画像エンコーダ (ViT Image Encoder)
いよいよLLM自体の処理の解説に移ります。ここからが本題です。
推論の実行 - forward() の call
この節以降からは以下の処理内部の話になります。
# 【2】
# load the model
model = AutoModelForCausalLM.from_pretrained(repo_name, **arguments)
# 【2】
# generate output; maximum 200 new tokens; stop generation when <|endoftext|> is generated
output = model.generate_from_batch(
inputs,
GenerationConfig(max_new_tokens=200, stop_strings="<|endoftext|>"),
tokenizer=processor.tokenizer,
)
Colabにて、Molmoモデルのインスタンスからファイルの場所を出力します。出力方法は上述の「デバッグ方法」を参照してください。
クラス名: MolmoProcessor
モジュール名: transformers_modules.cyan2k.molmo-7B-D-bnb-4bit.51097c4251a023d72485963c1ab69f3b6d6a1ec6.preprocessing_molmo
クラス定義ファイル: /root/.cache/huggingface/modules/transformers_modules/cyan2k/molmo-7B-D-bnb-4bit/51097c4251a023d72485963c1ab69f3b6d6a1ec6/preprocessing_molmo.py
ディープラーニングモデルにおいてモデルの処理のコアとなる部分は、モデルの forward() 関数です。これがモデルの処理の一丁目一番地になります。forward() 関数がどの順番で呼ばれるのかを調べるため、ソースコードを開き、forward() 関数の中に pdb のブレークポイントを仕込みます。そして、推論を実行しデバッガコマンドのwを実行することで、スタックトレースを標準出力にプリントすることが出来ます。
以下が forward() を呼び出すまでの過程です。スタックトレースの出力からモデルの挙動にあまり関係のないものを除いて編集したものになります。
<ipython>(11)<cell line: 0>()
9
10 # generate output; maximum 200 new tokens; stop generation when <|endoftext|> is generated
---> 11 output = model.generate_from_batch(
12 inputs,
13 GenerationConfig(max_new_tokens=200, stop_strings="<|endoftext|>"),
/root/.cache/huggingface/modules/transformers_modules/cyan2k/molmo-7B-D-bnb-4bit/51097c4251a023d72485963c1ab69f3b6d6a1ec6/modeling_molmo.py(2468)generate_from_batch()
2466 assert attention_mask.shape == (batch_size, mask_len)
2467
-> 2468 out = super().generate(
2469 batch["input_ids"],
2470 generation_config,
/usr/local/lib/python3.11/dist-packages/transformers/generation/utils.py(2252)generate()
2250
2251 # 12. run sample (it degenerates to greedy search when `generation_config.do_sample=False`)
-> 2252 result = self._sample(
2253 input_ids,
2254 logits_processor=prepared_logits_processor,
/usr/local/lib/python3.11/dist-packages/transformers/generation/utils.py(3251)_sample()
3249
3250 if is_prefill:
-> 3251 outputs = self(**model_inputs, return_dict=True)
3252 is_prefill = False
3253 else:
/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py(1736)_wrapped_call_impl()
1734 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1735 else:
-> 1736 return self._call_impl(*args, **kwargs)
1737
1738 # torchrec tests the code consistency with the following code
/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py(1747)_call_impl()
1745 or _global_backward_pre_hooks or _global_backward_hooks
1746 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1747 return forward_call(*args, **kwargs)
1748
1749 result = None
> /root/.cache/huggingface/modules/transformers_modules/cyan2k/molmo-7B-D-bnb-4bit/51097c4251a023d72485963c1ab69f3b6d6a1ec6/modeling_molmo.py(2362)forward()
2360
2361 # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
-> 2362 outputs = self.model.forward(
2363 input_ids=input_ids,
2364 input_embeddings=inputs_embeds,
スタックトレースの出力(編集なし)
<ipython-input-4-11c8696a2549>(11)<cell line: 0>()
9
10 # generate output; maximum 200 new tokens; stop generation when <|endoftext|> is generated
---> 11 output = model.generate_from_batch(
12 inputs,
13 GenerationConfig(max_new_tokens=200, stop_strings="<|endoftext|>"),
/usr/local/lib/python3.11/dist-packages/torch/utils/_contextlib.py(116)decorate_context()
114 def decorate_context(*args, **kwargs):
115 with ctx_factory():
--> 116 return func(*args, **kwargs)
117
118 return decorate_context
/root/.cache/huggingface/modules/transformers_modules/cyan2k/molmo-7B-D-bnb-4bit/51097c4251a023d72485963c1ab69f3b6d6a1ec6/modeling_molmo.py(2468)generate_from_batch()
2466 assert attention_mask.shape == (batch_size, mask_len)
2467
-> 2468 out = super().generate(
2469 batch["input_ids"],
2470 generation_config,
/usr/local/lib/python3.11/dist-packages/torch/utils/_contextlib.py(116)decorate_context()
114 def decorate_context(*args, **kwargs):
115 with ctx_factory():
--> 116 return func(*args, **kwargs)
117
118 return decorate_context
/usr/local/lib/python3.11/dist-packages/transformers/generation/utils.py(2252)generate()
2250
2251 # 12. run sample (it degenerates to greedy search when `generation_config.do_sample=False`)
-> 2252 result = self._sample(
2253 input_ids,
2254 logits_processor=prepared_logits_processor,
/usr/local/lib/python3.11/dist-packages/transformers/generation/utils.py(3251)_sample()
3249
3250 if is_prefill:
