Kaggle Advent Calendar その2の23日目の記事です。
私はkaggleを始めたばかりでテーブルデータのコンペはTitanicしかやったことがないため、特徴量をどのように選べばいいのかよくわからなかったのでまとめます。
特徴量選択手法のまとめ
特徴量選択とは、機械学習のモデルを使用する際に有効な特徴量の組み合わせを探索するプロセスのことを表しています。
特徴量選択を行うことによりいくつかのメリットが得られます。
- 変数を少なくすることで解釈性を上げる
- 計算コストを下げて、学習時間を短縮する
- 過適合を避けて汎用性を向上させる
- 高次元データによって、パフォーマンスが下がることを防ぐ。
特徴量選択の種類
特徴量選択の手法は大別して3つ存在します。
- Filter Method
- Wrapper Method
- Emedded Method
Filter Method
Filter Methodとは、機械学習モデルを使用せずにデータセットのみで完結する手法であり、データの性質に依存します。そのためたいていはどの機械学習モデルに対しても有効であり、なおかつ処理が高速です。
まずは変数の1つ1つを独立に処理していく手法を紹介します。手順としては以下になります。
- 評価指標に則って、特徴量を1つ1つランク付けする
- 上位のランクの特徴量を選択して使用する
あくまで変数を独立に計算していくので、変数間の関係などは考えません。
評価指標として、変数ごとに統計テストを行っていきます。
- カイ2乗スコア
- フィッシャースコア
- anova
- 変数の分散
また、変数間同士の関係も計算する手法も存在し、例として以下のようなものになります。
- 無駄な(説明変数に影響を与えない)特徴量を削除する
- 同じ傾向を示す($y1 = x1 + a$のような)特徴量を削除する
- 相関が非常に高い特徴量を削除する
このFilter Methodは、特徴量を削減するときに真っ先に行う処理です。
Wrapper Method
Filter Methodでは、特徴量の性質を1つ1つ見ていき、それが予測にどの程度寄与しているのか等は考慮していませんでした。しかし実際には、最適な特徴量の組み合わせは使用する機械学習モデルに依存します。
Wrapper Methodとは、機械学習モデルを使用して特徴量の組み合わせを評価することです。こうすることでFilter Methodではわからなかった変数間の関係を探し出し、それぞれのモデルに最適な特徴量の組み合わせを探し出すことができます。
Wrapper Methodを行うには以下を繰り返して実行していきます。
- 特徴量の組み合わせを選択する
- [1]で選択した特徴量を使用してモデルを学習させる
- 性能を評価する
しかしどのように特徴量の組み合わせを探せばいいのか、またいづ探索を切り上げればいいのでしょうか。
特徴量の組み合わせを見つけ出す方法は大きく3つ存在しています。
- Forward Feature Selection
- イテレーションごとに特徴量を1つずつ追加していく手法
- Backward feature Elimination
- イテレーションごとに特徴量を1つずつ削除していく方法
- Exhaustive Feature Search :
- すべての組み合わせを試す
この組み合わせの探索方法からわかるように、Wrapper Methodは、Filter Methodと比較して、計算コストが非常に高いです。しかしFilter Methodよりも精度の高い特徴量選択を行うことができます。
また組み合わせの探索を切り上げるための評価指標は、タスクに合わせて選択する必要があります。
Embedded Method
Embedded Methodとは、特徴量選択をモデルの学習時に行う手法です。Filter Methodでは計算することのできなかった変換の関係も、この手法で計算することができます。また学習時に探索するため、Wrapper Methodよりも計算コストはかなり低いです。
手順は以下のようになります。
- モデルを学習させる
- 特徴量の重要度を算出する
- 重要でない特徴量を削除する
よく使用されるモデルとして、Lassoモデルや、木モデルでのfeature importance、回帰係数を含む線形モデルなどが存在します。
実際に解析で使用してみる
使用するデータは2018年に開催されたSantandarのデータを使用します。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import VarianceThreshold
data = pd.read_csv('train.csv')
print(data.shape)
-> (4459, 4993)
データの訓練数と特徴の数は確認できたので、今度はNULL値が含まれているかどうかを確認します。
null_cols = [col for col in data.columns if data[col].isnull().sum() > 0]
