1.初めに
ハイパーパラメータのチューニングで
グリッドサーチとベイズ最適化のどちらが楽で良いか検証してみた。
一般的な星取り表でまとめるとこんな感じ・・・
| グリッドサーチ | ベイズ最適化 | |
|---|---|---|
| 探査 | 全数探査 | 最適点探査 |
| 変数の取り扱い | 離散値 | 連続値/離散値 |
| 計算時間(コスト) | 長? | 短? |
| 精度 | ? | ? |
全数探査するからグリッドサーチの方が精度良くなりそうだけど、
離散的な探索だから、ベイズ最適化の方が良いんじゃないかと思います。
しかし、計算コストに対してどの程度精度が良くなるかはわからないので、
今回は、同じ問題でグリッドサーチとベイズ最適化でチューニングしてみて、
精度と計算時間(コスト)を明確化してみることにした。
2.検証するデータについて
前回記事のデータで検証する
入力因子は8つ、出力因子(特性値)は1つの回帰問題である。
3.チューニングするモデル・変数について
チューニングするモデルはDeep Neural Network(5層のパーセプトロン)とする。
パラスタする因子は下の表の通りとする。
| 変数 | 1水準目 | 2水準目 | 3水準目 |
|---|---|---|---|
| 隠れ層1層目のニューロン数 | 50 | 100 | 200 |
| 活性化関数 | ReLU | Swish | Mish |
| 学習率 | 0.01 | 0.1 | 0.5 |
| batchサイズ | 10 | 50 | 100 |
| Epochs | 100 | 200 | 300 |
※2層目のニューロン数は 1層目の1/2
※3層目のニューロン数は 1層目の1/4
※4層目のニューロン数は 1層目の1/8
※5層目のニューロン数は 1層目の1/16 と設定する
※Early Stoppingは今回は不使用
※グリッドサーチのGridSearchCVのk分割交差検証は2とした
※ベイズ最適化のiterationは100回とした
※ベイズ最適化は1水準目から3水準目の間は連続値となる
※ベイズ最適化で「質的因子」や「変数を離散的」に取り扱うには工夫がいるので、付録にて解説する
これは今回使用したベイズ最適化のライブラリ特有の仕様のため↓
4.結果
今回の結果は以下の表の通り。
活性化関数はSwishがどちらも良いという結果に
ニューロン数は異なる結果に
| 変数 | グリッドサーチのベスト | ベイズ最適化のベスト |
|---|---|---|
| 隠れ層1層目のニューロン数 | 50 | 101 |
| 活性化関数 | Swish | Swish |
| 学習率 | 0.01 | 0.02 |
| batchサイズ | 100 | 70 |
| Epochs | 200 | 257 |
| 計算時間 | 181分 | 37分 |
| チューニング回数 | 486回 | 100回 |
では未学習データの予測結果はどうなったかというと…
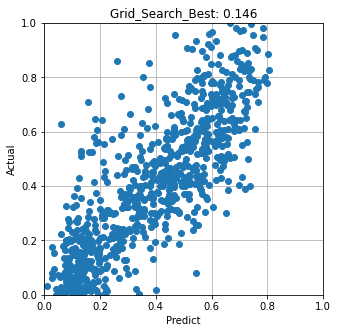
グリッドサーチで得られたベスト設定で予測した結果 RMSE=0.146
ベイズ最適化で得られたベスト設定で予測した結果 RMSE=0.149
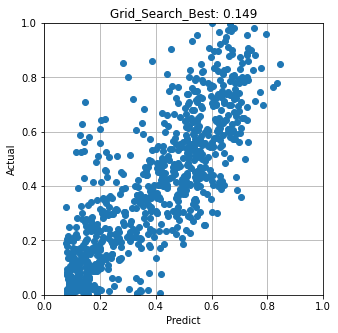
RMSEで評価した結果はグリッドサーチの方が良い結果となった
※最適化は乱数依存の初期値問題があるので、この通りになるとは限らないですが・・・
まじめにやるならN増しが必要ですが今回はN1の検証です。
まとめ
今回はベイズ最適化の6倍の計算コストをかけたグリッドサーチの方が良い結果であった
しかし、RMSEの差異は0.003で僅かです
納期が近く、コストもかけられない中ではベイズ最適化は有効であると考える
時間があり、コストもかけられる中では愚直にグリッドサーチを実施した方が良さそうであると考える。
まぁどちらも有効な手段ですので、使えることに越したことはないなと思います。
色々調べてみるとベイズ最適化のライブラリはGPyOptを活用したほうが良さそうです。
GPyOptは離散的な変数の取り扱いが楽だったり、最大化・最小化の切り替えができる模様。
bayesian-optimizationは最大化のみなので、いろいろ設定が煩雑。
次回はGpyOptのベイズ最適化とbayesian-optimizationの比較もしてみようと思います。
最後までお読みいただきありがとうございました。
付録 GridSearchのコード
# ライブラリのインポート
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_california_housing
cali_housing = fetch_california_housing(as_frame=True)
x=cali_housing.data
y=cali_housing.target
cali_housing.frame.describe()
df=cali_housing.frame
ar_std=df['AveRooms'].std()
ab_std=df['AveBedrms'].std()
pop_std=df['Population'].std()
ao_std=df['AveOccup'].std()
