目次
- はじめに
- 実行環境
- 画像収集
- CNNモデル作成(初期)
- 改良(画像水増し、vgg16転移学習、バッチ正規化)
- アプリ作成
- 反省とまとめ
はじめに
この記事は初心者のおじさんが、思い付きで始めたプログラミング学習の一環としてAidemyさんのデータ分析講座を受講し、成果物の作成をしたものです。
テーマは「アンパンマンキャラを識別するアプリを作成する」です。子供が好きなのと、画像収集が(おそらく)容易であろうということで決めました。
※記事中にはアンパンマンの画像は著作権の関係で載せていません
実行環境
Python 3.10.4
Google Colaboratory
Visual Studio Code (1.68.0)
画像収集 (Icrawler)
画像収集にはIcrawlerを用いました。
公式サイト
参考サイト
キャラ選定はTwitterでフォロワーさんに軽くアンケートして決めました。

画像収集のコード
from icrawler.builtin import BingImageCrawler
character_list=['anpanman', 'currypanman', 'syokupanman', 'baikinman', 'melonpanna',
'rollpanna', 'dokinchan', 'kokinchan', 'naganegiman']
character_word_list=['アンパンマン', 'カレーパンマン', '食パンマン', 'バイキンマン', 'メロンパンナちゃん',
'ロールパンナちゃん', 'ドキンちゃん', 'コキンちゃん', 'ナガネギマン']
character_dict=dict(zip(character_list, character_word_list))
#icrawlerで画像集め
for i, j in character_dict.items():
crawler = BingImageCrawler(storage={"root_dir": 'ディレクトリのパス/'+i})
crawler.crawl(keyword=j, max_num=300)
各キャラ150~200枚程度集まりました。
その後、手作業で不要な画像や重複画像を削除&目的のキャラがメインになるようにトリミングし、各キャラ100枚前後のデータとしました。
CNNモデルの作成(初期)
画像収集が出来たのでとりあえず簡単なモデルを作って学習させてみることにしました。
モデルは画像認識分野でポピュラーなCNN(Convolutional Neural Network)を採用しました。
#GoodleDriveに保存した画像データを読み込み、ラベルデータとともにリスト化
X=[]
y=[]
def character_label(character, label):
for i in os.listdir("/content/drive/MyDrive/anpanman2/"+character+"/"):
img=cv2.imread("/content/drive/MyDrive/anpanman2/"+character+"/"+i)
img=cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img=cv2.resize(img, (50, 50))
X.append(img)
y.append(label)
for j in range(len(character_list)):
character_label(character_list[j], j)
#imgリストをnumpyに変換、ラベル付け
X = np.array(X)
y = np.array(y)