print(null_cols)
-> []
NULL値が含まれていないことが確認できました。次は解析に使用するために、データを学習データと検証データに分けていきます。
X_train, X_test, y_train, y_test = train_test_split(
data.drop(['ID', 'target'], axis=1),
data['target'],
test_size=0.2,
random_state=2018
)
Filter Methodでの解析例
特徴量の値のみ選択する
ここでは特徴量の分散や同じ特徴量が存在するのかを確認していきます。
なお処理は個別に行っているわけではなく、上から順番に処理を行っています。
分散が0の場合
# 分散が0(すべて同じ値)のデータは削除します
sel = VarianceThreshold(threshold=0)
sel.fit(X_train)
# get_supportで保持するデータのみをTrue値、そうでないものはFalse値を返します
print(sum(sel.get_support()))
# -> 4692
これで元の4993個存在していた特徴量が、4692個とおよそ300個ほど特徴量を削減することができました。
あとはこの操作を訓練データとテストデータの両方に適用させます。
# numpy に変換したい場合はこちら
X_train = sel.transform(X_train)
X_test = sel.transform(X_test)
# pandasのまま保持して次の処理を行い場合はこちら
X_train = X_train.loc[:, sel.get_support()]
X_test = X_test.loc[:, sel.get_support()]
分散がほぼ0の場合
ここでは特徴量の値の大部分が同じデータのみの場合に削除するようにしていきます。当然このやり方は必ず正しいというわけではなく、元のデータの特徴を観察して削除するかどうか決めてください。
sel = VarianceThreshold(threshold=0.1)
sel.fit(X_train)
print(sum(sel.get_support()))
# -> 4692
# numpy に変換したい場合はこちら
X_train = sel.transform(X_train)
X_test = sel.transform(X_test)
# pandasのまま保持して次の処理を行い場合はこちら
X_train = X_train.loc[:, sel.get_support()]
X_test = X_test.loc[:, sel.get_support()]
この処理では特徴量の数は削減されなかったので、分散が0.1以下の特徴量は存在していないことがわかります。
特徴量がほかの特徴量と完全に一致している場合
ここではPandasのduplicatedメソッドを使用します。
# indexとcolumnsを入れ替える
X_train_T = X_train.T
print(X_train_T.duplicated().sum())
# -> 9
# 同じ特徴量の名前を取得したい場合はこちら
duplicated_features = X_train_T[X_train_T.duplicated()].index.values
print(len(X_train.columns))
# -> 4683
この手法で9つの特徴量が削減できました。
特徴量の相関係数を使用する
よい特徴量ならば、ターゲットの値と高い相関を持っているという仮定で特徴量を削減していきます。
注意点としては、特徴量にはターゲットといい相関を持っていてほしいですが、同時にほかの特徴量同士はあまり相関を持たないようにすることです。こうすることで冗長な特徴量を削減することができます。
参考:Correlation-based Feature Selection for Machine Learning
この手法を使用すればいくつかのメリットが得られます。
- 互いに相関の高い特徴量の片方を削除することで、精度にあまり影響を与えずに特徴量空間の次元を下げることができる。
- 線形モデルの解釈性を上げることができる。
相関はピアソン相関係数を用いて評価します。
threshold = 0.8
feat_corr = set()
corr_matrix = X_train.corr()
for i in range(len(corr_matrix.columns)):
for j in range(i):
if abs(corr_matrix.iloc[i, j]) > threshold:
feat_name = corr_matrix.columns[i]
feat_corr.add(feat_name)
print(len(set(feat_corr)))
# -> 658
X_train.drop(labels=feat_corr, axis='columns', inplace=True)
