※こちらはPythonデータ分析勉強会#1の発表資料です。
新潟県工業技術総合研究所で、YOLOを使った面白い報告がありました。
工業技術研究報告書 平成29年度
http://www.iri.pref.niigata.jp/pdf/houkoku/h29houkoku.pdf
リンク先の最終ページ付近に、YOLOを使ったパトライトの監視があります。
本稿では、この報告を見習い、keras-yolo3を使ってパトライトを監視させようと思います。
※結論からいうと、まだまだ完成度は低いです。完成度を上げるためには
工場内で撮ったリアルな画像を集めてこないといけないです。
モデルの選定
最終的にラズベリーパイで動かすことを念頭におきます。
従って、重いフルモデルではなく、軽いtinyモデルを使います。
tinyモデルは精度は落ちますが、早いことが特徴です。
公式ページによると1秒間に200コマ以上処理する、とてつもなく早いモデルです。
こちらを見ても、CPUでサクサク動くようです。
クイックスタート
Anaconda3やTensorFlow、Kerasのインストールは省略します。
※Colaboratoryであれば、これらのインストールは不要です。
以下からkeras版yolo3を入手します。
Windowsの場合は「Download ZIP」をクリックしてダウンロードします。
解凍すると、keras-yolo3フォルダができます。
学習済みのモデルを入手します。今回は、tinyモデルですので、こちらからダウンロードします。
ダウンロードしたファイルをkeras-yolo3フォルダの直下に入れます。
次に、入手した学習モデルをKeras用に変換します。以下のコマンドを入力します。
python convert.py yolov3-tiny.cfg yolov3-tiny.weights model_data/tiny_yolo_weights.h5
Colaboratoryで作業する場合は、以下のとおりコマンドします。
%run convert.py yolov3-tiny.cfg yolov3-tiny.weights model_data/tiny_yolo_weights.h5
これで、Keras用の学習済みモデルが「model_data」フォルダに入ります(tiny_yolo_weights.h5)。
yolo.pyをコピーし、「tiny_yolo.py」に名前を変えます。
そして、その中身の23、24行目を以下のように書き換えます。
"model_path": 'model_data/tiny_yolo_weights.h5', #'model_data/yolo.h5'
"anchors_path": 'model_data/tiny_yolo_anchors.txt', #,yolo_anchors.txt',
また、yolo_video.pyをコピーし、「tiny_yolo_video.py」に名前を変えます。
そして、その中身の3行目を以下のように書き換えます。
from tiny_yolo import YOLO, detect_video
とりあえず、これで静止画と動画の物体検出ができます。
静止画は、実行したい写真をkeras-yolo3直下に入れ、以下のコマンドで物体検出させることが可能です。
python tiny_yolo_video.py ---image
Colaboratoryの場合は、以下のとおりコマンドします。
%run tiny_yolo_video.py ---image
ファイル名を聞かれるので、写真名を入力してください。
判定画像を保存したい場合は、tiny_yolo_video.pyの16、17行目を以下のように書き換えます。
r_image = yolo.detect_image(image)
import cv2
cv2.imwrite("out.jpg", np.asarray(r_image)[..., ::-1])
r_image.show()
動画を判定させたい場合は、以下のように、入力動画名と出力ファイル名をコマンドします。
python tiny_yolo_video.py ---input 〇〇〇 ---output △△△
例えば、
python tiny_yolo_video.py ---input test.mp4 ---output test_out.mp4
となります。こちらは、Colaboratoryだとエラーが出たので、自分のPCで実行しました。
パトライト画像の準備
ネットでパトライトの画像を集めます。
Data Augmentation
今回は、画像数が少なかったので、Data Augmentation(データ水増し)を行いました。
十分なデータ数があれば、ここの処理は必要ありません。
こちらを参考にkerasでコードを作りました。
import matplotlib.pyplot as plt
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
import cv2
import numpy as np
img_path = 'picture/01.jpg'
# 画像ファイルをPIL形式でオープン
img = image.load_img(img_path)
# PIL形式をnumpyのndarray形式に変換
x = image.img_to_array(img)
# (height, width, 3) -> (1, height, width, 3)
x = x.reshape((1,) + x.shape)
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0,
height_shift_range=0,
shear_range=0,
zoom_range=[0.5,2],
horizontal_flip=True,
vertical_flip=False)
max_img_num = 10
NO = 1
for d in datagen.flow(x, batch_size=1):
# このあと画像を表示するためにndarrayをPIL形式に変換して保存する
cv2.imwrite("Aug_%2d.jpg"%(NO), np.asarray(d[0])[..., ::-1])
# datagen.flowは無限ループするため必要な枚数取得できたらループを抜ける
if (NO % max_img_num) == 0:
print("finish")
break
NO += 1
最終的に、学習データを100個(画像データ10個+水増しデータ90個)ほど用意しました。
アノテーションデータの作成
事前に、以下のようにフォルダを作っておきます。
keras-yolo3
┗ VOCdevkit
┗ VOC2007
┣ Annotations
┣ ImageSets - Main
┗ JPEGImages
アノテーションデータの作成は、こちらのAnnotationTool.exeを使わせていただきました。
使い方は、リンク先の「独自データでの準備」の題目を参考にしてください。