-> 3251 outputs = self(**model_inputs, return_dict=True)
3252 is_prefill = False
3253 else:
/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py(1736)_wrapped_call_impl()
1734 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1735 else:
-> 1736 return self._call_impl(*args, **kwargs)
1737
1738 # torchrec tests the code consistency with the following code
/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py(1747)_call_impl()
1745 or _global_backward_pre_hooks or _global_backward_hooks
1746 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1747 return forward_call(*args, **kwargs)
1748
1749 result = None
> /root/.cache/huggingface/modules/transformers_modules/cyan2k/molmo-7B-D-bnb-4bit/51097c4251a023d72485963c1ab69f3b6d6a1ec6/modeling_molmo.py(2362)forward()
2360
2361 # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
-> 2362 outputs = self.model.forward(
2363 input_ids=input_ids,
2364 input_embeddings=inputs_embeds,
-> 2468 out = super().generate() が呼び出されると、モデル固有の generate() メソッドから一歩離れて、Hugging Face Transformers と PyTorch が提供する親クラスの処理に移行します。この Molmo() が継承する親クラスでは、生成のために複数の内部メソッドが順番に呼び出され、その中で最終的に forward()が実行される仕組みになっています。PyTorch の慣習として、ユーザ実装の forward() を直接呼び出すのではなく、モデルインスタンスに対して model( input ) のように呼び出し可能オブジェクト(__call__)を介して入力を与えることが推奨されています。実際スタックトレースを見てみると、モデルの骨組みとなる親クラスの一つ /usr/local/lib/python3.11/dist-packages/transformers/generation/utils.pyの内部にて、 model( input ) の形で forward() が call されています。
単語埋め込み
MolmoForCausalLM.forward() が call されると、すぐに Molmo.forward() の処理に移ります。
Molmo.forward() では、はじめに入力データに対するいくつかのバリデーション処理の後、以下のトークンIDから特徴量ベクトルへの変換処理が実行されます。
x = self.transformer.wte(input_ids) if input_embeddings is None else input_embeddings # type: ignore
属性 wte の実体は Embedding() です(全体図参照)。Embeddingは、単語IDをベクトルに変換する“辞書”のようなものです。内部に語彙数×埋め込み次元の行列 W を持ち、入力IDを行番号として該当行をそのまま取り出します(行列積はナシ)。初期値は正規分布でランダムに設定され、学習中は誤差逆伝播で該当行だけが更新される。結果的に意味が近い単語ほど似た方向のベクトルに収束します。
ViT ( OpenAI CLIP )
x = self.transformer.wte(input_ids) if input_embeddings is None else input_embeddings # type: ignore
num_image: Optional[int] = None
if images is not None:
# shape: (batch_size, num_image, num_patch, d_model)
# cls_embed: (batch_size, num_image, d_model)
image_features, cls_embed = self.vision_backbone(images, image_masks)
num_image, num_patch = image_features.shape[1:3]
assert image_input_idx.shape == (batch_size, num_image, num_patch)
vision_backbone の中に画像を特徴量埋め込みする機能が入っています。実際にオブジェクトを見てみると、OLMoPretrainedVisionBackbone クラスとなっています。全体図内の vision_backbone 以下を見てもわかりますが、ここには大きく3つの機能が実装されています。3つの機能とは、ViT画像エンコーダ(image_vit)、アテンションプーリング(image_pooling_2d)、コネクタ(image_projector)です。
この内の一つ、「 ViT 画像エンコーダ( image_vit )」の実体が ViT ( OpenAI CLIP ) となっているのです。つまり、VisionTransformerクラスがまさに ViT ( OpenAI CLIP ) の画像エンコーダ部分ということになります。
OLMoPretrainedVisionBackbone.encode_image() の中で ViT 埋め込みと、埋め込み特徴量の複数層取り出し及び結合が実行されています。
ViT の解説までしていると長過ぎるので踏み込みません。別途、論文をご参照ください。
とはいっても、使うのは CLIP の中の画像エンコーダ部分のみで、それはほぼ ViT そのものです。そこで実際、ViTの概念図右側(Transformer Encoder)を見てみると、Molmo の ViT 実装も概ねオリジナルの ViT の概念図の通りであることが読み取れます。
- MultiHeadAttention(黄緑ブロック) →
MultiHeadDotProductAttention(attention) - Norm(黄色ブロック) →
LayerNorm(attention_norm) - Norm(黄色ブロック) →
LayerNorm(ffn_norm) - MLP(水色ブロック) →
ViTMLP(feed_forward)
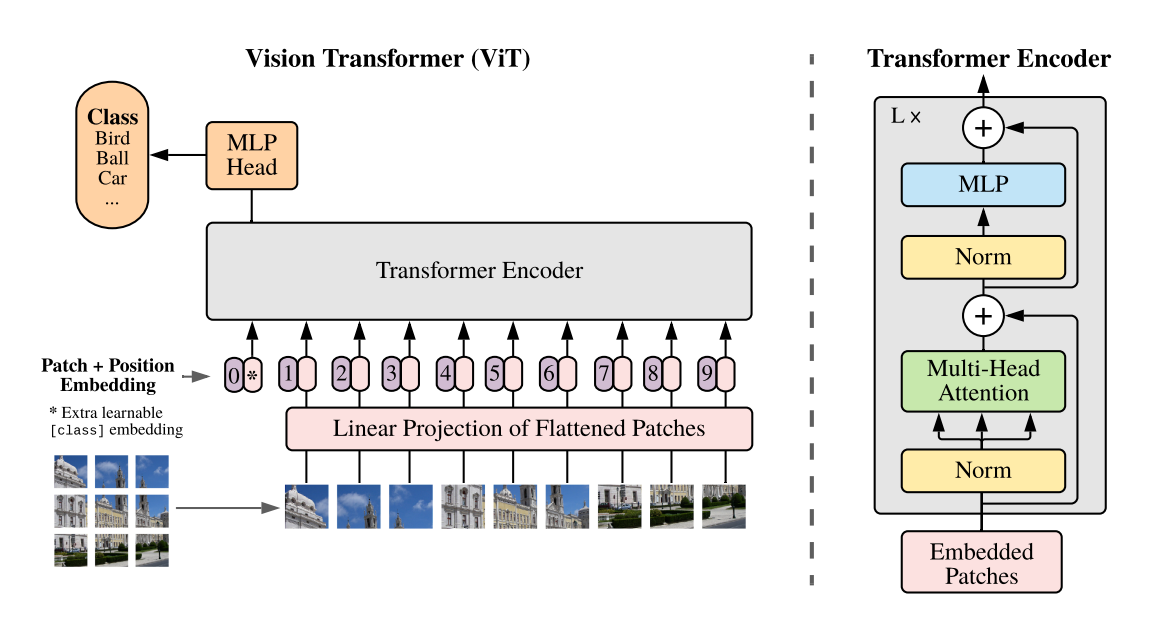
└── vision_backbone: -OLMoPretrainedVisionBackbone
├── image_vit: -VisionTransformer
│ ├── patch_embedding: -Linear4bit(in_features=588, out_features=1024, bias=False)
│ ├── pre_ln: -LayerNormFp32((1024,), eps=1e-05, elementwise_affine=True)
│ └── transformer: -BlockCollection
│ └── resblocks: -ModuleList
│ └── 0-22: 23 x -ResidualAttentionBlock # <--------- x 23
│ ├── attention: -MultiHeadDotProductAttention
│ │ ├── wq: -Linear4bit(in_features=1024, out_features=1024, bias=True)
│ │ ├── wk: -Linear4bit(in_features=1024, out_features=1024, bias=True)
│ │ ├── wv: -Linear4bit(in_features=1024, out_features=1024, bias=True)
│ │ ├── wo: -Linear4bit(in_features=1024, out_features=1024, bias=True)
│ │ └── residual_dropout: -Dropout(p=0.0, inplace=False)
│ ├── feed_forward: -ViTMLP
│ │ ├── w1: -Linear4bit(in_features=1024, out_features=4096, bias=True)
│ │ ├── act: -QuickGELU()
│ │ └── w2: -Linear4bit(in_features=4096, out_features=1024, bias=True)
│ ├── attention_norm: -LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
│ └── ffn_norm: -LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
コネクタ (Connector)
アテンションプーリング
ViT ( OpenAI CLIP )での処理を経た後、特徴量に対してプーリング処理をします。
プーリングといえば近隣の値を足したり平均値や最大値を取ったりするだけではと思ってしまいますが、Attentionを使ったプーリングとは一体何でしょう?