mhv_std=df['MedHouseVal'].std()
ar_mean=df['AveRooms'].mean()
ab_mean=df['AveBedrms'].mean()
pop_mean=df['Population'].mean()
ao_mean=df['AveOccup'].mean()
mhv_mean=df['MedHouseVal'].mean()
limit_low=ar_mean - 1*ab_std
limit_high=ar_mean + 1*ab_std
limit_low1=ab_mean - 1*ab_std
limit_high1=ab_mean + 1*ab_std
limit_low2=pop_mean - 1*pop_std
limit_high2=pop_mean + 1*pop_std
limit_low3=ao_mean - 1*ao_std
limit_high3=ao_mean + 1*ao_std
limit_low4=mhv_mean -1*mhv_std
limit_high4=mhv_mean +1*mhv_std
newdf=df.query('@limit_low < AveRooms < @limit_high')
newdf1=newdf.query('@limit_low1 < AveBedrms < @limit_high1')
newdf2=newdf1.query('@limit_low2 < Population < @limit_high2')
newdf3=newdf2.query('@limit_low3 < AveOccup < @limit_high3')
newdf4=newdf3.query('@limit_low4 < MedHouseVal < @limit_high4')
newdf4.describe()
#正規化(Max-Min法)
def minmax_norm(df):
return (df - df.min()) / ( df.max() - df.min())
df_minmax_norm = minmax_norm(newdf4)
df_minmax_norm.describe()
# 必要なライブラリーのインポート
import seaborn as sns
# 多変量連関図
sns.pairplot(df_minmax_norm, size=1.0)
x=df_minmax_norm.iloc[:,0:8]
y=df_minmax_norm.iloc[:,8:9]
from sklearn.model_selection import train_test_split
#全体データから未知データを生成
x_know,x_unknown,y_know,y_unknown=train_test_split(x,y,test_size=0.2)
#既知データから訓練データとテストデータに分割
x_train,x_test,y_train,y_test=train_test_split(x_know,y_know,test_size=0.2)
# Importing the necessary packages
import time
from sklearn.model_selection import GridSearchCV, KFold
from keras.models import Sequential
from keras.layers import Dense
from keras.losses import mean_squared_error
import tensorflow as tf
from tensorflow.keras.layers import Activation
from tensorflow.keras.utils import get_custom_objects
#分類問題用のライブラリ
#from keras.wrappers.scikit_learn import KerasClassifier
#回帰問題用nライブラリ
from keras.wrappers.scikit_learn import KerasRegressor
from keras.optimizers import Adam
from keras.layers import Dropout
#============================================================================
class Mish(Activation):
'''
Mish Activation Function.
.. math::
mish(x) = x * tanh(softplus(x)) = x * tanh(ln(1 + e^{x}))
Shape:
- Input: Arbitrary. Use the keyword argument `input_shape`
(tuple of integers, does not include the samples axis)
when using this layer as the first layer in a model.
- Output: Same shape as the input.