ツールを実行すると、画像ファイル分の「~.xml」ファイルと、「trainval.txt」ができます。
これらを以下のように、「VOCdevkit/VOC2007」内のフォルダにコピーします。
- 「Annotations」フォルダには作成されたxmlファイルを全部入れます。
- 「ImageSets/Main」に「trainval.txt」を入れます。
- 「JPEGImages」フォルダに、パトライトの画像ファイルをすべて入れます。
学習実行
学習の前に、ファイルの準備が必要です。
「VOCdevkit/VOC2007/ImageSets/Main」にある「trainval.txt」をコピーして、「train.txt」、「val.txt」、「test.txt」という3つのファイルを作ります。
さらに、「model_data」フォルダにある「voc_classes.txt」のラベル名を書き換えます。
この中にはaeroplaneなど複数のラベル名がありますが、全て消し、今回用のラベルに書き換えます。
「voc_annotation.py」の6行目も同様に書き換えます。
ここで、以下のコマンドを実行します。
python voc_annotation.py
すると、keras-yolo3直下に「2007_val.txt」、「2007_train.txt」、「2007_test.txt」が生成されます。このうち「2007_train.txt」のみを「train.txt」というファイル名を変更しておきます。
Colaboratoryで学習させる場合は、「train.txt」の各行のアドレスを以下のように編集します。
VOCdevkit/VOC2007/JPEGImages/****
ここでは、置換機能で書き換えました。そして、keras-yolo3のフォルダをグーグルドライブに上げます。
次に、keras-yolo3直下のtrain.pyをコピーし、「tiny_train.py」に名前を変えます。
そして、19、20行目を以下のように書き換えます。
classes_path = 'model_data/voc_classes.txt'
anchors_path = 'model_data/tiny_yolo_anchors.txt'#yolo_anchors.txt'
最後に、以下のコマンドで学習を実行します。
python tiny_train.py
自前のGPUで学習させようとすると、非力過ぎてメモリーエラーが出てしまったので、学習はColaboratoryで実行しました。
%run tiny_train.py
デフォルトの学習は、以下のように設定されています。
- trainデータとvalデータは、自動的に割り振られます。
- 1~50エポックでは、事前学習された重みを使って学習します。
学習可能な層は、最後の2層だけのようです。 - 50~100エポックでは、全ての層で学習可能となっています。learning rateも徐々に下げる設定になっており、前半のエポックに比べlossは1桁下がります。最終的に、valのlossは8くらいになりました。
物体検出実行
学習が完了したら、「logs/000」フォルダ内にあるval_lossが一番低い.h5ファイルをmodel_dataフォルダに入れます。
次にtiny_yolo.pyファイルの中身をいじります。
まずは、22行目を先ほどの.h5ファイルの名前で書き換えます。
"model_path": 'model_data/***.h5',#'model_data/yolo.h5'
そして、24行目も以下のように書き換えます。
"classes_path": 'model_data/voc_classes.txt',#'model_data/coco_classes.txt',
さらに、バグかどうか分かりませんが、一部の画像は取り込む際に
色が反転したりして、色情報が正しくないことがありました。
その理由は、基本的に、JPGで学習させているため、カラーモードをRGBに
統一してあげる必要があるためです。
そこで103、104行目を以下のように書き換えます。
start = timer()
image = image.convert('RGB')
さらに、動画はOpenCV2を使って取り込んでいますが、デフォルトは「BGR」になっています。
従って、「RGB」に変えてあげる必要があり、191~196行目を以下のように書き換えます。
return_value, frame = vid.read()
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image = Image.fromarray(frame)
image = yolo.detect_image(image)
result = np.asarray(image)
result = cv2.cvtColor(result, cv2.COLOR_RGB2BGR)
あとは、クイックスタートと同じです。
画像で物体検出する場合、ローカルPCであれば
python tiny_yolo_video.py ---image
ですし、Colaboratoryの場合は
%run tiny_yolo_video.py ---image
となります。
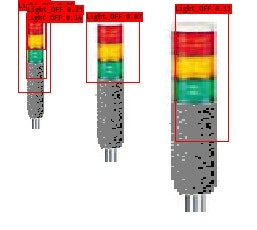
結果
まずは、静止画です。
検知する窓(Bounding Box)が重なっていますが、検知できています。
画面サイズは225×225です。処理時間はCPU使用で0.12秒です。
次に動画です。

静止画より画面サイズが大きいため、若干処理が遅くなります。
それでも、CPUで0.2秒(1秒間に5フレーム処理できる)ほどです。
課題点
学習データについて
以下の課題点は、「ネット画像で学習させるのは限界がある」という結論に至ります。
従って、工場内で撮ったリアルな画像を集めてこないといけないです。
-
誤検知(検知漏れ)している
→ 学習データをもっと集めれば、誤検知が減ると思います。 -
背景に他の物体があっても、誤検知しないのか?
→ 本来は、誤検知を防ぐために、背景に他の物体があるものも用意しないといけません。
しかし、ネットから画像を集めてくると、背景には何も写っていません。
従って、工場内のリアルな写真を撮るのが妥当といえます。 -
光の加減で誤検知するのか?
→ 新潟県の報告にもありましたが、光の加減で誤検知することがあるそうです。
従って、明暗を変えたリアルな写真を撮る、もしくはこちらにある
PCA Color Augmentationを使うと良いかもしれません。 -
今のところ、「Light_OFF」しか検知できていない
→ 本来であれば、「Light_OFF」、「赤」、「緑」、「黄色」を分類し検知させたいです。
しかし、ネットの画像に単色だけ光っているものは見当たらず、学習データが
用意できませんでした。
その他について
- 位置情報の照合をどうするのか?
→ 実際の運用を考えたとき、「画面内の位置情報」と「YOLOの出力情報」を照合・登録する
ソフトを別途用意する必要があります。