About me
こんにちは。
「Livesense Advent Calendar 2017-自-」の11日目にお邪魔させて頂きます。
リブセンスキャリア事業部で先々月からマーケティング部署に配属となった、新卒1年目のshin_aと申します。
tomoharu33と同じく、よくわからないまま、気づいたら参加してました(笑)。
マーケティング部署なのですが、上司や先輩がみんなエンジニアリングスキルを持っているという実にリブセンスらしい部署です。
大学時代、HTML/CSSくらいは少しだけ触ったことはあったものの、その他エンジニアリング知識は一切なかったため、
エンジニアリング/広告運用/SEO関連の勉強に一ヶ月時間を頂き、その後部署で実務をこなしながら、日々出て来る新出概念と格闘しています。
本投稿のテーマと対象者
さて、このアドベントカレンダーはテーマが「自由」ということで、
入社するまでホストもクライアントも聞き覚えがなく、最近まで「ブラウザって結局何?」「Gemって美味しいの?」って状態だった自分が今回選んだテーマは、「クローラー」です。
「クローラーの作成」というちょっと違った角度から、Web入門者向け記事を書いてみました。
(ホントはクローラーの技術的な部分を書ききれなかっただけ)
対象としては、
・HTML?CSS?JavaScript?Ruby?何だそれ?
から
・クローラーって、言葉くらい聞いたことはあるかも
くらいの幅を人を想定しています。
込み入った話は触れず、概要についての記事となります。
クローラーの作成については、*「佐々木拓郎/るびきち『Rubyによるクローラー開発技法 -巡回・解析機能の実装と21の運用例-』(SBクリエイティブ株式会社)」*を参考に書かせて頂いてるので、詳しくはそちらを御覧ください。
あくまで「知識ほぼゼロからクローラー作成の入り口まで雰囲気を理解する」という趣旨を念頭に置きながら、自分の理解出来ている範囲内で記述してきます。
厳密には違うところがあるかもしれませんが、ご容赦頂けると幸いです。
クローラーとは?
システムが自動的にWebページを巡回して情報を収集するプログラムのことをクローラー(Crawler=這いずり回るもの?)と言います。
代表的なクローラーはGoogleのGooglebotで、Googleはこれを使って予め世界中(Web上)のあらゆる情報を取得し、それぞれに目印をつけて置きます。
Googleの検索窓にユーザーがキーワードを打ち込んだ(ググった)際、その目印などを元に「このキーワードでググった人が欲しい情報は何か」を、Googleのアルゴリズムが自動で判断し、ユーザーに取って便利だと思う順に並び替えて、検索結果としてPCやスマホの画面に表示します。
このように、知らないだけで我々の生活の身近な部分にクローラーは存在しています。
(因みに、自社サイトを魅力的にし、Googlebotに内容と魅力をきちんと伝え、検索結果の上位に表示されるように努力する行為が「SEO(検索エンジン最適化)」と呼ばれるものです。Webサイト運営者は、自分のサイトをより多くの人に見てもらいたいのでこうした努力を行います。)
**「世の中の情報を一箇所に見やすく集めたい」「膨大な情報を収集して分析したい」**といった際などに、クローラーはその威力を発揮するのでしょう。
(アプリストアなどでの順位情報の収集・新刊情報の収集・企業や株価情報の収集等)
言語について
このままクローラーについてもう少し詳しく話していきたいのですが、その前に事前知識として言語についてかなりざっくりと記述します。