#データをシャッフルして学習データと検証データに分割
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
y_train=to_categorical(y_train)
y_test=to_categorical(y_test)
#CNNモデルの作成
model=Sequential()
model.add(Conv2D(filters=64, kernel_size=(5,5), input_shape=(50, 50, 3)))
model.add(Activation('relu'))
model.add(Conv2D(filters=64, kernel_size=(5,5)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Activation('relu'))
model.add(Conv2D(filters=32, kernel_size=(5,5)))
model.add(Activation('relu'))
model.add(Dense(64))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(9, activation='softmax'))
#コンパイル
model.compile(loss='categorical_crossentropy',
optimizer='adadelta',
metrics=['accuracy'])
#学習
history=model.fit(X_train, y_train, batch_size=16, epochs=100, verbose=1, validation_data=(X_test, y_test))
#学習結果の可視化
plt.plot(history.history['accuracy'], label='acc', ls='-')
plt.plot(history.history['val_accuracy'], label='val_acc', ls='-')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
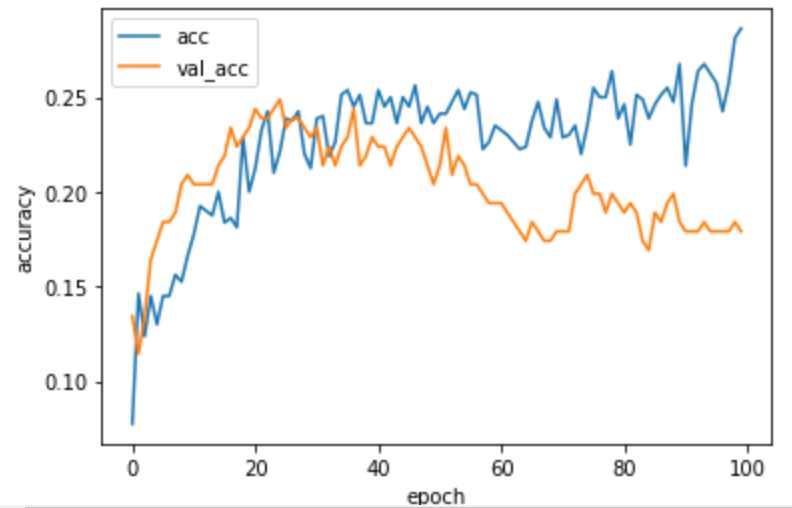
ひどい結果・・・正解率20%前後。しかも上がったり下がったりでepoch数を増やしても学習が進んでいる感じもない・・・。
パラメータのチューニングを試しましたが、あまり変わらなかったので見直しをする事にしました。
改良(画像水増し、vgg16転移学習、バッチ正規化)
基本的な改良方針は以下としました。
①画像の水増し
②転移学習
③正規化
①画像の水増し
まず学習データを増やすためにImageDataGeneratorを用いて水増ししました。
datagen = ImageDataGenerator(horizontal_flip=True, rotation_range=40, vertical_flip=True)
#水増し関数
def img_extend(x, y):
X_extend=[]
y_extend=[]
i=0
#水増しの繰り返し
while i < 10:
extension=datagen.flow(X_train, y_train, shuffle=False, batch_size=len(X_train))
X_extend.append(extension.next()[0])
y_extend.append(extension.next()[1])
i += 1
#numpy配列に変換
X_extend = np.array(X_extend).reshape(-1, 50, 50, 3)
