※こちらはPythonデータ分析勉強会#07の発表資料です。
オートアノテーションツールを作ってみました。
このツールを使えば、人間は画像を見ることなく、アノテーション作業ができちゃいます。

アノテーション作業とは
ここでいうアノテーション作業とは、物体検出で行われる作業のことです。
物体検出の学習データでは、物体の位置を示す必要があり、一般的にマウスで
ドラッグさせる作業が発生します。

上の動画のように、ひたすら、ただひたすら、ドラッグし続けます。
この作業、多くの問題があります。
-
手作業の時間が長い
過去にこちらの記事でアノテーション作業を行いましたが、画像400枚に対し
手作業で4時間かかっています。これが1000枚、5000枚になると何十時間も
かかってしまいます。 -
精神的ダメージが大きい
作業中の精神状態は良くありません。「このデータ量で足りるだろうか?」
「そもそも物体検出なんて無理じゃないか」などとマイナスのことを考えがちです。
作業後の疲労感が半端ないです。
そこで、本稿ではアノテーション作業を自動化する「オートアノテーションツール」を
作ってみました。(もう誰かがやっているかもしれませんが。。。)
オートアノテーションツールを使った作業の流れ
- ラベル付きの画像を集める。
- 集めた画像を分類できる畳み込みニューラルネットワーク(CNN)を用意する(学習させる)。
- オートアノテーションツールで画像にアノテーションを付ける。
- アノテーション結果が正しいかどうか画像を見ながらチェックし、的外れなアノテーションした場合は削除する。
- 最後に、アノテーションに関するデータを保存する。
使い方
全体はgithubに置きました。
前段にcifar-10で動かしてみた結果を示しています。
興味ある方は実行してみてください。15分くらいかかります。
後段はYOLOv3-keras用にアノテーションデータを出力する
コードが書かれています。
ダウンロードしていただき、Colaboratoryに持って行ってポチポチ実行して
いけば、使い方は分かると思います。一部変更すればJupyter Notebookでも
動くと思います。
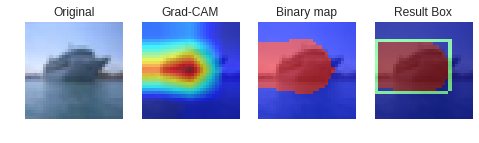
アルゴリズム
基本的にGrad-CAMをベースに作っています。
-
ステップ0
あらかじめCNNを学習させておきます。 -
ステップ1
画像を用意し、Grad-CAMでヒートマップを取得します。 -
ステップ2
取得したヒートマップを二値化します(Binary map)。 -
ステップ3
Binary mapにベイズ最適化を適用し、イイ感じにボックスを決めさせます。
ステップ0
自作でも転移学習でも良いですが、認識させたい画像をある程度正確に分類できるCNNを
用意します。ポイントはGrad-CAMで可視化したときに物体全体に反応するCNNを用意することです。
ステップ1とステップ2
Grad-CAMはCNNがどこを見て判断したのかを示すヒートマップを出してくれます。
コードは以下の記事を参考にしています。
https://qiita.com/haru1977/items/45269d790a0ad62604b3
そのヒートマップに閾値(デフォルトで0.3)を設け、二値化しています。
ステップ3
ボックスの最適な形状は、ベイズ最適化で見つけています。
ベイズ最適化は以下の記事を見れば、イメージが掴めるかと思います。
https://qiita.com/shinmura0/items/2b54ab0117727ce007fd
本当は総当たりでボックスの探索できれば良いのですが、あまりにも
時間がかかるので、ベイズ最適化で効率的に探索させています。
中ではこんな形で色々なボックスを試しています。