プログラミングにおいては、色んな言語が存在していて、言語ごとに、得意不得意なこと・出来る出来ないことがあります。
今Qiitaの画面を見ていると思いますが、こうした目に見える部分の構築を守備範囲とする言語を総評してフロントエンド、記事の取得など、裏側の目に見えないところで動いている言語をサーバーサイドの言語と呼びます。(とてつもなくざっくりですが)
本記事で出てくる言語を分類すると、
・フロントサイド…HTML/CSS/JavaScript
・サーバーサイド…Ruby
となります。
より詳しい分類等は、例えばこの方の記事とか読むと良いかもしれません。
フロントサイドの言語に関して、もう少しそれぞれについて補足すると
・HTML…ページの構造を形成する
・CSS…文字や配置など、色や形などを形成する
・JavaScript…ページ上の動きを形成したり
のように、役割が異なっています。
(但し、特にJavaScriptは、近年出来ることがかなり広がっているようです)
例えば、今開いている画面上部の「ホーム」という部分について、「ホーム」という文字列を定めているのはHTMLで、色(白色)や背景色(緑)などを定めているのはCSSだったりします。
ページが画面に表示されるまでの流れは、省略している箇所は多々ありますがざっくり下の感じです。
①ブラウザ(GoogleChromeとかSafariとか)を立ち上げ、欲しい情報のあるURLにアクセスする(リクエストを送る)
②諸々サーバー側で処理が行われて、リクエストに対応した情報が返って来る(レスポンスを受け取る)
③受け取った情報をブラウザが処理し、人が見てわかる状態に処理する(レンダリング)
④実際に画面に表示される
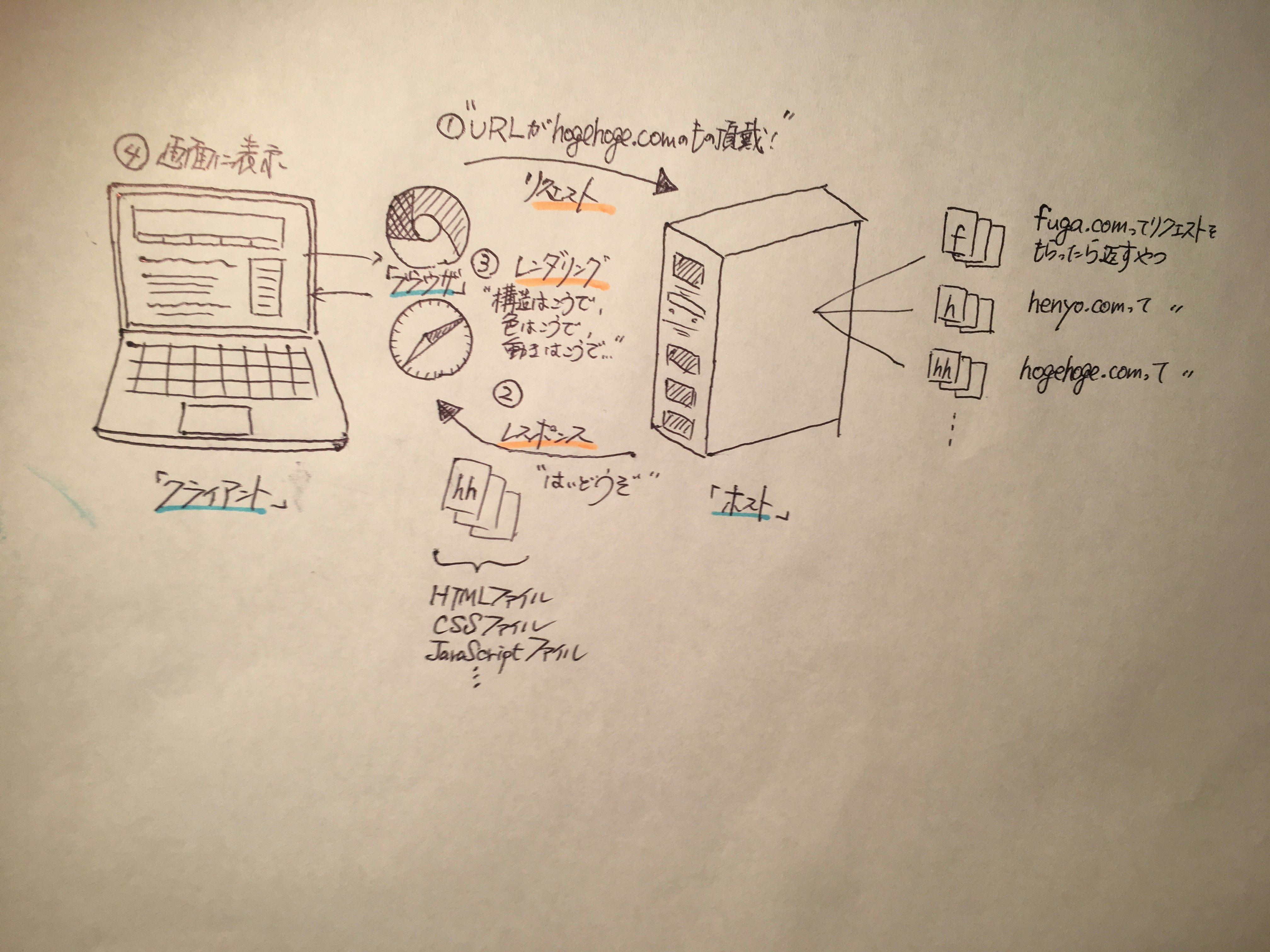
レスポンスで受け取った内容は、③の処理(レンダリング)で、ブラウザによって人が読める形に処理されます。
レンダリング前の元々の状態は、MacであればCommand+Option+U(またはI)で、WindowsであればControl+U(または+Shift+I)で確認することが出来ます。
下の画面はYahoo!JAPANのトップページで、画像右側が処理される前のHTMLファイル、左側がHTMLファイルやCSSファイル等様々なファイルをブラウザが処理(レンダリング)した後画面に表示される、いつも見ている画面(④)になります。
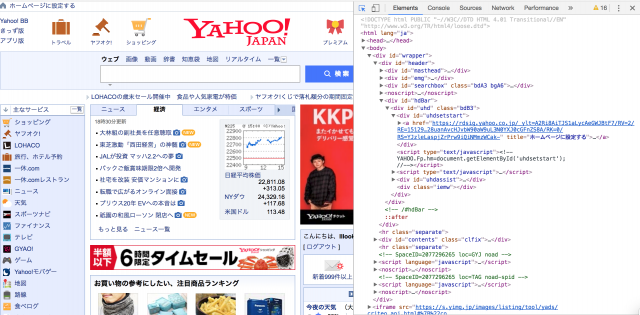
見てわかるとおり、HTMLは<x>から</x>(xは仮置きで、実際は目的に応じてdiv,p,aなど様々な値が入ります)で囲まれたタグと呼ばれる要素によって構成されています。
また、<x id="hoge">や<x class="fuga">などidやclassと言ったもの(属性)を使って、目印が付いているものもあります。
より詳細については、ドットインストールやprogateなどで概要を学べると思うので、興味があれば御覧下さい。
クローラーの挙動
クローラーの話に戻ります。
先に「クローラーとは?」をお伝えしましたが、ここでは「クローラーが実際どんな動きをするのか」、挙動について簡単にご説明します。
クローラーの挙動の分解
クローラーの挙動については、大きく以下の3つに分けられます。
①コンテンツの取得(ダウンロード)
...サイトにアクセスし、HTMLなどをページ分全てダウンロードする