y_extend = np.array(y_extend).reshape(-1, 9)
return X_extend, y_extend
img_add = img_extend(X_train, y_train)
#水増しした画像を学習データに追加
X_train_add=np.concatenate([X_train, img_add[0]])
y_train_add=np.concatenate([y_train, img_add[1]])
#水増しの確認
print(X_train.shape, X_train_add.shape)
結果

800枚のデータを8800枚に増やすことが出来ました。
②転移学習、③正規化
次に、モデル部分の改良として、vgg16を用いた転移学習と、BatchNormalizationを用いた正規化を試しました。
#vgg16を用いた転移学習モデル
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.1))
top_model.add(BatchNormalization())
top_model.add(Dense(128, activation='relu'))
top_model.add(Dropout(0.1))
top_model.add(Dense(9, activation='softmax'))
#モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
for layer in model.layers[:15]:
layer.trainable = False
#コンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
ここまでで再学習してみました。
#学習
history=model.fit(X_train_add, y_train_add, batch_size=16, epochs=10, verbose=1, validation_data=(X_test, y_test))
#学習結果の可視化
plt.plot(history.history['accuracy'], label='acc', ls='-')
plt.plot(history.history['val_accuracy'], label='val_acc', ls='-')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
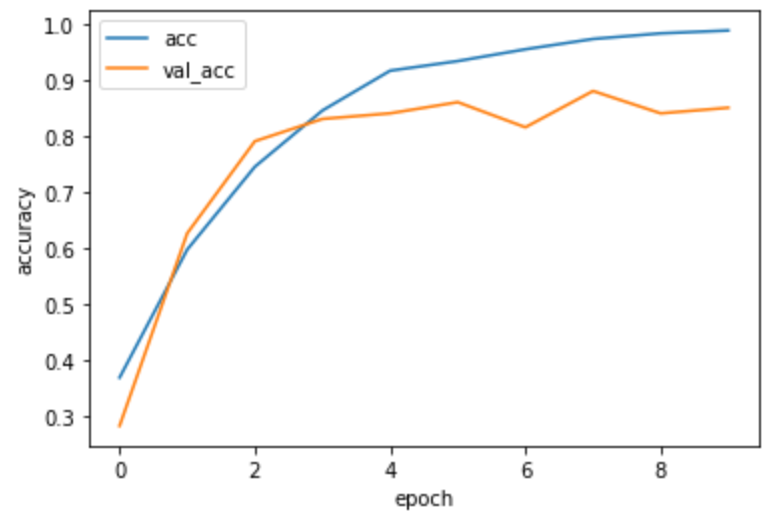
正解率85%になりました。
もう少し上げようかと思いましたが、時間の都合と、改良の効果が確認出来たのでOKとしました。
アプリ作成
アプリ作成部分はAidemyさんのテキストをベースに必要な箇所だけ修正して使いました。
まずはHTMLとCSSです。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>アンパンマンキャラ識別</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<img class="header_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<a class="header-logo" href="#">アンパンマンキャラ識別アプリ</a>
</header>
<div class="main">
<h2> AIが送信された画像をアンパンマンキャラで識別します</h2>
<p>画像を送信してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
