はじめに・・
はじめまして、プログラミングに憧れる年季の入った事務員です。
この度、給付金制度を利用して受講したAidemyさんの課題として、ブログの作成をいたします。
内容は、CNN (Conbolutional Neural Network) の画像認識アプリを使って野菜の識別をやってみるというものです。
時間の都合もあり大量の画像収集は断念しましたが、完璧でない事もPython初心者の方々に励みになるかと思います。
それでは早速本題に入ります。よろしくお願いいたします。
内容・・
1.画像収集
2.画像の処理
3.実行環境(インポート)
4.画像の学習
5.画像の可視化
6.実装結果
7.まとめ
実行環境:
・Visual Studio Code
・Google Colaboratory
作成課題・・
野菜識別
Step1.画像の収集
先ずは必要な画像を用意。
**「 scraping 」**でWebから画像を調達。
(※スクレイピングとは、Webページから必要な情報を自動で抜き出す作業です。)
参考文献:
>>【だれでもできる】プログラミングが未経験でも大丈夫。Webから大量画像を収集する方法をわかりやすく解説します。(YouTube動画です)
https://www.youtube.com/watch?v=hRB104ik6pQ
>>画像データをキーワード検索で効率的に収集する方法(Python「icrawler」のBing検索)
https://www.atmarkit.co.jp/ait/articles/2010/28/news018.html
# 必要な機能のインストール
!pip install icrawler
# pythonライブラリの「icrawler」でBing用モジュールをインポート
from icrawler.builtin import BingImageCrawler
# 5種類の野菜をキーワードとするため変数を作成(ほうれん草、人参、きゅうり、ジャガイモ)
search_word = "jagaimo"
# ダウンロードするキーワード
crawler = BingImageCrawler(storage={'root_dir': search_word})
# ダウンロードする画像の最大枚数は130枚
crawler.crawl(keyword=search_word, max_num=200)
上記、
・ひとまず画像検索の決まりコードとして認識する。
・keywordは"ジャガイモ"・・と日本語入力がOK。
・max_numは、最大1000枚まで指定可能とのこと。
・storage={'root_dir': search_word} 辞書型リストで、収集した画像を納めるフォルダ名を作成。
(決まりコードとして認識するのが早い。重要なのは 「search_word」にあたるフォルダ名)

Step2.画像の処理
Webで画像収集を行うと、自力収集と違い不要なデータが混ざります。
今回は手作業で不要データの間引きました。
思った以上に不要データが多かったので精度には期待できません。
Step3.インポート
pythonで画像認識を行うには、専用のファイルをインポートする必要があります。
Aidemyで学習した内容と講師の方のアドバイスによりファイルをインポートするコードを作成していきます。
import os#osモジュール(os機能がpythonで扱えるようにする)
import cv#画像や動画を処理するオープンライブラリ
import numpy as np#python拡張モジュール
import matplotlib.pyplot as plt#グラフ可視化
from tensorflow.keras.utils import to_categorical#正解ラベルをone-hotベクトルで求める
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input#全結合層、過学習予防、平滑化、インプット
from tensorflow.keras.applications.vgg16 import VGG16#学習済モデル
from tensorflow.keras.models import Model, Sequential#線形モデル
from tensorflow.keras import optimizers#最適化関数
# 野菜画像の格納
drive_hourennsou = "/content/drive/MyDrive/Colab Notebooks_1/yasai/hourennsou/"
drive_jagaimo = "/content/drive/MyDrive/Colab Notebooks_1/yasai/jagaimo/"
drive_kyabetu = "/content/drive/MyDrive/Colab Notebooks_1/yasai/kyabetu/"
drive_kyuuri = "/content/drive/MyDrive/Colab Notebooks_1/yasai/kyuuri/"
drive_ninnjinn = "/content/drive/MyDrive/Colab Notebooks_1/yasai/ninnjinn/"
image_size = 50#50x50のサイズに指定
# os.listdir() で指定したファイルを取得
path_hourennsou = [filename for filename in os.listdir(drive_hourennsou) if not filename.startswith('.')]
path_jagaimo = [filename for filename in os.listdir(drive_jagaimo) if not filename.startswith('.')]
path_kyabetu = [filename for filename in os.listdir(drive_kyabetu) if not filename.startswith('.')]
path_kyuuri = [filename for filename in os.listdir(drive_kyuuri) if not filename.startswith('.')]
path_ninnjinn = [filename for filename in os.listdir(drive_ninnjinn) if not filename.startswith('.')]