結論から言うと、アテンションプーリングとは所謂、以下の式で示される 通常の Attention 計算 と同じです。実際、実装上も ViT で使われているものと同じ MultiHeadDotProductAttention クラスが使われています。しかし、アテンション " プーリング " ですから、プーリングに相当する工夫がなされています。実装を追っていきそれを確認します。
- Attention Pooling
\begin{aligned}
& \operatorname{Attention}(Q,K,V)
= \operatorname{softmax}\!\Bigl(
\frac{QK^T}{\sqrt{d_k}}
\Bigr)V \\
& y= \operatorname{Linear}\Bigl(
\operatorname{MergeHeads}\bigl(
\operatorname{Attention}(Q,K,V)
\bigr)
\Bigr)
\end{aligned}
# before_rearrange : type = Tensor, shape = (1, 10, 24, 24, 2048)
# after_rearrange : type = Tensor, shape = (1440, 4, 2048)
image_features = einops.rearrange(
image_features,
'b n (h dh) (w dw) c -> (b n h w) (dh dw) c',
dh=cfg.image_pooling_h,
dw=cfg.image_pooling_w,)
# query : type = Tensor, shape = (1440, 1, 2048)
query = image_features.mean(-2, keepdim=True)
# after_pooling : type = Tensor, shape = (1440, 1, 1024)
image_features = self.image_pooling_2d(query, image_features) # MultiHeadDotProductAttention()
ViT(OpenAI CLIP)でクロップ画像をエンコードした後、本実装では第3層と第10層のパッチ特徴をチャネル方向で連結して最終的なパッチ特徴量を構築します。これは単一層のみを用いる場合に比べ、若干の性能向上をもたらします。
つづいて einops.rearrange を用いて、バッチ数やクロップ数、ウィンドウサイズ(隣接する 2 × 2 パッチの小領域)ごとにまとめて、形状を変換します。ここで、各ウィンドウ内のパッチ特徴量の平均を取り、次元を 4→1 に落としたものをクエリとして用意します。
最後に、self.image_pooling_2d()( MultiHeadDotProductAttention クラス)に、キー(K)・バリュー(V)としてウィンドウ内の全パッチ特徴量、クエリとして先ほどの平均特徴量を与え、Attention 計算を実行します。ここで Attention 演算によりウィンドウ内の情報を重み付きで統合し、元の 4 次元分の情報を 1 次元に集約させることでプーリングが実現します。さらに、複数層の特徴量を連結してできた高次元部分は、self.wo(出力線形層)を通すことで最終的に LLM モデル埋め込み次元(1024)へ射影されます。この一連の流れにより、単純な平均プーリング以上に「重要なパッチ」を強調したプーリングが可能となり、視覚特徴の集約精度が向上します。
簡単に書くと、Transformer の Attention と機構は同じですが、今回のように Pooling が目的の場合、query ベクトルの次元を4→1に落として
KおよびVと行列積を取ることで次元が落ちる機構です。こうして上記コードの通り、image_featuresは Attention Pooling によって4→1に次元が落ちています。
余談ですが、einops(アインオプス)をここで初めてみて、すごく便利だと思いました。因数を指定して変形したい次元形状に変えられるのは、本当に直感的にやりたいことが実現出来てかなりいいなと思いました。
LLM 埋め込み空間へのマッピング(投影)
こちらがマッピング処理のエントリーポイントになります。
if self.grad_checkpointing:
from torch.utils.checkpoint import checkpoint
image_features = checkpoint(self.image_projector, image_features, use_reentrant=False)
else:
image_features = self.image_projector(image_features)
論文の中ではモデルを形作る4つのコンポーネントの1つとして扱われていますが、その実体は全てのコードを貼り付けられるぐらい量も少なく、ロジックも平易なものです(※reset_parameters のみ省略)。線形写像に活性化関数という、ディープラーニング事始めといった具合です。説明は不要でしょう。
class MLP(nn.Module):
def __init__(self, config: FullMolmoConfig, input_dim: int, dropout: float = 0.0):
super().__init__()
self.config = config
self.hidden_size = (
config.mlp_hidden_size if config.mlp_hidden_size is not None else config.mlp_ratio * config.d_model
)
self.initializer_range = config.initializer_range
self.w1 = nn.Linear(
input_dim,
self.hidden_size // 2,
bias=False,
device=config.init_device,
)
self.w2 = nn.Linear(
self.hidden_size // 2,
config.d_model,
bias=False,
device=config.init_device,
)
self.w3 = nn.Linear(
input_dim,
self.hidden_size // 2,
bias=False,
device=config.init_device,
)