②データの解析(≒分解)
...ダウンロードしたページを要素(タグ等)に解析し、そのうち欲しいデータを取得する(抜き出し加工する)
③データの保存
...①と②によって取得したものをデータベースなどに保存する
この一連の流れ(主に①・②)を繰り返していくことをクローリングと言います。
例えば、②で、そのページ上の欲しい情報に加えてリンク(URL)の取得も行うことで、
「①取得したリンク先にアクセス」→「②解析して欲しいデータを取得&次アクセスしたいページのリンクを取得」→「①取得したリンク先にアクセス」→…
と自動で繰り返し、どんどん欲しい情報を集めることが出来たりします。
この②解析の際に、例えば「<a>タグ」だったり「id="hogehoge"のもの」だったりと、欲しい情報を持っている要素を指定してあげることで、自由に情報を取得することが出来ます。
下のようなHTMLファイルを持つページであれば、例えば「<p>タグで且つid="hoge"のもの」と指定すれば、欲しい情報を取得出来ます。
<html>
<head>
省略
<body>
<p class = "hoge">
欲しい情報①
</p>
<p class = "fuga">
別にいらない情報
</p>
<p class = "hoge">
欲しい情報②
</p>
<p class = "fuga">
別にいらない情報
</p>
</body>
</html>
挙動を可能とするライブラリ
クローラーをいちから作成することも勿論可能ですが、既に確立された作成方法が存在する場合は、その方法をパーツレベルで分解・再利用し、自分の目的に合わせて組み合わせて作成する方が早いです。
一般公開され、誰でも利用可能な状態にある部品のことをライブラリと呼び、特にRubyではGemという形式(名称)で広く公開されています。基本的にダウンロードすることで使用可能となります。
挙動別に代表的なライブラリ名を列挙しておきます。
(もう少し後に紹介するライブラリがこれらをデフォルトで参照していることも多く、直接関わる機会は少ないかもしれないですが。)
①コンテンツの取得(ダウンロード)
・「open-uri」
・標準添付されており、Ruby利用可能であればすぐに使える
・「httpclient」
・Cookieの対応やHTTPのHEADメソッドやPOSTメソッドに対応
②データの解析(≒分解)
・「Nokogiri」
・CSSセレクタ等を使っての解析が可能で使いやすい
※因みにこうした構文解析プログラムのことを**パーサー(parser)**と呼びます
③データの保存
特になし(何かあれば知りたい)
④その他
・「robotex」
・”robot.txt”を参照しクロールの可否を確認してくれる
※”robot.txt”…クローラーのアクセスの可否などを指示するファイル。
SEOの文脈などでよく出てくる。
ページの性質と性質別クローラー作成
上述したような動きでサイト上を動き周り、必要な情報を収集していくクローラーですが、サイト・ページの性質に応じて、異なった対応が必要となることがあります。
ここでは、そうしたページの性質の分類と、それに対応するクローラーの作り方について概要をご説明します。
サイトの性質の分類
Webサイト・ページの種類を性質で大きく3つに分けると次のようになります。
①ステートレスなページ(状態を持たないページ)
・URLを指定すると単純にHTMLが返って来るタイプ
・クローラーで最も対応がしやすい
