この記事は、Elastic stack Advent Calendar 2016の24日目です。
自己紹介
- Acroquest Technology という会社でエンジニアをしています。
- 学生時代は自然言語処理や情報検索などをしていました。
概要
Elasticsearchを基盤にして、質問応答システム的な物を作りたい。
-
日本語で書かれた質問に対して勝手に答えを吐き出すようなもの。
-
知識源になり得るソースは世の中にいくらでもある。可能なら柔軟に選択できて、なおかつ情報が常にアップデートされてくのが理想。
-
知識源が膨大になったときに、スケールしやすいElasticsearchは良いかもしれないと思ってます。(もちろん個人で大きいクラスタ組んでやる気合いはありませんが)
-
複数記事に分けて書きます。
→今回の記事では下準備として色々試してみたことなどを書きます。
環境
- mac OS Sierra 10.12.2
- elasticsearch-5.1.1
- kibana-5.1.1
- python-3.5.2
- mecab 0.996
今回の流れ
- 方針書く
- 知識源となるデータをとりあえずelasticsearchに投入
- Python側から関連ドキュメントを取得できるようにする
方針
まず前提として、「質問応答」といっても定義がふわっとしている。
質問の種類によって難易度の幅も大きく違うので、
今回は第一段階として、最も簡単と思われる「真偽判定問題」を対象にしてみます。
たとえば特定の事実をあらわす「徳川家康は江戸幕府をひらいた」といった文に対して、
真偽判定を行うものです。
これなら
- 知識源データが正しく保持されている
- 質問の解釈ができる
- 知識源から正しい情報を検索できる
という条件がそろえば百発百中で正解できるはずです。
理論上は。
知識源となるデータをとりあえずelasticsearchに投入
今回はある程度のサンプルデータを作成して、Elasticsearchに投入します。
とりあえずテキストデータそのものと、分かち書きしたものを突っ込んでみました。
(キーワードを視覚的に見れたほうが嬉しいけど、
あとで構文解析したくなるだろうなぁと思ってテキストも残してます)
データの流れとしては