# Activation function.
self.act = Activation.build(config)
self.dropout = Dropout(dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.w2(self.act(self.w1(x), self.w3(x)))
x = self.dropout(x)
return x
LLMへクロップ重複部分をパスしないようにする
前処理の段階でも説明しましたが、画像をクロップする際に重なりがあります。論文にはこの重なりがあることにより情報の見切れを防ぐことが出来るため、精度が向上すると書かれてあります。しかし、重なり部分をそのままLLMに渡してしまうと、一つしかないオブジェクトが2つカウントされてしまったり、情報を2重で渡してしまうことになります。
そこで入力画像をクロップした際に発生した重複部分をLLMにパスしないようにする仕組みが以下のコード箇所になります。
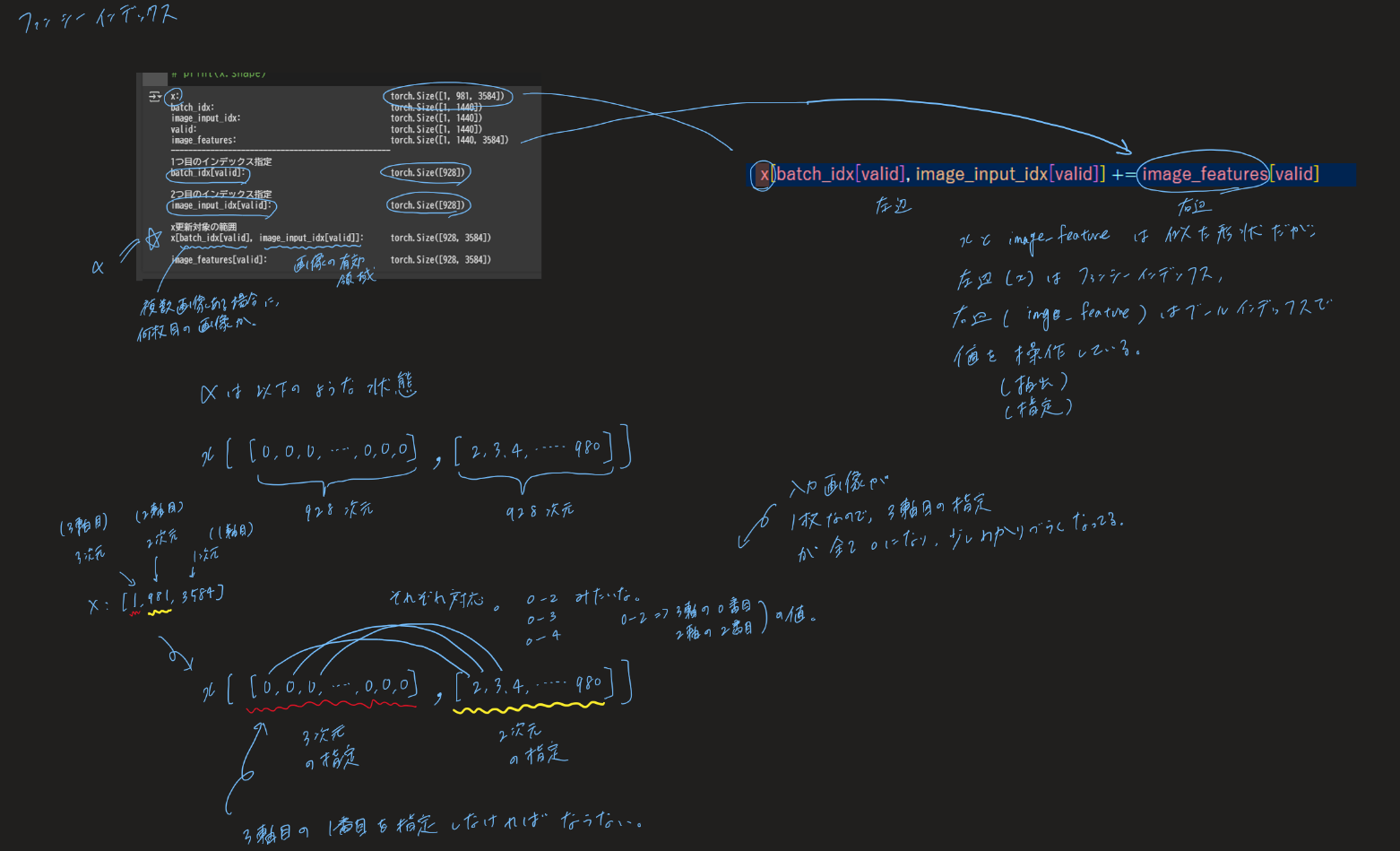
x[batch_idx[valid], image_input_idx[valid]] += image_features[valid]
この処理ではファンシーインデックスが活用されているため、コードが直感的に分かりづらくなっています。
もう少し周辺のコードから見てみます。
if images is not None:
# shape: (batch_size, num_image, num_patch, d_model)
# cls_embed: (batch_size, num_image, d_model)
image_features, cls_embed = self.vision_backbone(images, image_masks)
num_image, num_patch = image_features.shape[1:3]
assert image_input_idx.shape == (batch_size, num_image, num_patch)