# 野菜画像を格納するリスト作成
img_hourennsou = []
img_jagaimo = []
img_kyabetu = []
img_kyuuri = []
img_ninnjinn = []
for i in range(len(path_hourennsou)):
#print(drive_hourennsou+ path_hourennsou[i])
img = cv2.imread(drive_hourennsou+ path_hourennsou[i])#画像を読み込む
img = cv2.resize(img,(image_size,image_size))#画像をリサイズする
img_hourennsou.append(img)#画像配列に画像を加える
for i in range(len(path_jagaimo)):
img = cv2.imread(drive_jagaimo+ path_jagaimo[i])
img = cv2.resize(img,(image_size,image_size))
img_jagaimo.append(img)
for i in range(len(path_kyabetu)):
img = cv2.imread(drive_kyabetu+ path_kyabetu[i])
img = cv2.resize(img,(image_size,image_size))
img_kyabetu.append(img)
for i in range(len(path_kyuuri)):
img = cv2.imread(drive_kyuuri+ path_kyuuri[i])
img = cv2.resize(img,(image_size,image_size))
img_kyuuri.append(img)
for i in range(len(path_ninnjinn)):
img = cv2.imread(drive_ninnjinn+ path_ninnjinn[i])
img = cv2.resize(img,(image_size,image_size))
img_ninnjinn.append(img)
# np.arrayでXに学習画像、yに正解ラベルを代入
X = np.array(img_hourennsou + img_jagaimo + img_kyabetu + img_kyuuri + img_ninnjinn)
# 正解ラベルの作成
y = np.array([0]*len(img_hourennsou) + [1]*len(img_jagaimo) + [2]*len(img_kyabetu) + [3]*len(img_kyuuri) + [4]*len(img_ninnjinn))
label_num = list(set(y))
# 配列のラベルをシャッフルする
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# 学習データと検証データを用意
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
# 正解ラベルをone-hotベクトルで求める
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデルの入力画像として用いるためのテンソールのオプション
input_tensor = Input(shape=(image_size,image_size, 3))
# 転移学習のモデルとしてVGG16を使用
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# モデルの定義~活性化関数シグモイド
# 転移学習の自作モデルとして下記のコードを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation="sigmoid"))
top_model.add(Dropout(0.5))
top_model.add(Dense(64, activation='sigmoid'))
top_model.add(Dropout(0.5))
top_model.add(Dense(32, activation='sigmoid'))
top_model.add(Dropout(0.5))
top_model.add(Dense(5, activation='softmax'))
# vggと自作のtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16による特徴抽出部分の重みを15層までに固定(以降に新しい層(top_model)が追加)
for layer in model.layers[:15]:
layer.trainable = False
# 訓令課程の設定
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
# 学習の実行
# グラフ(可視化)用コード
history = model.fit(X_train, y_train, batch_size=32, epochs=50, verbose=1, validation_data=(X_test, y_test))
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
# acc, val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
# モデルを保存
model.save("my_model.h5")
以降、上記コードを自分理解で解説させて頂きます。
説明箇所は学習する上で自分がつまづいたコードです。(つまりほぼ全部ですが・・)
途中、参考文献を載せていきます。
コードその①
# 野菜画像を格納するリスト作成
img_hourennsou = []
img_jagaimo = []
img_kyabetu = []
img_kyuuri = []
img_ninnjinn = []
上記、
・空リストを事前に作成する理由: 収集する画像の増減に対応。
コードその②
for i in range(len(path_hourennsou)):
上記、
・for文 range() で len()を使用し配列( )の長さを取得。
・リスト内に含まれるデータの数だけループを繰り返す。
コードその③
# 正解ラベルの作成
y = np.array([0]*len(img_hourennsou) + [1]*len(img_jagaimo) + [2]*len(img_kyabetu) + [3]*len(img_kyuuri) + [4]*len(img_ninnjinn))
上記、
・配列内の [0]、[1]、[2]、[3]、[4] はインデックス番号ではない。
・コンピュータは、全てを数値化して処理していく。
野菜画像を野菜の「名前」では理解できないため、「ほうれん草=0」「ジャガイモ=1」という具合に仮名名の代わりに数字名でそれぞれの野菜を認識してもらう。
コードその④
# 配列のラベルをシャッフルする
rand_index = np.random.permutation(np.arange(len(X)))
上記、
・ random.permutationで元の配列をコピーして新しい配列を作成し、学習効力をあげる。
参考文献:
>>numpy.random.permutation – 配列の要素をランダムに並べ替えた新しい配列を生成
https://www.headboost.jp/numpy-random-permutation/
>>Generator.permutation – 既存の配列の要素をランダムに並べ替えた新しい配列を生成
https://www.headboost.jp/generator-permutation/
Step4.画像の学習
Kerasモジュールのmodel.add()を使って転移学習をする
**「keras」**とは・・
・Pythonで書かれたニューラルネットワークライブラリ、シンプルな記述が特徴。
・機会学習をより簡単に使うためのライブラリ。
・プログラミング経験が無くてもコードの作成が可能。
参考文献:
>>Kares公式サイト「Keras: Pythonの深層学習ライブラリ」
https://keras.io/ja/
>>【入門者でもわかる】Kerasとは?基礎から丁寧に解説!