<small>識別対象:アンパンマン、カレーパンマン、食パンマン、バイキンマン、ドキンちゃん、コキンちゃん、メロンパンナちゃん、ロールパンナちゃん、ナガネギマン</small>
</footer>
</body>
</html>
header {
background-color: #f4f00a;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: rgba(228, 23, 23, 0.955);
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
height: 370px;
}
h2 {
color: #444444;
margin: 90px 0px;
text-align: center;
}
p {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #F7F7F7;
height: 110px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 25px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}
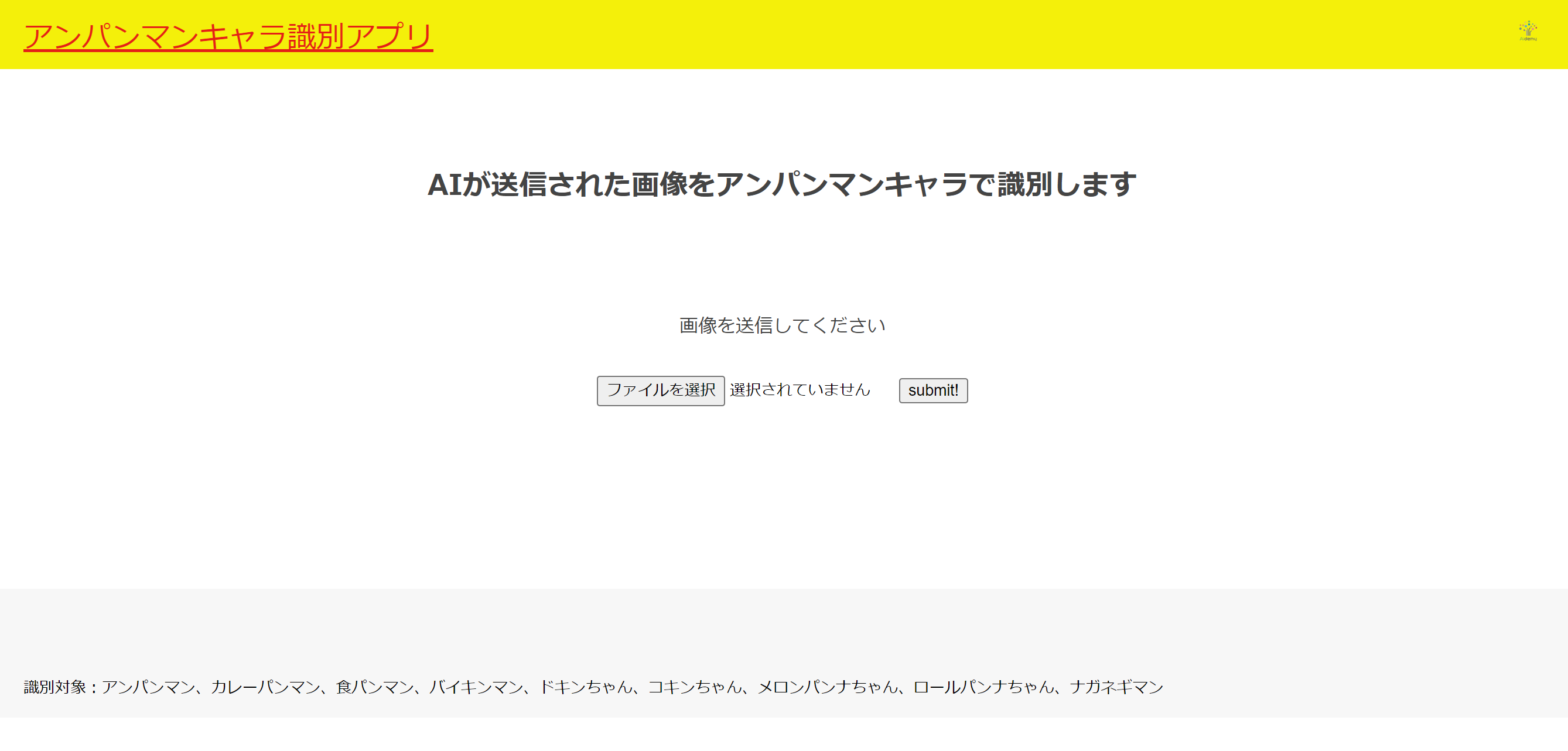
完成したページがこちら。
本当はアンパンマンの画像とかを使ってそれっぽくしたかったんですが、めんどくさがって著作権の問題で断念しました。
次にFlask部分です。こちらもほぼAidemyさんのテキストをベースに必要な箇所だけ変更するにとどめました。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["アンパンマン","カレーパンマン","食パンマン","バイキンマン","ドキンちゃん","コキンちゃん","メロンパンナちゃん","ロールパンナちゃん","ナガネギマン"]
image_size = 50
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5')#学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=False, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
最後にherokuにデプロイして完成です。こちらは割愛します。
試しに、出来上がったページに画像を入れて識別してみましょう。(アンパンマンの画像をいれてみます)
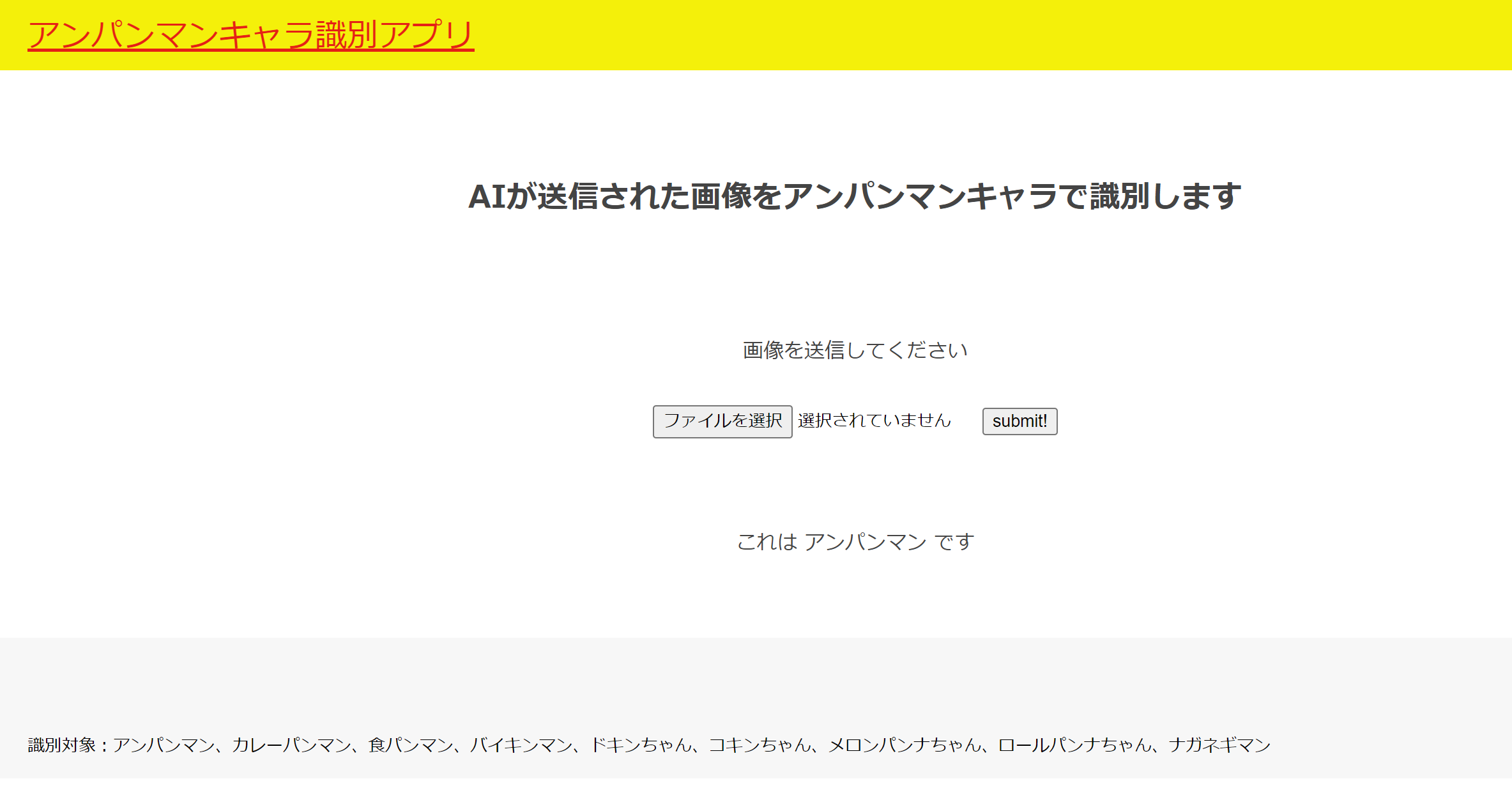
上手くいきましたね。その後いくつか入れてみましたが、キャラの特徴がきっちり出ているような画像であればほぼ完ぺきに解答してくれました。
ただ、学習データにないような手書きの絵は識別出来ませんでした。(学習データにないので仕方ないですが)
ちなみに、お遊びで子供の写真も入れてみたところ、ロールパンナちゃんと識別されました(肌色で人間ぽいから?)
反省とまとめ
ひとまず自分でコーディングして、それなりの精度で識別出来るアプリが出来てよかったです。講座で学んだことをベースに改良することで精度が上がったのを実感できたのも達成感がありました。(最初の20%代の正解率を見た時は焦りました。)
反省点としては全体の正解率だけを見て満足しており、個別の正解率やF値を見ていないので、どのキャラが判別しにくいのか?またそれを改善するにはどうすれば良いのか?というところまで考えなかったところだと思っています。
また、アプリ化の部分はほぼテキストの転用になってしまっていて身についていないと感じています。自分のオリジナルにするためにももう少し勉強しないといけないですね。