# [A]
# inster the image feature into the embedding.
image_features = image_features.view(batch_size, num_image * num_patch, -1)
image_input_idx = image_input_idx.view(batch_size, num_image * num_patch)
valid = image_input_idx >= 0
batch_idx = torch.arange(batch_size, device=x.device)
batch_idx = torch.tile(batch_idx[:, None], [1, image_features.shape[1]])
# For hf demo/endpoint
image_features = image_features.to(x.device)
# [B]
x[batch_idx[valid], image_input_idx[valid]] += image_features[valid]
# [A] とコメントアウトした箇所から該当の処理が始まり、# [B] において、重複部分の無効化が実行されています。# [B] 時点での各データの形状は以下のとおりです。
x: torch.Size([1, 981, 3584])
batch_idx: torch.Size([1, 1440])
image_input_idx: torch.Size([1, 1440])
valid: torch.Size([1, 1440])
image_features: torch.Size([1, 1440, 3584])
-----------------------------------------------------------------------------------
# 1つ目のインデックス指定([B] の左辺)
batch_idx[valid]: torch.Size([928])
# 2つ目のインデックス指定([B] の左辺)
image_input_idx[valid]: torch.Size([928])
# [B] の左辺
x[batch_idx[valid], image_input_idx[valid]]: torch.Size([928, 3584])
# [B] の右辺
image_features[valid]: torch.Size([928, 3584])
一部、データの中身も覗いてみます。
-
batch_idx
ファンシーインデックスで更新対象を対応させるためのただのインデックス番号。インデックス番号を入れるだけのマスク行列です(ここでは"隠す"という意味でのマスクではありません)。
今回の例の場合、バッチサイズは 1 なので全て 0 のマスクになります。

-
image_input_idx
見やすさのため、[10, 12, 12]に reshape しています。
パッチ特徴量について、169の次の170は次のクロップ画像(画像内 Group2)の左上の要素。
ここまでデータの内容を把握したうえで改めて元のコードを参照します。
x[batch_idx[valid], image_input_idx[valid]] += image_features[valid]
-
左辺
LLM への入力シーケンスxの次元[1, 981, 3584]は左から、バッチ、シーケンス、特徴量を表します。
「バッチ(batch_idx[valid])」、「シーケンス(image_input_idx[valid])」それぞれの次元に対し、インデックス番号を抽出したものを指定し、適切なxのパッチ格納場所を有効化します。 -
右辺
image_input_idxで作った有効領域のマスク(valid)を用いて、画像特徴量の非重複部分だけを抽出します。
左辺が分かりづらいですが、一つずつ紐解いてゆけば解るかと思います。両辺を同じ形にしてから代入してやりたいという意図です。ここまでの説明でも難しい場合は、一度ファンシーインデックスの簡単な例を調べて、自分で実行してみるのがおすすめです。ファンシーインデックスは自分で触らないと分かりづらいところではあります。
[ 自分用のメモ ]
自分用に取ったメモですが、せっかくなので誰かの理解の一助になればと思い、メモも載せておきます。情報を整理するために自分用として書いたメモなのでわかりやすくまとまってはいませんが、図で表されている分、直感的ではあると思います。
Decoder-only Transformer (LLM)
1回の Molmo.forward() イテレーションにおける処理
今更ですが、前提のお話として、テキスト生成における単語の生成は一語づつ行われます。一語ずつ単語の分布が生成されて出力をフィードバックしながらループすることで、文章を生成しているのです。Molmo.forward() はあくまで一回の順伝搬であり、実行一回につき生成される単語は一語です。外側の generate() が Molmo.forward()をループ実行させて、EOS がでると生成処理は終了します。
ここで一つ疑問が湧きます。Molmo.forward() ループ時に、フィードバックした同じデータに対し、画像特徴量を算出する処理(データの特徴量埋め込みの処理)を何度もやるのでしょうか?当然、そのようなことはせずにキャッシュを保存して一度計算した特徴量は次回からは再利用しています。次の一語の生成に必須な計算のみを繰り返して文章が生成されていくのです。
LLM Decoder への入力前処理
Decoder への入力前処理として、入力シーケンスデータ( x )の前処理およびアテンションマスクの作成があります。一連の主な処理内容は以下です。
- 位置埋め込みの付与
- ドロップアウト
- スケーリング
-
attention_maskの float 変換&負バイアス化 -
attention_bias(因果マスク・追加バイアス)の初期化・トリミング - mask と bias の合成&数値安定化
if not self.config.rope:
# Get positional embeddings.
# shape: (1, seq_len)
pos = torch.arange(past_length, past_length + seq_len, dtype=torch.long, device=x.device).unsqueeze(0)
# shape: (1, seq_len, d_model)
pos_emb = self.transformer.wpe(pos) # type: ignore
x = pos_emb + x
# Add input + positional embeddings and apply dropout.
# shape: (batch_size, seq_len, d_model)
x = self.transformer.emb_drop(x) # type: ignore
# …
# 途中省略
# …
# Add in the masking bias.
if attention_mask is not None:
attention_bias = attention_bias + attention_mask
# Might get -infs after adding attention mask, since dtype.min + dtype.min = -inf.
# `F.scaled_dot_product_attention()` doesn't handle -inf like you'd expect, instead
# it can produce NaNs.
ensure_finite_(attention_bias, check_neg_inf=True, check_pos_inf=False)
単調な処理が続くので基本的に各項の説明は省略しますが attention_bias に関してだけ少し触れておきます。こちらは attention_mask とその存在がややこしいというか紛らわしいです。
attention_bias とは、セルフアテンションのスコアに加算されるバイアス項です。アテンションスコアに情報を付与する枠組みであり、attention_mask から attention_bias が導出されています。attention_mask はモデルに与える「マスクの意図」を表す入力であり、attention_bias は実際にスコア計算に加えられる数値バイアスです。多くの実装ではこの二者は表裏一体であり、attention_mask と attention_bias は一対のものとして扱われています。この二つは、役割は同じで表現が異なるだけです。
-
attention_mask: ユーザ/高レベルが指定するマスク -
attention_bias: 内部計算で用いるマスクの実体
ALiBi という手法に関するこちらの Wikiの一節に、attention_bias のしっくりとくる良い説明がありましたので、紹介のため載せておきます。ALiBi は今回の推論で用いられている手法ではありませんが、attention_bias の類のものです。
ALiBi (Attention with Linear Biases) is not a replacement for the positional encoder on the original transformer. Instead, it is an additional positional encoder that is directly plugged into the attention mechanism.
ALiBi(線形バイアス付きアテンション)は、元のトランスフォーマーの位置エンコーダを置き換えるものではありません。これは、アテンション機構に直接接続される追加の位置エンコーダです。
The idea being that the linear bias matrix is a softened mask.