https://udemy.benesse.co.jp/data-science/ai/keras.html
※ **model.add()**=バッチ正規化(標準化)で学習に直接関係のないものを取り除き、学習の効率をあげる
コードその⑤
# モデルの定義~活性化関数シグモイド
# 転移学習の自作モデルとして下記のコードを作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation="sigmoid"))
top_model.add(Dropout(0.5))
top_model.add(Dense(64, activation='sigmoid'))
top_model.add(Dropout(0.5))
top_model.add(Dense(32, activation='sigmoid'))
top_model.add(Dropout(0.5))
top_model.add(Dense(5, activation='softmax'))
# vggと自作のtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
上記、
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
・この中の**「input_shape」**は入力シェイプといい、以降に続く学習を行うための初期設定のようなもの。
・最初の1行目で設定すれば、以降2行目以降は必要ない。(ここはコード構成をまるっと覚える)
コードその⑥
top_model.add(Dense(256, activation="sigmoid"))
top_model.add(Dropout(0.5))
上記、
・活性化関数であるシグモイド関数(上限f(x)=1,下限f(x)=0)を使用して、全結合層で学習。
・Dropout5割で「過剰適合」などの過学習を抑制。
参考文献:
>>活性化関数(Activation function)とは?
https://www.atmarkit.co.jp/ait/articles/2003/26/news012.html
>>[活性化関数]シグモイド関数(Sigmoid function)とは?
https://www.atmarkit.co.jp/ait/articles/2003/04/news021.html
>>ディープラーニング初心者が知りたいKerasにおけるdropoutの使い方
https://aizine.ai/keras-dropout0706/
>>Denseを調べます
http://marupeke296.com/IKDADV_DL_No7_dense.html
>>畳み込みネットワークの「基礎の基礎」を理解する ~ディープラーニング入門|第2回
https://www.imagazine.co.jp/
コードその⑦
# vggと自作のtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16による特徴抽出部分の重みを15層までに固定(以降に新しい層(top_model)が追加)
for layer in model.layers[:15]:
layer.trainable = False
上記、
・既存のvgg16モデルと自作モデルを連結させる。
・ vgg16は15層までとする。(vgg16全てを学習内容に取入れるとデータ量が多く、時間もかかる。)
コードその⑧
# 訓令課程の設定
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
上記、
・「損失関数**(loss function)」と「最適化(Optimization)**」で、学習内容を構築。
・lossの値はつまり失敗値なので「0」に近いほどよい。
・ categorical_crossentrは分類問題を解くために用いる損失関数
・ to_categoricalはOne-hot-vectorを求めるための関数。
コード内では
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
がそれを示す。
・optimizerに指定した「SGD」は「確率的勾配降下法(Stochastic gradient descent)」
ランダム抽出した1つのデータを使って、誤差の最小値を探索する。
・ **「compile」**はSequentialが持つcompileメソッド。
参考文献:
>>勾配降下法とは?分かりやすく図解で解説
https://nisshingeppo.com/ai/gradient-descent/
>>categorical_crossentropyとsparse_categorical_crossentropyの違い【Keras】
https://engineeeer.com/keras-categorical-crossentropy-sparse-categorical-crossentropy/
コードその⑨
# 学習データと検証データを用意
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