データソース → Python → elasticsearch → Python → 出力
とするのが良いかと思っています。
突っ込んだデータはこんな感じ
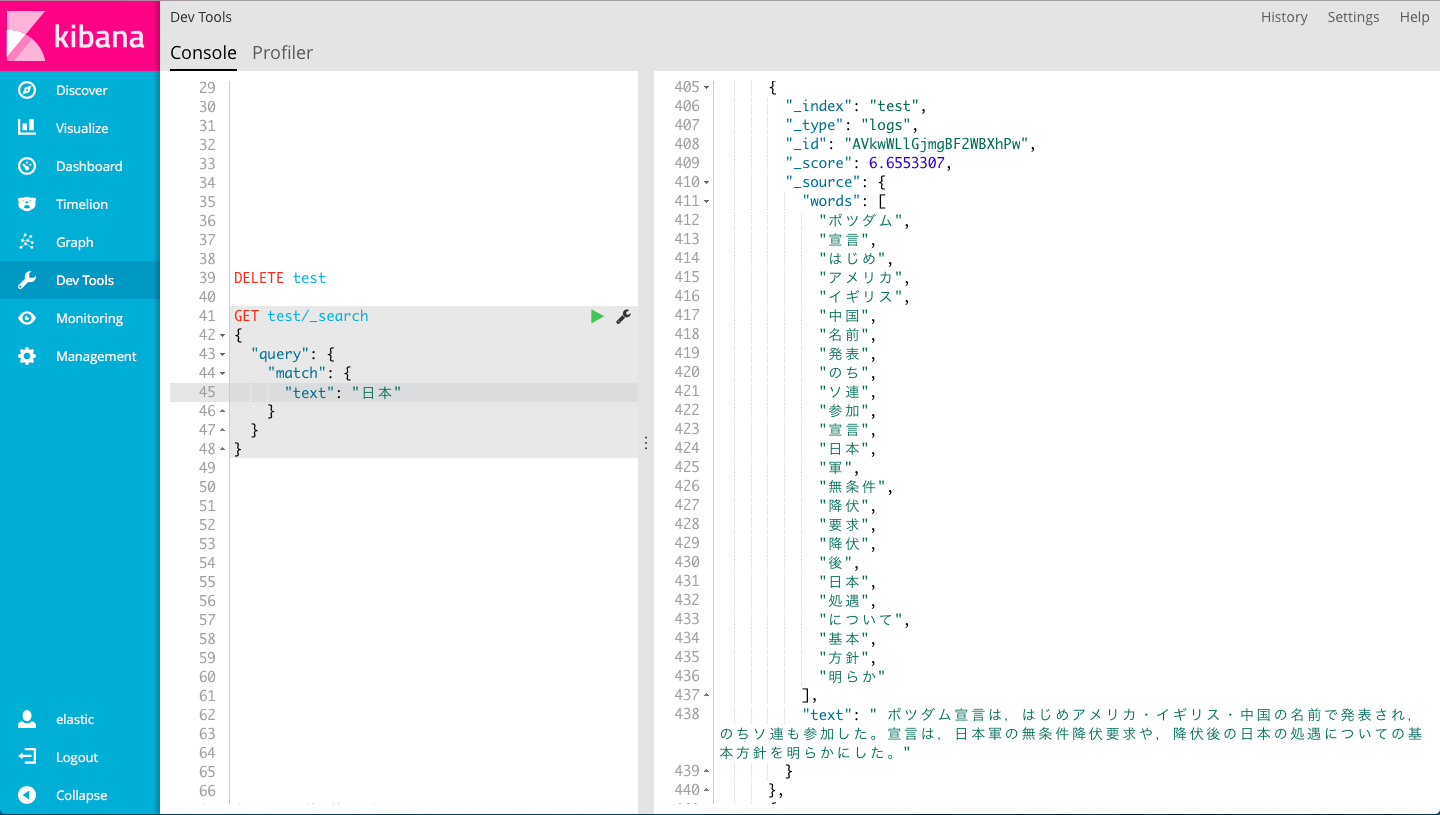
今回やりたいことに直接関係ないですが、配列で持っとくとGraph使えて楽しいです
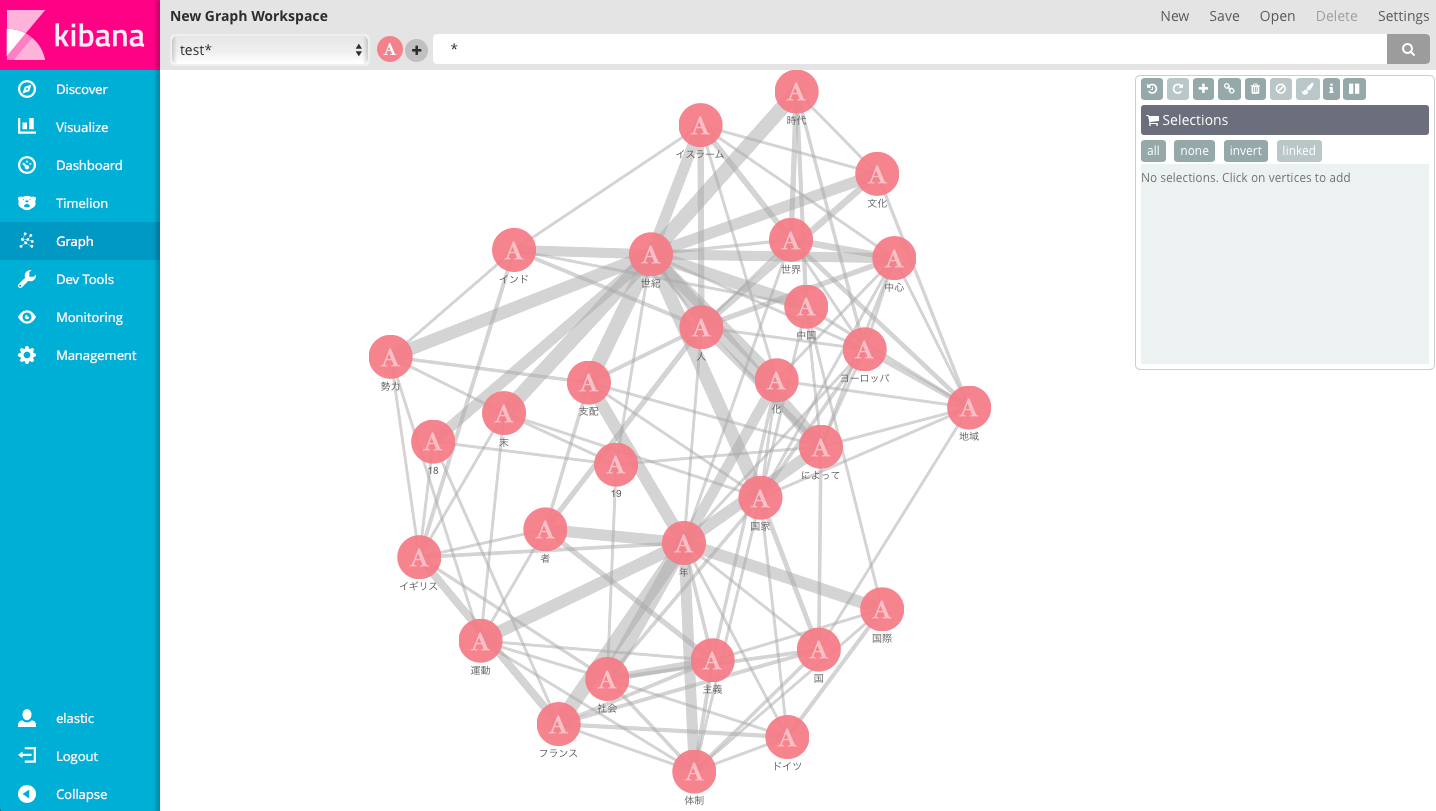
Graph今回は意味ないと思ったけど割と重要でした...
これを見ると「19」と「世紀」が別々で出てきたり「化」という謎の単語が抽出されていることが一目でわかります。(「化」ってなんだよ....)
処理としては間違ってないけれど「○○世紀」はセットになってくれた方が嬉しい。
分かち書きのやり方を改善する必要がありそうです。
辞書は別途見直してみます。
とりあえず適当なキーワードでpython側から検索できることを確認します。
from elasticsearch import Elasticsearch
import json
es = Elasticsearch(['http://USER:PASSWORD@localhost:9200'])
request_body="{\"size\":10,\"query\":{\"term\":{\"words.keyword\":\"日本\"}}}"
output = open("search_result.json","w")
json.dump(es.search(index="test",body=request_body),output, ensure_ascii=False, indent=4, sort_keys=True, separators=(',', ': '))
こんな感じで書けば「日本」というワードを含むドキュメントが引っ張れます。
結果は↓のように返ってきます

真偽判定という点に関して言えば、
あとは質問文と、返ってきたドキュメントのテキストを解析すれば判定できそうです。
とりあえず下準備ということで今回はここまでにします。
続きをご期待ください。
まとめ
とりあえず質問応答システムを作る下準備をしました
(下準備の下準備くらいかもしれませんが。。。)
次の記事ではちゃんと質問に答えてくれる子を作りたいものです。