線形バイアス行列は、緩和されたマスクであるという考え方です。
LLM Decoder での計算
いよいよ主要な処理としては最後になるLLM Decoderでの処理に入ります。
該当のコード箇所はこちらです。
LLMの実体
まずはLLMの実体を確認します。下記、全体図の抜粋を参照してください。
LLMの実体は blocks というインスタンス属性に格納されているオブジェクトです。ModuleList はレイヤーを格納しているだけのクラスなので、LLM のメインのコンポーネントと言えるのは MolmoSequentialBlock ということになるでしょう。
- MolmoForCausalLM
└── model: -Molmo
├── transformer: -ModuleDict
│ ├── wte: -Embedding()
│ ├── emb_drop: -Dropout(p=0, inplace=False)
│ ├── ln_f: -RMSLayerNorm()
│ ├── blocks: -ModuleList
│ │ └── 0-27: 28 x -MolmoSequentialBlock # <--------- x 28
│ │ ├── dropout: -Dropout(p=0, inplace=False)
│ │ ├── act: -SwiGLU()
│ │ ├── attn_out: -Linear4bit(in_features=3584, out_features=3584, bias=False)
│ │ ├── ff_out: -Linear4bit(in_features=18944, out_features=3584, bias=False)
│ │ ├── rotary_emb: -RotaryEmbedding()
│ │ ├── attn_norm: -RMSLayerNorm()
│ │ ├── ff_norm: -RMSLayerNorm()
│ │ ├── att_proj: -Linear4bit(in_features=3584, out_features=4608, bias=True)
│ │ └── ff_proj: -Linear4bit(in_features=3584, out_features=37888, bias=False)
│ └── ff_out: -Linear(in_features=3584, out_features=152064, bias=False)
具体的な実装をざっと確認します。
モデルのコード内には MolmoBlock() というクラスが存在しますが、こちらもLLMの本体の一部です。MolmoSequentialBlock() は このMolmoBlock() を継承しているため、実質、この2つのクラスがLLMの実体と言えるでしょう。
# 実装メソッドと継承関係(主要なメソッドのみ抜粋)
class MolmoBlock(nn.Module):
def _scaled_dot_product_attention
def attention
def forward
class MolmoSequentialBlock(MolmoBlock):
def forward()
-Molmo.forward()
└── -MolmoSequentialBlock.forward × (28)
└── -Molmoblock.attention
└── -Molmoblock.scaled_dot_product_attention
Molmo() クラスにおいては、下記のようにして LLM の本体(28ブロック分のMolmoSequentialBlock())がインスタンス属性へセットされます。
blocks = [MolmoBlock.build(i, config, self.__cache) for i in range(config.n_layers)]
if self.config.block_group_size > 1:
raise NotImplementedError()
else:
self.transformer.update({"blocks": nn.ModuleList(blocks)})
LLM(大規模言語モデル)での計算
LLM の計算に入ります。論文の説明通り、本稿で取り扱うモデル(Molmo-7B-D)におけるLLMデコーダは、Qwen2をベースとしており、新たに追加で学習を行ったものです。Qwen2はGPT系のモデルであり、Transformerアーキテクチャに基づいています。細かなテクニックを除けば、基本的な仕組みはTransformerと同様であるため、Transformerの基本的な構造を理解していれば、全体の処理の流れを把握することは難しくないでしょう。
こちらがLLM Decoderを実行するコードです。
# Apply blocks one-by-one.
if self.config.block_group_size == 1:
#--【A】--
for block_idx, block in enumerate(self.transformer.blocks):
if output_hidden_states:
# add hidden states
all_hidden_states.append(x)
layer_past = None if past_key_values is None else past_key_values[block_idx]
#--【B】--
# x = [1, 981, 3584] ⇐ Molmo.forward() 一周目のみ
# x = [1, 1, 3584] ⇐ Molmo.forward() 二周目以降
x, cache = block(x, attention_bias=attention_bias, position_ids=position_ids, drop_mask=response_mask, layer_past=layer_past, use_cache=use_cache)
if attn_key_values is not None:
assert cache is not None
attn_key_values.append(cache)
【 A 部 : トランスフォーマーブロックのイテレーション】
self.transformer.blocks(28 層の MolmoSequentialBlock)を enumerate で回し、先頭から順に処理を進めます。各イテレーションで変数 x には直前の層までで得られた最新の系列表現が格納されており、この x を新たに取り出したブロックに渡すことで、時系列的に情報が伝播していきます。
【 B 部 : 各ブロックへの入力と適用処理】
まず過去ステップの key / value を保持している past_key_values が渡されていれば、その層に対応する要素を引き出し layer_past として用意します。続いて block() を呼び出し、画像特徴量とテキスト特徴量が格納された現在の入力系列 x に対して Attention 処理を行います。
【 出力 】
各ブロック呼び出しから返却されるのは二つの値です。一つ目の x はそのブロックを通過した後の系列表現で、次の層への入力となる「最新の文脈埋め込み」を指します。特にシーケンスの最後尾は次トークンの分布情報を含むため、最終出力時には最新の x を末尾だけ切り出して次の語生成に繋げることが可能です。
二つ目の cache は、Attention 計算で用いた key・value 行列をまとめたタプルで、デコーダの逐次生成時に「履歴として蓄積されたメモリ(コンテキスト情報)」として再利用されます。最終的に28回の反復処理を終えた段階で、この x が最終的なデコーダ出力として、またすべての cache が attn_key_values に集約されて戻されます。
基本的な LLM Decoder モデルなのであまり特筆すべきところはありませんが、より詳しく上記 block の実装の中身( MolmoSequentialBlock() )を見てみます。
1. Attention 用入力の正規化と準備
(処理の意図) 残差前に正規化をかけるかどうかを分岐し、Attention 射影の準備を行う
• config.norm_after=False の場合 ▶︎ atten_in = self.attn_norm(x)
• config.norm_after=True の場合 ▶︎ atten_in = x
• atten_in を self.attn_proj に渡すために保持
----------------------------------------
2. Q/K/V の一括射影と分割
(処理の意図) 1回の線形変換で Query, Key, Value を得る
• qkv = self.att_proj(atten_in)
• config.clip_qkv が指定されていれば qkv.clamp_(min=-clip, max=clip)
• q, k, v = qkv.split(self.fused_dims, dim=-1)
----------------------------------------
3. マルチヘッドセルフアテンションの計算
(処理の意図) 各ヘッドごとに scaled dot product attention を計算し、元の次元に戻す
• att, cache = self.attention(q, k, v, attention_bias, position_ids, drop_mask, layer_past, use_cache)