X_test.drop(labels=feat_corr, axis='columns', inplace=True)
print(len(X_train.columns))
# -> 4025
統計的評価指標を用いる
流れとしては以下のようになります。
- 特徴量をある評価指標で測る
- 高いランクの特徴量だけを残す
あくまで1つの特徴量とターゲットを使用して性能を評価するので、特徴量間の関係などは基本的にはわかりません。
# 使用するデータは直前までのFilter Methodを適用させたものが対象です
print(X_train.shape)
# -> (3567, 4025)
print(X_test.shape)
# -> (892, 4025)
Mutual Infomartion
相関係数を使用して特徴量を削減した手法と似ていますが、より一般的な手法になります。
ある特徴量Xと別の特徴量Yの間の同時分布$P(X, Y)$と個々の分布の積$P(X)P(Y)$がでれだけ似ているのかを計算します。もし互いに独立であればMutual Infomartionは0になります。
$$
\sum_{i,y} P(xi, yj) \times log \frac{p(xi, yj)}{P(xi)P(yj)}
$$
# 使用するモジュール
from sklearn.feature_selection import mutual_info_regression
from sklearn.feature_selection import SelectKBest, SelectPercentile
MI = mutual_info_regression(X_train, y_train)
MI = pd.Series(MI)
MI.index = X_train.columns
MI.sort_values(ascending=False).plot(kind='bar', figsize=(20,10))
# KBest : 抽出する特徴量の"数"を指定
kbest_sel_ = SelectKBest(mutual_info_regression, k=10)
print(len(kbest_sel_.get_support()))
# Percentile : 抽出する特徴量の割合を指定
percentile_sel_ = SelectPercentile(mutual_info_regression, percentile=10)
print(len(percentile_sel_.get_support()))
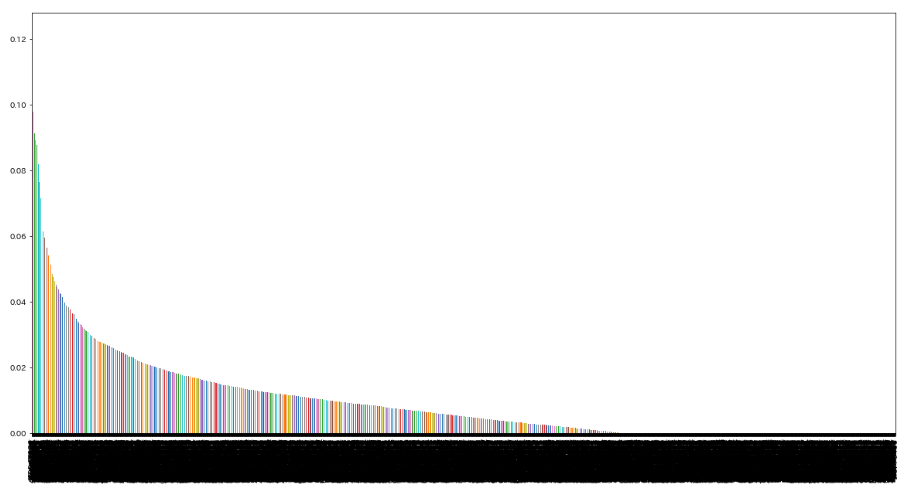
カイ2乗、フィッシャー係数
これは特徴量がカテゴリ変数でありターゲットが2値の場合によく使用される手法です。
例えば2値の分類タスクであるカテゴリの特徴量を評価する際、カテゴリごとの2値の出現回数などをカテゴリごとに比較したり、全体の出現回数などと比較したりします。
$$
S_{i} = \frac{\sum_{k=1}^{K} n_{j}(\mu_{ij}-\mu_{i]})}{\sum_{k=1}^{K} n_{j} \rho_{ij}^2}
$$
# Santandarのデータには適用できないので、簡単な紹介のみ
from sklearn.feature_selection import chi2
# fisher score
fscore = chi2(X_train.fillna(0), y_train)
Univariate
ターゲットが2値である必要があり、よく連続値の特徴量に対して使用されます。2変数に対して行う手法はANOVAなどと呼ばれます。
前提として(1)変数とターゲットに線形の関係があること、(2)変数が正規分布している必要があります。
# Santandarのデータには適用できないので、簡単な紹介のみ
from sklearn.feature_selection import f_regression
from sklearn.feature_selection import SelectKBest, SelectPercentile
univariate = f_regression(X_train, y_train)
sel_ = SelectKBest(f_regression, k=1000).fit(X_train, y_train)
Univariate ROC_AUC / RMSE
2変数間の依存性を評価しますが、この手法では機械学習モデルを使用します。
Univariateとは異なり、変数に特に前提条件は必要ありません。
流れとしては以下のようになります。
- 1変数のみを使用して学習させる
- すべての変数に対して計算にランキング付けする
- 高いランクの変数だけを選択する
from sklearn.tree import DecesionTreeRegressor
from sklearn.metrics import mean_squared_error, roc_auc_score