ベイズ最適化では、評価関数を用意しないといけません。
今回は、IOUを評価関数にしています。IOUは以下の記事を参考にしてください。
https://meideru.com/archives/3538#i-2
要は、IOUを評価関数にすることで、過不足なくBinary mapの赤い部分を囲わせることができます。
学習用画像の制約
このツールでは二種類の画像が必要です。
- あらかじめ学習させておくCNNの学習用画像
- アノテーション用の画像
どちらも同じデータの使い回しで良いのですが、画像の構図について以下の制約があります。
- 一枚の画像に物体検出させたい物が一個だけの構図
- 写真の構図をコントロールできる工業製品などに向いている
もちろん、YOLOv3などの物体検出に組み込んでしまえば、一枚の画像から複数個の物体検出が可能となります。
逆に以下の条件のものは適していません。
- 一枚の画像に物体検出させたい物が複数個含まれる構図
- 景色の写真など色々なものが写っている画像は不得意
色々なものが写っていても、「物体検出させたい物が一個だけの構図」であれば適用できます。
動作速度
このツールは画像一枚に対し、20秒ほど時間がかかります。
内訳はGrad-CAMで5秒、ベイズ最適化で15秒ほどです。
ベイズ最適化の速度は以下の max_iterの値を小さくすれば早くなりますが、精度と速度の
トレードオフの関係になっているので、お気を付けください。
myBopt.run_optimization(max_iter=10)
ツールの出力結果
このツールでは、以下のファイルが出力されます。
- xmlファイル
- jpgファイル
- trainval.txtファイル
これらはYOLOv3-keras用のファイルとなっていますが、最新のM2Det用に
改造できると思うので、興味ある方は試してみてください。
xmlファイルの取り扱いは、以下の記事を参考にさせていただきました。
https://qiita.com/icchi_h/items/44abb5a8147b1ef7475f
実験
自前の画像で実験
今回、用意した画像の内訳は以下のとおりです。
||ナットの画像|ボルトの画像|何も映っていない画像|
|---|---|---|---|---|
|数量|30|30|10|

これらを分類するCNNでは、DataAugmentationを行い7000枚近くの画像に
水増しして学習させています。
そして、せっかくアノテーションデータを用意したので、YOLOv3(tiny)で学習させてみます。
学習のさせ方はこちらの記事を参考にしてください。
アノテーション結果
最初にアノテーション結果を示します。


おおむね良好な結果ですが、ボルトのボックスが小さい傾向にあります。
YOLOv3(tiny)の物体検出結果
個人的にやってみたい実験があります。
それは、「学習データの数と検出精度」の関係を見てみるということです。
ディープラーニングなので、当然、データ数が多いほど正確な検出をしてくれる
とは思いますが、何事も実験してみたいもので、今回やってみました。
この実験は、手作業のアノテーションでは膨大な時間がかかって無理でしたが、
オートアノテーションツールを使えば比較的簡単にできます。
オートアノテーションツールでは、DataAugmentationしながらデータを増やすので、
元の画像をある程度用意できれば、良質なデータを無限に作ることができます。
早速、結果を見ていきましょう。
- データ数が100の場合

ナットは検出できましたが、ボルトは全く検出できませんでした。
ナットのバウンディングボックスも大きめな印象を受けます。
- データ数が500の場合

ナットのバウンディングボックスは絞られてきた印象です。
ボルトは検出できるようになりましたが、検出漏れがあります。
- データ数が1000の場合

データ数が500の場合とほぼ同じ結果です。
- データ数が2500の場合

精度が劇的に向上しました!
ナットのバウンディングボックスは丁度良いサイズになり、そのスコアも上がっています。
さらに、ボルトも5本中4本は検出できました。
ちなみに、val lossは以下のとおりになりました。
| データ数 | 100 | 500 | 1000 | 2500 |
|---|---|---|---|---|
| val loss | 7.847 | 7.041 | 6.608 | 6.716 |
データ数が1000と2500の間に大きな壁があると思うのですが、数値的には
大きな差は見られませんでした。
cifar-10で実験
最後にcifar-10で実験した結果を示します。
アノテーション結果



アノテーションされる箇所として、鳥は頭、車はボンネット、船は船橋になる傾向です。
まとめ
- オートアノテーションツールは全自動でアノテーション作業をしてくれる。
- ただし、学習用画像に制約があり、ある程度誤差もある。
- 主題からは逸れるが、「学習データの数と検出精度の関係」を確認する実験を行った。その結果、学習画像が多いほど正確な検出をしてくれることが分かった。