--- 'self.attention' の内部処理 ---------------
a) Q/KV の形状変換
- B, T, C = q.size()
- q → view→transpose → (B, nh, T, hs)
- k, v → view→transpose → (B, n_kv_h, T, hs)
b) 相対位置埋め込み(RoPE)
- if use_position_ids and rope: q, k = self.rotary_emb(q, k, position_ids)
c) 過去キー・値の連結
- if layer_past:
k = cat(past_key, k, dim=-2)
v = cat(past_value, v, dim=-2)
- present = (k, v) if use_cache else None
d) 注意バイアスの整形
- slice attention_bias[:, :, key_len-query_len:key_len, :key_len]
- attention_bias = _cast_attn_bias(sliced_bias, dtype)
e) _scaled_dot_product_attention の呼び出し
--- '_scaled_dot_product_attention' の内部処理 ---------------
i) マスクをデバイスへ転送
- if attn_mask is not None: attn_mask = attn_mask.to(q.device)
ii) FlashAttention が利用可能か判定
- if flash_attn_func and attn_mask is None:
r = flash_attn_func(q.T, k.T, v.T, dropout_p, causal=is_causal)
return r.T
iii) GQA(Grouped Query Attention)対応
- num_q_heads ≠ num_kv_heads の場合 k, v を repeat_interleave
iv) PyTorch 標準 SDPA 呼び出し
output = F.scaled_dot_product_attention(q, k, v, attn_mask, dropout_p, is_causal)
return output
-------------------------------------------------------------
f) ヘッド再結合と射影
- att: (B, nh, T, hs) → transpose→contiguous→view → (B, T, C)
- out = self.attn_out(att)
- return out, present
-------------------------------------------------------------
----------------------------------------
4. Attention 後の正規化と残差結合
(処理の意図) Post-LN モードなら正規化をかけ、残差+ドロップアウトを適用
• if config.norm_after: att = self.attn_norm(att)
• x = x + self.dropout(att, drop_mask)
• og_x = x ※FFN 用残差として保持
----------------------------------------
5. フィードフォワードネットワーク(FFN)の適用
(処理の意図) 位置ごとの非線形変換で表現力を補強
• if not config.norm_after: x = self.ff_norm(x)
• x = self.ff_proj(x) ▶︎ 線形変換 (d_model→hidden)
• x = self.act(x) ▶︎ SwiGLU 等の活性化
• x = self.ff_out(x) ▶︎ 出力射影 (hidden×multiplier→d_model)
• if config.norm_after: x = self.ff_norm(x)
• x = self.dropout(x, drop_mask)
• x = og_x + x ▶︎ 残差結合
----------------------------------------
6. 最終出力とキャッシュの返却
(処理の意図) ブロックの出力テンソルと次ステップ用キャッシュを呼び出し元に返す
• return x, cache
【 2 : Q/K/V の分割】
2周目以降は最新の生成トークン1語のみの処理になります。Attention 計算に必要な以前までの情報には後述の Attention キャッシュを利用します。
これらの Attention キャッシュが何かわからないという方向けに、KVキャッシュを説明する記事をいくつか載せましたので、参照してみてください。記事を読んでもよくわからない場合は、とりあえず読み進めてみてください。続きにも詳しく書いております。
# (q), k, v = [1, 981, (3584) 512] ⇐ Molmo.forward() 一周目のみ
# (q), k, v = [1, 1, (3584) 512] ⇐ Molmo.forward() 二周目以降
q, k, v = qkv.split(self.fused_dims, dim=-1)
# Get attention scores.
if self._activation_checkpoint_fn is not None:
att, cache = self._activation_checkpoint_fn( # type: ignore
self.attention, q, k, v, attention_bias, position_ids=position_ids, layer_past=layer_past, use_cache=use_cache
)
else:
# att = [1, 981, 3584] ⇐ Molmo.forward() 一周目のみ
# att = [1, 1, 3584] ⇐ Molmo.forward() 二周目以降
att, cache = self.attention(q, k, v, attention_bias, position_ids=position_ids, layer_past=layer_past, use_cache=use_cache)
【 3-c : Attention キャッシュの保存と再利用】
LLM の逐次生成では、Attention 計算の過去の key・ value を「コンテキスト」(または「メモリ」、「履歴」)として持ち続けることで、一度計算した注意重みを再利用しながら効率良く長い依存関係を扱えます。
各 MolmoSequentialBlock の呼び出し時には、Attention 計算で用いたキー・バリュー行列を
present = (k, v) if use_cache else None
としてまとめ、cache として返却します。そして、28層の block( MolmoSequentialBlock ) ループの中で attn_key_values.append(cache) によって蓄積します。こうして得られた attn_key_values は、Molmo.forward() の戻り値として past_key_values という名前で受け取られます。そして、次ステップにおける Molmo.forward() の LLM デコーディング時にフィードバックされ、再び layer_past=past_key_values[i] として block 各層に渡されます。
このようにキャッシュを保持し、フィードバックすることでコンテキストが捉えられます
よりイメージを鮮明にするために、past_key_values の具体的なデータ形状も確認しておきます。past_key_values は実際に Molmo.forward() の引数を保存して調べたので簡易的な例ではなく実際の情報になります(調べるのに結構時間がかかりました)。
ちなみに、私はpast_key_valuesを最初に見たとき、past の key の value(過去のkeyの値)と思っていたのですが、正しい理解はPast key and value(過去の key と value)です。
構造およびテンソル形状
past_key_values は長さ (28, 2) のリストで、各要素は (k, v) のタプルです。リストインデックス 0~27 がそれぞれ MolmoSequentialBlock の 28 層に対応します。各 k または v は (1, 4, seq_len, 128) の形状を持ち、推論を重ねるごとに seq_len(過去トークン数)が増加します(例: 981 → 1081 …)。ここで 4 は Attention のキー/バリューヘッド数(effective_n_kv_heads)です。past_key_values の形状をまとめて書くとするならば、 [28, 2, 1, 4, seq_len, 128] のような形状をしています。
※ 誤解を避けるために補足すると、先に示した
[28, 2, 1, 4, seq_len, 128]のような「リストと torch.Tensor の混在表記」は便宜的な説明であり、実際にはリスト内の各要素が純粋なテンソルオブジェクトで管理されています。