上記、
・コード表記が前後してしまったが、ここでの注目はスライス「:」の位置である。
・結論としては、「トレーニング8,テスト2」を表現している。
9:1でも7:3でも自由に選択できる。
コードその⑩
history = model.fit(X_train, y_train, batch_size=32, epochs=50, verbose=1, validation_data=(X_test, y_test))
上記、
・ **model.fit()**では、compile化した内容を固定のepochs数で訓練。
・ historyは、.fit()メソッドの戻り値として取得する学習履歴のオブジェクト。
・ batch_sizeは、学習内容の分別個数。過学習予防。
・ epochsは、学習する回数。
・ validation_dataは、検証データ。
・ verboseは、学習過程の表示の仕方。(「0」表示しない、「1」プログレスバー表示、「2」結果のみ表示)
「トレーニングデータを32個に分別。50回の反復学習。訓練データと共に検証データも記録。」
参考文献:
>>コールバックの使い方
https://keras.io/ja/callbacks/
>>Keras で MNIST データの学習を試してみよう
https://weblabo.oscasierra.net/python/keras-mnist-sample.html
コードその⑪
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
上記、
・ **model.evaluate()**は評価関数。
・ scoreは「損失値と評価値」という2つの値をもつタプル。(タプルは()、リストは[]で表現)
(タプルについての理解が勉強不足)
コードその⑫
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
上記、
・{0}はformatメソッドの最初の引数、score。
・{0}[0]はscoreの1つ目の要素、モデルの損失値。
・{0}[1]はscoreの2つ目の要素、モデルの評価値。
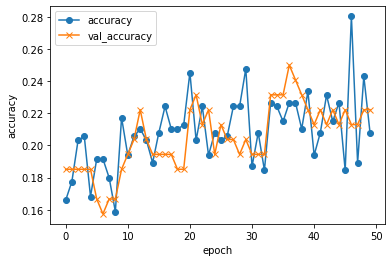
Step5.画像の可視化
コードその⑬
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
# 凡例表記
plt.legend(loc="best")
plt.show()
上記、
Numpy.matplotlib.pyplotで訓練データと検証データのグラフを可視化
Step6.実装結果
やはり結果は完璧ではありませんでした。
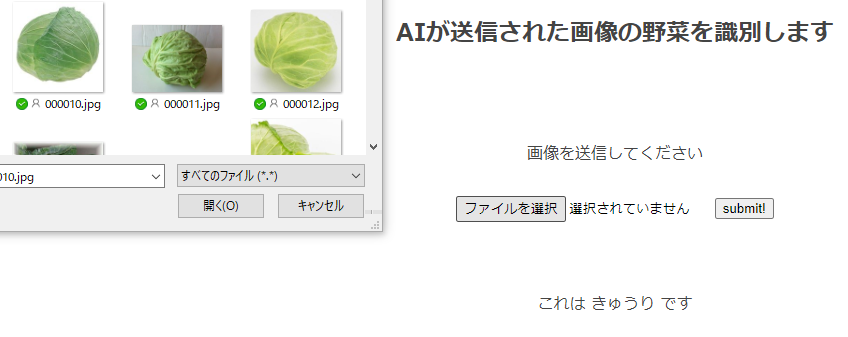
HTML作成(参考になるので載せました)
コードの参考は、AidemyのFlask入門です。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>野菜識別</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<a class="header-logo" href="#">野菜識別</a>
</header>
<div class="main">
<h2> AIが送信された画像の野菜を識別します</h2>
<p>画像を送信してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
<small>© 2021 A.NAKAMURA</small>
</footer>
</body>
</html>
Step7.まとめ
冷蔵庫に野菜識別が出来る機能があれば、・・・と思った事はありませんか。
買ってきた野菜の名前と重量を入力しておけば、献立を考案してくれて、野菜が腐る事も無くなる。
そんな単純な思いから「野菜識別」をしてみようと思いました。
今回の結果は完璧ではありませんでしたが、改善の余地はあると思っています。
今回の画像認識で目的の成果が得られなかった要因は以下です。
1. 学習させる画像の枚数
2. 学習させる野菜のデータ数
3. epochs数
以上について改善すれば、正解率の高い画像認識ができると思います。
もし野菜識別&献立考案機能のついた冷蔵庫がリーズナブルな価格で商品化されれば、きっとヒットするのではないでしょうか。
最後に
プログラミングには興味を持っていましたが、3ヶ月で片手間に勉強するのは大変でした。
頑張れたのは、以下の2つからです。
①質問すれば応えてくれる講師の方々がいた事。
②あえて周囲に公言した事。(こっそりでは挫折が目に見えてました'笑’)
勉強に集中出来ない事を仕事のせいにしていましたが、このブログ作成という課題が出されたことで、
「コードを理解する」という事に真剣に向き合えました。
今後は、Aidemyの3ヶ月より少しだけのんびりとプログラミングの知識を増やしていきたいと思っています。
大それた野望は、自分の仕事に出来るようにスキルを上げる事です。