MSE_features = []
for feature in X_train.columns:
clf = DecisionTreeRegressor()
clf.fit(X_train[feature].to_frame(), y_train)
y_pred = clf.predict(X_test[feature].to_frame())
MSE_features.append(mean_squared_error(y_test, y_pred))
MSE_series = pd.Series(MSE_features)
MSE_series.index = X_train.columns
MSE_series.sort_values(ascending=False).plot(kind='bar', figsize=(20, 10))
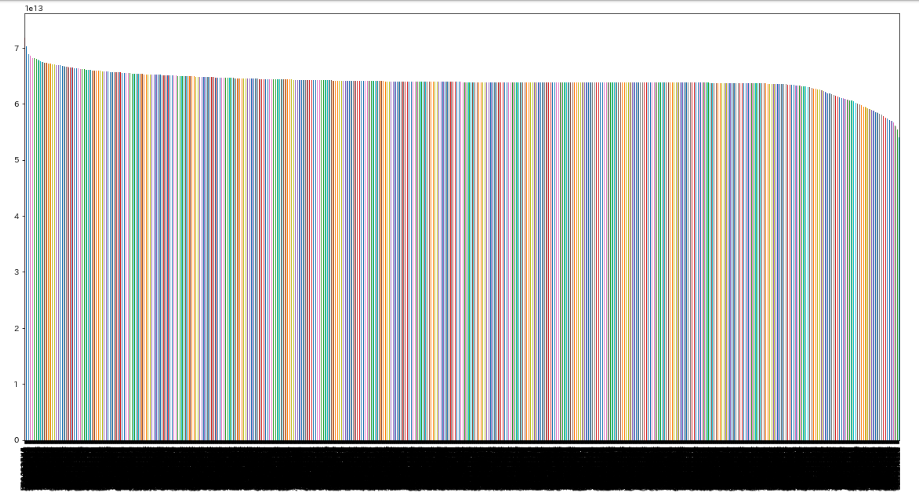
平均2乗誤差なので低いほうから選択して選ぶ必要があります。
Wrapper Methodでの解析例
使用するデータは簡単にFilter Methodを適用させたものを対象とします。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import VarianceThreshold
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from sklearn.metrics import roc_auc_score
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
data = pd.read_csv('train.csv')
X_train, X_test, y_train, y_test = train_test_split(
data.drop(['ID', 'target'], axis=1),
data['target'],
test_size=0.2,
random_state=2018
)
# 1. delete const, quisi-const, duplicated
# 2. correlated 0.8
評価指標としては、例として分類問題ならROC_AUCを選択し、回帰問題ならR squaredなど選択します。
Step Forward
- すべての特徴量から1つずつ独立して学習させる。
- 最も評価指標が高くなったものを選択する
- [1]で選択した特徴量に、ほかに特徴量をどれか1つのみ追加して学習させる。
- 最も評価指標が高くなった組み合わせを選択する。
- 上記を特徴量を1つずつ加えながら繰り返す。
sfs1 = SFS(RandomForestClassifier(n_jobs=4),
k_features=10, # いくつの特徴量を出力させたいのか
forward=True,
floating=False,
verbose=2,
scoring='roc_auc', # 'r2' なども選択できる。
cv=3)
sfs1 = sfs1.fit(np.array(X_train.fillna(0)), y_train)
selected_feat = X_train.columns[list(sfs1.k_feature_idx_)]
最後に抽出された特徴量を使用して学習を行ってみます。
clf = RandomForestClassifier(n_estimators=200, random_state=2018, max_depth=4)
clf.fit(X_train[selected_feat], y_train)
print(roc_auc_score(y_train, clf.predict_proba(X_train[selected_feat])[:, 1]))
print(roc_auc_score(y_test, clf.predict_proba(X_test[selected_feat])[:, 1]))
Step backward
- すべての特徴量を使用して評価する。
- 特徴量を1つずつ削除して評価する。
- 特徴量をさらに1つ削除して評価する。
- 上記を繰り返す。
sfs1 = SFS(RandomForestClassifier(n_jobs=4),
k_features=15, # いくつの特徴量を出力させたいのか
forward=False, # False -> Step Backward
floating=False,
verbose=2,
scoring='roc_auc', # 'r2' なども選択できる。
cv=3)
sfs1 = sfs1.fit(np.array(X_train.fillna(0)), y_train)
selected_feat = X_train.columns[list(sfs1.k_feature_idx_)]
最後に評価を行います。
clf = RandomForestClassifier(n_estimators=200, random_state=2018, max_depth=4)