【 3-e-iv : Scaled Dot-Product Attention の実装】
LLM Decoderにおける計算のコアである Attention の計算です。下記コードより Attention の計算にエントリーし結果を得ます。
# Get attention scores.
if self._activation_checkpoint_fn is not None:
att, cache = self._activation_checkpoint_fn( # type: ignore
self.attention, q, k, v, attention_bias, position_ids=position_ids, layer_past=layer_past, use_cache=use_cache
)
else:
# att = [1, 981, 3584] ⇐ Molmo.forward() 一周目のみ
# att = [1, 1, 3584] ⇐ Molmo.forward() 二周目以降
att, cache = self.attention(q, k, v, attention_bias, position_ids=position_ids, layer_past=layer_past, use_cache=use_cache)
Attention の計算は、PyTorch 標準の scaled_dot_product_attention() 関数をそのまま呼び出して実装されています。該当箇所は F._scaled_dot_product_attention()という1行で、クエリ(q)とキー(k)の内積をスケーリングし、ソフトマックスを経てバリュー(v)に適用する処理を内部で一括して行います。
キャッシュによる次元の変化としては、二周目以降は query( および attention_mask )の長さが 1 となるので生成される att ( attention )の長さも 1 になるという仕組みです。
from torch.nn import functional as F
# …
# 省略
# …
def _scaled_dot_product_attention(
self,
# …
# 省略
# …
# ⇓ Molmo.forward() 一周目のみ
# q, k, v = [1, 28, 981, 128]
# attn_mask = [1, 1, 981, 981]
return F.scaled_dot_product_attention(
# ⇓ Molmo.forward() 二周目以降
q, # [1, 28, 1, 128]
k, # [1, 28, seq_len, 128]
v, # [1, 28, seq_len, 128]
attn_mask=attn_mask, # [1, 1, 1, seq_len]
dropout_p=dropout_p,
is_causal=is_causal,
)
LLM計算後の後処理
最後の処理として、LLM デコーダーから得られた隠れ状態を「最終的なトークン単位のロジット(次の一単語の分布)」に変換する 後処理 があります。
#--【A】--
if images is not None and self.config.use_cls_feature:
assert num_image is not None
x = torch.cat(
[x[:, :1], x[:, num_image+1:], torch.zeros_like(x[:, :num_image])],
dim=1,
)
#--【B】--
if last_logits_only:
# shape: (batch_size, 1, d_model)
if append_last_valid_logits is not None:
last_valid_output = x[
torch.arange(x.shape[0], device=x.device), append_last_valid_logits.to(x.device)]
x = last_valid_output.unsqueeze(1)
else:
x = x[:, -1, :].unsqueeze(1)
#--【C】--
# Apply final layer norm.
# shape: (batch_size, seq_len or 1, d_model)
x = self.transformer.ln_f(x) # type: ignore
if output_hidden_states:
# add final hidden state post-final-layernorm, following HuggingFace's convention
all_hidden_states.append(x)
#--【D】--
# Get logits.
# shape: (batch_size, seq_len or 1, vocab_size)
if self.config.weight_tying:
logits = F.linear(x, self.transformer.wte.weight, None) # type: ignore
else:
logits = self.transformer.ff_out(x) # type: ignore
if self.config.scale_logits:
logits.mul_(1 / math.sqrt(self.config.d_model))
#--【E】--
if not last_logits_only and append_last_valid_logits is not None:
last_valid_logit = logits[
torch.arange(logits.shape[0], device=logits.device), append_last_valid_logits]
logits = torch.cat([logits[:, :-1], last_valid_logit[:, None]], dim=1)
return ModelOutput(logits=logits, attn_key_values=attn_key_values, hidden_states=tuple(all_hidden_states) if output_hidden_states else None) # type: ignore[arg-type]
[ A. 画像特徴量処理(CLS特徴利用時)]
画像が入力され、かつ CLS トークンを利用する設定が有効な場合、モデルはまず入力系列の先頭にある CLS 埋め込みを保持し、その直後に続く画像パッチの埋め込みをすべて取り除いてから、同じ数だけのゼロ埋めベクトルを末尾に追加します。これにより、画像から抽出された複数のパッチ特徴量は学習や生成の過程で扱われなくなり、代わりに画像全体の要約情報を担う CLS 特徴のみが残ることで計算効率とメモリ使用量の削減を図ります。背景には、Vision Transformer の設計として最初の CLS トークンが全パッチ情報を集約する役割を果たすという考え方があり、このモードでは個々のパッチを扱わずに CLS トークンだけで画像情報を表現するという意図があります。
[ B. 最後のロジット抽出処理]
自動回帰生成の高速化を目的として、モデルは系列全体の特徴を計算した後に、出力すべき最後のトークンに対応するベクトルのみを抜き出します。具体的には、バッチごとに指定された有効位置があればそこから特徴を抜き出し、なければ系列の末尾要素を取り出して次元を調整します。こうすることで、生成に必要な情報だけを手早く取得し、不要な全系列データの保持を避けることでメモリ使用量を節約しつつ推論速度を向上させる設計になっています。
[ C. 最終層正規化]
最後の Transformer ブロックを通り抜けた後、出力ベクトルには標準的な LayerNorm が適用されます。この正規化は、各次元の値を均一化して数値的な安定性を確保し、勾配の伝搬を安定化させる役割を果たします。GPT 系モデルではポストノルム構成が一般的であり、このステップによって学習時や推論時の振る舞いがより安定するよう意図されています。
[ D. ロジット計算]
正規化済みの特徴ベクトルから最終的な出力ロジットを計算する際、モデル設定に応じて埋め込み層の重みをそのまま再利用するか、あるいは専用の線形層を用いるかが切り替えられます。埋め込み層と出力層の重みを共有する「Weight Tying」を有効にすればパラメータ数を削減しつつ性能を維持できる一方で、専用出力層を使うとより柔軟な変換が可能になります。このトレードオフを反映して、両者を切り替えられるようになっています。
[ E. 最終ロジット調整]
バッチ処理では、バッチ内の異なるサンプルがそれぞれ異なる有効長を持つ場合、「本当の最後のトークン」の位置は各サンプルで異なります。このコードは、各サンプルの実際に有効な最後の位置のlogitsを、出力の最後尾に配置することで、次のトークン予測や損失計算を正確に行うためのものです。