Examples:
>>> X = Activation('Mish', name="conv1_act")(X_input)
'''
def __init__(self, activation, **kwargs):
super(Mish, self).__init__(activation, **kwargs)
self.__name__ = 'Mish'
def mish(inputs):
return inputs * tf.math.tanh(tf.math.softplus(inputs))
get_custom_objects().update({'Mish': Mish(mish)})
#============================================================================
# DNNモデル定義
def create_model(learning_rate,active,neuron):
model = Sequential()
#ポイント:float型に変更
neuron=float(neuron)
neuron2=int(neuron/2)
neuron3=int(neuron/4)
neuron4=int(neuron/8)
neuron5=int(neuron/16)
#最後にint型に戻す
neuron=int(neuron)
model.add(Dense(neuron,input_dim = 8,kernel_initializer = 'normal',activation = active))
model.add(Dense(neuron2,activation = active))
model.add(Dense(neuron3,activation = active))
model.add(Dense(neuron4,activation = active))
model.add(Dense(neuron5,activation = active))
model.add(Dense(1,activation = 'linear'))
adam = Adam(lr = learning_rate)
#model.compile(loss = 'binary_crossentropy',optimizer = adam,metrics = ['acc'])
model.compile(loss = 'mse',optimizer = adam,metrics = ['mae'])
return model
# Create the model
#model = KerasClassifier(build_fn = create_model,verbose = 0,batch_size = 40,epochs = 10)
# Define the grid search parameters
active=['relu','swish','Mish']
epochs_grid=[50,100,150]
batch_size_grid=[10,50,100]
learning_rate = [0.01,0.1,0.5]
neuron=['50','100','200']
### the grid search parametersを辞書型で定義する
param_grids = dict(active=active,neuron=neuron,learning_rate = learning_rate,batch_size=batch_size_grid,epochs=epochs_grid)
#回帰問題の設定
model=KerasRegressor(build_fn=create_model,verbose=0,batch_size = batch_size_grid,epochs = epochs_grid)
# Build and fit the GridSearchCV
#時間計測
t1 = time.time()
grid = GridSearchCV(estimator = model,param_grid = param_grids,verbose = 10,cv=KFold(n_splits=2))
grid_result = grid.fit(x_train,y_train)
#時間計測終了
t2 = time.time()
# 経過時間を表示
elapsed_time = t2-t1
print(f"経過時間:{elapsed_time}")
# 結果のまとめを表示
print('Best : {}, using {}'.format(grid_result.best_score_,grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print('{},{} with: {}'.format(mean, stdev, param))
付録:Bayesian Opti.のコード
本検討ではbayesian-optimizationを使用するため、
ライブラリが無い方は下記をインストールしてください
pip install bayesian-optimization
このライブラリは変数が連続値として取り扱われるため
離散的な取り扱いをしたい場合、下記のように記述しておいてベイズ最適化の変数設定でacti_criteriaを0~30まで連続値で設定することで再現できるので参考にしていただきたい。
create_model(learning_rate,batch_size,neuron,epochs_opti,acti_criteria):
model = Sequential()
・・・省略・・・
#活性化関数の選択#
acti_criteria=acti_criteria/10
acti_list = ['ReLU', 'swish','Mish']
listno=int(round(acti_criteria,1))
active = acti_list[listno]
・・・
全コードは下記の通り
# ライブラリのインポート
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_california_housing
cali_housing = fetch_california_housing(as_frame=True)
x=cali_housing.data
y=cali_housing.target
cali_housing.frame.describe()
df=cali_housing.frame
ar_std=df['AveRooms'].std()
ab_std=df['AveBedrms'].std()
pop_std=df['Population'].std()
ao_std=df['AveOccup'].std()
mhv_std=df['MedHouseVal'].std()
ar_mean=df['AveRooms'].mean()
ab_mean=df['AveBedrms'].mean()
pop_mean=df['Population'].mean()
ao_mean=df['AveOccup'].mean()
mhv_mean=df['MedHouseVal'].mean()
limit_low=ar_mean - 1*ab_std
limit_high=ar_mean + 1*ab_std
limit_low1=ab_mean - 1*ab_std
limit_high1=ab_mean + 1*ab_std
limit_low2=pop_mean - 1*pop_std
limit_high2=pop_mean + 1*pop_std
limit_low3=ao_mean - 1*ao_std
limit_high3=ao_mean + 1*ao_std
limit_low4=mhv_mean -1*mhv_std
limit_high4=mhv_mean +1*mhv_std
newdf=df.query('@limit_low < AveRooms < @limit_high')
newdf1=newdf.query('@limit_low1 < AveBedrms < @limit_high1')