②ステートフルなページ(状態を持つページ)
・ログイン済み状態であったり、事前にPOSTで情報を送らないと参照できないようなタイプ
・上記問題を解決するためにクローラー側で一工夫必要
③JavaScriptをもとにクライアント側でページを組み立てるタイプ
・JS指示のもとデータの取得や処理をブラウザ内で行いページを組み立て表示するタイプ
・ブラウザ同様に、JSを解釈し描写する必要があり、通常のクローラーでの対応は困難
・ブラウザを起動し操作できたり、クローラー自身にブラウザエンジンを組込んだりする必要がある
このようにWebページと言っても様々な種類があり、それに合わせてクローラーも作り分ける必要があります。
サイト性質別ライブラリ
上記の種類に応じて、それぞれ異なったライブラリを組み合わせることで、対応したクローラーを作成することが出来ます。
各種類のサイトに対して最適な代表的なライブラリを列挙すると以下の通りです。
①ステートレスなページ(状態を持たないページ)
・「Anemone」
・次の巡回先の取得やページ解析、robot.txtの検出や対応など必要機能を一通り網羅している
②ステートフルなページ(状態を持つページ)
・「Mechanize」
・Webサイトとの対話を自動化できる。Cookieの保存やformタグへの入力・送信機能を備える
③JavaScriptをもとにクライアント側でページを組み立てるタイプ
・「Capybara」/「Selenium」
・ブラウザを利用して所定のパラメータを入力することなどができる
・Gemの「selenium-webdriver」や「Poltergeist」などが必要
これら4つのライブラリのうち、明確にクローリング目的で作られたものはAnemoneのみで、他のライブラリは解析や巡回機能などを別途付加する必要があったりします。
クローリング時のマナー
さてここまで、クローラーの動きや対象ページの性質の話をして来ましたが、もう一点大切な観点があると思っていて、それについて最後に記述します。
クローリングの対象となるWebサイトは著作物であり、やり方によってはトラブルを引き起こす可能性があります。トラブルを回避するための観点を幾つか列挙します。
①robot.txtを尊重する
…robot.txtは、クローラーがWebサイトを巡回する際に守るべき規約をまとめた紳士協定に過ぎず強制力はありませんが、トラブルを避けるためにできるだけ尊重した方が無難のようです。
②サイトの利用規約を確認する
…明示的な禁止事項と承諾事項を確認しましょう。
③著作権法に注意
…Webサイトに公開された情報は基本的に著作権法に従って取り扱う必要があるので注意が必要です。
④サイトに負荷をかけ過ぎて業務妨害にならないようにする
…クローリングを行うことでサイトに負荷をかけ、アクセス障害を引き起こすことがあります。アクセス頻度をコントロールするなど、荷重不可を回避する工夫が必要です。
終わりに
本投稿での内容は以上になります。
Web知識ゼロ状態からクローラーの作成の入り口まで、強引に詰め込んでみましたが、雰囲気だけでもお伝え出来たでしょうか。
クローラーに関して、まだまだ技術的な話や観点も沢山あるので、
「もっと具体的に知りたい!」「実際にクローラーを作りたい!」と言う際は、他の記事や、冒頭部分でお伝えした書籍などをご参照下さい。(自分も勉強します!)
もし来年また参加するなら、もっと突っ込んだ話を書けるようになりたいなあ。。
最後までお読みいただき、ありがとうございました!