clf.fit(X_train[selected_feat], y_train)
print(roc_auc_score(y_train, clf.predict_proba(X_train[selected_feat])[:, 1]))
print(roc_auc_score(y_test, clf.predict_proba(X_test[selected_feat])[:, 1]))
Exhaustive Search
- すべての組み合わせを試して最も性能が高くなった組み合わせを選択する。
これは計算量が非常に多くなります。例えば4つの特徴量を考えれば、全部で15通りを計算する必要があり、特徴量が多いデータセットには適用させることは難しいです。
from mlxtend.feature_selection import ExhaustiveFeatureSelector as EFS
efs1 = EFS(RandomForestClassifier(n_jobs=4, random_state=2018,
min_features=1,
max_features=4,
scoring='roc_auc',
print_progress=True,
cv=2))
efs1 = efs1.fit(np.array(X_train[X_train.columns[0:4]].fillna(0)), y_train)
clf = RandomForestClassifier(n_estimators=200, random_state=2018, max_depth=4)
clf.fit(X_train[selected_feat], y_train)
print(roc_auc_score(y_train, clf.predict_proba(X_train[selected_feat])[:, 1]))
print(roc_auc_score(y_test, clf.predict_proba(X_test[selected_feat])[:, 1]))
Embedded Method での解析例
使用するデータは簡単なFilter Methodを適用させたものにします。
Lasso正則化
L1正則化には重要でない特徴量に対して、その係数をゼロにしていく性質が存在します。そこでこの性質を利用して特徴量を削減していくことを考えます。
解析の際は線形モデルなので特徴量を正規化させておきます。
from sklearn.linear_model import Lasso
from sklearn.feature_selection import SelectFromModel
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
sel_ = SelectFromModel(Lasso(alpha=100))
sel_.fit(scaler.transform(X_train, y_train))
print(len(sel_.get_support()))
木モデル
from sklearn.ensemble import RandomForestRegressor
from sklearn.feature_selection import SelectFromModel
sel_ = SelectFromModel(RandomForestRegressor(n_estimators=200))
sel_.fit(X_train, y_train)
rest_features = X_train.columns[sel_.get_support()]
参考文献
- A survey on Feature Selection Methods
- Feature-Selection-for-Machine-Learning
- The 2009 Knowledge Discovery in Data Competition (KDD Cup 2009)
- Feature Selection: A literature Review
- An Introduction to Variable and Feature Selection
- Feature Selection for High-Dimensional Data: A Fast Correlation-Based Filter Solution
- Data Preprocessing for Supervised Learning
- Correlation-based Feature Selection for Machine Learning
- A review of feature selection methods with applications
- Feature Selection for Classification: A Review
ほかにもHybrid MethodやRecursiveなやり方などいろいろあるけど力尽きました。