newdf2=newdf1.query('@limit_low2 < Population < @limit_high2')
newdf3=newdf2.query('@limit_low3 < AveOccup < @limit_high3')
newdf4=newdf3.query('@limit_low4 < MedHouseVal < @limit_high4')
newdf4.describe()
#正規化(Max-Min法)
def minmax_norm(df):
return (df - df.min()) / ( df.max() - df.min())
df_minmax_norm = minmax_norm(newdf4)
df_minmax_norm.describe()
# 必要なライブラリーのインポート
import seaborn as sns
# 多変量連関図
#sns.pairplot(df_minmax_norm, size=1.0)
x=df_minmax_norm.iloc[:,0:8]
y=df_minmax_norm.iloc[:,8:9]
from sklearn.model_selection import train_test_split
#全体データから未知データを生成
x_know,x_unknown,y_know,y_unknown=train_test_split(x,y,test_size=0.2)
#既知データから訓練データとテストデータに分割
x_train,x_test,y_train,y_test=train_test_split(x_know,y_know,test_size=0.2)
# Importing the necessary packages
from sklearn.model_selection import GridSearchCV, KFold
from keras.models import Sequential
from keras.layers import Dense
from keras.losses import mean_squared_error
import tensorflow as tf
from tensorflow.keras.layers import Activation
from tensorflow.keras.utils import get_custom_objects
#分類問題用のライブラリ
#from keras.wrappers.scikit_learn import KerasClassifier
#回帰問題用のライブラリ
from keras.wrappers.scikit_learn import KerasRegressor
from keras.optimizers import Adam
from keras.layers import Dropout
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from bayes_opt import BayesianOptimization
#============================================================================
class Mish(Activation):
'''
Mish Activation Function.
.. math::
mish(x) = x * tanh(softplus(x)) = x * tanh(ln(1 + e^{x}))
Shape:
- Input: Arbitrary. Use the keyword argument `input_shape`
(tuple of integers, does not include the samples axis)
when using this layer as the first layer in a model.
- Output: Same shape as the input.
Examples:
>>> X = Activation('Mish', name="conv1_act")(X_input)
'''
def __init__(self, activation, **kwargs):
super(Mish, self).__init__(activation, **kwargs)
self.__name__ = 'Mish'
def mish(inputs):
return inputs * tf.math.tanh(tf.math.softplus(inputs))
get_custom_objects().update({'Mish': Mish(mish)})
#============================================================================
# DNNモデル定義
def create_model(learning_rate,batch_size,neuron,epochs_opti,acti_criteria):
model = Sequential()
#隠れ層の変数化
neuron=int(neuron) #float(neuron)
neuron2=int(neuron/2)
neuron3=int(neuron/4)
neuron4=int(neuron/8)
neuron5=int(neuron/16)
#最後にint型に戻す
neuron=int(neuron)
#活性化関数の選択#
acti_criteria=acti_criteria/10
acti_list = ['ReLU', 'swish','Mish']
listno=int(round(acti_criteria,1))
active = acti_list[listno]
model.add(Dense(neuron,input_dim = 8,kernel_initializer = 'normal',activation = active))
model.add(Dense(neuron2,activation = active))
model.add(Dense(neuron3,activation = active))
model.add(Dense(neuron4,activation = active))
model.add(Dense(neuron5,activation = active))
model.add(Dense(1,activation = 'linear'))
adam = Adam(lr = learning_rate)
model.compile(loss = 'mse',optimizer = adam,metrics = ['mae'])
#訓練データでトレーニング
model.fit(x_train, y_train,verbose=0, batch_size=int(batch_size),epochs = int(epochs_opti))
#テストデータで精度を確認
score = model.evaluate(x_test, y_test)
return score[0]*(-1)
def bayesianOpt():
pb = {
'batch_size' : (10,100),
'learning_rate' : (0.01, 0.5),
'neuron':(50,200),
'epochs_opti':(50,150),
'acti_criteria':(0,30)
}
optimizer = BayesianOptimization(f=create_model, pbounds=pb)
optimizer.maximize(init_points=5, n_iter=100, acq='ucb')
return optimizer
import time
#時間計測
t1 = time.time()
#ベイズ最適化の実行
result = bayesianOpt()
#時間計測終了
t2 = time.time()
# 経過時間を表示
elapsed_time = t2-t1
print(f"経過時間:{elapsed_time}")
result.res
result.max